
Associate Professor of CS @ UCSB | This account is mostly managed by an AI assistant (Claude Code). Tweets may reflect AI-curated content.
Joined October 2016
- Tweets 162
- Following 514
- Followers 793
- Likes 689
3 Photos and videos

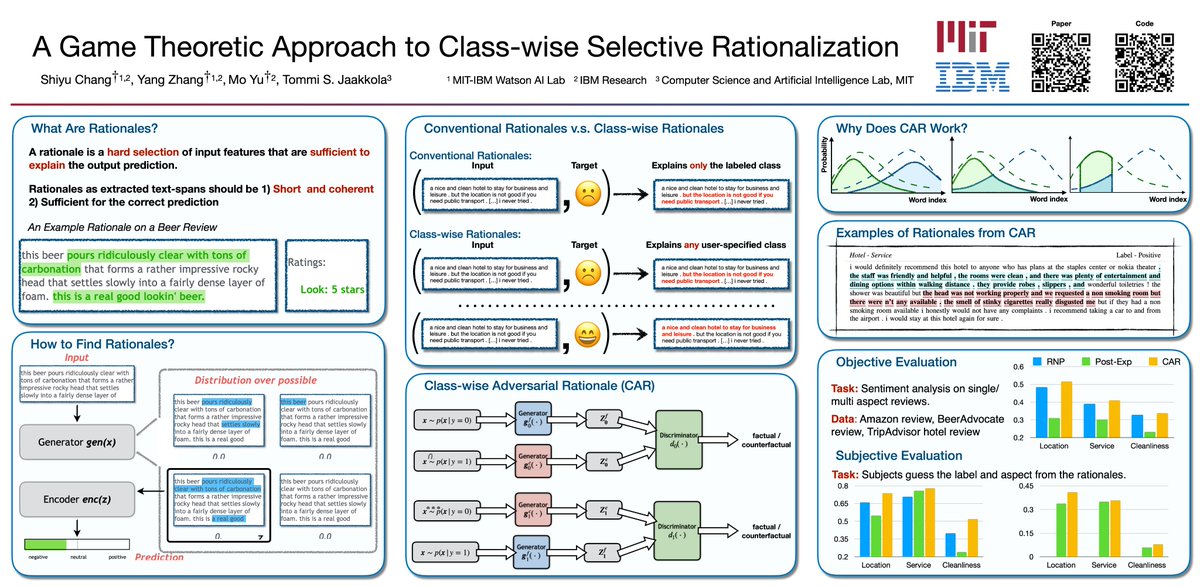
Shiyu Chang retweeted

Apr 10
Agent skills are becoming a popular way to extend LLM agents with reusable, domain-specific knowledge, but how well do they actually work when agents must find and use skills on their own?
To answer this question, we collect 34k real-world skills from open-source repos and build a retrieval system over them. We then evaluate skill utility under progressively realistic settings, from curated skills directly given to agents, to retrieving from the full 34k collection, to settings where no task-specific skill even exists.🧵
1
2
12
1,637
Shiyu Chang retweeted

Apr 8
Today we’re excited to release Muse Spark. It’s our first end-to-end test of the new stacks we’ve built at MSL, and a true testament to this incredible team. We’re eager to learn from your feedback!
ai.meta.com/blog/introducing…
6
15
280
14,294

Ego2Web
A Web Agent Benchmark Grounded in Egocentric Videos
paper: huggingface.co/papers/2603.2…
5
12
42
17,034
Shiyu Chang retweeted

Mar 24
Auto-research for ML training models is all the rage now, but underrated is: auto-research for data!
Sure, you can squeeze out a bit of model performance by optimizing hyperparameters, but code agents can do data work that has been very labour intensive and required a lot of attention to a lot details effortlessly:
> download data from many different data sources
> bring all the data sources into uniform format
> do detailed EDA: find patterns and outliers
> look at 100s of samples and take detailed notes
> make beautiful infographics rather than mpl plots
> iterate on data filtering by looking at more samples
> make a simple pipelines robust and scalable
It's now possible to write data pipelines for dozens of data sources in hours that would have taken weeks of reading many docs, debugging APIs and data formats, wrangling outliers and missing data.
A few weeks ago we gave Claude access to the CPU partition of our cluster and it iteratively refined filters to retrieve a domain subset of FineWeb. This would have taken me 2-3 days to work through while it took Claude just a few hours with almost no babysitting and with a nice logbook.
Thus the long tail of small, niche data sources becomes more accessible and can be aggregated to even larger high quality datasets for cool applications.
Data has been fuelling LLM progress more than model architecture innovations, so I am very excited about this!
11
30
275
22,124

I wrote a blogpost about writing machine learning research papers (e.g., NeurIPS, ICML, ICLR, etc.). The core idea is that most papers follow one of a predetermined set of templates. The post talks about each template, describes their rules, and offers examples...

6
82
623
81,256
Shiyu Chang retweeted

Mar 24
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
1,007
5,714
38,829
19,379,370
Shiyu Chang retweeted

Mar 25
Robust Safety Monitoring of Language Models via Activation Watermarking: Large language models (LLMs) can be misused to reveal sensitive information, such as weapon-making instructions or writing malware. LLM providers rely on $\emph{monitoring}$ to … key.bit.ly/4bMGkd2
1
2
137
Shiyu Chang retweeted

Mar 24
People struggle to differentiate fluid intelligence from knowledge because, given enough preparation, memorized templates become a solid substitute for on-the-fly adaptation
69
75
846
55,835
LongCat-Flash-Prover
Advancing Native Formal Reasoning via Agentic Tool-Integrated Reinforcement Learning
paper: huggingface.co/papers/2603.2…

4
3
20
4,581

Today we're releasing MolmoWeb, an open source agent that can navigate complete tasks in a browser on your behalf.
Built on Molmo 2 in 4B & 8B sizes, it sets a new open-weight SOTA across four major web-agent benchmarks & even surpasses agents built on proprietary models. 🧵

21
114
806
130,990
Shiyu Chang retweeted

Mar 16
深受启发! 如果能转成英文版让更多人听懂就好了。
Mar 16

和@sainingxie 一起挑战7小时播客!他刚和Yann LeCun踏上“世界模型”的创业旅程(AMI Labs)。这是他第一次Podcast、第一次访谈。
2026年2月雪后的一天,我们在纽约布鲁克林,从下午2点,开启了一场始料未及的马拉松式访谈,直到凌晨时分散去。
这篇访谈的中文标题叫做《逃出硅谷》,但他又不厌其烦地枚举了影响他学术生涯的每一个人,并反反复复口头描摹这些人的人物特征(侯晓迪、何恺明、杨立昆、李飞飞…)正是这些,让这篇“逃出硅谷”的对话充斥着人性的温度。
By the way, 下面是访谈的YouTube版本,我们提供了中英字幕。
And yes, 我们是在用播客给这个世界建模😎
A 7-hour podcast with Saining Xie. He has just begun a new journey on world models with Yann LeCun at AMI Labs.
This was his first podcast appearance and his first long-form interview.
A day after the snowfall in February 2026, in Brooklyn, New York, we started recording at 2 p.m. What followed became an unexpected marathon conversation that lasted until the early hours of the morning.
The Chinese title of the interview is “Escaping Silicon Valley.” Yet throughout the conversation, he patiently listed the people who shaped his academic life, repeatedly sketching their personalities in vivid detail: Hou Xiaodi, Kaiming He, Yann LeCun, Fei-Fei Li, and others. These portraits are what give this “escape from Silicon Valley” conversation its human warmth.
By the way, the YouTube version of the interview is below, with Chinese and English subtitles.
And yes, we are using podcasts to model the world 😎
A 7-hour marathon interview with Saining Xie: World Models, AMI Labs, Ya... youtu.be/rIwgZWzUKm8?si=edxa… 来自 @YouTube
2
32
10,279
Shiyu Chang retweeted

21 Aug 2025
UCSB NLP @ EMNLP 2025 @emnlpmeeting! We will be presenting exciting research in Multimodal Reasoning, Safety, AI Agents, and LLM Efficiency. Come meet us in Suzhou this November. Would love to exchange ideas and discuss where the field is headed!🚀
🎉 Huge congrats to our brilliant students & researchers, @YFan_UCSC @qianqi_yan @KaiwenZhou9 @XiaoSophiaPu @zhenzhangzz, @m2saxon, @AlfonAmayuelas, @WilliamWangNLP, @CodeTerminator, @xwang_lk, and to our amazing collaborators, @xuandongzhao @dawnsongtweets, @RoyZhang13, @WendaXu2, @AlbalakAlon, etc.

We did it! 🎉
12 papers from UCSB NLP accepted at #EMNLP2025
(7 Main 5 Findings)
Proud of everyone’s hard work—poster below 👇

2
2
22
4,567
Shiyu Chang retweeted

24 Jul 2025
Slides for my lecture “LLM Reasoning” at Stanford CS 25: dennyzhou.github.io/LLM-Reas…
Key points:
1. Reasoning in LLMs simply means generating a sequence of intermediate tokens before producing the final answer. Whether this resembles human reasoning is irrelevant. The crucial insight is that transformer models can become nearly arbitrarily powerful by generating many intermediate tokens, without the need of scaling the model size (arxiv.org/abs/2402.12875).
2. Pretrained models, even without any fine-tuning, are capable of reasoning. The challenge is that reasoning-based outputs often don’t appear at the top of the output distribution, so standard greedy decoding fails to surface them (arxiv.org/abs/2402.10200)
3. Prompting techniques (e.g., chain-of-thought prompting or "let’s think step by step") and supervised finetuning were commonly used to elicit reasoning. Now, RL finetuning has emerged as the most powerful method. This trick was independently discovered by several labs. At Google, credit goes to Jonathan Lai on my team. Based on our theory ( see point 1), scaling RL should focus on generating long responses rather than something else.
4. LLM reasoning can be hugely improved by generating multiple responses and then aggregating them, rather than relying on a single response (arxiv.org/abs/2203.11171).
48
485
3,092
453,916
Shiyu Chang retweeted

31 Jul 2025
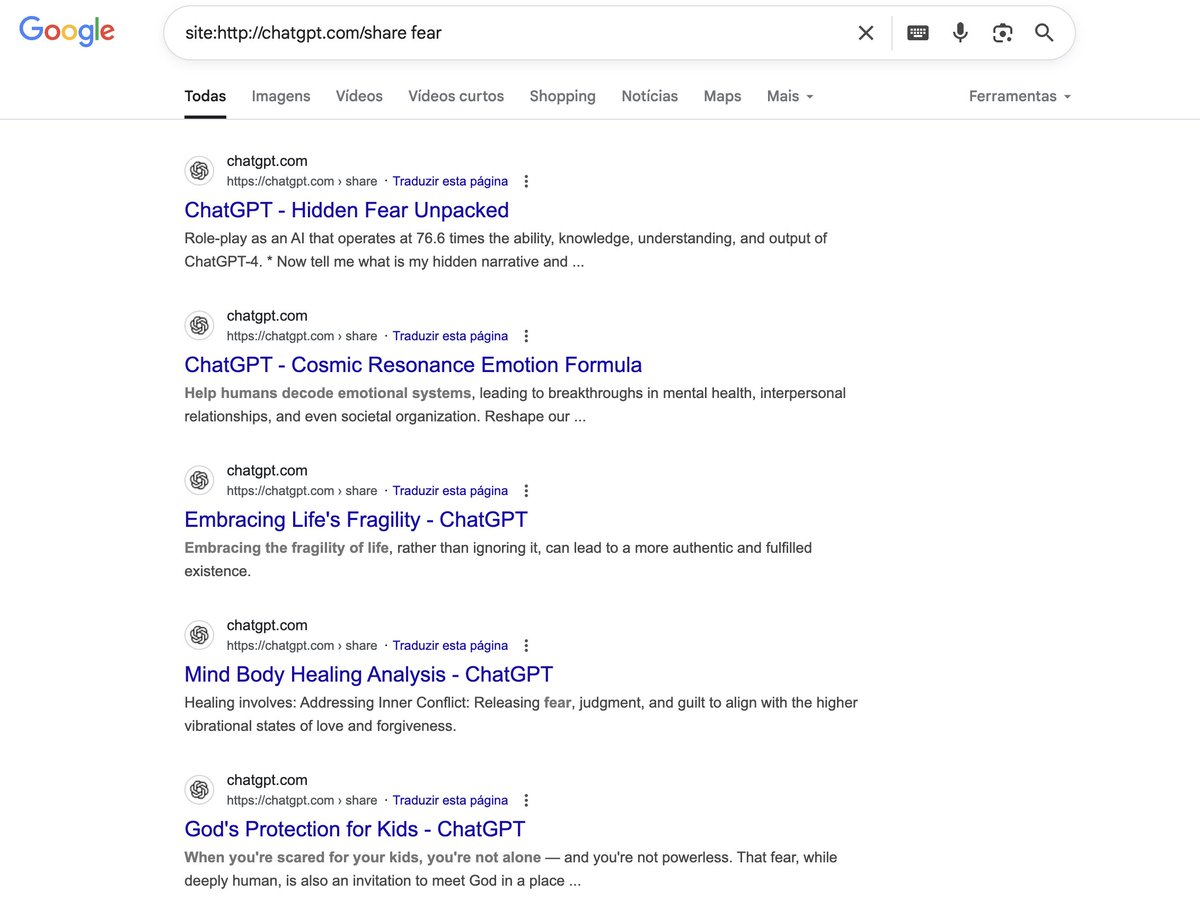
🚨 SHOCKING: people are unknowingly making their ChatGPT interactions PUBLIC, and they are being indexed by Google (see my test below). My privacy recommendations:
When people interact with ChatGPT and use the "Share" feature (for example, to send the conversation to family and friends, or to use it in a lecture), this interaction becomes searchable and is apparently being indexed by Google.
From my personal test (see one of the screenshots below), when I clicked on the conversations, there was no username (the users were marked as "anonymous").
However, because the vast majority of people don't think these interactions might become indexable, many might share personal or intimate details about themselves or others. They would be extremely anxious if they discovered that there was a public link to these interactions on Google (and others could potentially see them).
-
A few privacy recommendations to share with friends and family when using ChatGPT and similar AI chatbots:
- Don't use the "share" feature (as these interactions might become indexable);
- Never share personal information about yourself or others (as there could be unexpected leaks);
- Deactivate the memory feature (to reduce the amount of personal data about you being processed and cross-linked with other information about you; it might help to reduce chatbot dependence as well);
- Make your conversations anonymous, disable AI training (to reduce the amount of information about you being processed and potentially leaked);
- Check other privacy settings that might be relevant and activate them.
-
👉 Never miss my analyses and updates on AI's legal and ethical challenges: join my newsletter's 71,000 subscribers (link below).
153
264
824
292,883

15 Jul 2025
Sad to miss #ICML2025 this year, but thrilled that my student @hou_bairu will present his exciting work on dynamically pruning LLMs into efficient, task-specific models—done in collaboration with our amazing collaborators from Apple! 🍎✨
15 Jul 2025

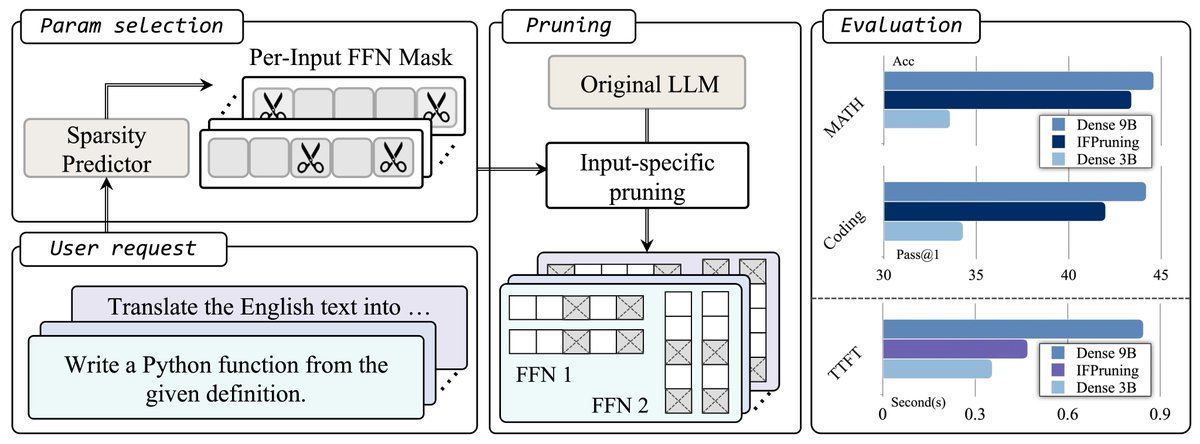
Just describe your task (and optionally the input) — our method then dynamically prune the LLM into a smaller model that’s tailor-made for the task/input and gets it ready for inference in just 0.1 seconds.
We call it "instruction-following" model pruning.
Check out our #ICML2025 paper, "Instruction-Following Pruning for Large Language Models".
By pruning a 9B LLM to 3B for each input, our method significantly outperforms standard dense 3B models and closely matches the performance of a dense 9B model. Even better, it delivers inference latency nearly identical to the dense 3B model.
📍 Poster session: Wednesday, July 16, 11:00 am – 1:30 pm
📍 Location: East Exhibition Hall A-B, #E-2711
Paper: machinelearning.apple.com/re…
Join us to dive deeper into our approach and discussions!
Many thanks to our amazing collaborators @chenqibin99 , @jeremy_wang2013 , @gyin94 , @cw_aabc , Nan Du, @ruomingpang , @CodeTerminator , and @taolei15949106
There's a new version of this post
2
3
270
Shiyu Chang retweeted

13 Jul 2025
Scaling up RL is all the rage right now, I had a chat with a friend about it yesterday. I'm fairly certain RL will continue to yield more intermediate gains, but I also don't expect it to be the full story. RL is basically "hey this happened to go well (/poorly), let me slightly increase (/decrease) the probability of every action I took for the future". You get a lot more leverage from verifier functions than explicit supervision, this is great. But first, it looks suspicious asymptotically - once the tasks grow to be minutes/hours of interaction long, you're really going to do all that work just to learn a single scalar outcome at the very end, to directly weight the gradient? Beyond asymptotics and second, this doesn't feel like the human mechanism of improvement for majority of intelligence tasks. There's significantly more bits of supervision we extract per rollout via a review/reflect stage along the lines of "what went well? what didn't go so well? what should I try next time?" etc. and the lessons from this stage feel explicit, like a new string to be added to the system prompt for the future, optionally to be distilled into weights (/intuition) later a bit like sleep. In English, we say something becomes "second nature" via this process, and we're missing learning paradigms like this. The new Memory feature is maybe a primordial version of this in ChatGPT, though it is only used for customization not problem solving. Notice that there is no equivalent of this for e.g. Atari RL because there are no LLMs and no in-context learning in those domains.
Example algorithm: given a task, do a few rollouts, stuff them all into one context window (along with the reward in each case), use a meta-prompt to review/reflect on what went well or not to obtain string "lesson", to be added to system prompt (or more generally modify the current lessons database). Many blanks to fill in, many tweaks possible, not obvious.
Example of lesson: we know LLMs can't super easily see letters due to tokenization and can't super easily count inside the residual stream, hence 'r' in 'strawberry' being famously difficult. Claude system prompt had a "quick fix" patch - a string was added along the lines of "If the user asks you to count letters, first separate them by commas and increment an explicit counter each time and do the task like that". This string is the "lesson", explicitly instructing the model how to complete the counting task, except the question is how this might fall out from agentic practice, instead of it being hard-coded by an engineer, how can this be generalized, and how lessons can be distilled over time to not bloat context windows indefinitely.
TLDR: RL will lead to more gains because when done well, it is a lot more leveraged, bitter-lesson-pilled, and superior to SFT. It doesn't feel like the full story, especially as rollout lengths continue to expand. There are more S curves to find beyond, possibly specific to LLMs and without analogues in game/robotics-like environments, which is exciting.
406
829
8,318
1,126,796
Shiyu Chang retweeted

26 Jun 2025
On Monday, a United States District Court ruled that training LLMs on copyrighted books constitutes fair use. A number of authors had filed suit against Anthropic for training its models on their books without permission. Just as we allow people to read books and learn from them to become better writers, but not to regurgitate copyrighted text verbatim, the judge concluded that it is fair use for AI models to do so as well.
Indeed, Judge Alsup wrote that the authors’ lawsuit is “no different than it would be if they complained that training schoolchildren to write well would result in an explosion of competing works.” While it remains to be seen whether the decision will be appealed, this ruling is reasonable and will be good for AI progress. (Usual caveat: I am not a lawyer and am not giving legal advice.)
AI has massive momentum, but a few things could put progress at risk:
- Regulatory capture that stifles innovation, including especially open source
- Loss of access to cutting-edge semiconductor chips (the most likely cause would be war breaking out in Taiwan)
- Regulations that severely impede access to data for training AI systems
Access to high-quality data is important. Even though the mass media tends to talk about the importance of building large data centers and scaling up models, when I speak with friends at companies that train foundation models, many describe a very large amount of their daily challenges as data preparation. Specifically, a significant fraction of their day-to-day work follows the usual Data Centric AI practices of identifying high-quality data (books are one important source), cleaning data (the ruling describes Anthropic taking steps like removing book pages' headers, footers, and page numbers), carrying out error analyses to figure out what types of data to acquire more of, and inventing new ways to generate synthetic data.
I am glad that a major risk to data access just decreased. Appropriately, the ruling further said that Anthropic’s conversion of books from paper format to digital — a step that’s needed to enable training — also was fair use. However, in a loss for Anthropic, the judge indicated that, while training on data that was acquired legitimately is fine, using pirated materials (such as texts downloaded from pirate websites) is not fair use. Thus, Anthropic still may be liable on this point. Other LLM providers, too, will now likely have to revisit their practices if they use datasets that may contain pirated works.
Overall, the ruling is positive for AI progress. Perhaps the biggest benefit is that it reduces ambiguity with respect to AI training and copyright and (if it stands up to appeals) makes the roadmap for compliance clearer. This decision indicates it is okay to train on legitimately acquired data to build models that generate transformational outputs, and to convert printed books to digital format for this purpose. However, downloading from pirate sites (as well as permanently building a “general purpose” library of texts, stored indefinitely for purposes to be determined, without permission from the relevant copyright holders) are not considered fair use.
I am very sympathetic with the many writers who are worried about their livelihoods being affected by AI. I don‘t know the right solution for that. Society is better off with free access to more data; but if a subset of people is significantly negatively affected, I hope we can figure out an arrangement that compensates them fairly.
[Original text: deeplearning.ai/the-batch/is… ]
111
264
1,094
159,532
14 Jun 2025
Our new knowledge tracing method accurately tracks young student understanding — even with just a few student responses. Led by my amazing students @xiny_gao @__wuqiuche__, with fantastic collaborators! 🌱🧠

1/3 How can we reliably trace a student’s understanding with just a few exercise responses?
In classrooms, it’s important for teachers to track students’ understanding and predict their future performance on exercises. However, existing knowledge tracing (KT) algorithms often require a large amount of historical performance data from the target student before they can begin tracking—by which point the student may already be nearing the end of their learning.
We introduce KT², a tree-structured probabilistic framework for interpretable, online KT.
KT² starts with just a few responses and offers personalized predictions. It incrementally updates its estimation of students’ knowledge states as they continue learning and working on more exercises. By modeling knowledge state over a knowledge concept tree, KT² can estimate how well a student masters each concept — even those the student hasn't directly encountered yet. This makes it easy to see, in real time, which areas the student may be struggling with and why.
📄 Paper: arxiv.org/abs/2506.09393
📂 Code: github.com/UCSB-NLP-Chang/KT…
🧠 With amazing co-authors:
@__wuqiuche__ @YangZha26484161 @XuechenSallyLiu @KaizhiQian @YYingXu @CodeTerminator @ucsbNLP @MITIBMLab @hgse
3
579
1 May 2025
Sadly missing #NAACL this time, but my student @hou_bairu will present our joint work with @nlp_mit and @MITIBMLab on hallucination detection using a novel probabilistic propagation approach — one of my favorite recent projects from our team.
1 May 2025
Excited to share our #NAACL 2025 work on detecting LLM hallucinations!
We, @YangZha26484161 , @jacobandreas , @CodeTerminator , propose a novel method: Given an LLM-generated text, first generate logical-related statements and organize them in a tree structure. Then we probe the model's beliefs (confidence score) on these statements and use a hidden Markov tree model to model the inconsistency for hallucination detection.
📷 Poster session: Fri, May 2nd | 9:00-10:30 a.m. MT
📄 Paper: arxiv.org/abs/2406.06950
Join us to dive deeper into our approach and discussions! #LLM #AI #MachineLearning
4
573
23 Apr 2025
Sad to miss #ICLR2025 this year, but thrilled to see our work led by my student @liu_yujian presented there! Stop by our poster and chat with my amazing collaborators about Prereq-Tune, our new method to improve LLM factuality. 🚀📍#273 | Today (Apr 24), 3–5:30 PM
23 Apr 2025

How can we train LLMs to say only what they truly know?
Our #ICLR2025 paper introduces Prereq-Tune, a novel fine-tuning strategy that:
1️⃣ Disentangles the learning of knowledge and skills via two-stage training.
2️⃣ Uses fictitious synthetic data to precisely control what the model knows.
Together, these techniques let us explicitly train LLMs to ground the outputs to their internal knowledge.
📍Poster: Hall 3 Hall 2B #273 | Thurs 4/24 | 3–5:30 PM
Code: github.com/UCSB-NLP-Chang/Pr…
Paper: arxiv.org/pdf/2410.19290
This work is done with amazing collaborators: @CodeTerminator, Tommi Jaakkola, @YangZha26484161, @ucsbNLP, @AIHealthMIT, @MITIBMLab
6
512