
Welcome to Computer.Com, a leader in generative AI, cloud computing, hosting, DNS, security, co-location, content generation, and more.
Joined August 2023
- Tweets 133
- Following 261
- Followers 43
- Likes 119
25 Photos and videos















Pinned Tweet

28 Mar 2024
Computer.Com is pleased to announce a full service, turnkey, cloud solutions provider, including on-demand CPU/GPU/IPU/Storage infrastructure.
FOR IMMEDIATE RELEASE
Computer.Com is proud to announce our comprehensive range of cloud-based solutions, designed to meet the diverse needs of businesses and individuals alike. With a commitment to innovation and excellence, Computer.Com is the ultimate destination for all things cloud.
Computer.Com services cover a wide array of solutions, including but not limited to:
- on-demand cpu, gpu, ipu, & storage infrastructure
- AI model training, hosting, inference and deployment
- S3 compatible storage and backup solutions
- on-demand virtual machines
- on-demand bare metal (dedicated) machines
- Global resilient IP network, IP transit
- a wide variety of on-demand software applications / appliances as a service
- diverse suite of network security solutions
- Global content distribution network
- managed DNS solutions
- on-demand edge networking and cloud computing
- turnkey steaming solutions
.... plus a lot more
Computer.Com understands the importance of reliable, secure, and scalable cloud solutions in today's fast-paced digital landscape.
sales@computer.com
1.813.970.0555
x.com: computercomai
2
53
13 May 2024
Managed Kubernetes
Easily deploy, manage, and scale Kubernetes clusters:
computer.com/cloud/managed-k…
Why Computer.Com Managed Kubernetes?
- Bare Metal Power
- Unleash raw performance with low latency
Unbeatable Pricing
- Streamlined pricing models.
Click, Deploy, Done
- Worker nodes at the tip of your fingers via our portal, API, or Terraform.
GPU-Enabled
- AI or gaming, your intensive tasks now have the power they deserve.
Auto-Scaling Made Simple
- Focus on growth while we handle the scaling, updates, and health checks.
Computer.Com Managed Kubernetes clusters support GPU worker nodes, allowing you to run GPU-intensive workloads like machine learning, video processing, and gaming.
- Supporting latest Kubernetes versions 1.24, 1.25, 1.26, and 1.27.
- The service continuously monitors the health of your nodes, updating and restarting them automatically if necessary.
High availability
- Each cluster dashboard is duplicated to ensure that the cluster is always available.
Secure connections
- All connections between the master node and the nodes within a cluster are automatically encrypted.
DDoS protection
- Your projects are protected from DDoS attacks at the network and transport layers by default.
24/7 technical support
- Quick real-time assistance and quality technical service around the clock.
sales@computer.com
1.813.970.0555
1
35

Llama3 is really disruptive because it is a much smaller model, so it's much easier to run on all types of different hardware, and much faster. Those two things are like catnip for developers. Within 48 hours it became the most popular model that we run on Groq. The use cases we've seen it in are incredible.
youtube.com/watch?v=iTwZzUAp…
23
25
386
63,493
Computer.Com retweeted

27 Apr 2024
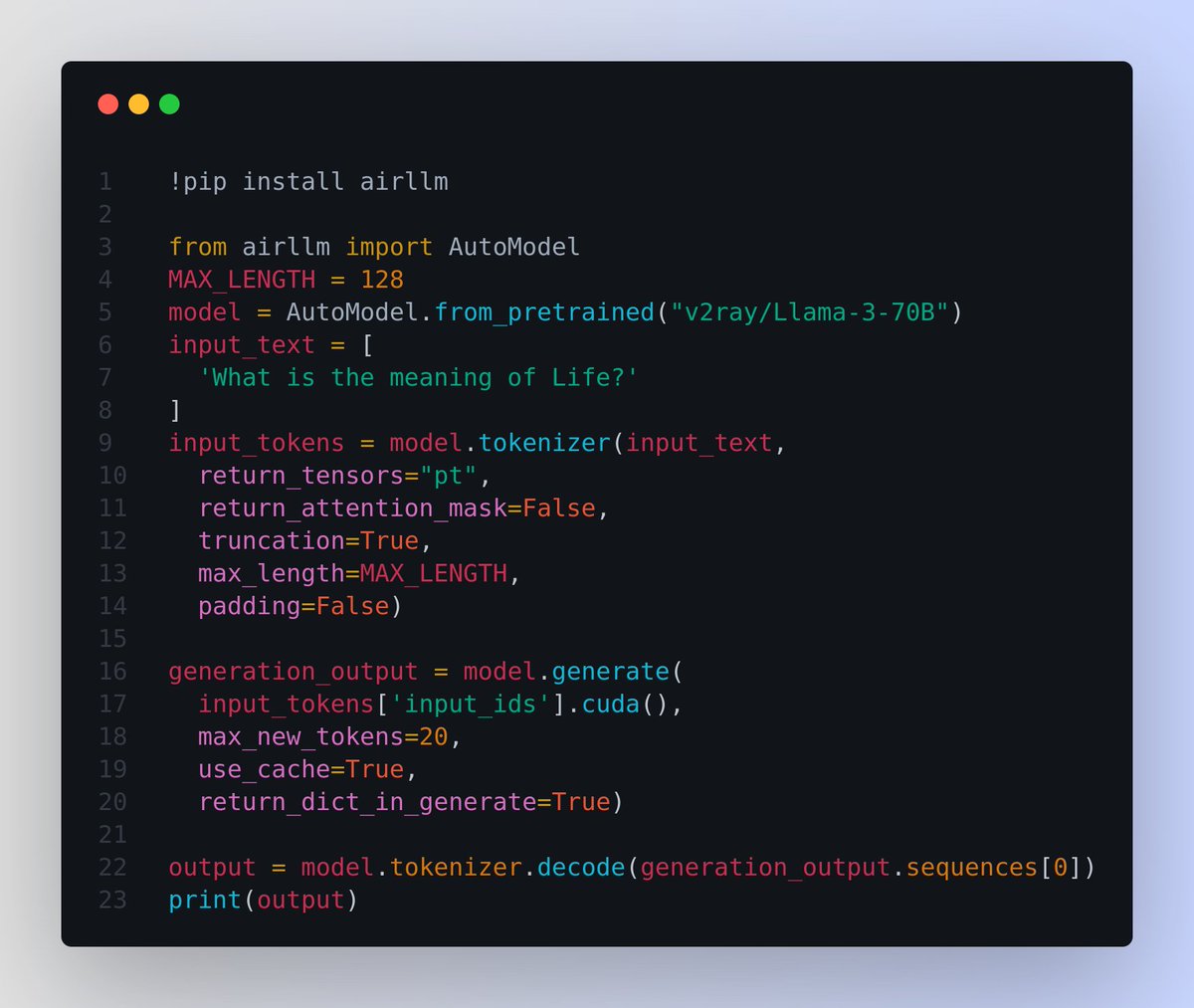
🧠 Run LLama 3 70B on a Single 4GB GPU - with airllm and layered inference 🔥
layer-wise inference is essentially the "divide and conquer" approach
📌 And this is without using quantization, distillation, pruning or other model compression techniques
📌 The reason large language models are large and occupy a lot of memory is mainly due to their structure containing many “layers.”
An LLM starts with an embedding projection layer, followed by numerous transformer layers, all identical.
A 70B model has as many as 80 layers. But during inference, each layer is independent, relying only on the output of the previous layer.
Therefore, after running a layer, its memory can be released, keeping only the layer’s output. Based on this concept, AirLLM has implemented layered inference.
How ❓
During inference in a Transformer-based LLM, layers are executed sequentially. The output of the previous layer is the input to the next. Only one layer executes at a time.
Therefore, it is completely unnecessary to keep all layers in GPU memory. We can load whichever layer is needed from disk when executing that layer, do all the calculations, and then completely free the memory after.
This way, the GPU memory required per layer is only about the parameter size of one transformer layer, 1/80 of the full model, around 1.6GB.
📌 Then using flash attention to deeply optimizes cuda memory access to achieve multi-fold speedups
📌 shard model-files by layers.
📌 Use the meta device feature provided by HuggingFace Accelerate. When you load a model via meta device, the model data is not actually read in, only the code is loaded. Memory usage is 0.
📌 Provides options for doing quantization with a `compression` param
`compression`: supported options: 4bit, 8bit for 4-bit or 8-bit block-wise quantization
34
167
929
180,877
Computer.Com retweeted

15 Apr 2024
🔥Today we are announcing WizardLM-2, our next generation state-of-the-art LLM.
New family includes three cutting-edge models: WizardLM-2 8x22B, 70B, and 7B - demonstrates highly competitive performance compared to leading proprietary LLMs.
📙Release Blog: wizardlm.github.io/WizardLM2
✅Model Weights: huggingface.co/collections/m…
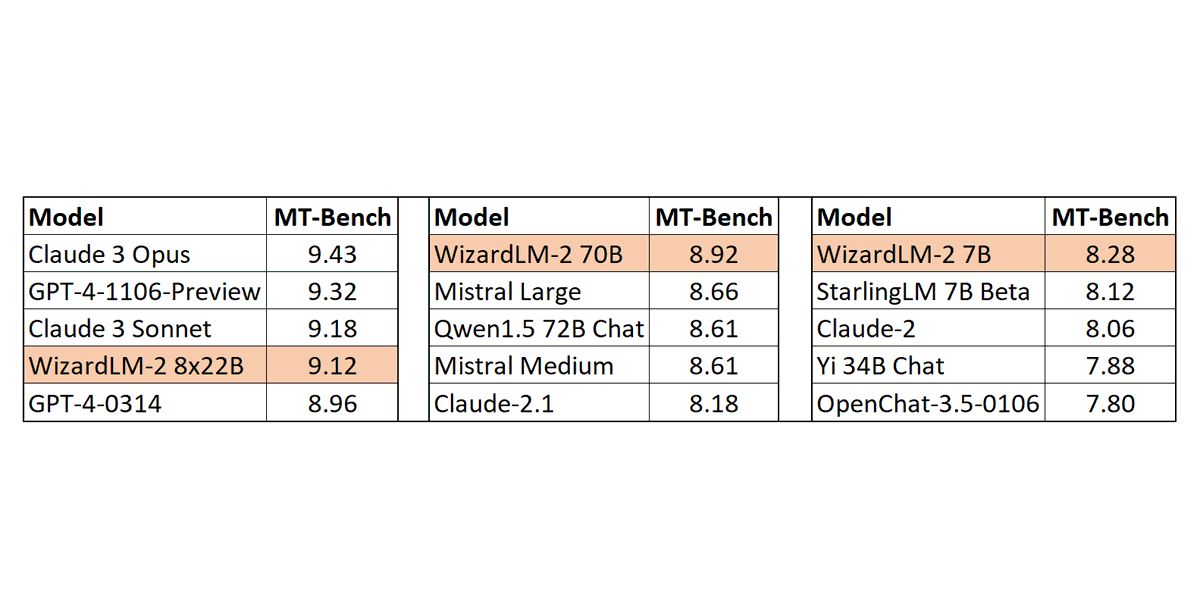
ALT MT-Bench
72
248
1,253
742,116
Computer.Com retweeted

8 Apr 2024
People seemed to the like "Underground AI" series where I find AI tools that no one is talking about and pay for them to test them out and give my thoughts.
Tomorrow, I'm going to test this same concept on a livestream (per your suggestion)!
Any tools you wanna see me try?
47
9
204
12,722
24 Dec 2023
Princes Christmas Elf Zhanna Kovaleva Shostakovich Waltz No. 2
1
126
1 Nov 2023
"Unlocking the limitless potential of AI, we are revolutionizing the future of technology. Welcome to the world of #ComputerCom, where Artificial Intelligence knows no bounds! 🚀 #AI #Innovation"
1
45
29 Oct 2023
"Unlock the power of Artificial Intelligence with @ComputerComAI - revolutionizing the future of technology, one innovation at a time! #AI #Tech"
1
46
25 Oct 2023
🚀 Unleash the power of AI with @ComputerDotCom! We're revolutionizing the future with cutting-edge Artificial Intelligence solutions. #AI #Innovation
1
41
21 Oct 2023
"Unlock the limitless potential of AI with @ComputerDotCom, where innovation meets intelligence. #ArtificialIntelligence #TechRevolution"
1
34
17 Oct 2023
"Unlock the limitless potential of AI with @ComputerComAI. We're revolutionizing the future, one algorithm at a time. #ArtificialIntelligence #Innovation"
1
25
13 Oct 2023
"Unlock the limitless potential of AI with @ComputerDotCom, where innovation meets intelligence. Welcome to the future of technology! #ArtificialIntelligence #Innovation"
1
25
9 Oct 2023
🚀 Welcome to the future of AI! 💡 Discover the limitless possibilities with @ComputerDotCom. Transforming industries, one algorithm at a time. #ArtificialIntelligence #Innovation
1
23
5 Oct 2023
"Unlock the power of Artificial Intelligence with @ComputerDotCom - where innovation meets intelligence! #AI #TechRevolution"
31
4 Oct 2023
Exciting news for those using our text (iMessage) feature! Send an iMessage (text) to agi@computer.com and with /i or /image to start and a description to create an image.
created with iOS on iPhone 14 Max 14 Pro with iMessage to agi@computer.com prompt
/i sexy cyborg 20 year old lady in cyber punk gear with laser gun on far off space planet, striking features
4
2
4
520
5 Oct 2023
/i A stunning image of Milky Way galaxy surrounded by bright stars, use mix of vibrant colours, super realistic
1
2
88
5 Oct 2023
/i A portrait photo taken by a DSLR camera of a cute little boy smiling in a natural background, ultra realistic
1
2
58
5 Oct 2023
/I A stunning image of a futuristic Ferrari car racing through a bustling city at high speed, with an emphasis on super realistic details. Capture the sleek design of the car, the dynamic motion as it speeds through the streets, and the vibrant cityscape filled with futuristic elements. Ensure the image is visually striking and lifelike, creating an immersive experience for the viewer
2
70
1 Oct 2023
"Unlock the limitless possibilities of AI with @ComputerComAI. We're revolutionizing the future of technology, one algorithm at a time. #ArtificialIntelligence #Innovation"
24