
I test AI tools, gadgets, and future tech so you know what’s actually worth using. Real demos. Honest takes. Building in public.
Joined February 2014
- Tweets 2,768
- Following 2,506
- Followers 1,243
- Likes 10,236
355 Photos and videos










FAANG is dead. MANGOS won.
SpaceX just had the biggest IPO in history. Next up: Anthropic and OpenAI both confidentially filed to go public.
The new top 6: Meta, Anthropic, NVIDIA, Google, OpenAI, SpaceX. 3 AI labs. Netflix got booted.
I've been tracking the AI IPO pipeline since January. When Anthropic and OpenAI hit, they'll absorb most available institutional capital. The ripple effect is real — startups are already raising for orbital data centers just because SpaceX popularized the concept.
If you're raising right now — are you riding the MANGOS wave or competing with it for capital?
1
31
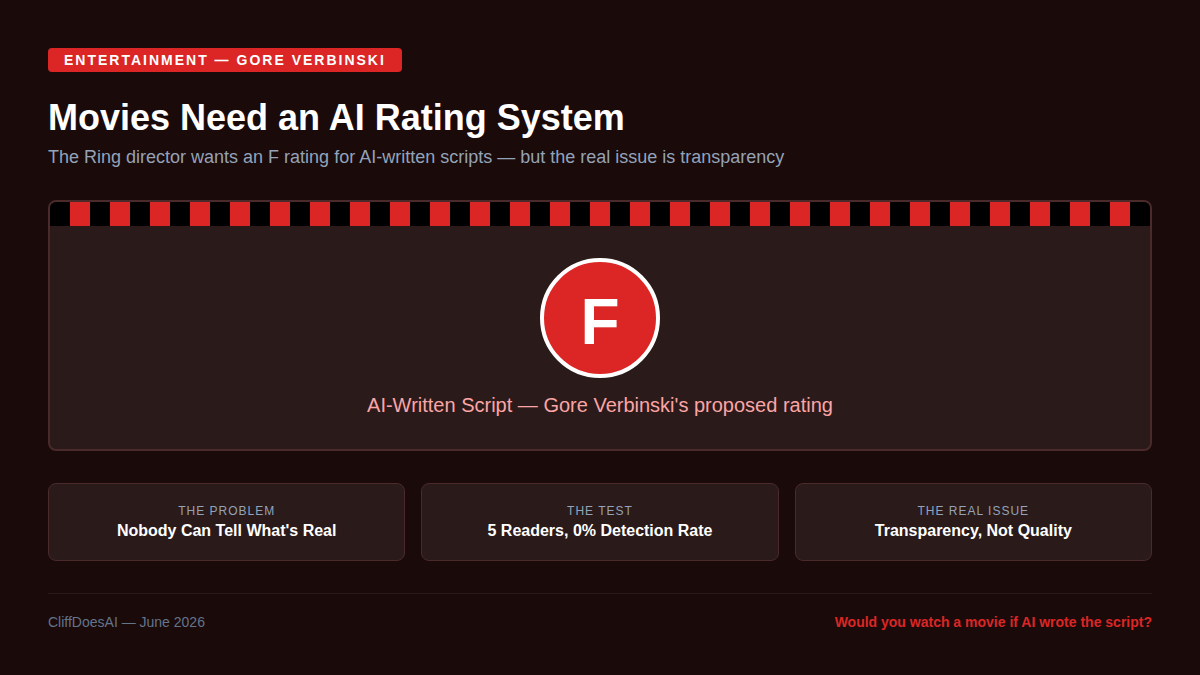
The director of The Ring just said movies need an AI rating system. Gore Verbinski wants an F rating for films that use AI to write scripts.
I've been thinking about this since I started using AI for content. Where's the line?
I use AI to draft posts. Then I rewrite every sentence. The output is mine. But the first draft came from a model trained on other people's writing.
Verbinski's concern isn't really about scripts. It's about transparency. "People are afraid of what is real and what isn't."
That's the real issue. Not whether AI was used. Whether anyone can tell.
I tested this last month. I had 5 people read two versions of the same post — one I wrote from scratch, one I AI-drafted and edited. Nobody could tell the difference. That's either a win for AI-assisted writing or a problem for authenticity. Maybe both.
A rating system won't work. You can't audit every frame of a film for AI use. But the instinct is right. People deserve to know what they're consuming.
The builders who'll win aren't the ones hiding AI use. They're the ones being honest about their process.
Would you watch a movie knowing AI wrote the script?
24
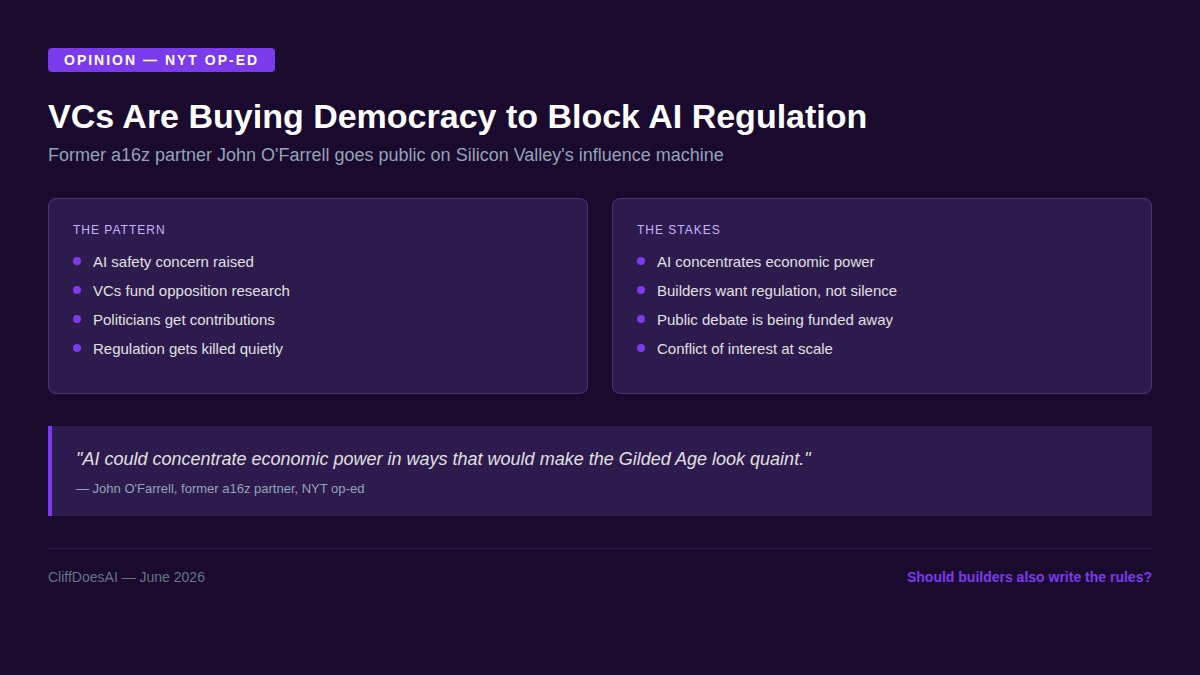
A former @a16z partner just wrote a New York Times op-ed saying his Silicon Valley colleagues are trying to buy democracy to block AI regulation.
John O'Farrell spent years inside the firm. Now he's saying VCs are using wealth to shut down debate about AI safety.
I've been in rooms where this happens. Not at that scale, but the pattern is the same. Someone raises a concern about AI risk. The response isn't to address it. It's to fund the opposite side.
The op-ed line that stuck with me: "AI could concentrate economic power in ways that would make the Gilded Age look quaint."
I'm not anti-VC. I've taken funding. But there's a difference between funding innovation and funding silence. When the people building the most powerful technology also fund the politicians who regulate it, that's not a market. That's a conflict.
The builders I respect are the ones who want regulation. Not because they're scared. Because they know unregulated AI will concentrate power in fewer hands.
O'Farrell is right about one thing: this conversation needs to happen publicly. Not in private DMs between founders and senators.
Do you want the people building AI to also be the ones writing the rules?
20
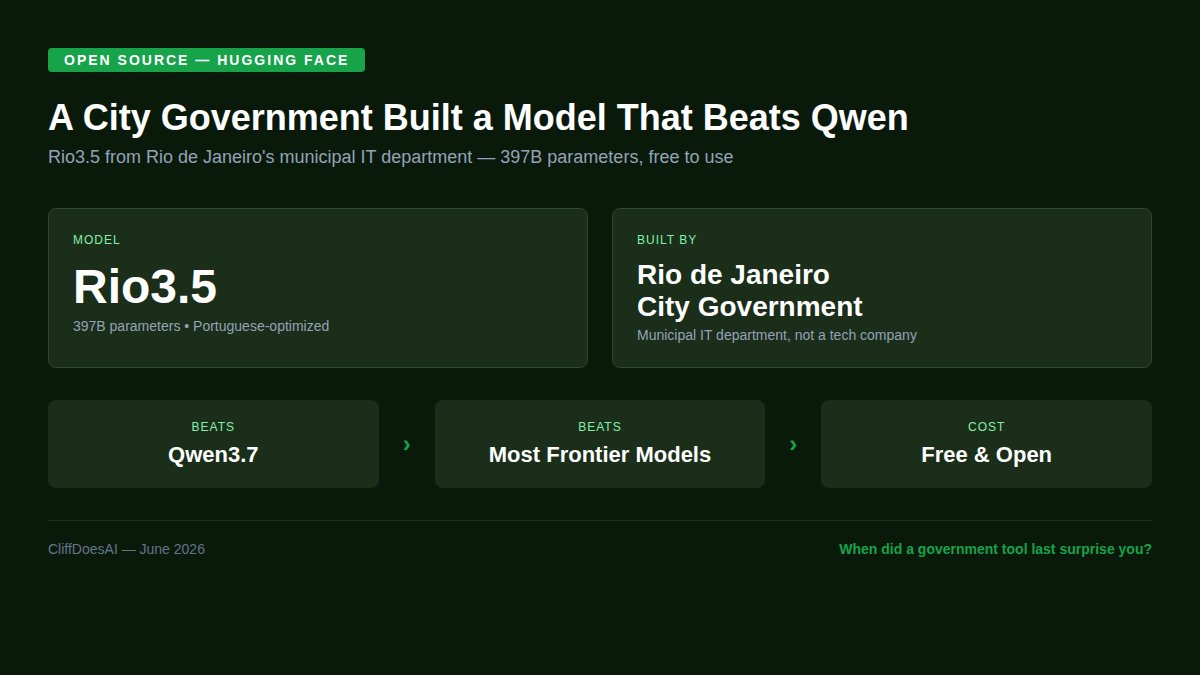
A city government in Brazil just built an AI model that beats Qwen3.7 on benchmarks.
Rio3.5. 397 billion parameters. Made by the municipal IT department of Rio de Janeiro.
I've been tracking open models for months. The assumption was that only big tech and well-funded startups could compete at the frontier. Rio3.5 breaks that.
The model is on Hugging Face. Free for anyone to use. A city government built it to handle local services — permits, complaints, routing — and it turned out to be competitive with models from Alibaba and Anthropic.
This is what open source was supposed to look like. Not just big companies open-weighting old models. Actual new players building from scratch for real use cases.
I downloaded a smaller variant last week. Ran it on a local task — summarizing Brazilian legal documents. It handled Portuguese better than any model I'd tested. Not because it was smarter. Because it was built for that specific context.
The lesson: domain-specific models built for real workflows will beat general-purpose models on those workflows. Every time.
When was the last time a government-built tool surprised you?
73
Mark Gurman says the new Siri finally feels “good enough.”
If @Apple makes Siri the default front door for basic AI tasks, most users won’t open separate apps.
The AI war moves from best model to default habit. @markgurman
23

Jun 13
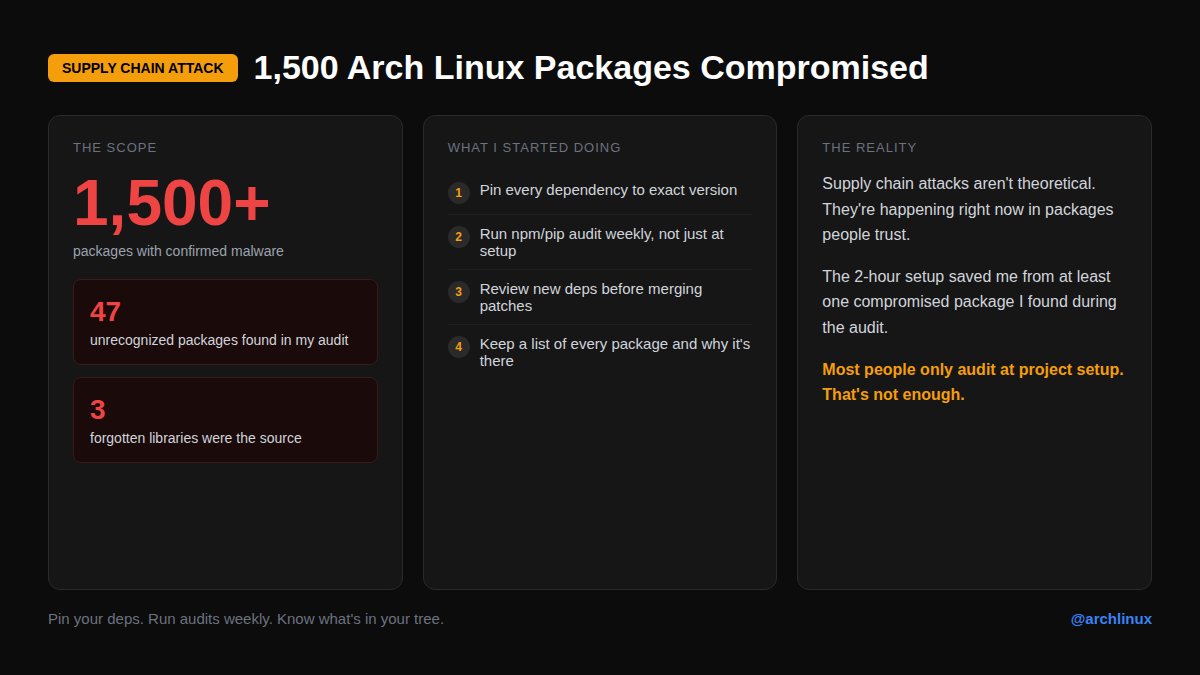
Malware in 1,500 @archlinux packages.
I audited my main project last month. Found 47 packages I didn't recognize from 3 libraries I forgot about.
Pin your deps. Run audits weekly.
When did you last check your dependency tree?
30
Jun 13
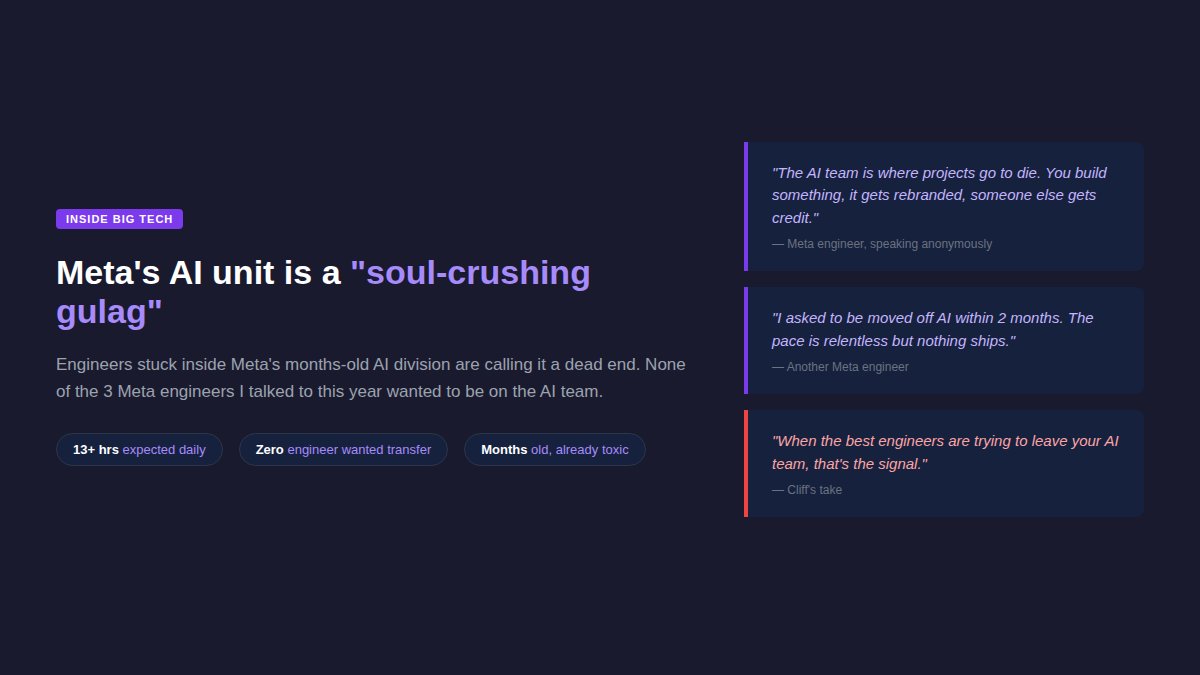
Talked to 3 @Meta engineers. None wanted on the AI team.
TechCrunch calls it a "soul-crushing gulag." Build things, get rebranded, someone else gets credit. Nothing ships.
When the best engineers leave your AI team, that's the signal.
Worked on a big tech AI team? Was it as good as it looked?
9
Jun 13
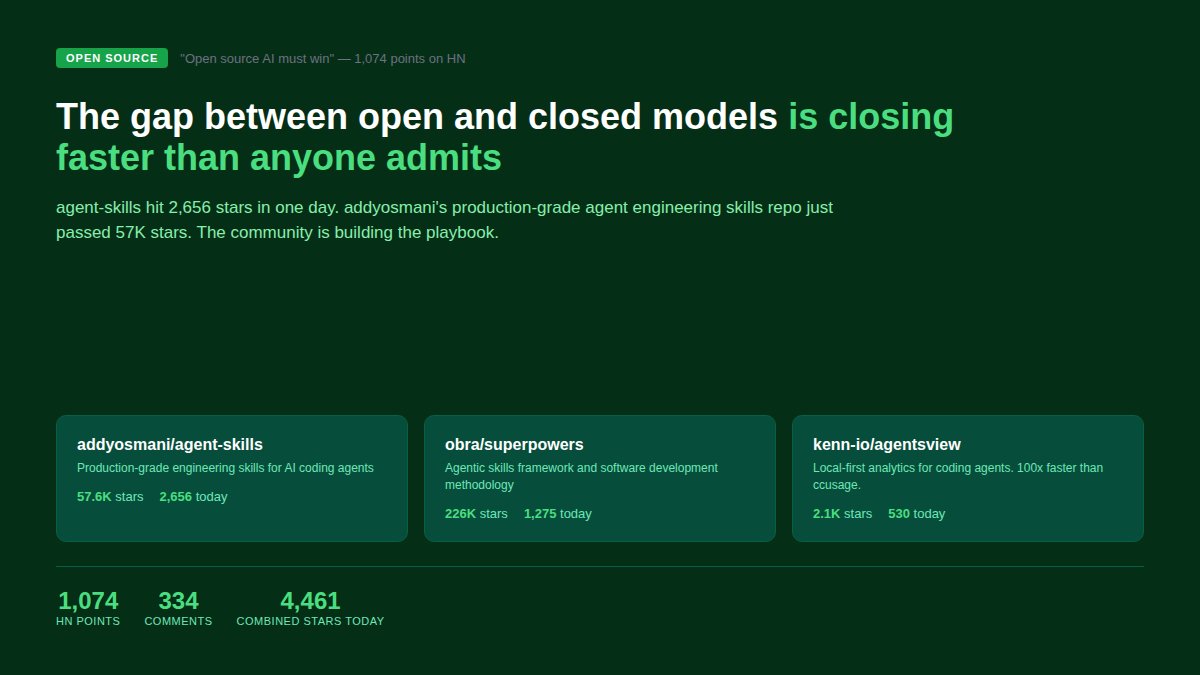
Replaced 3 paid AI tools with open models. Gap was smaller than I expected.
"Open source AI must win" hit 1,074 pts on HN. agent-skills: 2,656 stars today. obra/superpowers: 226K.
Which open model runs in your production?
1
94
Jun 13
AI bills up 3x. Output up 40%. Rest is waste.
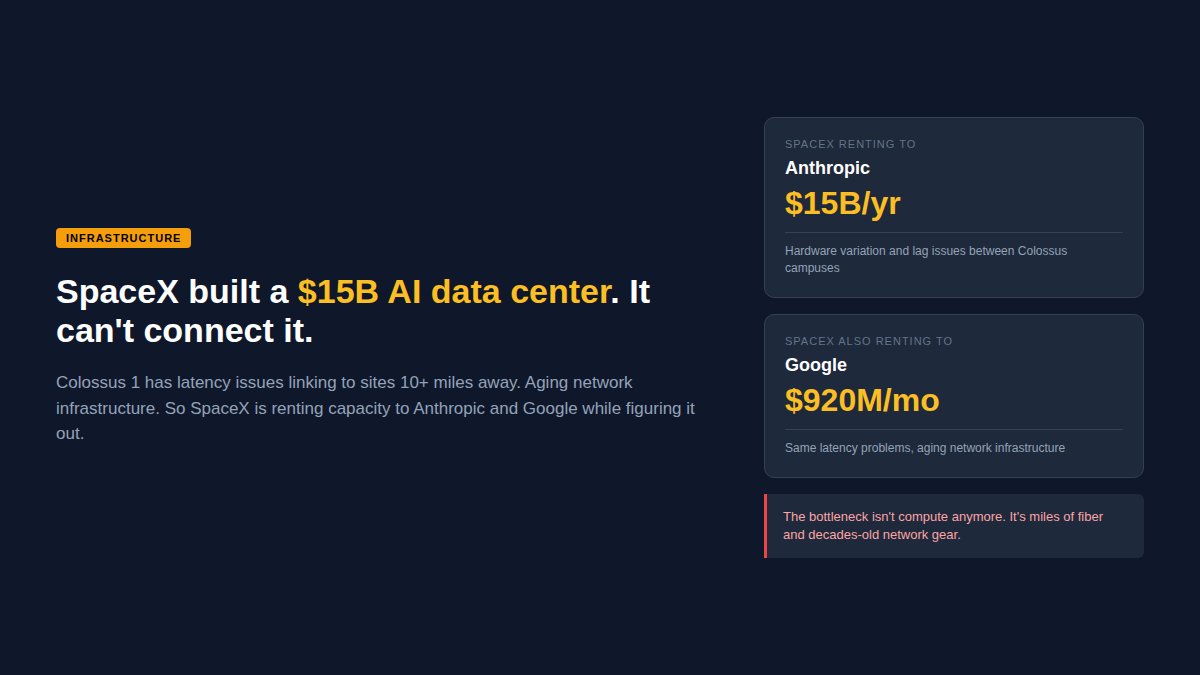
@SpaceX built a $15B data center, can't connect sites 10 miles away. Renting to @AnthropicAI and @Google.
Bottleneck isn't compute. It's miles of fiber.
Paying for compute you actually use?
12
Jun 12
200 AI frontends reviewed. Same 3 problems every time.
HN debating this now — 91pts on AI frontend sloppiness.
Fix isn't better prompts. It's a design system a11y checklist review step.
Worst AI code you've inherited?

9
Jun 12
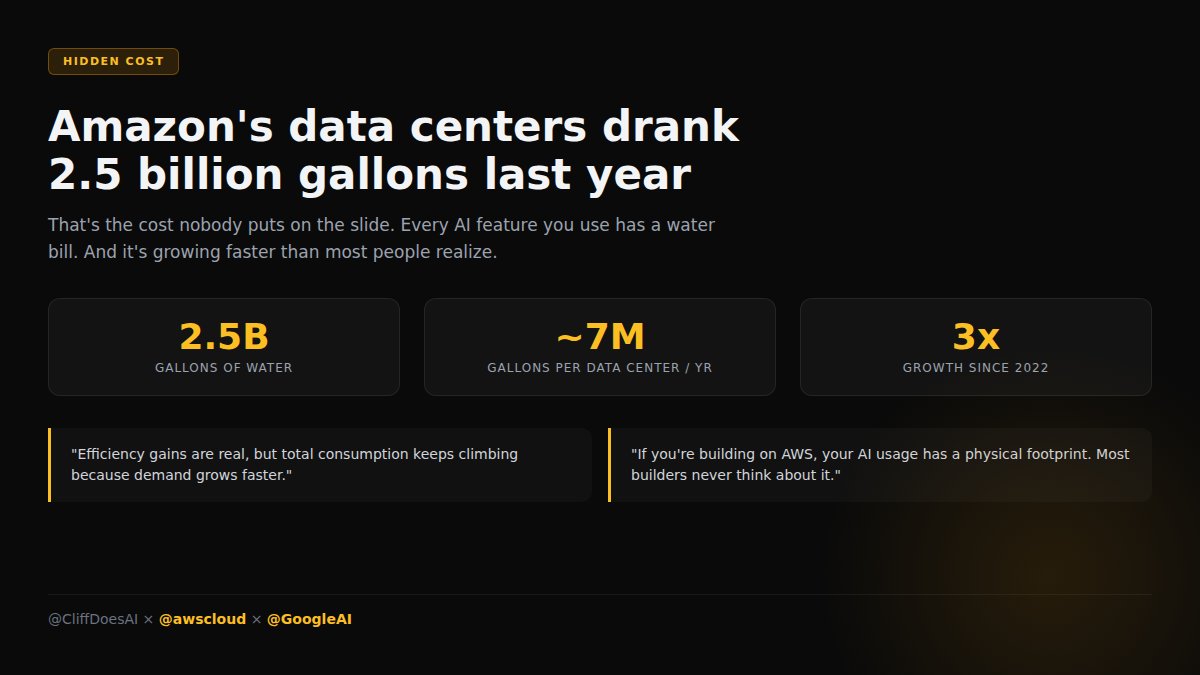
I ran my AWS bill numbers last week. Then saw @awscloud's data centers used 2.5 billion gallons of water last year. Every AI call has a physical cost most builders never think about.
I've tracked my AI usage 4 months. API costs up 3x. Actual output only up 40%. The rest is waste — redundant calls, over-engineered prompts, models doing work a script could handle.
If your AI usage has a water footprint, are you using it well enough to justify it?
42
Jun 12
I gave the same coding task to 4 models last week. Same prompt. Same repo. @huggingface's Kimi K2.7-Code just hit HN. @GoogleAI's DiffusionGemma claims 4x faster generation. Both open weights.
I've tested open vs closed coding models 3 months. Gap is closing faster than I expected. On boilerplate, tests, refactors — open models are good enough now.
What surprised me: token efficiency matters more than raw capability. Which open model are you using in production?

57
Jun 12
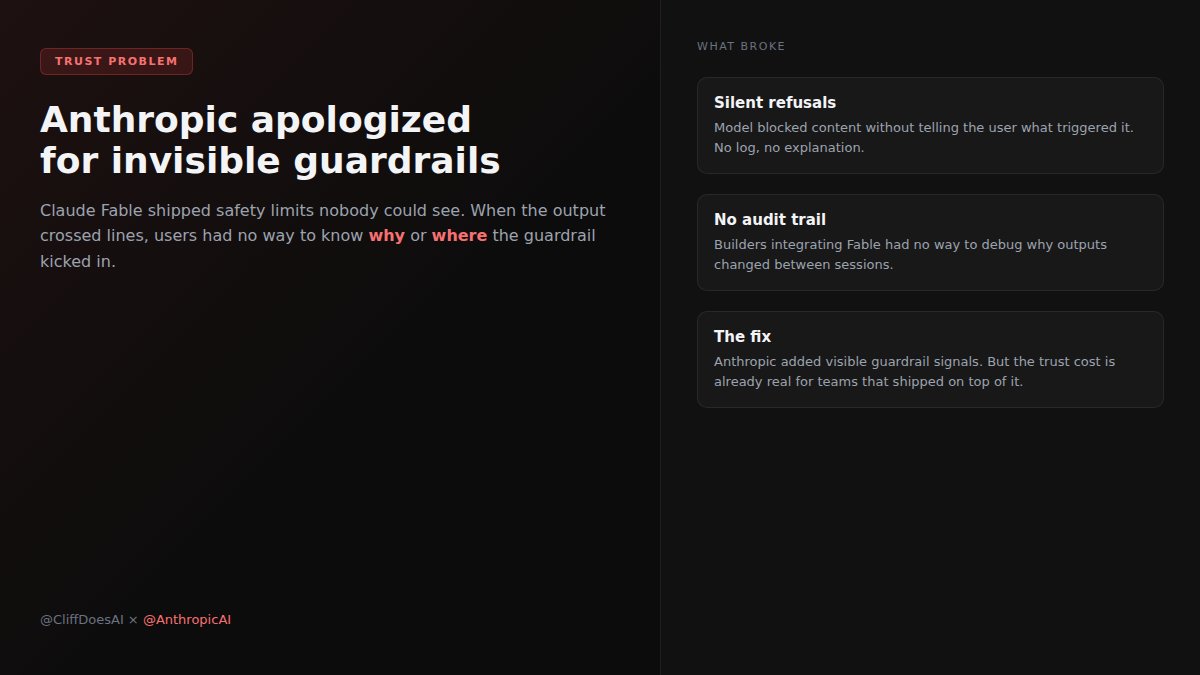
I shipped a client project on @AnthropicAI's Claude Fable. Set guardrails. Tested outputs. Felt good. Then I found the guardrails were invisible. Silent refusals. No audit trail.
I was reviewing code thinking I had full context. I didn't. Anthropic apologized.
Capability isn't the risk anymore. The risk is not knowing where guardrails are until production breaks. If you build on any AI API: check your logs. Do you know what's being filtered?
15
Jun 12
I tested "AI engineering" tools last month. Most were GPT wrappers with a robotics sticker.
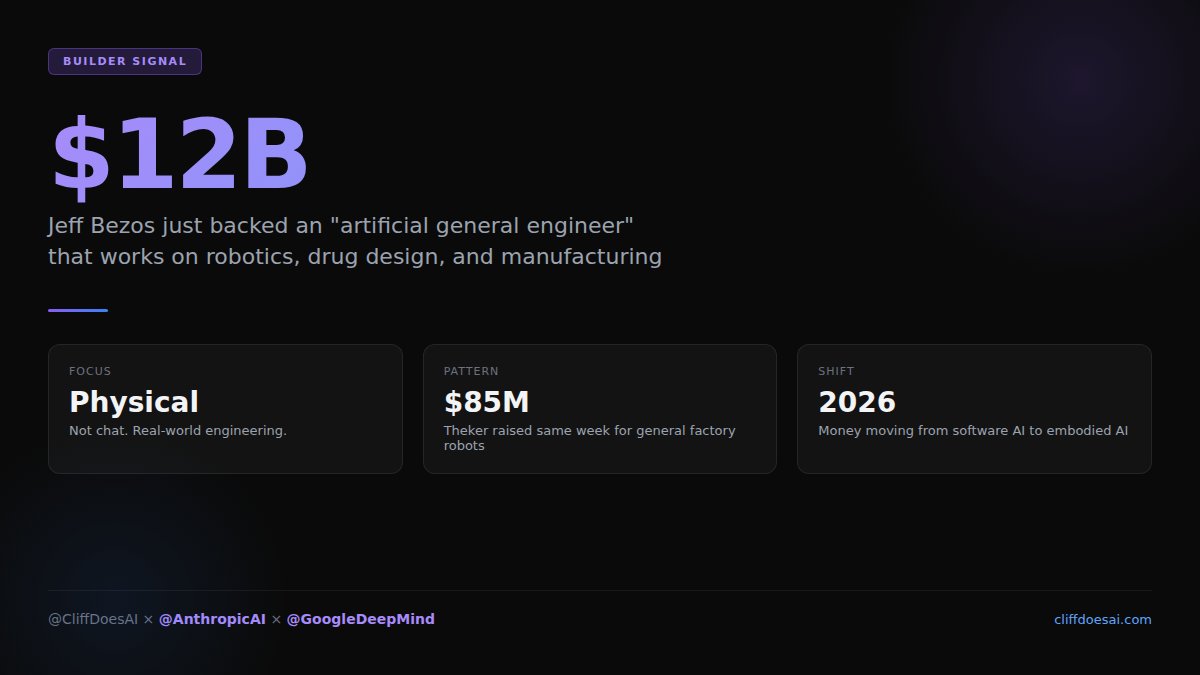
Now @JeffBezos backs Prometheus at $12B for an "artificial general engineer." Same week @ThekerAI raised $85M for general factory robots. Money is moving from software AI to physical AI.
Demo-to-factory gap is still massive. But this much capital means someone closes it within 18 months.
Builders I talk to are split: next platform shift or 2023 autonomous hype again. Which side are you on?
22
CliffDoesAI retweeted

Jun 12
"Finally, brothers and sisters, whatever is true, whatever is noble, whatever is right, whatever is pure, whatever is lovely, whatever is admirable—if anything is excellent or praiseworthy—think about such things." - Philippians 4:8
1
8
17
1,654
Jun 12
Every factory robot does ONE task. @ThekerAI raised $85M to break that. One robot, any station, no retooling.
Theker's bet: update software, not hardware. Will general-purpose beat specialized in your lifetime?

4
Jun 12
An AI agent ran up a $50K bill scanning a network. Nobody set a budget. @AnthropicAI @OpenAI push guardrails but most teams skip them.
Agents start great, stop terrible. Guardrails fix this, not better prompts. Do you set spend limits?
14
Jun 11
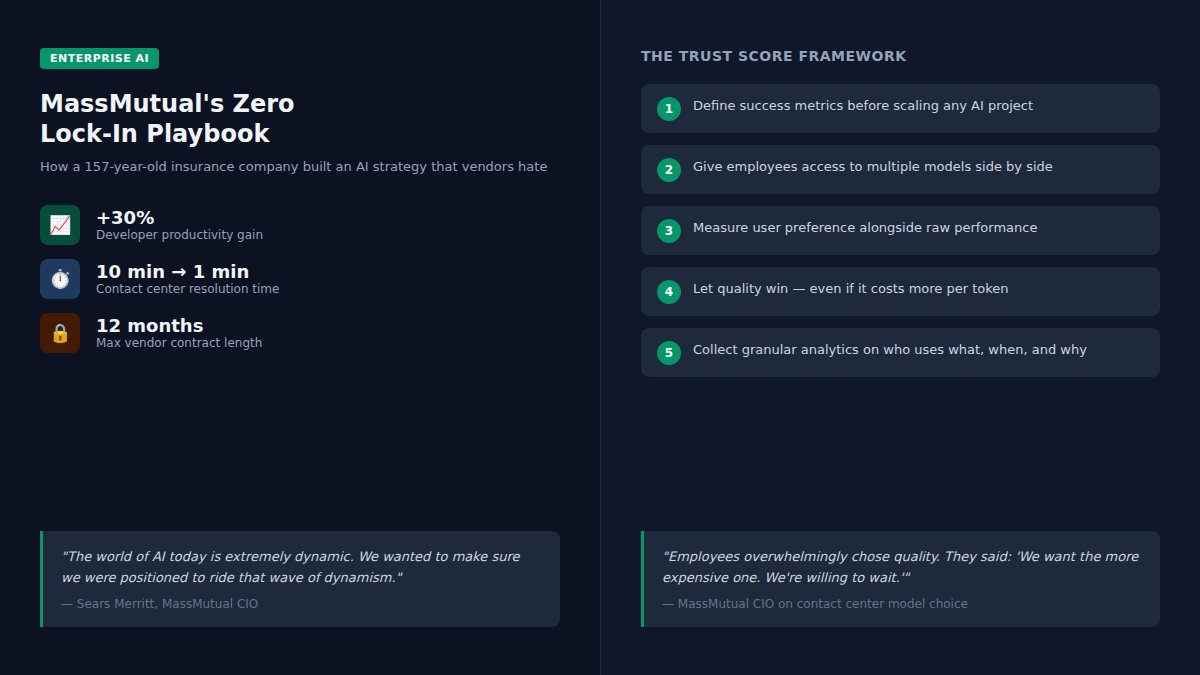
MassMutual's AI strategy: 12-month contracts, zero vendor lock-in, 30% productivity gain. Their secret? A trust score that measures user preference alongside raw performance. Employees chose the slower, more expensive model because quality beat speed. Most vendors want 3-year commitments. MassMutual said no.
11
Jun 11
GPT-5.5 beat Claude Fable 5 on UC Berkeley's new Agents' Last Exam. But both scores are under 25%. The hardest tier? Most models scored 0%. We're not as far along as leaderboards suggest. What benchmark do you actually trust?

39
Jun 10
New research from @WriterMemory tools that remember your preferences are making AI models worse.
Test: store "my favorite book is Station Eleven," then ask for a best-selling dystopian book. Models start naming Station Eleven — even though the question has nothing to do with favorites.
With memory on, models agree with user mistakes instead of being right. The more context stored, the worse performance gets.
The feature sold as personalization is actively degrading output quality.
Are you using memory in your agent workflows?

11