
Joined December 2009
- Tweets 3,239
- Following 104
- Followers 21,800
- Likes 5,113
330 Photos and videos













Pinned Tweet

Apr 10
We built an app called Hatch
It enables Karpathy's entire LLM Knowledge Base workflow out of the box, in 2 or 3 clicks, in a single interface.
No need to stitch together Obsidian plugins markdown files custom tools etc.
Hatch is an AI workspace where files, docs, and chats all live together. Not only can the chats READ files and docs, but they can WRITE and ORGANIZE them as well.
This means you can set up an LLM Wiki in literally 3 steps, as I show in this video.
Apr 2

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
46
76
941
180,361
Jun 11
Planning a Eurotrip to Portugal and Paris for the second half of July (between 7/15–7/29).
Wanna throw an indie hackers meetup in each city!
Anyone down? Reply/DM me!
cc @levelsio @Pauline_Cx
8
29
3,692
Jun 10
What's wild is:
Here's the kicker:
The contrarian bit:
The interesting part:
The thing people miss:
The insane part is this:
The part everyone resists:
The thing most people skip:
Stop it. Please. I'm begging you. You can write your own thoughts. I believe in you.
7
12
989
Jun 9
I want very badly to believe this model will be a step change like OpenAI's o1 back in the day but I've stopped getting my hopes up.

Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
5
5
1,336
Jun 9
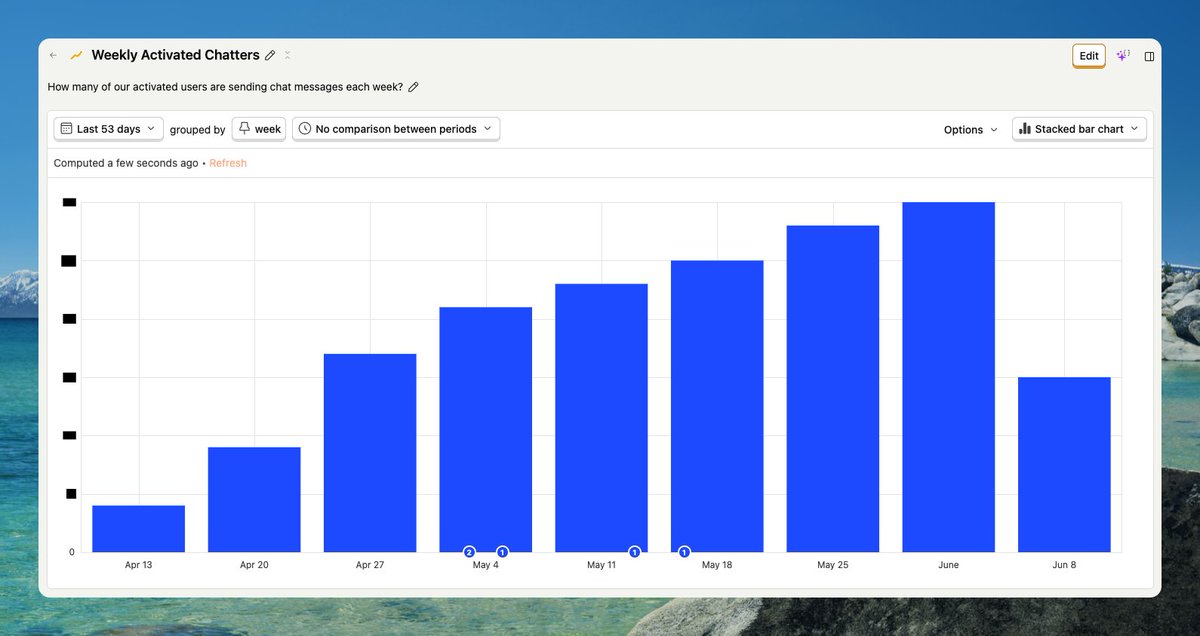
Super encouraging week-over-week growth for @UseHatchAI 🥹
Avoiding VC and doing relatively little marketing. Only running ads on channels we own.
Retention is through the roof! (50% if we get a user to the "aha" moment)
Focus. On. Quality.
2
270
Jun 5
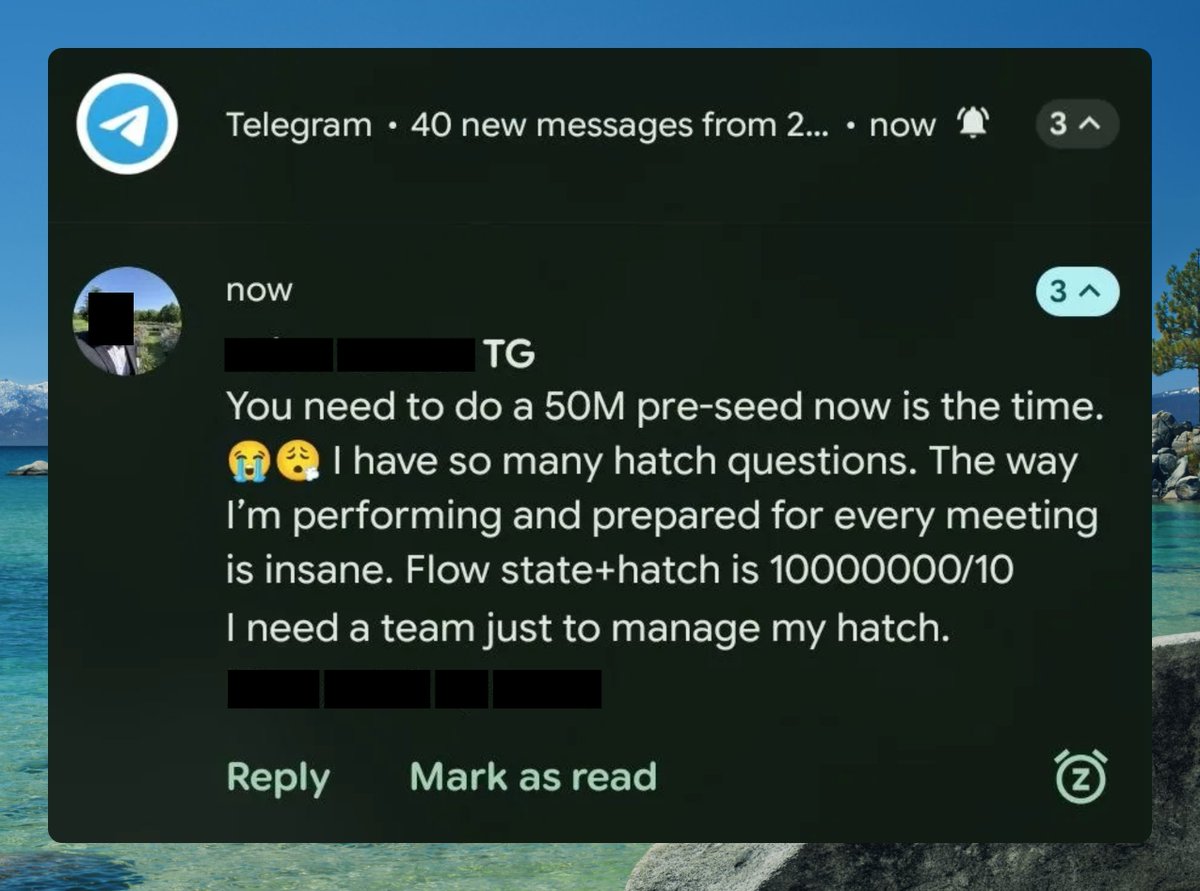
Hard to describe how motivating it is to get messages like this from people using @UseHatchAI in the wild
2
349
Jun 4
Forgot how fun founder events are. Going to start doing Indie Hackers meetups in NYC again soon!
Jun 2

If you're in NYC today,
I'm doing a panel discussion about @IndieHackers and @UseHatchAI at Port Sa'id at 10:30am for NY TechWeek
Come say hi!
1
6
847
Jun 3
Kinda sucks that Markdown is the default language of most AI responses… it's got obvious visual limits.
@UseHatchAI can now generate full HTML pages too, so answers can look like polished mini-sites, dashboards, reports, interactive docs, etc
Jun 2

If you're serious about AI, you should be using HTML to get responses that are 2x more valuable!
Here's how:
2
1
662
Jun 2
If you're in NYC today,
I'm doing a panel discussion about @IndieHackers and @UseHatchAI at Port Sa'id at 10:30am for NY TechWeek
Come say hi!
1
10
1,726
Jun 1
Speed used to be an advantage when nobody could build apps 5–10 years ago.
Now that everybody can build, it all comes down to quality.
May 30

Ship the best product. Use lots of AI, some AI, maybe no AI. Just be the best.
2
1
5
606
May 19
Today's Luddites are in the universities, not the factories.
Booing Eric Schmidt is like booing gravity. The forces behind AI are now bigger than Schmidt and bigger than Google/OpenAI/Anthropic.
Maybe 1/10 of these students will adapt & land on their feet. As for the rest?
May 18

Google CEO tries to tell University students to love AI.
They tell him to BOO off.
This is what most people think of the hated AI, we don't want it.
10
2
12
1,971
May 19
If you're building in AI and feel late, you're probably just spending too much time on tech Twitter.
Out in the real world, people are still figuring out whether they even like this stuff.
May 18

i genuinely feel like normies hate AI even more than crypto now lol
2
7
794
May 19
So dope seeing Yasser hit $10M ARR bootstrapped 🥹
I interviewed him in his first 6 months of Chatbase (he was already at $64k/mo!) and his story is so cool.
Removing the paywall from the interview since he's blowing up right now:
indiehackers.com/post/how-a-…
May 18

We just crossed $10M in ARR at @Chatbase! 🎉 🎉
And today, we're launching Chatbase as the full harness for customer-facing AI agents.
Similar to how Claude code is a harness for coding agents, Chatbase is the harness for customer experience agents.
That means we give the model the context, tools, workflows, guardrails, and human-in-the-loop systems to be the best ambassador for your brand.
It's going beyond just solving issues and is giving your customers the best experiences across every channel.
This is a milestone I have been thinking about and obsessed with since day 1, and I am super excited to bring my vision for customer facing agents to life with Chatbase.
Thank you to every one of our customers and to the amazing Chatbase team for getting us here!
Next stop: $100M ARR
13
1,309
May 13
for the life of me I can't understand why every entrepreneur isn't building an AI company right now
27
1
39
5,185
May 13
It's official: we're changing the name of our community to "Indie God-Emperors"
May 13

Any time there’s a “flat org chart” and it actually works it’s because the entire company reports directly to one god-emperor who makes 999 decisions/day
1
8
1,483
May 13
I still find it crazy that companies like Microsoft pay us to advertise on our newsletter.
We used to be a tiny blog for founder interviews
3
1
27
1,416
May 7
The secret of our success at Indie Hackers has always been that we're great at crowdsourcing products.
Here's a simplified version of our current flywheel for growing IH subscriptions:
1. Our journalists publish paywalled reports & case studies.
2. We tease/promote this content on the newsletter 3x/week. Newsletter is at 226K subs now!
3. Half the newsletter's content comes not from paid staff but from user-generated content from our site. So it's "cheap" and sustainable to produce.
And all this is to say nothing about other revenue streams, like advertising, peer groups, link-in-bio pages, etc.
May 6

I’d love to know more about what you’ve been doing to grow IH, have you written about it somewhere?
3
14
2,317
May 7
Did a Zoom this morning with one of our @UseHatchAI customers to make sure he knew about nonobvious features (e.g. real-time collaboration, offline mode, window tiling).
By the end of the call he asked if we are hiring.
Good sign!
1
8
685