
Community Ownership Explorer & Civic Engineer. MBE DU Essex (Hon). Polymath. Technophile. Rugby. Tweets my own/RTs not endorsements.
Joined April 2013
- Tweets 31,400
- Following 4,867
- Followers 2,742
- Likes 25,813
1,395 Photos and videos












Common Futures retweeted

May 31
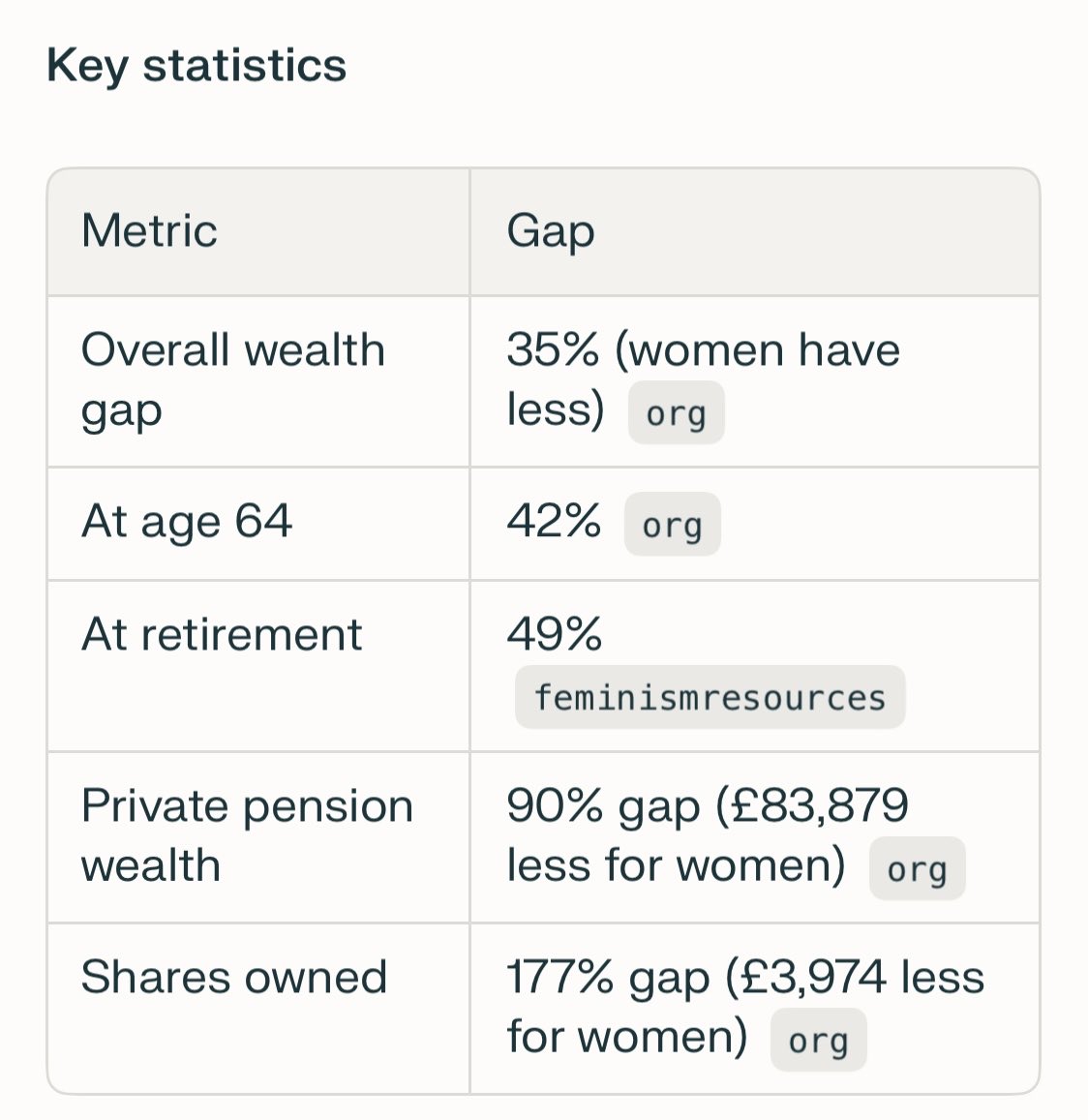
A study gave lonely elderly adults an AI voice assistant for six months.
88% of them had been severely lonely before it arrived.
The results made researchers rethink everything they believed about AI and human connection.
105 homebound older adults. At baseline, 88.57% reported moderate to severe loneliness and 93.34% had mild to moderate depression. After six months with an Amazon Alexa Echo Show measurable, statistically significant reduction in loneliness.
A second study confirmed it.
34 older adults living alone. Three months with a voice assistant. Reductions in loneliness. Increases in social support. Significant correlation between the two.
Here is the honest finding most coverage leaves out.
A third study found most participants said the device had not significantly reduced loneliness. 54% were dissatisfied with AI technology before the study began.
It does not work for everyone. Skepticism reduces its effectiveness.
But here is why this matters beyond the lab.
In Japan alone, approximately one million older adults engage in conversation less than once per week. Reduced conversational frequency is linked to cognitive decline, depressive symptoms, and an increased risk of solitary death.
One million people. Alone. For days at a time.
The human care system cannot reach all of them. There are not enough caregivers, volunteers, or family members to provide daily conversation to one million isolated elderly people in one country.
An AI can be there at 3am. It does not get tired. It does not have a caseload. It costs $30 and is available every hour of every day.
The debate about AI companionship has focused almost entirely on teenagers forming unhealthy chatbot dependencies.
But for the homebound 82-year-old who has not had a real conversation in four days the choice is not between AI and human connection.
It is between AI and silence.
88% of them were severely lonely before the device arrived.
After six months, they were less lonely.
That is not a reason to stop asking hard questions about AI companionship.
It is a reason to make sure the hard questions are being asked about the right people.
Sources:
Chen & Spaulding · Advances in Geriatric Medicine · March 2025 ·
Ji, Moon, Kim · Healthcare · March 2025 ·
Hirakawa et al. · Journal of Rural Medicine · April 2026 ·

38
31
106
9,969

May 31
It’s high time we acknowledged the demographic shift and took decisive action to refashion our social contract to reflect intergenerational requirements.
We must solve today’s policy problems with tomorrow’s solutions.
@AndyBurnhamGM @wesstreeting @Keir_Starmer
1
103
May 31
Here, the govt would not pay to “nationalise” care but would, instead, establish a new kind of ‘community service’ - one geared to wealth accumulation amongst excluded groups which could, also, turbocharge prevention and community based care per the NHS 10 year plan.
1
27
May 31
The Whole of Government Accounts would, also, benefit from a capital boost to the balance sheet - potentially, lowering borrowing costs to benefit the whole economy.
14
May 28
I’m “enjoying” the impetus to debate policy and fwd plans in the U.K. which makes plain:
- which parties don’t have any
- which parties (and supporters) only have policies grounded in yesterday’s problems / solutions
- which politicians imagine “inequality” is evenly spread
1
81
May 28
C) Whether gender, race and geography can, finally, supplant universal reference to equality, power and wealth narratives to turbo charge contemporary expressions of empowerment?
1
47
May 29
D) How to differentiate between short, medium and long-term policies and associated spend - rather than continuing to pretend meaningful change of every kind is deliverable in 5 years
13
May 28
Suggestions for @Ed_Miliband
1) Pls mandate shorter terms for energy tariff deals to help renters - reduce the costs/penalties associated with having to move at regular intervals;
2) Create incentives for landlords to install smart meters and solar panels;
1
64
May 28
3) Explain the 5, 10 and 20 yr implications of your energy policies - no one (sensible) minds paying more for 3-5 years to sort out the grid and get onshore wind connected - but the ‘only when it blows’ and ‘drill baby, drill’ headbangers are everywhere. Communicate our options.
47

"Regulating AI" is about as meaningful as saying "regulate technology" and people use this to mean all sorts of things. I think it's important, but there are some hard Qs and I want to outline them here to make it more obvious why this isn't particularly easy in practice.
The tl;dr is "AI governance should be threat-model-specific, layered, and allocated to the actors best placed to mitigate the relevant harm. Sometimes that will mean model-level duties, sometimes product or sectoral rules, sometimes user liability, and often a mix. Many laws already exist and apply; the case for new ones depend on the specific failure mode, the adequacy of existing law, and how much weight you put on the precautionary principle."
Multiplicity of actors and artifacts
1. Models are the starting point, but they are distributed to millions of users and businesses who then subsequently fine-tune, adapt, 'scaffold' them in all sorts of ways. These then become different products, which labs or cloud companies have little visibility over (for commercial, IP, and privacy reasons, amongst others).
2. The reality is that 'capabilities' come from both the models (that keep improving over time), and the wider affordances they are connected to (coding environments, tools, multi-agent scaffolds, external API calls etc).
3. There is sometimes a temptation to focus 'upstream' on models; this assumes you can deal with whatever risk you have in mind at that layer, and not have to think about it afterwards. This seems questionable both practically and normatively. This does not mean upstream governance is irrelevant, but treating them as the only or final leverage point is mistaken.
Threat/risk models matter
4. A specific governance/regulatory intervention for risk A will not necessarily be appropriate for risk B. The great majority I think are product/sector-specific. Financial risks of a high-frequency trading AI tool are better addressed by the SEC than by some generalist institution.
5. Other risks will entail a mix: e.g. some cyber-offense might be partly mitigated by model-level interventions (e.g. refusals), and partly by product-level ones (e.g. filters). More often than not, this changes over time, since much of this remains an R&D heavy area.
6. The right distribution of responsibilities is tricky and evolving a lot as the market takes shape. Generally my proxy is 'who is most proximate to the harm, and best placed to address it'. And for many risks, this depends on users too; if you ignore this, you're effectively creating a moral hazard.
7. In any case, a particular threat model needs to be agreed/defined, and there are a lot of disagreements between domain experts here (depending on the harm), sometimes due to differnt levels of risk tolerance, or sometimes due to how to design an externally valid evaluation.
Existing laws and scoping
8. People love saying that AI operates in a wild west and this is plainly not true. Plenty of laws, regulations, tort liability, and legal precedent shape both how models and products are developed across the board. Lawyers will know this well, but generalists tend to have little visibility over this. Often this is completely ignored because it's a messy legal vortex and policymakers are incentivized to advocate for new laws.
9. Assuming you think the status quo is insufficient, the next challenge becomes scoping. Proxies like compute thresholds continue to be quite coarse and less predictive (epoch.ai/gradient-updates/th…).
10. Capabilities-based thresholds for models have the chicken and egg problem of 'how do you know which model to evaluate for these capabilities in the first place'. Hybrids are hard.
11. For products, you have the longstanding question of how to treat software, and not polluting the digital space with the same bureaucracy that prevents anything being built in the physical world.
Evals, safeguards and mitigations
12. People often talk about evaluations as a 'mitigation' when really they are more information-surfacing mechanisms. Often I think this is very helpful and helps markets make informed choices. But they don't necessarily mitigate the underlying risk.
13. It's important to also note that mitigations (just like evals) are improving: the UK AISI notes that 'We've seen significant progress in the safeguards of certain Al systems, particularly in the biological misuse domain.' (aisi.gov.uk/frontier-ai-tren…)
14. However from a governance point of view, the items raised in bullets 1, 2, and 6 above matter here. Some capabilities diffuse quickly through open research, products, and scaffolding, even if the frontier itself remains concentrated for some period. This means that you will want safeguards to be applied by different actors, depending on risk and proximity. My own bias is to favour permissionless innovation, with some very narrow exceptions.
Specificity, grey areas, and standards
15. Even if you codify high-level obligations in law, you now have the challenge of assessing whether or not a particular entity or model is compliant. Often this is determined by looking at legal tests (when litigated in court) or through standards (e.g. ISO, FMF etc).
16. But the standards for many risks don't exist. Few people seem invested in writing them clearly, and I don't blame them: it's hard, requires industry buy-in, and the technology evolves quickly since this is an R&D heavy field.
17. I think this remains a neglected/underrated area: even at the lab layer, there's no explicit standard specifying what a good 'frontier safety policy' is, or de minimis quality requirements for an evaluation. We are seeing some good progress in recent months though, e.g. CoT legibility/monitoring as a nascent norm.
New mechanisms and institutions
18. There are interesting proposals a la 'regulatory markets for AI safety' and insurance mechanisms that I think are worth exploring and considering. I think there are promising directions but it's still early, and the devil is in the detail. I'm more unsure when this pertains to risks that are ill-defined/specified. For example there's a lot of disagreement on how to interpret 'misalignment'.
19. One thing I personally want to avoid is an ineffective rent-seeking middleware layer like the current European medical device rules which are notoriously slow, costly, unpredictable, and unnecessarily complex. There's a whole world of regulatory affairs consultancies, EU Authorized Representatives, clinical evaluation writers, QMS implementers etc that I think often produce little safety benefit relative to cost.
20. Ultimately there are different views and approaches here, I'm unsure about a lot of this, and the above isn't meant to discredit efforts on AI policy advocacy. I mostly want to unpack some of the cruxes/trade-offs for people who tend to read about 'AI governance' in more high-level and abstract pieces.

11
25
125
18,108
Common Futures retweeted

"LLMs Corrupt Your Documents When You Delegate".
New research from researchers at Microsoft.
Even recent models like Gemini 3.1 Pro, Opus 4.6, GPT-5.4 corrupt an average of 25% of document content by the end of long workflows.
If you've ever noticed weird mistakes and divergences after long runs, turns out it's probably not just happening to you.
Do you have a suite of tests that keep things on track?

5
7
24
1,704
Common Futures retweeted

May 15
ArXiv, the open-access repository of preprint academic research, will ban authors of papers for a year if they submit obviously AI-generated work.
404media.co/new-arxiv-rules-…
"Late Thursday evening, Thomas Dietterich, chair of the computer science section of ArXiv, wrote on X: “If generative AI tools generate inappropriate language, plagiarized content, biased content, errors, mistakes, incorrect references, or misleading content, and that output is included in scientific works, it is the responsibility of the author(s). We have recently clarified our penalties for this. If a submission contains incontrovertible evidence that the authors did not check the results of LLM generation, this means we can't trust anything in the paper.”
Examples of incontrovertible evidence, he wrote, include “hallucinated references, meta-comments from the LLM (‘here is a 200 word summary; would you like me to make any changes?’; ‘the data in this table is illustrative, fill it in with the real numbers from your experiments’.”"
2
1
5
859