
I am an author of @SpeechBrain1. I love cats and justice and games and stuff.
Joined November 2015
- Tweets 226
- Following 230
- Followers 168
- Likes 1,268
14 Photos and videos











Peter Plantinga retweeted

13 Jun 2025
🚀 We're excited to announce our latest work: "Discrete Audio Tokens: More Than a Survey!"
It presents a comprehensive survey and benchmark of audio tokenizers across speech, music, and general audio.
preprint: arxiv.org/pdf/2506.10274
website: poonehmousavi.github.io/date…
1
14
35
3,592

7 Jan 2025
37
9 Dec 2024
Proud of this work published a few days ago at SLT 2024 on continual learning for end to end ASR. Turns out changing the CL paradigm to parallel training on different tasks and merging these experts can reduce the forgetting rate to as low as 0.4%! poonehmousavi.github.io/asse…
1
69
Peter Plantinga retweeted

22 Nov 2024
🌟To all #MachineLearning researchers:
Join us in #Istanbul for the 35th #IEEE MLSP 2025
📅 Aug 31–Sept 3, 2025
We’re working hard to make this a memorable event in one of the world's most beautiful cities.
2025.ieeemlsp.org/en/
#DeepLearning #AI #NeuralNetworks #Research

ALT https://2025.ieeemlsp.org/en/
12
26
1,789
Peter Plantinga retweeted
18 Nov 2024
Join us for the Conversational AI Reading Group! 📚 We meet every Thursday, 11-12 AM EST, to discuss the latest advancements in conversational AI, multimodal models, and speech processing. Everyone is welcome! More info: poonehmousavi.github.io/rg.h… & follow us on Twitter: @convAI2024
6
12
731
Peter Plantinga retweeted
11 Nov 2024
Fine-tuning #LLMs on domain-specific data doesn’t always improve performance, a challenge we call the "Adaptation Odyssey".
Why does this happen? Our new #EMNLP2024 paper led by @firatoncell discusses this issue.
📄 arxiv.org/pdf/2410.05581
#AI #NLP #DeepLearning

ALT https://arxiv.org/pdf/2410.05581
1
23
49
4,518
Peter Plantinga retweeted
5 Nov 2024
🧠#SpeechBrain-MOABB, our #opensource #EEG benchmark, is designed to test #DeepLearning models across tasks with a robust protocol for fair comparison!
📄 Our latest #paper: sciencedirect.com/science/ar…
(just accepted in Neural Networks!)
💻 Code: github.com/speechbrain/bench…
#AI
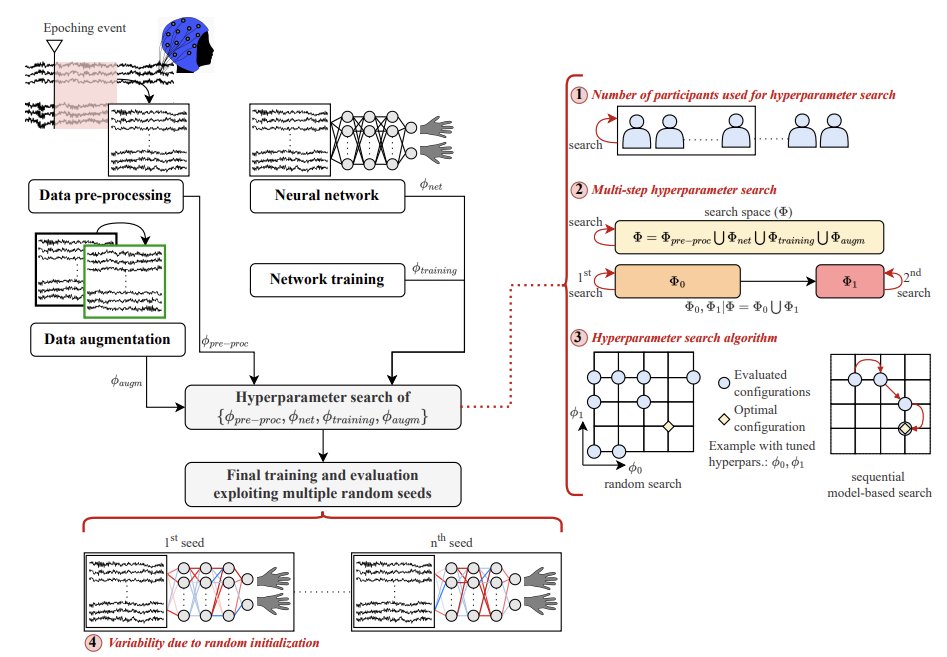
ALT Scheme of the proposed decoding protocol and of the performed experiments (marked with red)
10
40
2,086
30 Oct 2024
SpeechBrain version 1.0.2 is now out! My personal contribution is a clean adapters interface that allows custom adapters or integration with PEFT layers, your choice. You can see the tutorial here:
speechbrain.readthedocs.io/e…
2
9
267
2 Sep 2024
We just released v1.0.1 of SpeechBrain with some cool updates to Whisper integration: various tasks supported, fine-tuning fixes, performance improvements, and more!
1
1
81
Peter Plantinga retweeted
2 Sep 2024
📢 I'll be presenting our paper "How Should We Extract Discrete Audio Tokens from Self-Supervised Models?" at InterSpeech! 🎙️
Meet us at the Speech Processing Using Discrete Speech Units, Oral Session on Sep 3, 16:20.
🔗 Paper: arxiv.org/abs/2406.10735
#INTERSPEECH2024
9
20
4,214
Peter Plantinga retweeted

9 Jul 2024
I am happy to announce that "Listenable Maps for Audio Classifiers" has been accepted at #icml2024 as an oral!
Check out
👨💻 code in @Speechbrain1 tinyurl.com/lmac-code
🖥️ website tinyurl.com/lmac2
📖 paper: tinyurl.com/lmac5
#AI #deeplearning #audio #explainableAI
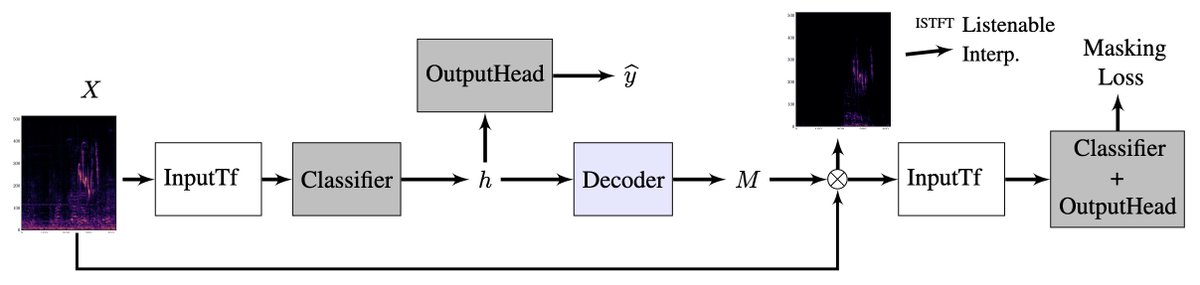
ALT L-MAC is a posthoc explanation method that helps us to hear why an audio classifier makes its decisions. It takes the hidden representations of a pretrained classifier and feeds them to a decoder to predict saliency maps.
6
14
49
9,123
Peter Plantinga retweeted

9 Apr 2024
We will have XAI-SA: Explainable Machine Learning for Speech and Audio, next week at ICASSP 2024. The date is April 15.
You can sign-up for it here to receive more information for it:
forms.gle/VPBP3Mojq3EwqwU77
Workshop website for the schedule:
xai-sa-workshop.github.io/
16
27
1,961
28 Feb 2024
We worked hard on this one!
28 Feb 2024

Exciting news! 🎉 #SpeechBrain 1.0 is out with tons of thrilling advancements.
Our #OpenSource toolkit now features 200 recipes and 100 pretrained models on #HuggingFace for diverse #ConversationalAI tasks.
🌐 Website: speechbrain.github.io/
💻 Repo: github.com/speechbrain/speec…

ALT Visit our website: https://speechbrain.github.io/
78
12 Feb 2024
Bodyqueer: a Term For All People With Non-normative Bodies open.substack.com/pub/peterp…
19
Peter Plantinga retweeted

10 Oct 2023
For a deep, thoughtful discussion of proliferation, regulation, and why open source is the better—and safer—path to take with AI, I HIGHLY recommend this piece by @jeremyphoward. I learned much from it and encourage others to as well: fast.ai/posts/2023-11-07-dis…
9 Oct 2023

How in the world Effective Altruists went from supporting data-driven charitable impact like mosquito nets to organizing protests against open source is beyond me. This is no long altruism—this is ideological posturing that hurts, not helps, society. spectrum.ieee.org/meta-ai
4
8
36
14,471
Peter Plantinga retweeted

11 Oct 2023
Fresh paper out #EMNLP2023
LLMs excel in zero-shot text-to-SQL but still benefit greatly from in-domain demonstrations. This work is driven by two questions: (1) What are the key factors within in-domain examples? (2) Can we harness these benefits without in-domain annotations?

7 Oct 2023

Happy to share the last work in my PhD is accepted to #EMNLP2023 findings. Many thanks to my advisor @EricFos We propose a new framework to select text-to-SQL demonstration examples from out-of-domain data and synthetic in-domain data. The paper will be released next week!
1
7
31
6,897
Peter Plantinga retweeted

25 Aug 2023
Excited to present at the SpeechBrain online summit on Monday 28th Aug
I'll be joined by @shinjiw_at_cmu, @functiontelechym, Daniel Povey, and Zhaoheng Ni for a panel discussion on open-source speech
It's not too late to register if you haven't already: speechbrain.github.io/sb_sum…

3
18
1,298
Peter Plantinga retweeted
7 Jun 2023
Excited to share the news about a new internship opportunity at @Mila_Quebec, where you can contribute to @SpeechBrain1!
We're seeking students skilled in RNN-T. If you have relevant experience, please apply at speechbrainproject@gmail.com.
#ICASSP2023 #DeepLearning #AI

ALT https://speechbrain.github.io/
18
52
7,603
17 May 2023
Just got to experience my first bona-fide email storm, and laughing at every minute of it
1
64