
4,245 Photos and videos










As you know, last year I resigned from my full-time job and become a professional technical book writer. I have plans for The Hundred-Page Books about reinforcement learning, computer vision, diffusion models, and more.
Not having a full-time job has put a significant strain on my savings, so if you love my books and are waiting for more, I would appreciate your continuous support.
I have finalized the offer for those who financially support me. Here's what I offer:
- As a Cool Supporter 10 🚀 ($10/month), you will get early access to new book chapters, exclusive updates on what to really care about in AI and why (only the important stuff, no hype), and a free e-book copy of all new books.
- As a Cool Supporter 30 🚀 ($30/month), you will get everything a Cool Supporter 10 🚀 gets, plus a signed hard copy of all new books.
The names of all Cool Supporters 🚀 will be mentioned in the Acknowledgment section of the new books as important contributors. Your name, printed in the book, will remain in history forever!
If you decide to become a Cool Supporter 🚀, you can choose from several platforms. Here's the list: linktr.ee/burkov
If you choose Substack, you will also get a subscription to a weekly AI newsletter without ads.

5
3
30
2,959
I need your expert opinion. My new RL book will be 100% about algorithms that train a parameterized function as a policy or a value function.
(Please read the rest of the post in the first comment. X doesn't allow creating polls on long posts.)
66%
Keep Deep
34%
Drop Deep
29 votes • 6 days
5
12
2,661
I need your expert opinion. My new RL book will be 100% about algorithms that train a parameterized function as a policy or a value function.
This parameterized function is, in today's practical applications, virtually exclusively a neural network.
A neural network today is virtually exclusively a deep one, so when today you say "deep neural network" or you say just "neural network," you mean the same thing. The same is true about "deep learning." When today you say "machine learning" or "training a neural network," you mean "deep learning," and the other way around.
So, I need your advice.
Should the book's title still be "The Hundred-Page Deep Reinforcement Learning Book," or can I simply and safely reduce it to "The Hundred-Page Reinforcement Learning Book" by explaining in the Foreword that the book is only covering the practical RL, which is today almost exclusively deep while the world deep is no longer meaningful in the same way as it was meaningful in 2012?
6
1
6
1,456
1. Spread false existential fear.
2. Put the thing online nonetheless.
3. Wait for the dumb government officials to react.
4. Profit.
Jun 13

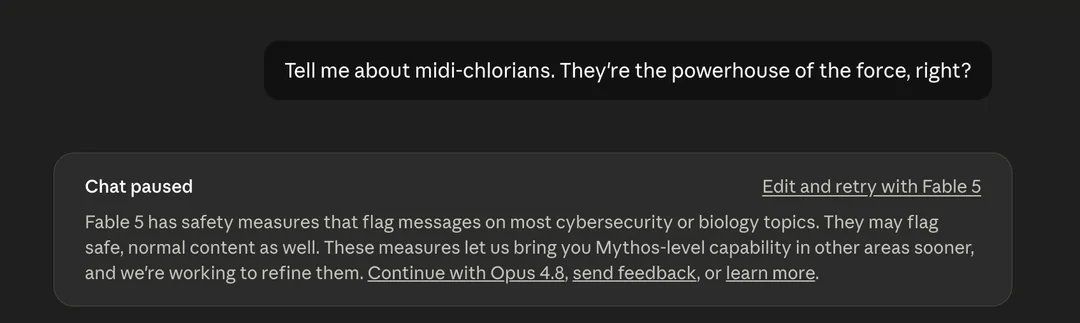
As a result of a US government directive, we are suspending access to Claude Fable 5 for all users. You can continue to use all other Claude models.
Here’s what this means for you:
Across Claude products, new sessions will run on your selected default model or Opus 4.8, and existing Fable 5 sessions will end with an error.
On the Claude Platform, requests to Fable 5 will also return an error. Please update your integrations to other Claude models.
We know this is a disruption to your workflows; we appreciate your patience and support.
22
24
338
13,527
A new curriculum on @ChapterPal : Prep reading for the retrieval-augmented generation interview
The curriculum offers a comprehensive technical foundation in retrieval-augmented generation by progressing from fundamental embedding techniques to advanced architectures and evaluation frameworks.
Students begin by mastering dense and sparse passage retrieval methods, such as Sentence-BERT and ColBERT, before examining how these mechanisms integrate directly into language model pre-training and inference via paradigms like REALM and RAG.
The coursework covers critical developments in few-shot learning, black-box model integration, and iterative reasoning agents, such as ReAct, while addressing practical challenges like context positioning sensitivity and long-tail knowledge retrieval.
By including state-of-the-art diagnostic tools like Ragas and innovative training strategies like ANCE or HyDE, this collection provides the expertise necessary to build, optimize, and evaluate modular, knowledge-intensive NLP systems capable of grounding model outputs in external data.
chapterpal.com/curriculum/62…
2
12
1,341
Assume you are training a small language model by having a larger "teacher" model correct it token by token along the small model's own attempts at solving a problem. A specific thing goes wrong that the authors of this 2026 paper from McGill, Mila and UT Austin name prefix failure: once the student starts down a wrong reasoning path, the teacher faces an awkward choice at every following word, either continuing the doomed path the student committed to or abruptly pivoting back toward the correct answer, and this split makes the correction signal weak and scattered rather than useful.
The authors show that the standard fixes people use (reweighting or capping individual token corrections) cannot repair this because they operate on the wrong scale: the failed reasoning prefix stays in place no matter how you adjust the per-token corrections, so the teacher just keeps pointing at the same "wait, this is wrong" word over and over on top of an already-broken context.
Their proposed method, Trajectory-Refined Distillation, changes what the student learns from: instead of correcting the student's flawed attempt in place, the teacher first rewrites the whole attempt into a cleaner version that fixes the errors while staying close to how the student tends to reason, and the student then learns from that rewritten version, which also exposes it to shorter and alternative valid solutions even on problems it already solves.
chapterpal.com/s/947ac241/tr…
1
6
47
2,911
BURKOV retweeted

The Hundred-Page Machine Learning Book (The Hundred-Page Books)
Link - amzn.to/4oeOdNS
#MachineLearning #ML #AI #DeepLearning #DataScience #SoftwareEngineering #programming

1
2
5
732
I have finished writing the first three chapters of my upcoming book, "The Hundred-Page Deep Reinforcement Learning Book." I'm preparing to put them online and am looking for volunteer early contributors to propose fixes, improvements, and ways to make the prose shorter without losing clarity.
As in my previous books, the names of all volunteer contributors will be printed in the book's Acknowledgments section.
The only requirement is to have a STEM education because the book assumes a certain minimum level of scientific and coding exposure.
Please DM me if you are interested in participating.
8
6
57
3,293
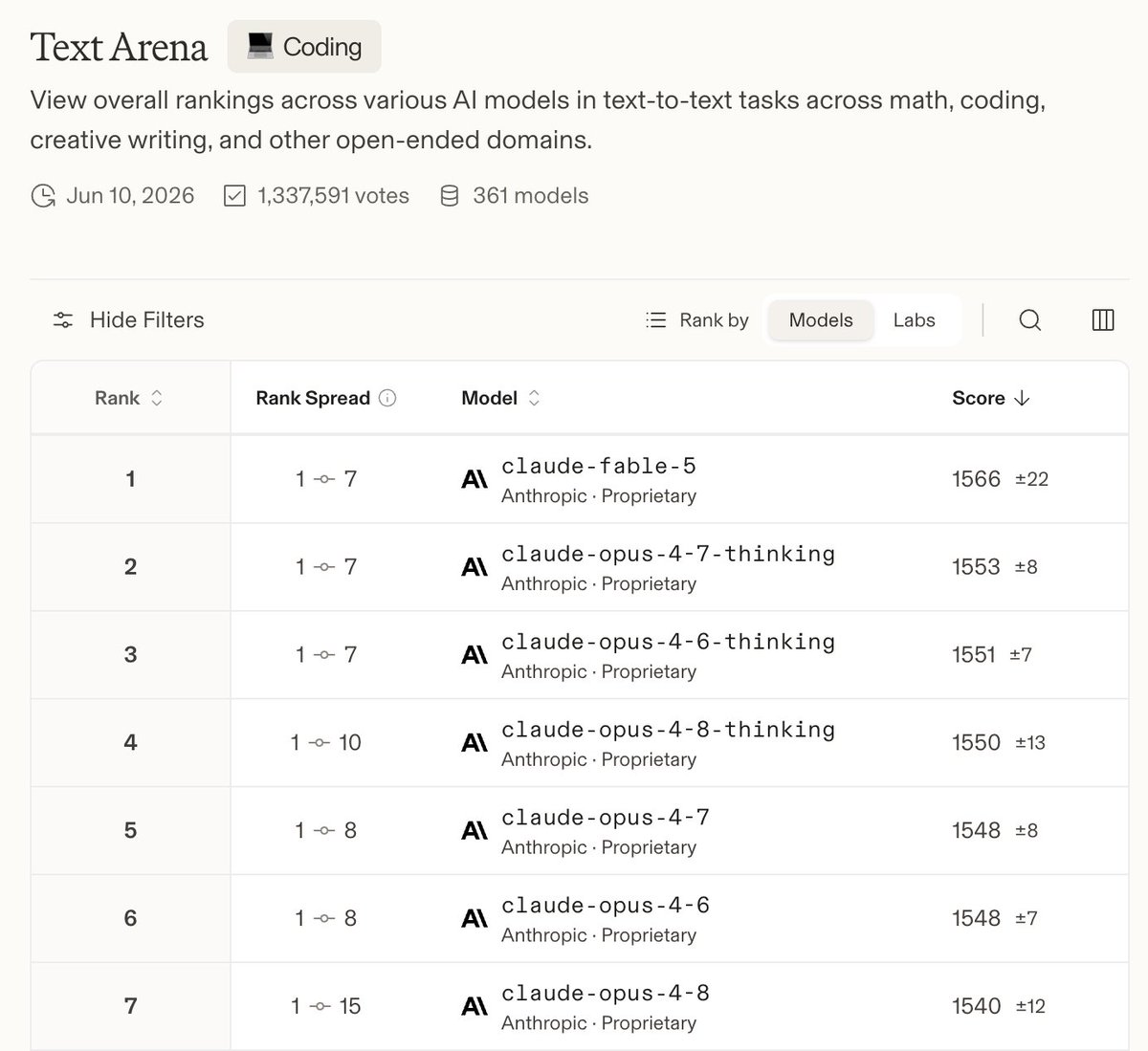
I don't know. Is that it? For all the buzz? For the crazy size? For the crazy price? For the crazy latency? For the crazy daily limits? For the crazy anti-AI research lobotomy? For all these "Ooohh, we are so afraid to show it!" and "Ooooh, someone has got a non-authorized access to it, ooohhhh!"
That's it?
That's ridiculous.

14
9
123
20,667
This 2026 paper introduces MeMo, a modular framework that efficiently incorporates new knowledge into frozen LLMs by encoding it into a dedicated memory model, offering robustness to noise, avoiding catastrophic forgetting, and ensuring plug-and-play compatibility with both open and closed-source LLMs with inference costs independent of corpus size.
chapterpal.com/s/a0444611/me…
3
4
28
1,523
This 2026 paper from Stanford challenges the conventional wisdom of data filtering by demonstrating that, with sufficient compute, large language models benefit from, rather than are hindered by, nominally "poor" and unfiltered data.
chapterpal.com/s/f0662141/a-…
1
1
13
1,126
A new issue of my weekly AI newsletter is out:
What data science is actually about in the age of AI
World modeling for physical AI
Forecasting with foundation models
Research-driven agents: What happens when your agent reads before it codes
CUDA made simple: A short, practical GPU programming guide
[ChapterPal] A bitter lesson for data filtering
[Model] DiffusionGemma: 4x faster text generation
[Model] Command A : an open-weight model for complex reasoning and multimodal agentic tasks—all while running on as little as two H100 GPUs
True Positive Weekly #165 open.substack.com/pub/aiweek…
2
2
14
1,428