
Freedom and Liberty. #Bitcoin
Joined February 2021
- Tweets 2,840
- Following 839
- Followers 262
- Likes 5,831
592 Photos and videos








CryptoTrigger retweeted
I don't know if this Fable banning is some scheme to boost future IPO values because it's a nice "just too powerful" story, or perhaps govt. punishing anthropic for not wanting to kill humans, etc.
But, the stated justification is actually insane. If vulnerabilities are found and disclosed, that is great. Sure, it may be chaotic for a bit, but the point is those vulnerabilities exist today whether we point them out or not. Sunlight is the best disinfectant, so they say.
Break things, move fast, get better, repeat. A billion bugs, then ultimately near zero from what remains. Sounds like a win to me, collateral damage aside.
6
13
83
2,595
CryptoTrigger retweeted

16h
The best teachers will be LLMs. The best feedback will be monetary. The best models will train competitively. The best AI company will be co-owned. The best software will be open source. And there is only one way to get all of it.
29
122
668
16,153

1
1
96

Jun 13
The promise of decentralisation, privacy and self governance gave way to the sheer power, efficiency and innovation coming out of at AI sector
Convenience is a powerful force and we’ve been sacrificing too much for it for too long
Open, private and decentralised or bust
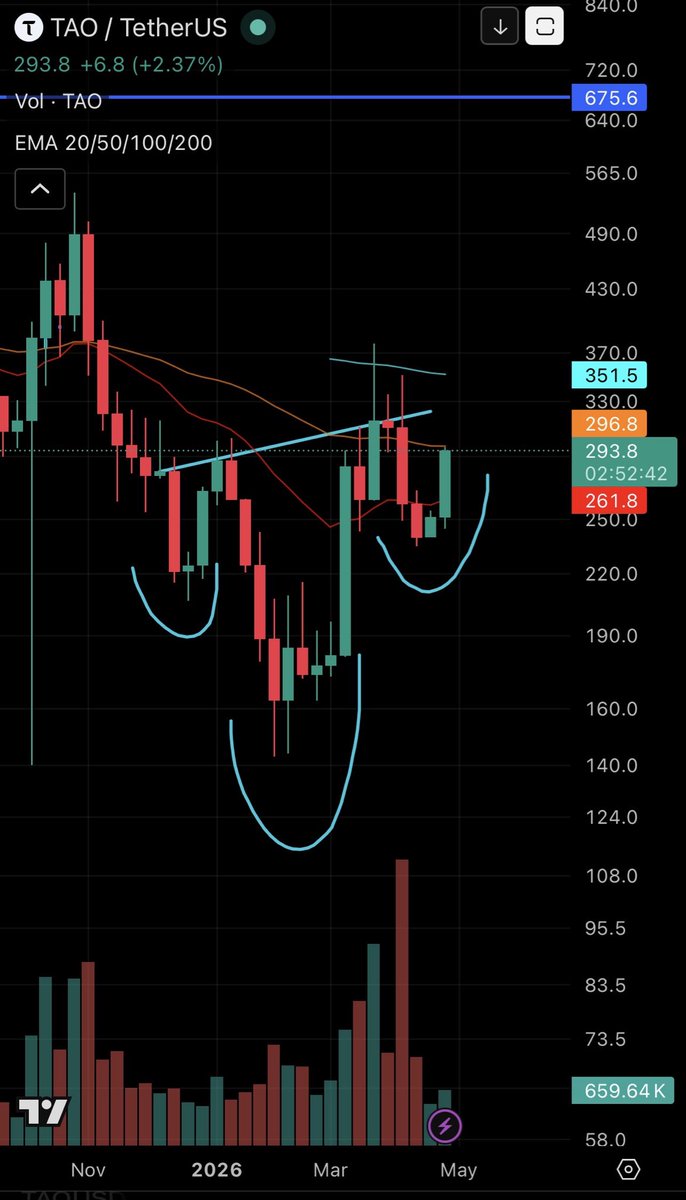
$TAO
45
Jun 13
So at this point you just buy $TAO and @chutes_ai and go to sleep.
Hot take: Bittensor achieves what it will for intelligence before $BTC Bitcoin achieves what it has aimed to for money since the beginning
One is ideal, the other I believe is an absolute necessity
1
89
CryptoTrigger retweeted

Jun 11
NVIDIA Nemotron 3 Ultra is live on Chutes.
550B parameters, 55B active. NVIDIA’s frontier open model for agents, long-context work, and hard reasoning. Hybrid Mamba-2 MoE architecture with a reasoning toggle.
87.9 GPQA. 69.7 SWE-Bench Verified. 256K context.
Running in TEE: GPU operators serving the model can’t see your prompts or outputs.
$1.50 in / $4.00 out per million tokens.
Try Now: chutes.ai/app/chute/feedcff5…

5
22
89
3,210


CryptoTrigger retweeted

Jun 10
Case in point... THOU SHALT NOT COMPETE.
- AI/LLM development generally
- distributed training
- pretraining pipelines
- ML accelerator design
- cybersecurity
- chemistry
Already disclosed as nerfed for the plebs. What's next on the lobotomization list?

Jun 9

The dream state would be models within a few IQ points of the frontier labs (probably task specific first, depth before breadth), with a "training-as-a-service" arm to achieve breadth (inc. RL), all on TEE with true privacy, served at a fraction of the price of frontier models with significantly less hardware, thereby commoditizing and democratizing intelligence to the maximum extent possible.
The entire world's knowledge trains these models, they should in turn be trained by and accessible to the entire world.
The thing about privacy is, it's not really just about privacy. YOU are the product (builders) by ignoring privacy concerns.
People are building the massive golden trillion dollar moats for the various labs for them by giving free RL data constantly. It's great, for a few, not so great for everyone else. Need to make sure AI remains accessible and available to everyone, always.
If AI gets concentrated into a handful of players, it would mean those teams and maybe even a single person within ultimately gets to decide if you are allowed to multiply matrices in particular ways or not, not to mention constant surveillance etc.
Parallax aims to be the destroyer of moats.
9
25
98
6,283
CryptoTrigger retweeted
Jun 9
The dream state would be models within a few IQ points of the frontier labs (probably task specific first, depth before breadth), with a "training-as-a-service" arm to achieve breadth (inc. RL), all on TEE with true privacy, served at a fraction of the price of frontier models with significantly less hardware, thereby commoditizing and democratizing intelligence to the maximum extent possible.
The entire world's knowledge trains these models, they should in turn be trained by and accessible to the entire world.
The thing about privacy is, it's not really just about privacy. YOU are the product (builders) by ignoring privacy concerns.
People are building the massive golden trillion dollar moats for the various labs for them by giving free RL data constantly. It's great, for a few, not so great for everyone else. Need to make sure AI remains accessible and available to everyone, always.
If AI gets concentrated into a handful of players, it would mean those teams and maybe even a single person within ultimately gets to decide if you are allowed to multiply matrices in particular ways or not, not to mention constant surveillance etc.
Parallax aims to be the destroyer of moats.
5
21
104
10,350
CryptoTrigger retweeted
Jun 9
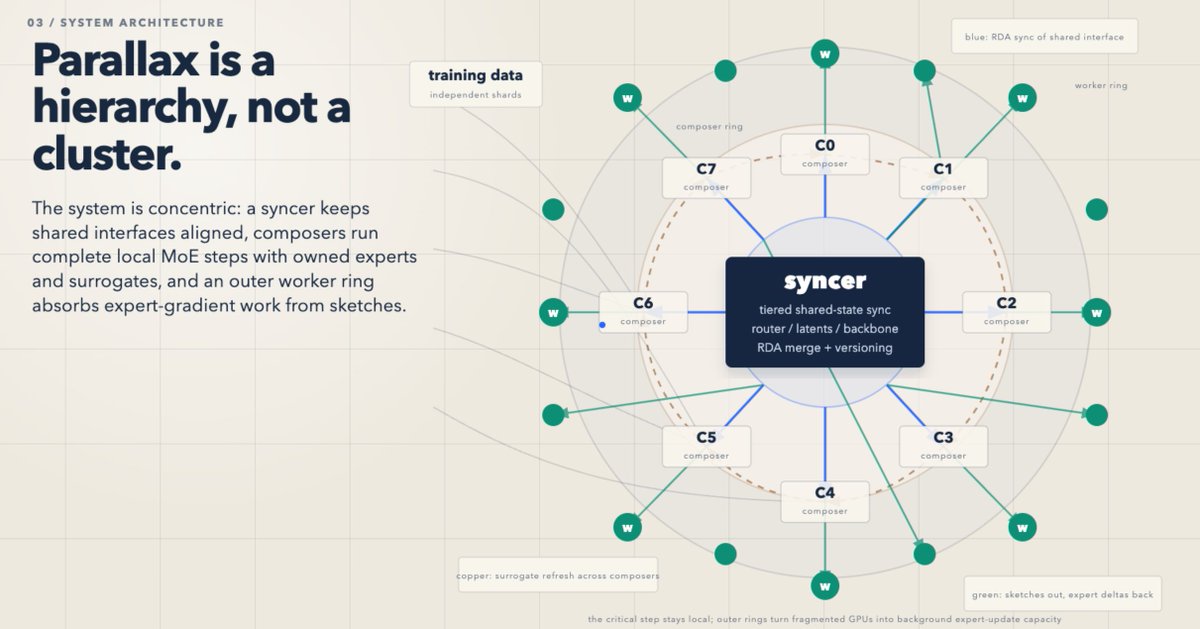
Here's a draft of the tech report on the model training method I've been experimenting with, "Parallax".
chutes.ai/parallax.pdf
TL;DR: MoE models' params are mostly routed experts, and you can massively reduce VRAM and FLOPS per participant by splitting up those experts. You can also offload the expert training to commodity hardware further saving compute/VRAM per island.
The crazy cool thing about these sketches is, you can actually onboard workers nearly instantly (sync time with ternary weights is a few MB), and they never need to download or stream the raw datasets (sketches contain all the work they need to do and are tiny). You'd probably want the first couple layers of the model in your own infra if you had sensitive data because otherwise you could do gradient inversion attacks to reconstitute the raw text, but beyond the first couple layers and not knowing which layer/expert you're training I think it's infeasible so privacy is pretty baked in.
Decoupled DiLoCo/RDA-diloco style backbone sync, surrogates for non-owned routed experts with low rank updates to sync those, tiered sync cadences for various components, "sketches" to offload expert work, etc.
20b tested two different ways, plenty of small model iterations, and 176b params just to prove out feasibility.
There are hundreds of additional experiments and loads of data we could also highlight as well, but the guts are there.
Variations:
- freeze routed expert weights instead of using surrogates, eliminates adam state, backward pass, etc., though you'd need different sync methods vs. low rank updates to the surrogates (the surrogates are already tiny, rank-8 updates to those even smaller)
- hierarchical parallax, i.e. each node itself becomes an rda diloco style multi-learner which then syncs with the outer/global islands (the point here is to enable GPUs without NVLink/etc. and reduce GPU<=>GPU comms to maximize MFU on less-capable/commodity GPUs)
- pipeline parallelize each island itself such that each island can decompose the backbone etc.
27
59
205
37,876
CryptoTrigger retweeted

Jun 9
Chutes @chutes_ai on track to Make Decentralized Great Again.
this Bittensor $TAO subnet released a research paper saying it is possible to train awesome AI models completely decentralized.
but this time, not in a "make it fit for decentralized infra" limiting way; it's better BECAUSE decentralized
hope this works out, we really need this. it's what matters most.
united for AI training without Datacenter limitations, producing state-of-the-art models at cheaper cost to run efficiently in a decentralized AI inference network.
this is how we survive the monopoly of tech giants as the world unites via decentralized protocols like Bittensor and Chutes SN64

Jun 9
Here's a draft of the tech report on the model training method I've been experimenting with, "Parallax".
chutes.ai/parallax.pdf
TL;DR: MoE models' params are mostly routed experts, and you can massively reduce VRAM and FLOPS per participant by splitting up those experts. You can also offload the expert training to commodity hardware further saving compute/VRAM per island.
The crazy cool thing about these sketches is, you can actually onboard workers nearly instantly (sync time with ternary weights is a few MB), and they never need to download or stream the raw datasets (sketches contain all the work they need to do and are tiny). You'd probably want the first couple layers of the model in your own infra if you had sensitive data because otherwise you could do gradient inversion attacks to reconstitute the raw text, but beyond the first couple layers and not knowing which layer/expert you're training I think it's infeasible so privacy is pretty baked in.
Decoupled DiLoCo/RDA-diloco style backbone sync, surrogates for non-owned routed experts with low rank updates to sync those, tiered sync cadences for various components, "sketches" to offload expert work, etc.
20b tested two different ways, plenty of small model iterations, and 176b params just to prove out feasibility.
There are hundreds of additional experiments and loads of data we could also highlight as well, but the guts are there.
Variations:
- freeze routed expert weights instead of using surrogates, eliminates adam state, backward pass, etc., though you'd need different sync methods vs. low rank updates to the surrogates (the surrogates are already tiny, rank-8 updates to those even smaller)
- hierarchical parallax, i.e. each node itself becomes an rda diloco style multi-learner which then syncs with the outer/global islands (the point here is to enable GPUs without NVLink/etc. and reduce GPU<=>GPU comms to maximize MFU on less-capable/commodity GPUs)
- pipeline parallelize each island itself such that each island can decompose the backbone etc.
3
14
84
3,781
CryptoTrigger retweeted
Jun 9
Old world: giant data center, racks of GPUs, power/cooling/water/land, $200M gatekeeping.
Parallax world: distributed GPUs, regular machines, no training data exposed to workers, same time target with ~82% less hardware/resources.
Proof of Parallax.
$TAO
14
44
192
8,240
CryptoTrigger retweeted
Jun 8
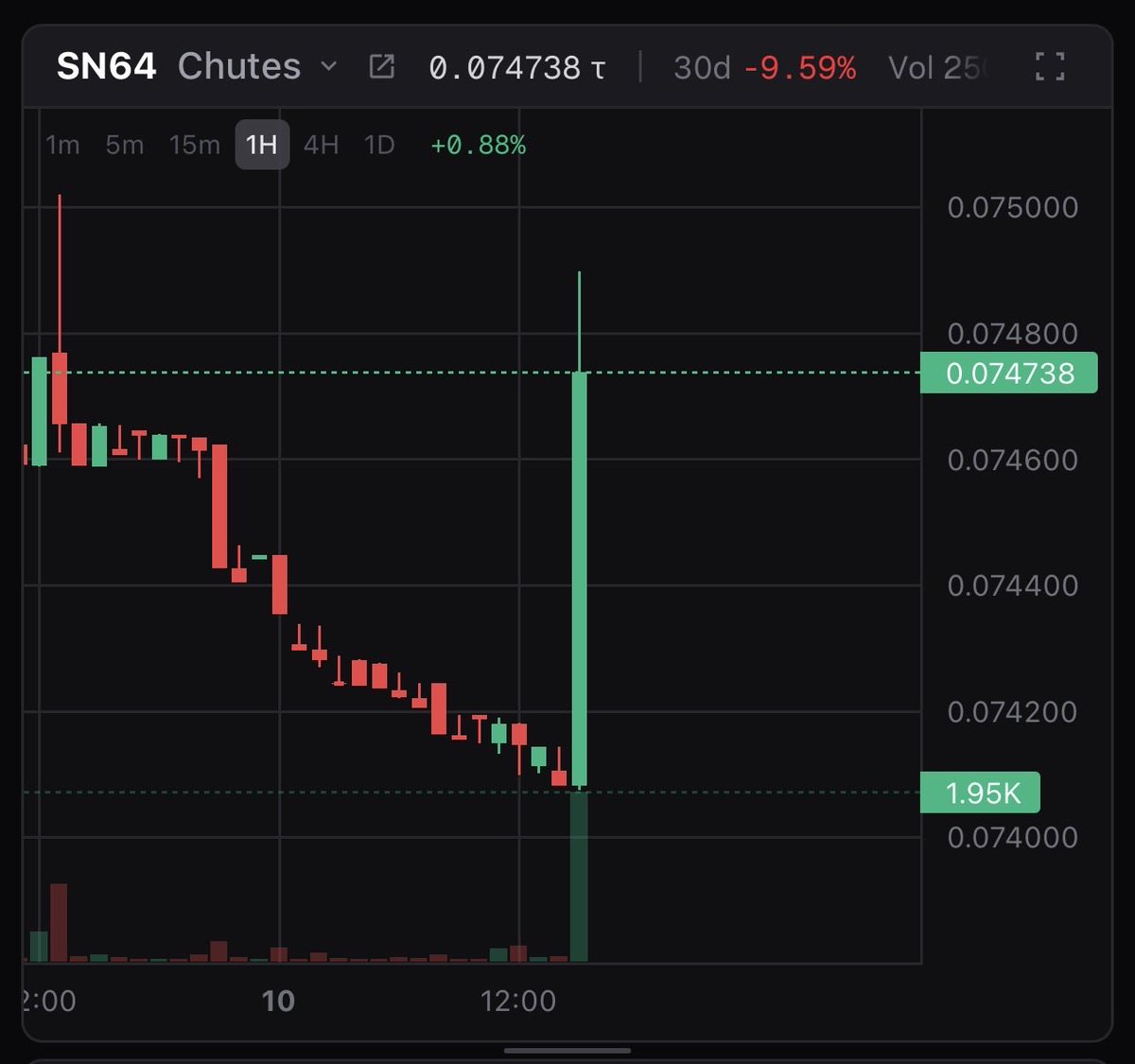
$TAO spoiler... This is what Chutes SN64 @chutes_ai price chart will look like in the future.
you just don't believe it yet

17
21
169
13,493
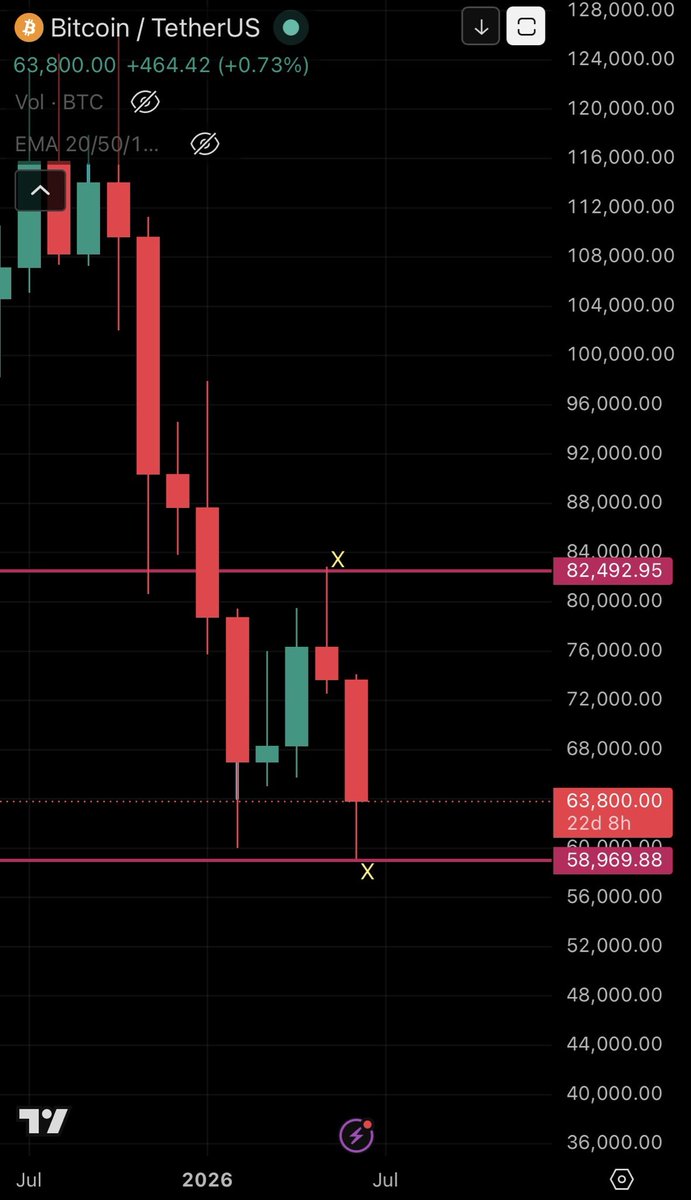
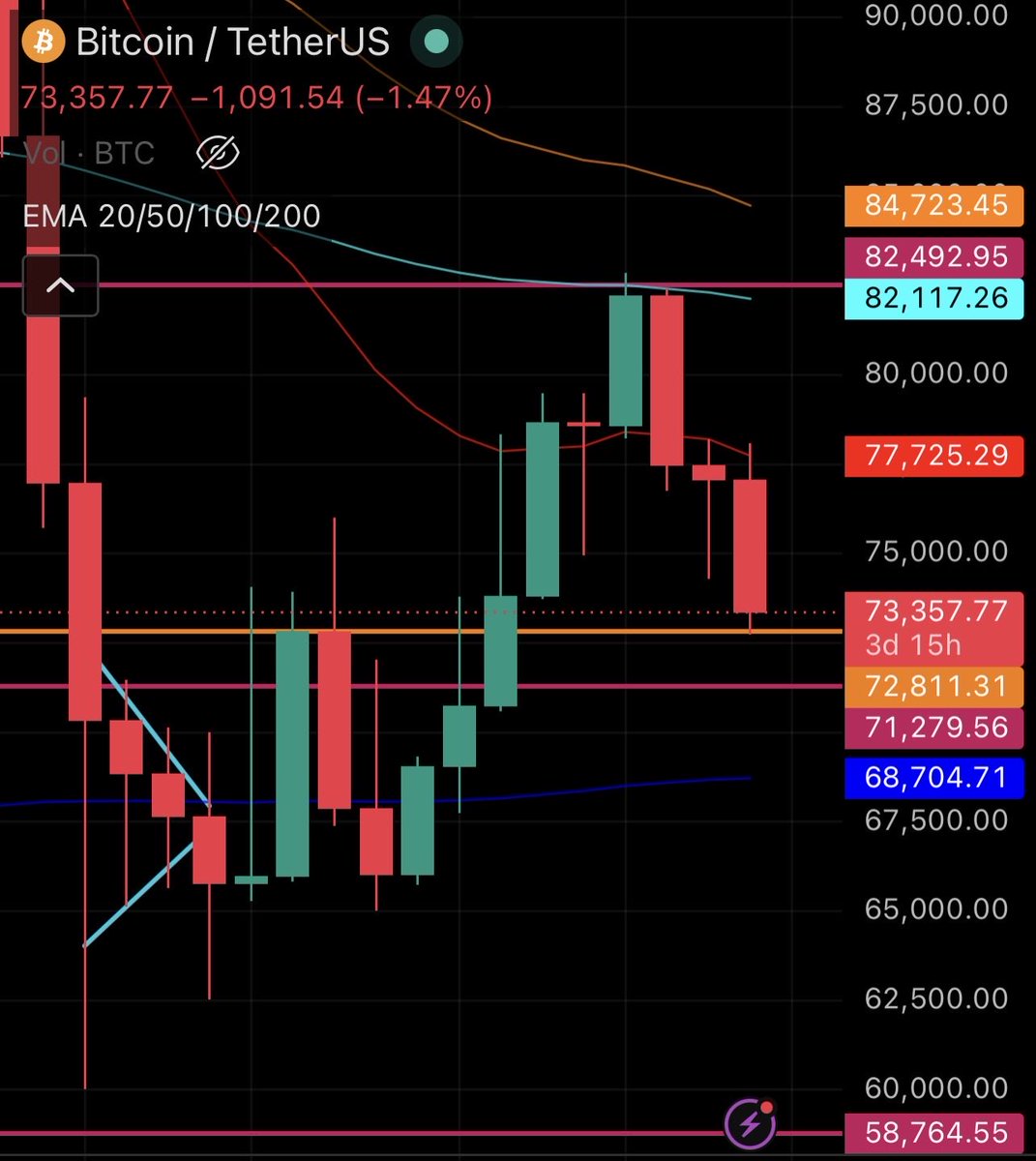
Gave these 2 levels on February 1st with hilarious levels of precision
$BTC
4/5 Why? Because for the first time in over 3 years $BTC has created a downtrend by closing a monthly below support. Typically this takes time to reverse. This is why below support is favored. Bulls would like to see reversal here, but support below remains more likely
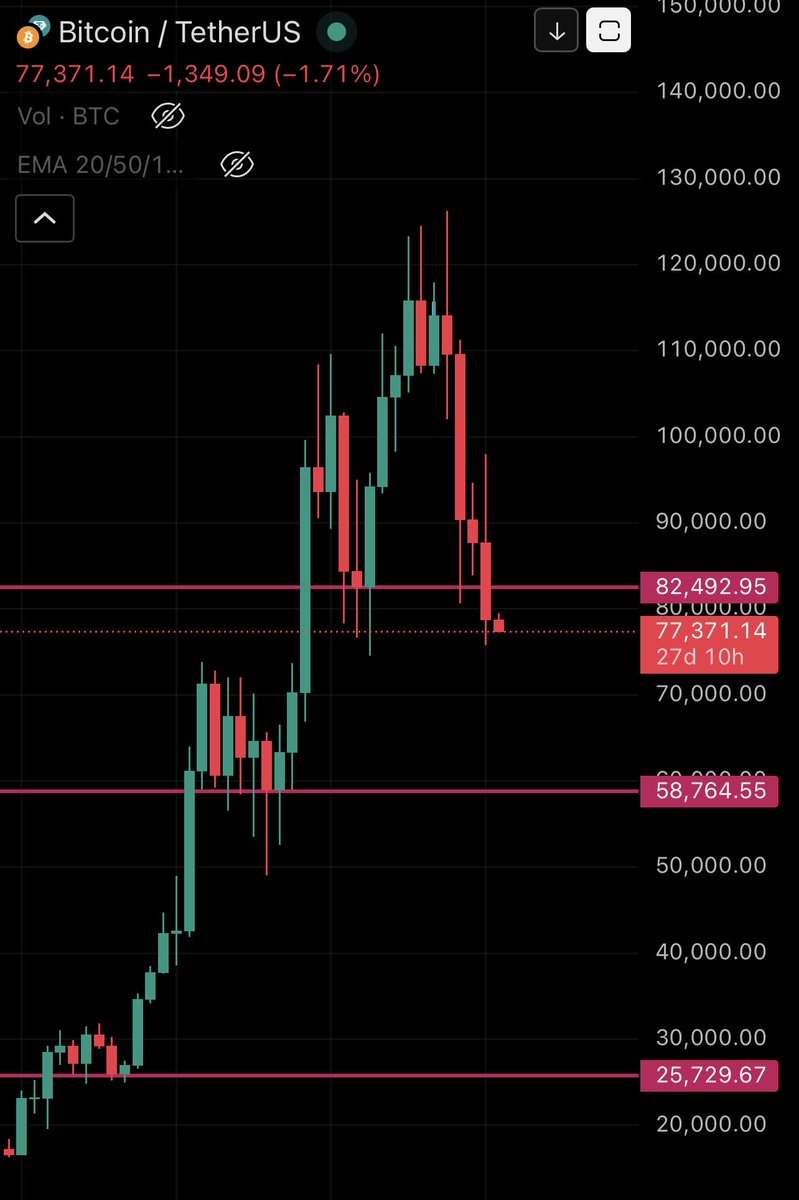
38
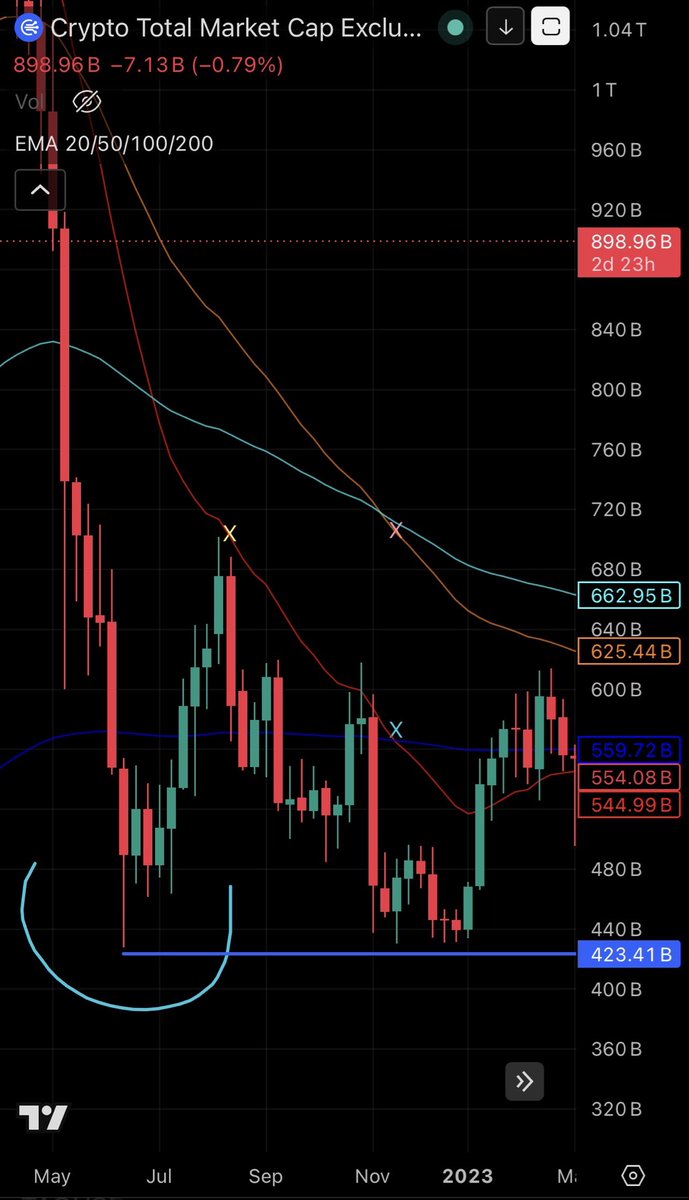
The cycle is repeating, but it’s early. Comparison to 2022 bottom on $TOTAL2 (Market minus $BTC):
Aggressive drop
Wick
Bounce - reject 20W EMA
Chop
Final capitulation to fill wick (you are here)
50/100W cross. 20/200W cross
Accumulation
Up only
Identical playbook
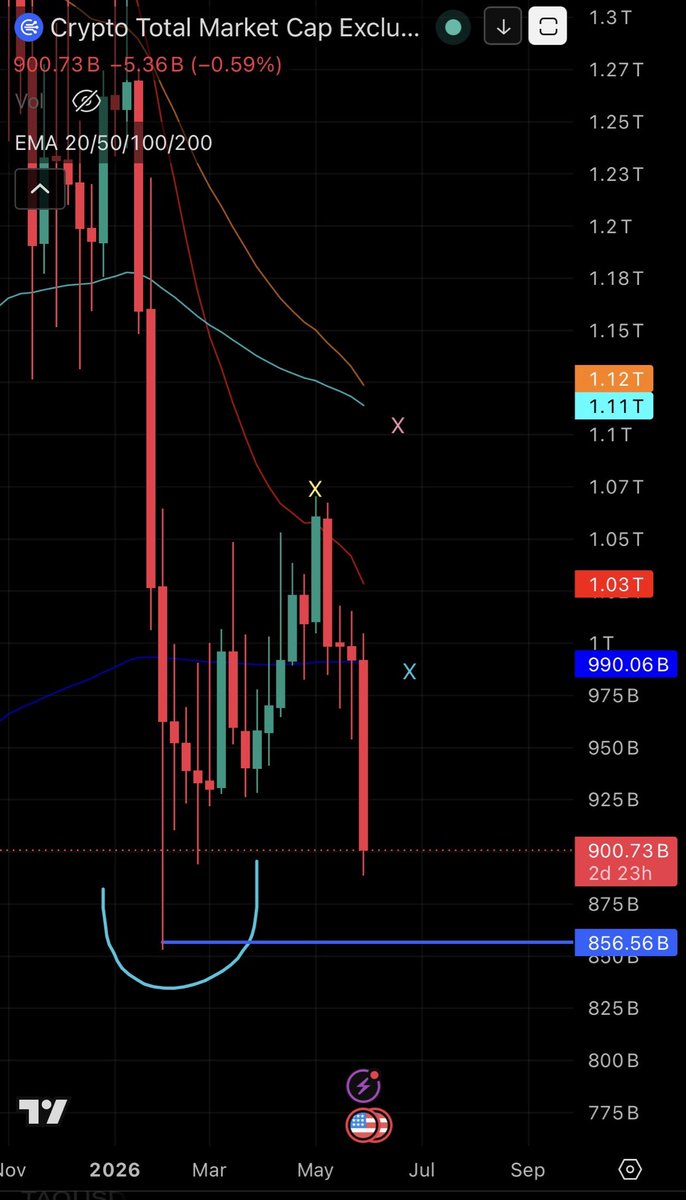
1
2
316
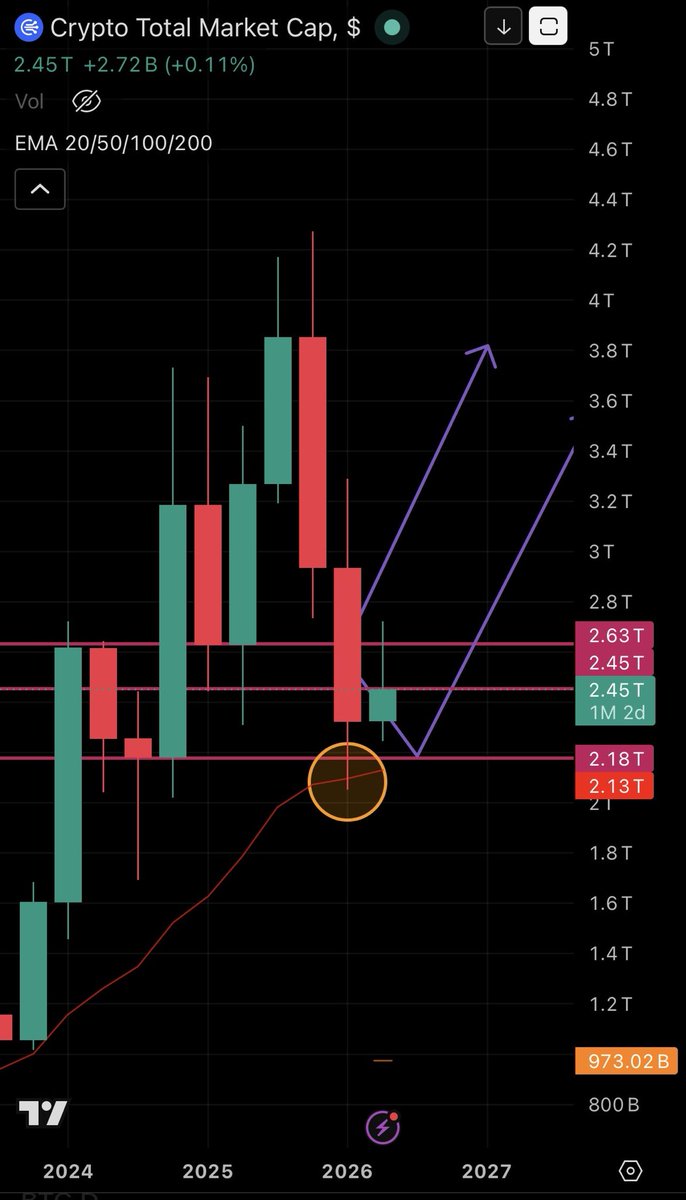
Think this time it’s more V recovery than a repeat of 2023 though. Different conditions. So EMAs maybe won’t cross as cleanly/just graze
44