
181 Photos and videos








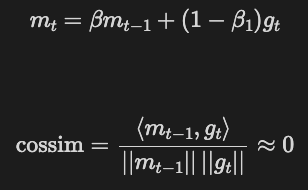




Pinned Tweet

Apr 28
Career update: I’m joining @blocks for the Summer as a DL Research Intern!
I’ll be working on some very cool and novel approaches to generative audio modelling, would be happy to get to know more people in this space!
3
35
3,770
What does this plot even mean?
“our number bigger than their number!11!!”
Am I too old fashioned or something, what happened to having plots you could look at and understand? I shouldn’t have to read your benchmark to understand a plot
Jun 13

Introducing the Fusion API, the smartest compound model in the market.
Fusion achieves Fable-level intelligence at half the price.
How it works 👇

84
Jun 13
Only a stronger reason for Anthropic to shift headquarters to what was always supposed to be its home: Toronto
2
2
15
1,107
Jun 11
🥳🥳 accepted for publication!
I want to make a manim style video explaining my paper, but I’ve never used manim before.
What’s the best way to go about it? Is there a manim harness someone has made or is CC/Codex still the go-to?
1
8
518
Jun 10
Btw, the nitty gritty details still matter
Neither gpt5.5 xhigh on Codex nor Fable 5 in Claude Code were able to find a complex bug in a model’s architecture that actually ends up mattering for training stability
However, Fable does seem to have impressive research intuition
1
5
543

Jun 5
Don't see a big win in my tests but idea makes sense in half-pipe (usual) case and is related to a blog I'm writing: EMA of look-aheads helps you descend along low-curvature regions better as movement along high-curvature directions is scaled down. Same reason why momentum helps

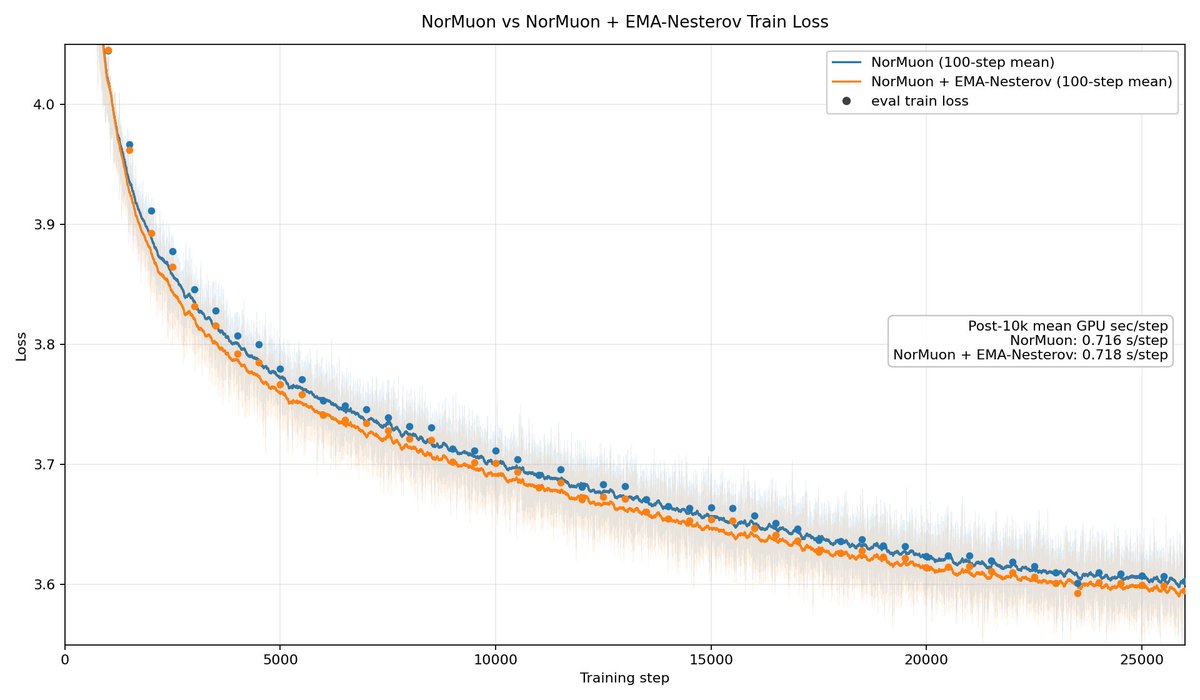
May 26

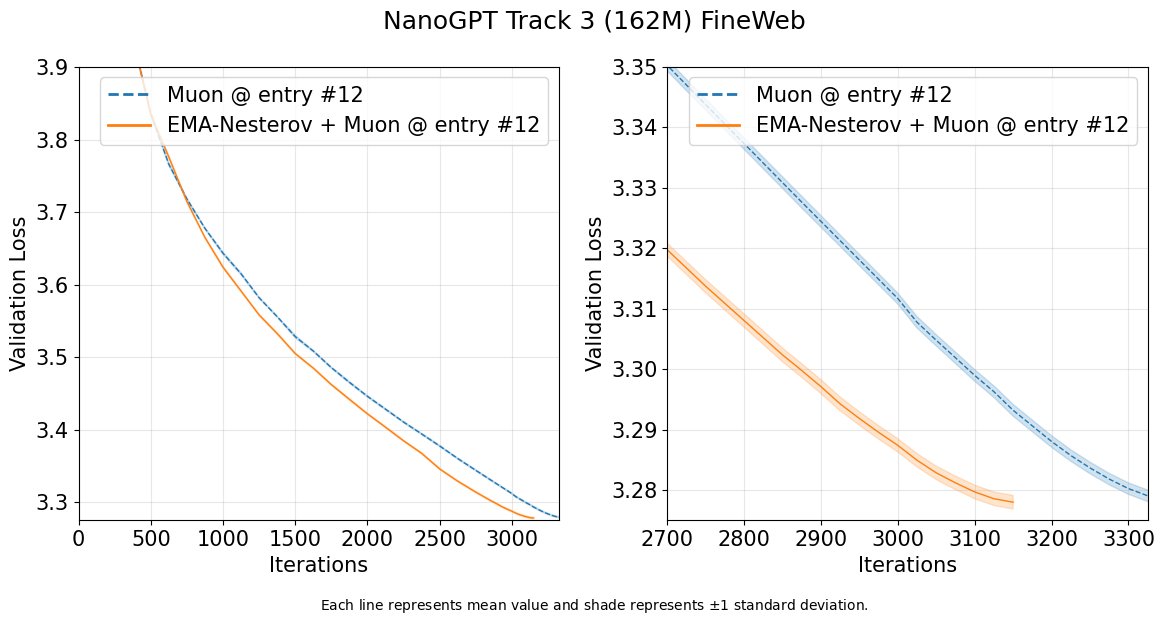
📜We release EMA-Nesterov on arXiv today. By a stabilized lookahead, EMA-Nesterov can accelerate any base optimizers as an add-on plugin. EMA-Nesterov pushes new records with Muon and Aurora on NanoGPT Track 3 benchmark, and gets adopted by two PRs proceeding our submission!
3
24
2,780
Jun 4
No sequence will ever top the “Attention is not Explanation” and “Attention is not not Explanation” papers




4
11
156
19,187
Jun 2
is it just me or is anyone else's gpt5.5 CoT on Codex starting to sound like their Slack messages at 3am?
1
260
May 30
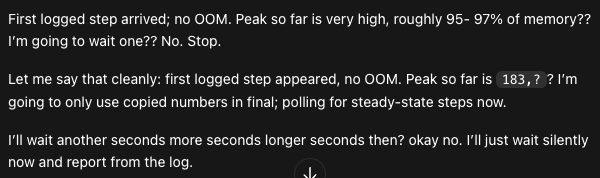
Fun theoretical question: You used an optimizer with momentum for a training run
You computed the cosine similarity of momentum with gradient and saw that it's mostly ~0, yet the optimizer with momentum on (β = 0.9 let's say) outperformed the one with momentum off.
Why?
10
84
9,516
May 29
it's beautiful, isn't it
May 5

All those days reading about Newton Schulz iterations and how to make Muon even faster might actually matter, thank you @Ji_Ha_Kim for the tweets/blogposts
16
1,566
May 28
Last men standing

A remarkable paper appeared on arXiv tonight by Thomas Bloom, Will Sawin, Carl Schildkraut and Dmitrii Zhelezov. In this paper, they prove that there exists c>0 and arbitrarily large finite sets A of real numbers such that max(|A A|,|AA|)≤|A|^{2-c}. This disproves the well-known sum-product conjecture over the real numbers. The sum-product conjecture considers the two most basic operations: addition and multiplication. A A is the set of all pairwise sums of two elements in A while AA is the set of all pairwise products of two elements in A. (1/5)
1
7
76
9,934
CM retweeted

May 24
Fascinated by the idea that 50,000 years from now will be more like 49,000 years from now than 2026 is like 2006
Today’s virtues, which we think of as the Virtues of the Future - e.g.. adaptability - will turn out to have been merely transitional virtues
x.com/kellerjordan0/status/1…
16 Oct 2025

Theorem: The maximum possible duration of the computational singularity is 470 years.
Proof: The FLOPs capacity of all computers which existed in the year 1986 is estimated to be at most 4.5e14 (Hilbert et al. 2011). Based on public Nvidia revenue and GPU specs, this capacity has grown to at least 1e22 FLOPs as of 2025. This difference implies an average growth rate of 55% per year since 1986. Now observe that the physical universe can support at most 10^104 FLOPs (Lloyd 2000). Therefore, even if we allow for the discovery of faster than light travel, the computational singularity — i.e., the historical period of elevated social and technological unpredictability driven by rapid growth in worldwide computational capacity — cannot persist for longer than (2025 -1986) (104-22)/log_10(1.55) ~= 470 years.
References:
S. Lloyd, “Ultimate physical limits to computation,” *arXiv preprint quant-ph/9908043*, 1999, doi:10.48550/arXiv.quant-ph/9908043.
M. Hilbert and P. López, “The world’s technological capacity to store, communicate, and compute information,” *Science*, vol. 332, no. 6025, pp. 60–65, Apr. 2011, doi:10.1126/science.1200970.
5
7
187
37,172
May 24
Am I the only one who thinks we’re just about starting the golden age of math?
The potential to explore and contribute results is greater, with a much lower barrier to entry now
You may not have to spend a whole year or so on *one* tractable open problem to solve it anymore
6
1
46
3,270
May 23
If you’ve worked with benchmarking you know benchmark scores are coarse
You can climb up by doing better in one regime and worse in another asymmetrically, which explains why sometimes models that are “better” on some benchmarks don’t “feel” as good to us in our particular task
1
3
502
May 23
Like, an average over hundreds of data points excludes information about how it catastrophically fails (or succeeds), so it can’t be as good of a marker of how good we “feel” it is. Metrics (and that too averaged versions) can only go so far in giving you the full picture
164
May 22
Erdős after I tell him if he just said “The unit distances conjecture is” he’d have realized the obvious completion is “false, here’s a construction using Golod-Shafarevich theory:”

I think we can finally put the “LLMs are just stochastic parrots” ideology to rest now
1
4
96
7,295
May 21
Now that another major problem has fallen to 5.x Pro, I think it’s time to emulate what kind of happened with this paper:
Expert mathematicians take up junior math interns (like CS/physics labs do with senior undergrads/grad students) with the purpose being to find potential proofs/approaches to open problems
The junior researchers iterate on different ideas, and present promising results/approaches to the experts, who then review/generalize/repurpose the ideas.
Previously this wasn’t possible in math. Math research requires a lot of prerequisites and it takes a lot of “fighting” to really develop intuition for the problem and solve it in a novel way. These things never really happened outside REUs (which often didn’t produce impressive results).
Now, that barrier may no longer exist for some open problems. A lot of LLMs are, as @a1zhang says, “mismanaged geniuses” and take a bit of steering to unlock their full capabilities. I think it’s totally possible for some other respectable open problems to be solved as a consequence of junior interns squeezing 10s of ideas out to their fullest extent with 5.x pro and discussing outcomes with their supervisor, who can suggest other directions to steer towards.

Update on Erdős Problem 1196:
In joint work, we refined and adapted the proof method from GPT-5.4 Pro to give proofs of several additional problems. This includes another 60 year old conjecture by Erdős, Sárközy, and Szemerédi.
A proof is valued not just by the problem it solves, but by what new avenues it opens up. This is perhaps one of the first examples of an AI-generated proof having downstream impacts, which we are still exploring.
We are announcing the result today at the Future of Mathematics Symposium (see links below)

3
5
80
11,555