
Remember when everyone had cool hacker handles? SF6 master ranked AKI, Marissa, JP, and Dahlsim in Switzerland 🇨🇭Proud member of TOBLS
Joined September 2009
- Tweets 2,968
- Following 518
- Followers 126
- Likes 3,606
377 Photos and videos





















Mar 3
Seriously one of the best LLM explanations… :-)
Mar 3

yeah, so pretty much when you talk to an LLM (chatgpt, claude, grok) and get fancy schmancy stuff from it, youre just interfacing with a probabilistic sequence-prediction engine
each word provided to the interface (or subwords like "ing" or "un", whatever) goes through a thingy called a tokenizer. the tokenizer transforms the words (or subwords) into tokens. although if you want to get super technical the tokenizer doesnt even know words its just raw text but whatever
the tokens are stored in a big ass fuck off prebuilt in-memory dictionary for the tokenizer thingy. the words (tokens) match a 32bit integer (literally just a number). this is basically like a dictionary where "i like cats" is translated to something like "1 200 1337"
"i" = 1
" like" = 200
" cats" = 1337
those tokenized numbers are vendor specific, they dont really mean anything, but these tokens are then sent to a "embedding lookup table" where theyre actually important
once the LLM has the tokens its passed to the embedding lookup table which just does a bunch of fancy math, nerds try to make it all complicated, but its literally just arrays and indexes and stuff
in this "embedding lookup table" (im just gonna write lookup table) each token (text to number) has a bunch of numbers associated with it (weights).
" cats" = 1337
lookup table entry 1337 = a bunch of numbers
so the word cats has a bunch of numbers associated with it, each LLM is different, but usually its 768 numbers, 1024 numbers, 2048 numbers, or 4096 numbers. these numbers associated with a token are called dimensions. each LLM has different numbers of dimensions for representing words
the llm then takes these numbers and stacks them on top of each other
i like cats = 1 200 1337
1 200 1337 =
(768 numbers)
(768 numbers)
(768 numbers)
its like a height by width thingy
basically if you get fancier its a 3x768 matrix (or 1024, 2048, whatever). the more stuff you feed the LLM the larger this matrix becomes. if you feed is 9000 word essay its
9000 words-to-tokens x 768 numbers matrix
each vendor will handle the words different, 9000 words could be 9000 tokens, or 10000 tokens, or 14000 tokens
ok thanks, now you understand llm tokenization, llm lookups, and the basics of llm weights (matrixing), this doesnt cover llm lookups with position matrixes, transformers, probability output, and transforming back to text. im tired of writing

57
Crayvex retweeted

The Wolf's license plate number in "Pulp Fiction" (1994), dir. by Quentin Tarantino, "3ABM581," is an anagram. If you treat digits as letters, like in passwords ("3" as "E," "5" as "S," "8" as two "O's," and "1" as "L"), then you have "EABMSOOL," an anagram for "Esma Lobo," which is an abbreviation for Butch Coolidge's taxi driver's name, Esmarelda Villalobos.
11
11
281
55,430
Crayvex retweeted


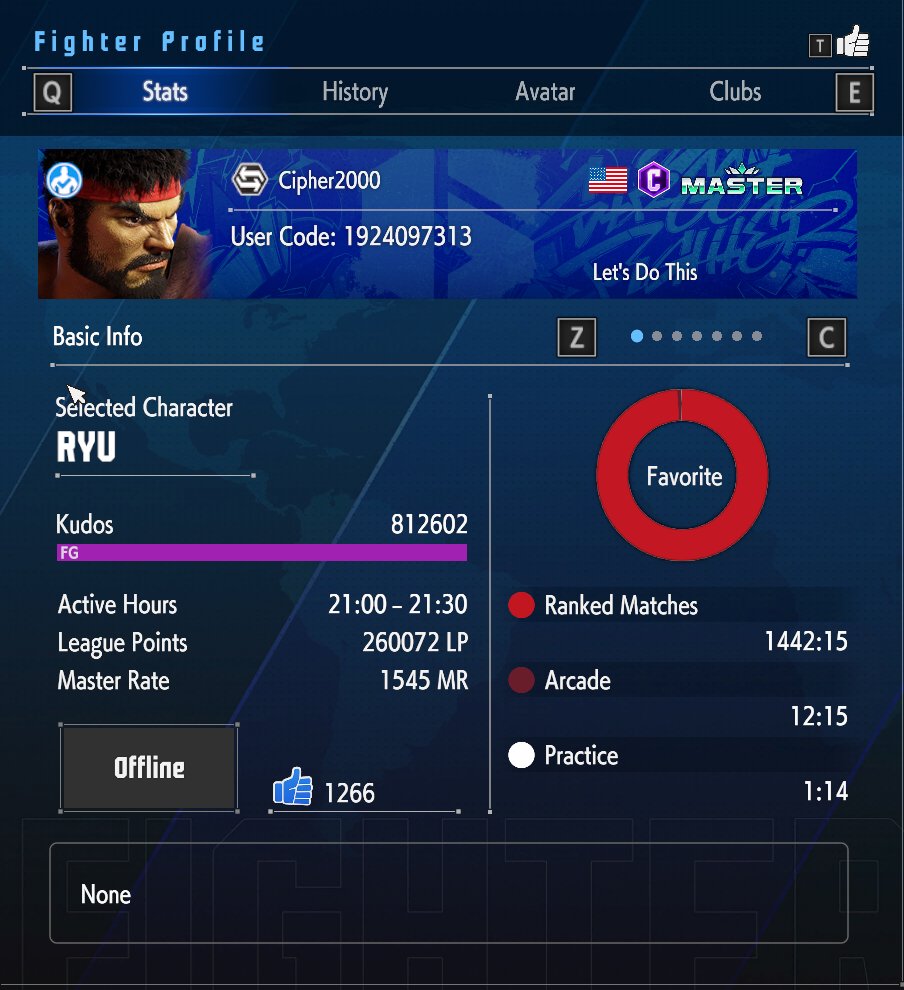

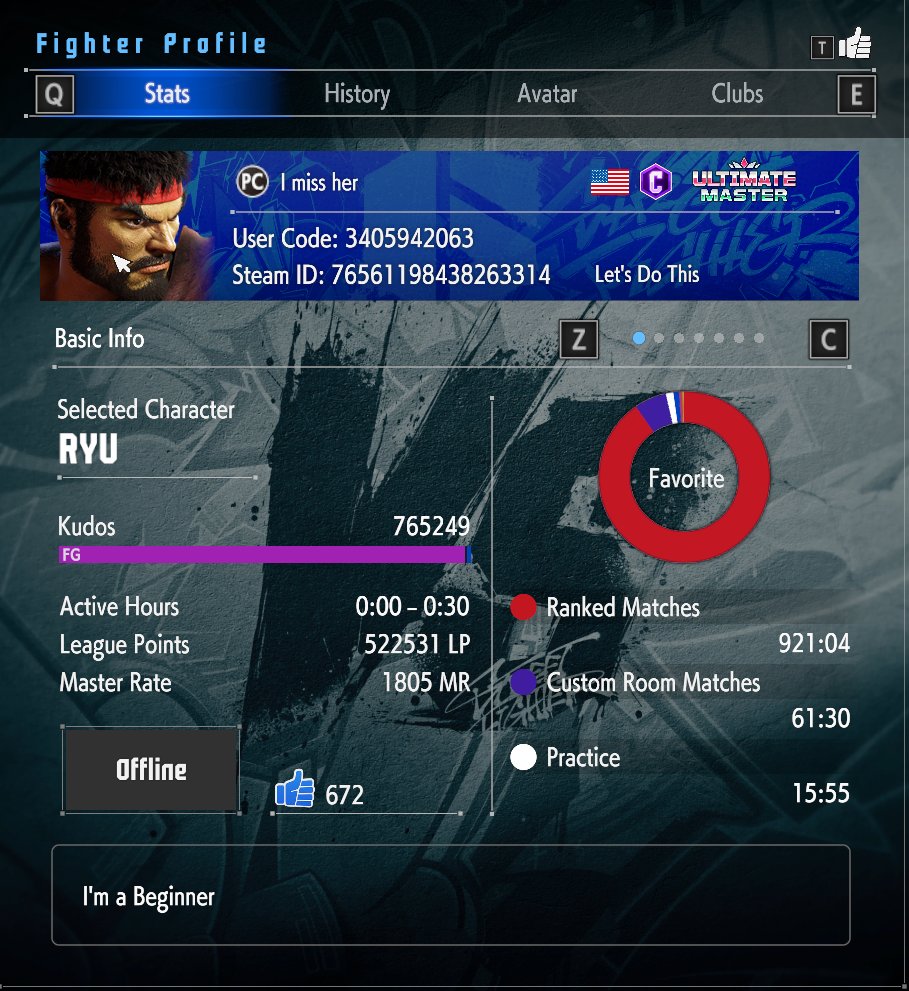
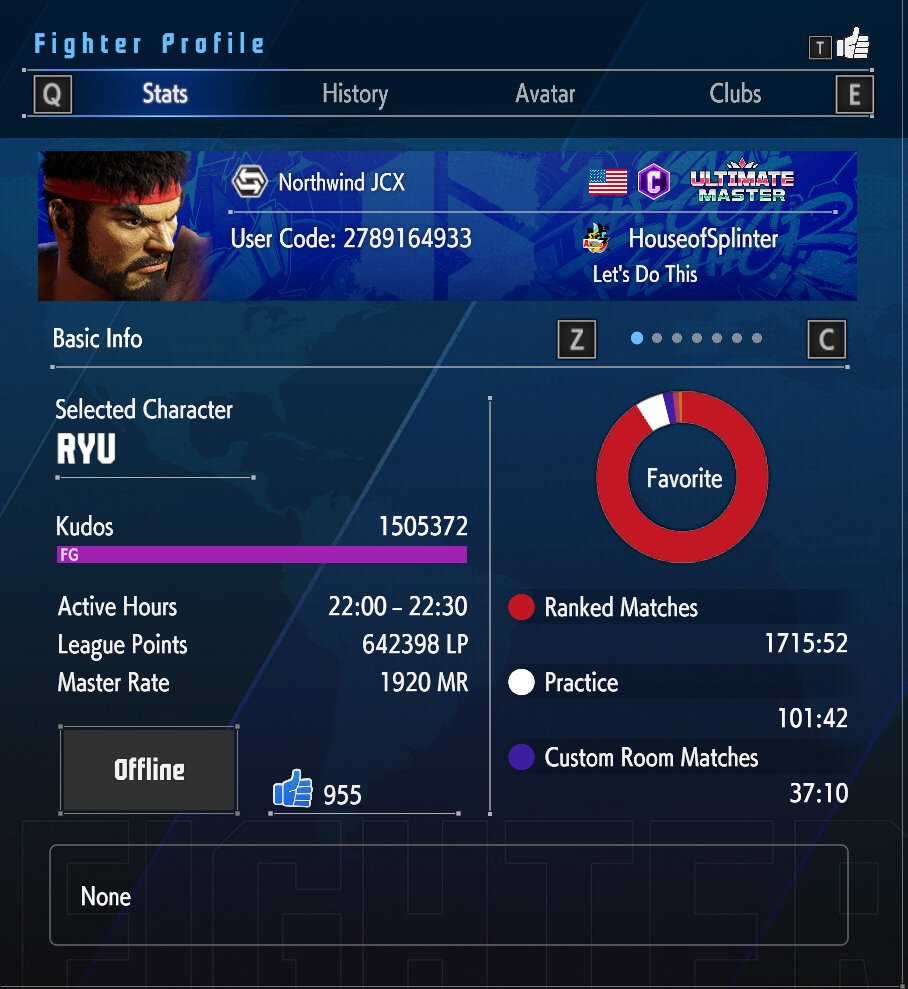
9
281
3,076
176,057
Jan 21
Ugh…
Jan 21

Trump in Davos, Switzerland:
"Without us, right now you'd all be speaking German".
German is the main language of Switzerland.
37
Crayvex retweeted

Jan 12
Detailed analysis of the behavior of Renee Good and Jonathan Ross prior to her death.
WATCH:
#DemsUnited
1,347
7,069
18,264
404,081
Crayvex retweeted

初代バイオハザードで重傷のまま階段登る時
550
14,167
121,064
7,357,502
13 Dec 2025
As a Dahlsim player who often struggles with execution, it felt good to land this in a match.
2
63
6 Dec 2025
This is the best superhero movie.
6 Dec 2025

“It’s weird I hated this movie when I first watched it, but a year later I watched it again, and now it’s one of my favourites...
91
Crayvex retweeted

22 Aug 2025
THE WIZARD RAISES HIS STAFF
PLEASE MAKE YOUR DEX SAVING THROW!
53
1,399
7,970
143,247

✋😮🤚
Source: bilibili.com/video/BV17pYZzb…
137
2,180
11,992
694,328
19 Aug 2025
I don’t think I’ve ever been so tremendously pleased by a trailer. Wow. 🤩
19 Aug 2025

Season Two greetings, Vaulties. Starting December 17, the Wasteland is your new home for the holidays.
1
85
Crayvex retweeted

16 Aug 2025
For celebrating this exciting announcement with GameSir, I will giveaway 10 G7 Pro controllers.
How to enter:
1) Follow @_MenaRD__ & @mygamesir
2) Retweet
3) Leave a comment down below.
The winners will be revealed on 25th of August, PDT.

1,430
1,255
1,948
152,040
24 Jul 2025
I’m wrapping up my first visit to Berlin. I’ve been to Germany many times but Berlin is unique.


1
55
Crayvex retweeted

25 Jun 2025
We knew it was coming…😂😂
Adding this to my playlist RIGHT NOW.
Credit TT: The remix bros
2,278
18,352
88,047
7,429,698
Crayvex retweeted

14 Jun 2025
New stun conversions. The last 2 are variations of @BreezyManX combo but they're much easier to set up this season. I showed DI on hit and block because it affects the timing and spacing
1
23
126
8,332
Crayvex retweeted

31 May 2025
MY MAGNUM OPUS!!!
36
403
4,093
509,064