
An intelligent reading partner designed for students, researchers, and lifelong learners. Read at your own pace and get help from AI if you are stuck.
Joined September 2025
- Tweets 80
- Following 4
- Followers 520
- Likes 24
3 Photos and videos


Jun 13
A new curriculum!

A new curriculum on @ChapterPal : Prep reading for the retrieval-augmented generation interview
The curriculum offers a comprehensive technical foundation in retrieval-augmented generation by progressing from fundamental embedding techniques to advanced architectures and evaluation frameworks.
Students begin by mastering dense and sparse passage retrieval methods, such as Sentence-BERT and ColBERT, before examining how these mechanisms integrate directly into language model pre-training and inference via paradigms like REALM and RAG.
The coursework covers critical developments in few-shot learning, black-box model integration, and iterative reasoning agents, such as ReAct, while addressing practical challenges like context positioning sensitivity and long-tail knowledge retrieval.
By including state-of-the-art diagnostic tools like Ragas and innovative training strategies like ANCE or HyDE, this collection provides the expertise necessary to build, optimize, and evaluate modular, knowledge-intensive NLP systems capable of grounding model outputs in external data.
chapterpal.com/curriculum/62…
1
64

A new curriculum on @ChapterPal : Prep reading for the retrieval-augmented generation interview
The curriculum offers a comprehensive technical foundation in retrieval-augmented generation by progressing from fundamental embedding techniques to advanced architectures and evaluation frameworks.
Students begin by mastering dense and sparse passage retrieval methods, such as Sentence-BERT and ColBERT, before examining how these mechanisms integrate directly into language model pre-training and inference via paradigms like REALM and RAG.
The coursework covers critical developments in few-shot learning, black-box model integration, and iterative reasoning agents, such as ReAct, while addressing practical challenges like context positioning sensitivity and long-tail knowledge retrieval.
By including state-of-the-art diagnostic tools like Ragas and innovative training strategies like ANCE or HyDE, this collection provides the expertise necessary to build, optimize, and evaluate modular, knowledge-intensive NLP systems capable of grounding model outputs in external data.
chapterpal.com/curriculum/62…
2
12
1,362
Jun 6
A new curriculum!
A new curriculum on @ChapterPal : Prep reading for the responsible AI and algorithmic fairness interview
This curriculum offers a comprehensive technical and conceptual foundation for navigating the complex landscape of responsible artificial intelligence and algorithmic fairness. Students will begin by examining the societal and legal implications of algorithmic bias, specifically how historical data patterns can perpetuate inequality, before shifting into core quantitative frameworks used to define, measure, and mitigate disparate impacts.
The coursework covers essential trade-offs between competing fairness definitions, the limitations of static group metrics, and the importance of considering long-term societal feedback loops. By bridging the gap between theoretical research and practical application, the curriculum introduces both robust optimization techniques and advanced alignment strategies—such as human and constitutional AI feedback—that move beyond simple model auditing.
Ultimately, learners are equipped to address the sociotechnical challenges of implementing fair systems by blending rigorous bias mitigation algorithms with a critical understanding of the systemic traps inherent in traditional machine learning abstractions.
chapterpal.com/curriculum/07…
1
2
1,569
Jun 1
A new curriculum!
A new learning curriculum on @ChapterPal: Prep reading for the ad ranking and targeting interview
This curriculum provides a comprehensive foundation for understanding the mechanics and machine learning challenges essential to ad ranking, targeting, and recommendation systems.
It begins with the economic principles of generalized second-price auctions before transitioning into the practical application of click-through rate prediction at industrial scale.
The reading list balances classical methodology with modern neural network architectures, covering techniques for feature interaction, sequence modeling, and multi-task learning for complex conversion objectives.
Furthermore, the selection addresses critical real-world engineering issues, including managing data bias, handling sparse categorical inputs, and utilizing counterfactual inference to improve model performance from logged bandit feedback.
chapterpal.com/curriculum/68…
1
90
May 30
A new curriculum!
A new curriculum on @ChapterPal: Foundational milestone papers in AI
This curriculum is a paper-by-paper path across what was groundbreaking in AI, from the stochastic gradient descent invented in 1951 to DeepSeek R1 in 2025.
Read with an AI tutor: chapterpal.com/curriculum/d8…
2
96
AlphaFold 2—arguably the biggest scientific-impact AI paper of the era—is now on @ChapterPal: chapterpal.com/s/198c901c/hi…
3
1
15
1,337
The LoRA paper is now on @ChapterPal: chapterpal.com/s/4y2jj82r/lo…
The LoRA technique from Microsoft made the finetuning of LLMs within reach of an average organization on relatively modest GPUs because it allows training only a small fraction of parameters by keeping the original weights of the LLM being finetuned frozen.
4
27
1,626
May 22
A new curriculum!
A new learning curriculum on @ChapterPal:
Prep reading for the ranking systems interview
This curriculum provides a comprehensive foundation in modern information retrieval, beginning with classic probabilistic models like BM25 and fundamental evaluation metrics such as cumulative gain. It traces the evolution of ranking research from early clickthrough-data optimization and learning-to-rank algorithms—including RankNet, LambdaRank, and LambdaMART—to contemporary deep learning architectures.
Students will explore the shift from simple neural techniques to state-of-the-art transformer-based models like BERT and advanced paradigms such as dense passage retrieval, late interaction architectures like ColBERT, and sparse lexical expansion.
The progression covers critical practical challenges like position bias, approximate nearest neighbor search using HNSW, and the integration of large language models for efficient ranking and knowledge distillation, equipping learners with the theoretical insights and technical implementations required to master large-scale industrial search and recommendation systems.
Learn from foundational papers with an AI tutor and quizzes: chapterpal.com/curriculum/87…
1
105
ChapterPal retweeted

Qwen3.5-Omni Technical Report is now on @ChapterPal if you would like to read it with an AI tutor: chapterpal.com/s/6b9f54a6/qw…
PDF: arxiv.org/pdf/2604.15804
Qwen3.5-Omni is an omnimodal LLM that achieves state-of-the-art performance across 215 audio and audio-visual benchmarks, introduces an innovative Adaptive Rate Interleave Alignment (ARIA) method for stable speech synthesis, and demonstrates emergent audio-visual vibe coding capabilities.
1
1
97
May 9
True
When reading papers, stop switching between PDF, NotebookLM, and ChatGPT. Use @ChapterPal, where reading, asking questions, and taking notes are in a single flow.

2
160
May 9
A new curriculum
A new learning curriculum on @ChapterPal: Prep reading for the search and retrieval systems interview
This curriculum provides a comprehensive foundation for understanding and building modern search and retrieval systems, bridging the gap between classical information retrieval techniques and cutting-edge neural architectures.
The scope begins with fundamental concepts such as term weighting, probabilistic models, inverted indexing, and evaluation metrics, establishing the necessary groundwork for large-scale production search engines. Students progress to advanced topics, including the use of clickthrough data for optimization, neural ranking, and the transformative impact of deep language models like BERT and Transformer architectures.
The final modules explore sophisticated retrieval strategies—such as dense passage retrieval, late interaction models, contrastive learning, and retrieval-augmented generation—while emphasizing the practical challenges of approximate nearest neighbor search and the importance of robust zero-shot evaluation across diverse, heterogeneous datasets.
chapterpal.com/curriculum/51…
210
May 7
A new curriculum
A new curriculum on @ChapterPal : **Prep reading for the LLM finetuning and alignment techniques interview**
Curated by Andriy Burkov
This curriculum provides a comprehensive progression through the theoretical foundations and practical methodologies of large language model (LLM) finetuning and alignment.
Learners begin by exploring core concepts in instruction tuning and data-efficient alignment techniques like LIMA, LoRA, and QLoRA, which enable high-performance model adaptation with minimal resource requirements.
The series then shifts focus to various alignment strategies, including reinforcement learning from human feedback (RLHF), constitutional AI, and preference optimization methods like DPO, KTO, and ORPO.
Beyond standard alignment, the curriculum covers advanced topics such as iterative reasoning, process-based verification, model evaluation using LLM-as-a-judge, and adversarial robustness.
By synthesizing these papers, students will gain a deep understanding of how to transform foundation models into instruction-following assistants that are reliable, steerable, and compliant with human preferences.
chapterpal.com/curriculum/2a…
1
190
May 6
A new curriculum:
A new curriculum on @ChapterPal:
**Prep reading for the embeddings and vector systems interview**
This curriculum provides a comprehensive foundation for understanding modern vector systems, beginning with the evolution of word representations from early static embedding methods to advanced transformer-based architectures.
Learners will study the architectural shift from recurrent networks to attention mechanisms, progressing through pre-training strategies like BERT and the refinement of sentence embeddings for semantic similarity and contrastive learning.
The coursework then bridges the gap between language understanding and scalable information retrieval by examining late-interaction models, dense retrieval techniques, and visual-language alignment.
Finally, the curriculum covers the technical challenges of billion-scale search, detailing state-of-the-art developments in approximate nearest neighbor algorithms, quantization methods, and graph-based indexing structures designed for efficient large-scale deployment.
chapterpal.com/curriculum/8a…
2
341
May 2
A new curriculum
A new learning curriculum on @ChapterPal: Prep reading for the AI platform and MLOps interview
This curriculum provides a foundation for MLOps and the engineering of production-grade AI platforms by bridging the gap between theoretical machine learning research and scalable real-world deployment.
The selected papers address the full lifecycle of modern machine learning, starting with the identification and mitigation of technical debt, the standardization of data validation, and the implementation of robust experiment tracking and model management systems.
It further explores technical strategies for high-performance training and serving, covering topics from distributed parallelization and memory-efficient optimization for multi-billion parameter models to advanced serving techniques for LLMs.
By combining software engineering rigor with infrastructure innovation, this collection equips learners with the necessary frameworks to build reliable, efficient, and reproducible machine learning pipelines.
chapterpal.com/curriculum/82…
1
224
May 1
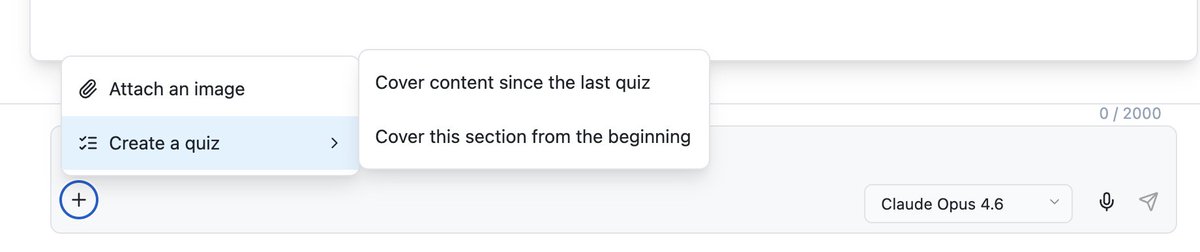
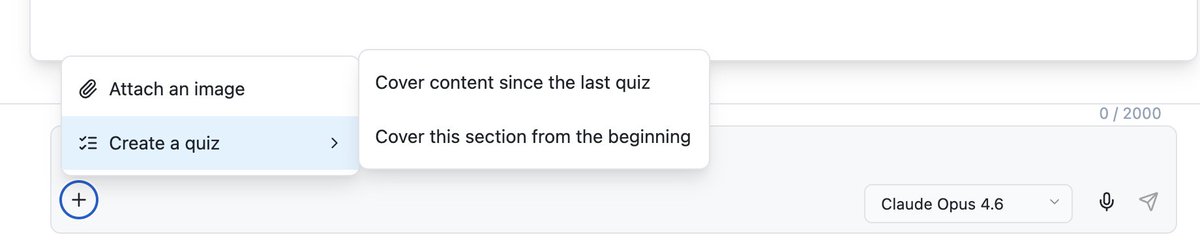
A new feature!
New feature on @ChapterPal: the reader can now add a quiz on demand and choose what content it should cover.
Previously, quizzes could only be created for the entire chapter by asking a multi-agent system to identify the topic to test and the places to put the quizzes.
Some users wanted more quizzes and more granular ones. Now the user can test themselves as often as they feel as they progress in the reading.
ChapterPal is without a doubt the best app to learn from scientific literature. AI is there to unblock you when you are stuck and to challenge you to test your understanding.
The *active reading* approach, where the reader decides when to reveal the content and when to ask questions, blurred terms that prevent superficial skimming, highlights and note-taking, all this provably contributes to better retention.
132
May 1
A new curriculum
A new curriculum on @ChapterPal: Prep reading for the ML monitoring and observability interview
This curriculum offers a comprehensive technical foundation for monitoring, evaluating, and maintaining production-level machine learning systems.
It begins by framing the challenges of technical debt and system reliability before progressing to specialized strategies for data validation, the mitigation of concept drift, and the identification of distribution shifts.
The syllabus further explores deep learning through the lens of robust uncertainty estimation, out-of-distribution detection, and anomaly identification, ensuring learners can distinguish between reliable model outputs and unexpected edge cases.
The curriculum concludes with advanced methods for model interpretability and feature attribution, providing the diagnostic tools necessary to audit model logic, build stakeholder trust, and fulfill essential production readiness standards.
chapterpal.com/curriculum/fc…
Use the Subscribe button to receive email updates to this curriculum.
1
106
Apr 28
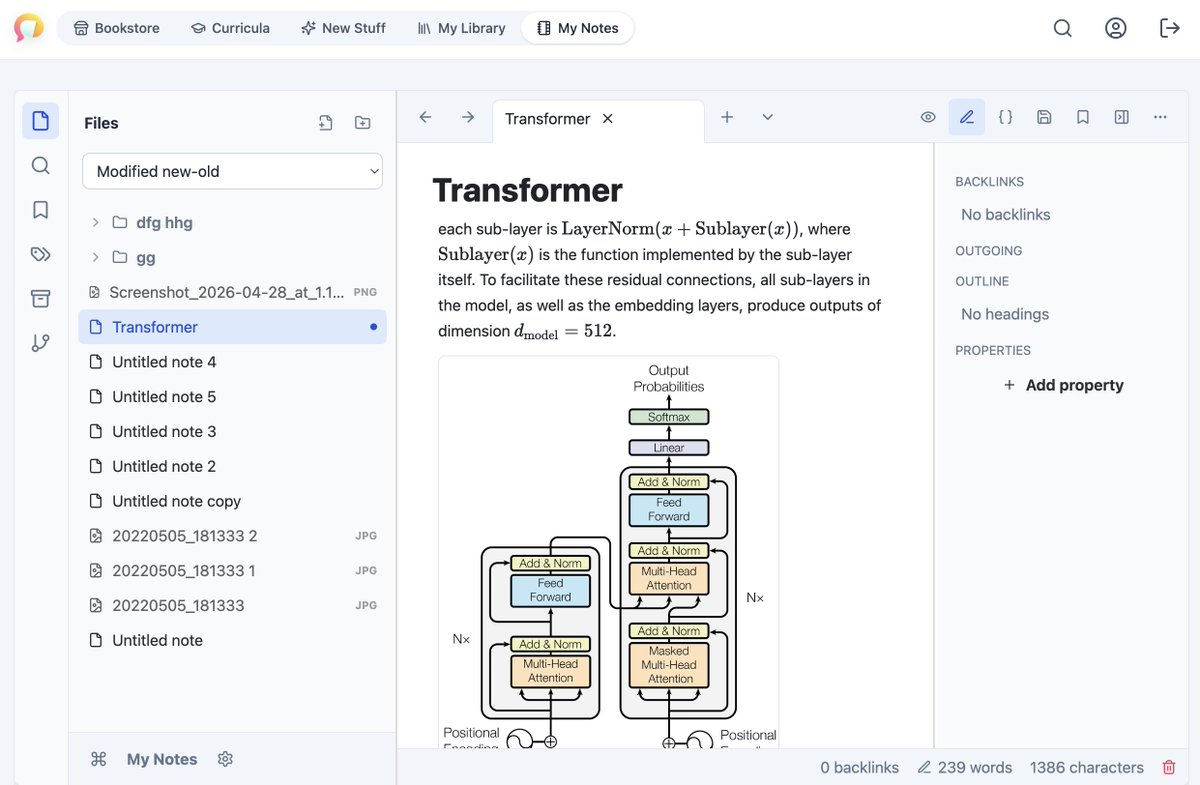
A new feature: My Notes. Any volunteers to help with the tests? Reach out to feedback@chapterpal.com.
Several @ChapterPal users mentioned to me that they use Obsidian for notes, and they asked how to move their highlights, annotations, and Q&As from ChapterPal to Obsidian.
Unfortunately, Obsidian doesn't have an API, so I showed a couple of screenshots to Codex today, and now ChapterPal has a new Obsidian-like Notes feature.
The user can create beautiful notes from their highlights/annotations/Q&As they generate when reading a paper or a book chapter.
They can even use AI to combine several messy highlightings or annotations into a single coherent note.
Then, of course, these notes can be downloaded straight into the user's offline Obsidian vault.
This feature was a single-day work. All important Obsidian features are already implemented, including the graph view, backlinks, hotkeys, and non-standard markdown commands.
Any volunteers familiar with Obsidian to test ChapterPal's Notes and send me feedback on what isn't working or what's missing?
155
Apr 26
A new curriculum.
A new curriculum on @ChapterPal:
Prep reading for the model serving and inference interview
This curriculum provides a comprehensive technical foundation for understanding the architecture and deployment of modern machine learning models, specifically focusing on the lifecycle of large language models (LLMs) from foundational design to high-throughput inference serving.
Learners will first engage with the Transformer architecture before transitioning to system-level optimizations, including custom compiler frameworks like TVM and Triton, memory-efficient attention algorithms such as FlashAttention and PagedAttention, and sophisticated serving strategies like disaggregated prefill-decode architectures and speculative decoding.
Furthermore, the curriculum addresses practical deployment challenges such as hardware-aware quantization techniques (LLM.int8(), SmoothQuant, GPTQ, AWQ) and the efficient multi-tenant management of fine-tuned adapters using methods like S-LoRA, ultimately equipping engineers with the expertise to build scalable, low-latency, and cost-effective model serving infrastructures.
Learn from the best with an AI tutor: chapterpal.com/curriculum/58…

1
307
Apr 24
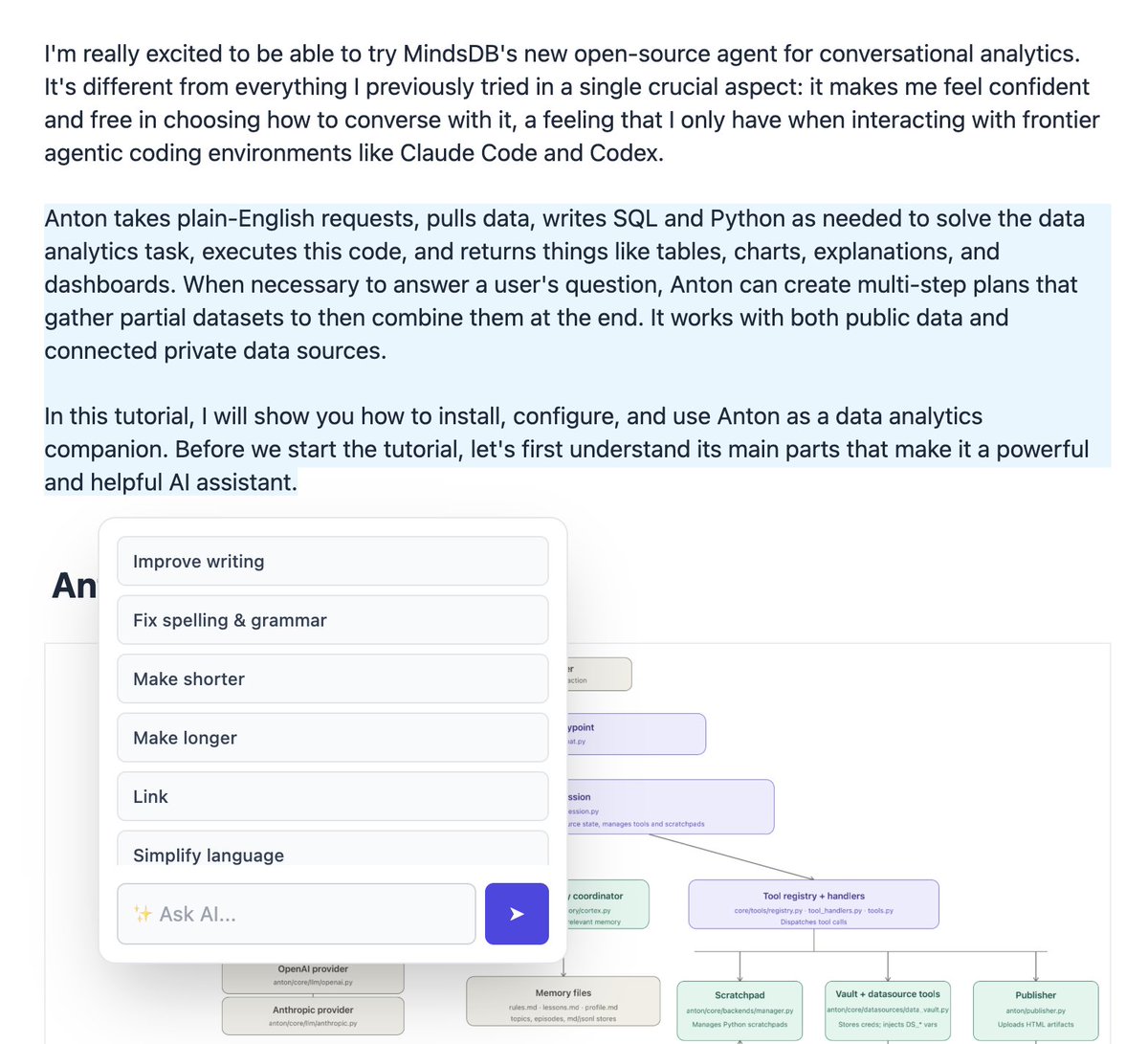
ChapterPal has a WYSIWYG Markdown editor. Try it out!
If you are an author or just write regularly and Markdown is your system of choice, try my @ChapterPal platform in the Editor mode.
It's a WYSIWYG Markdown editor that I've built for myself, and I've added lots of cool AI features that simplify writing and achieve high writing quality with minimal effort. It supports individual articles and multi-chapter books and generates reference numbers automatically, with support for cross-chapter references.
If you try it, please send me your feedback.
Here's just one example of what ChapterPal's editor can do. In the right screenshot, there's the "Link" option. When you type LINK between two paragraphs, then select these two paragraphs and then choose "Link," the AI will replace LINK with a paragraph or a sentence that logically links the two selected paragraphs so that the reading flow is smooth.

1
169
Apr 21
A new curriculum
A new curriculum on @ChapterPal:
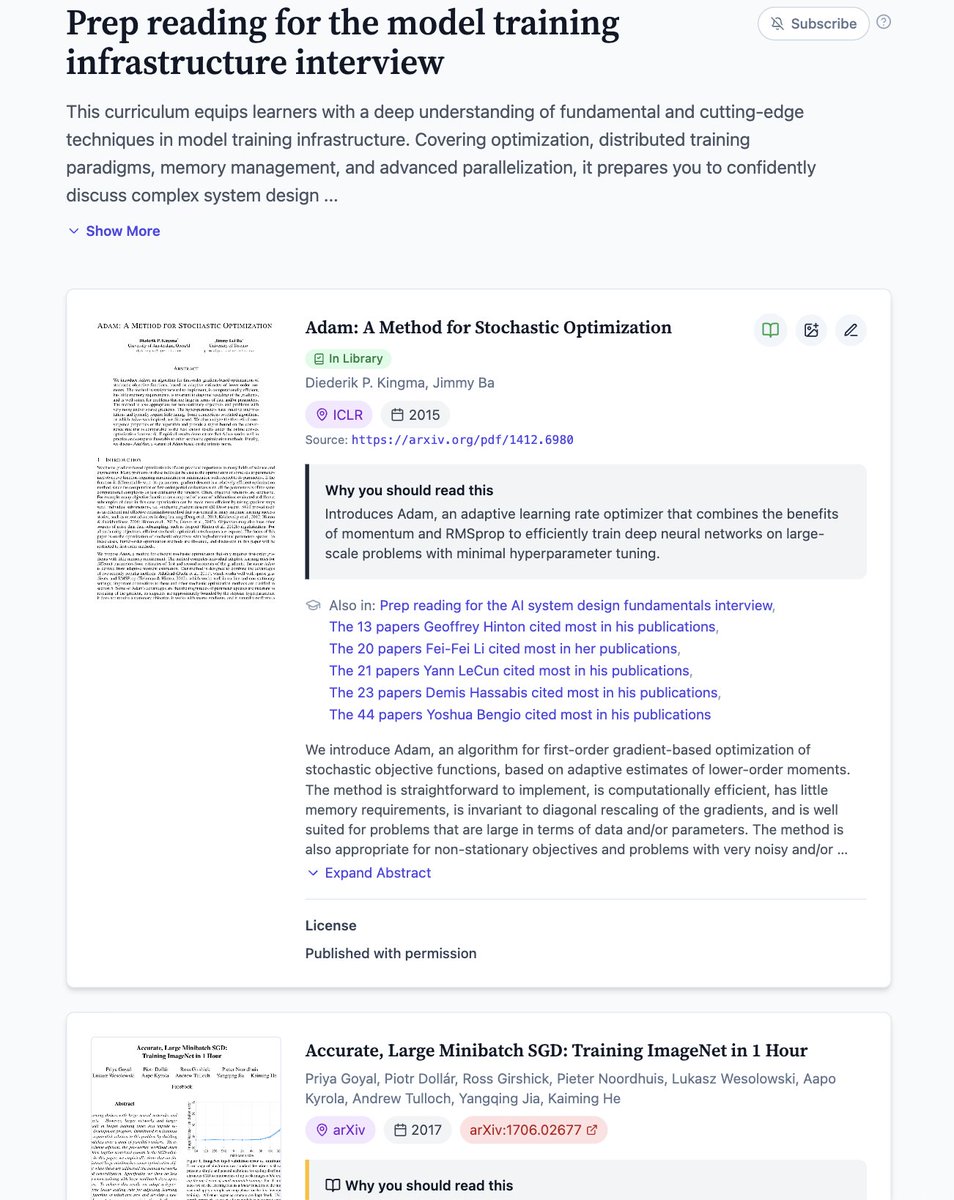
Prep reading for the model training infrastructure interview
This curriculum equips learners with a deep understanding of fundamental and cutting-edge techniques in model training infrastructure.
Covering optimization, distributed training paradigms, memory management, and advanced parallelization, it prepares you to confidently discuss complex system design and performance challenges.
chapterpal.com/curriculum/4f…
2
266