
Professor at IST Austria
Joined May 2022
- Tweets 181
- Following 310
- Followers 1,755
- Likes 99
52 Photos and videos





May 19
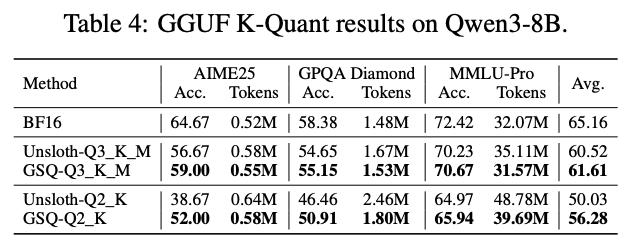
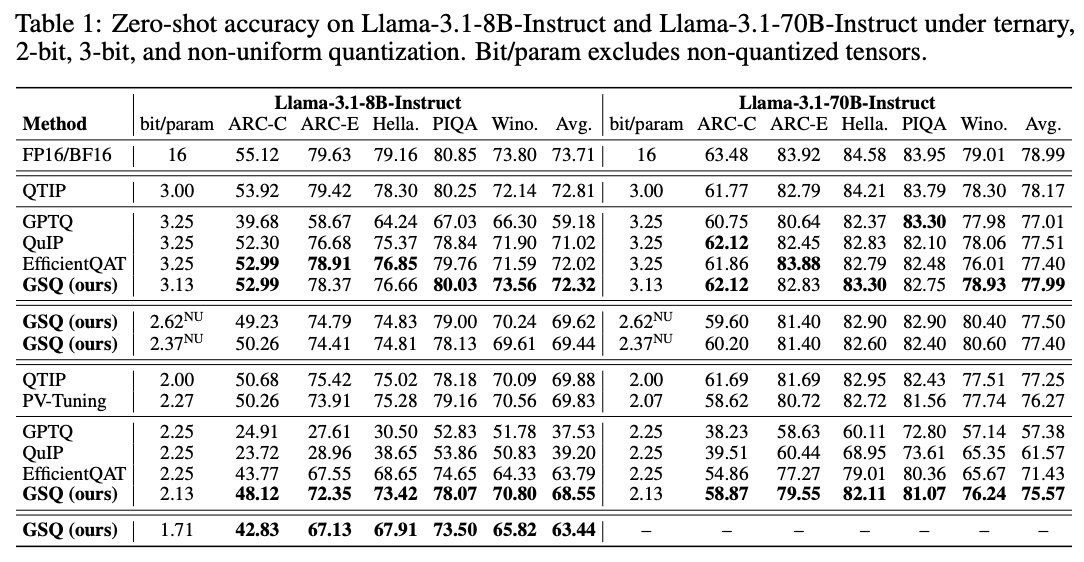
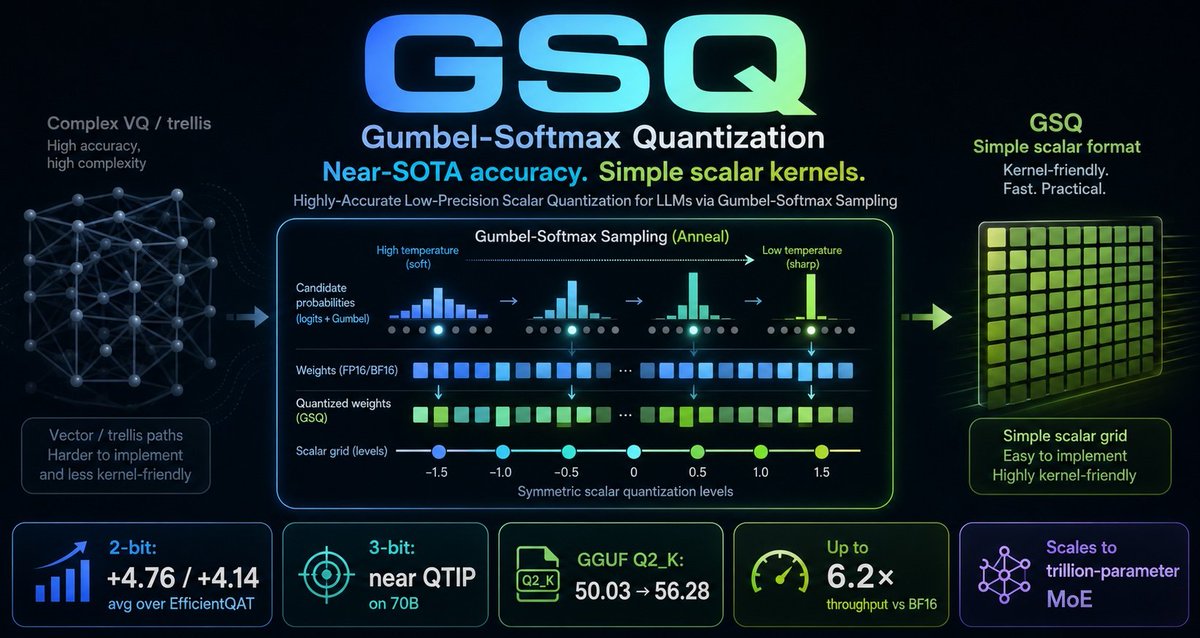
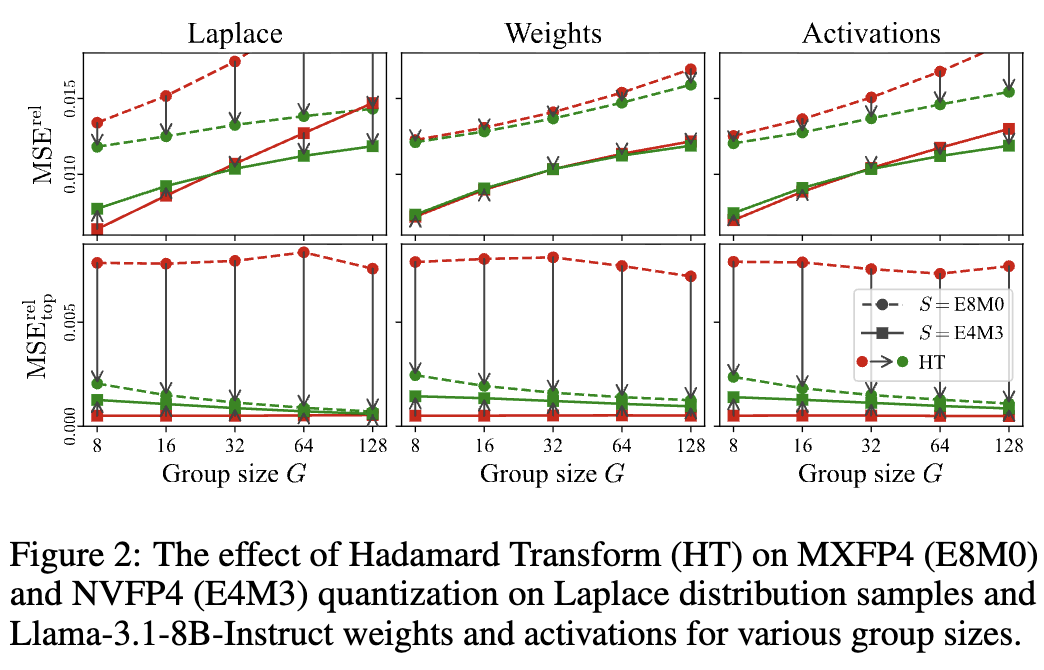
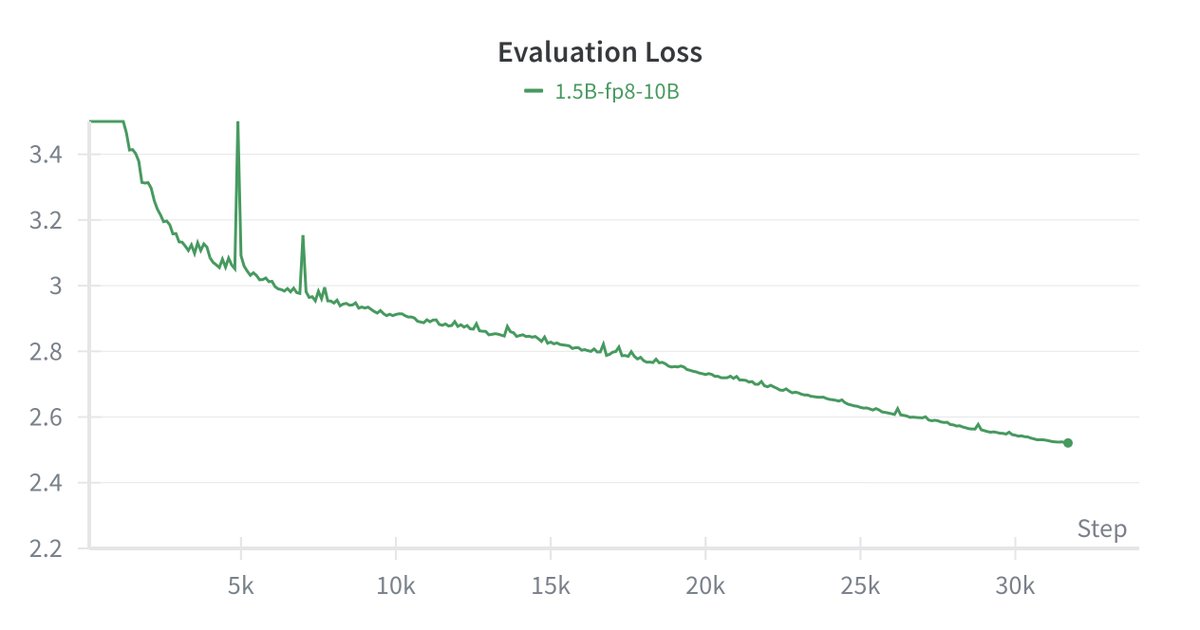
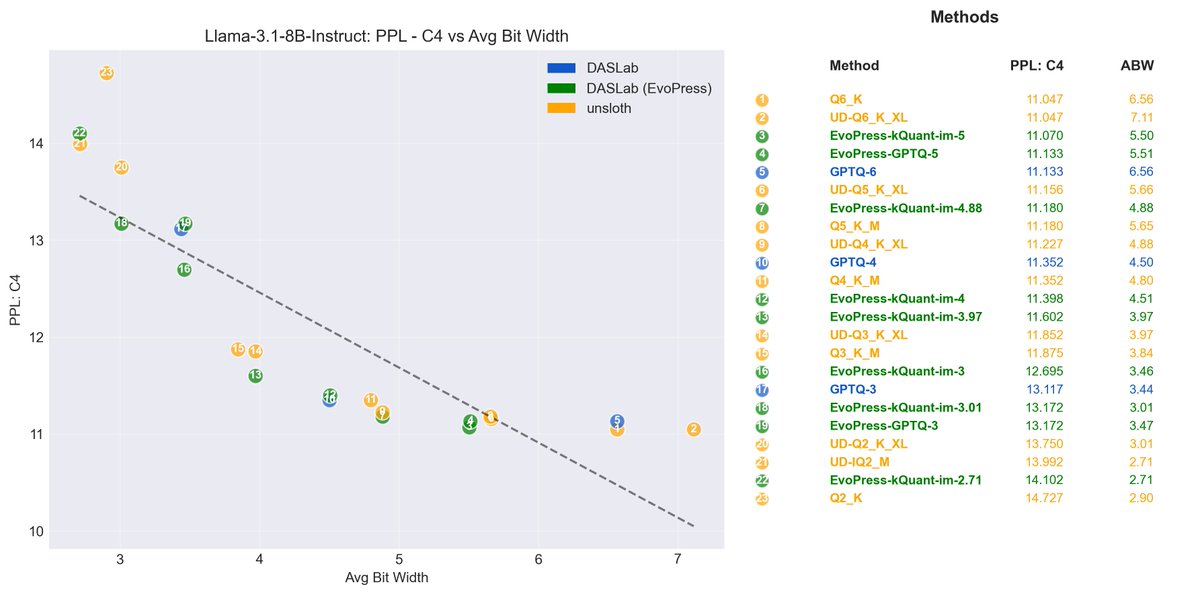
Weight-only quantization powers local LLMs like llama.cpp or Ollama. But SOTA quantized accuracy requires complex kernels that are notoriously hard to implement.
Can we get SOTA accuracy and keep things simple? Our new GSQ (Gumbel-Softmax Quantization) method says yes. 🧵
1
11
51
6,182
May 19
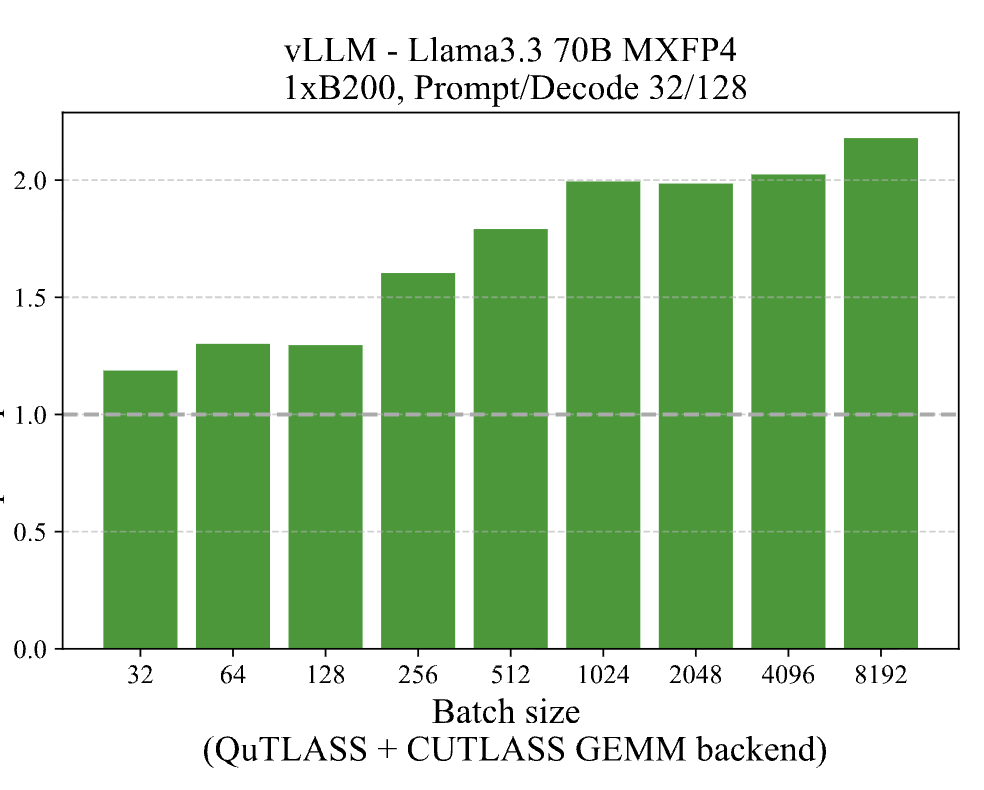
🚀 Scalar structure means GSQ can use highly-optimized low-precision GEMM kernels:
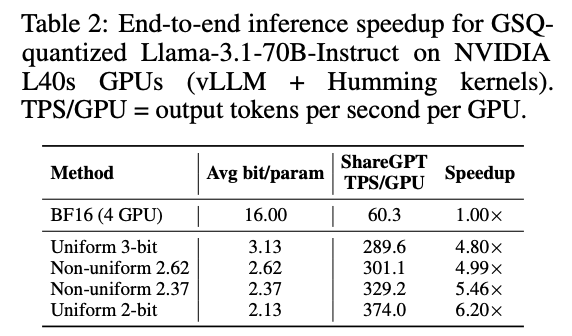
Using vLLM the excellent Humming kernels (github.com/inclusionAI/hummi…) on L40s GPUs, 2-bit GSQ-quantized Llama-3.1-70B hits up to 6.2× throughput vs BF16!
2
7
650
May 19
As always, our release is fully open:
💻 Paper and code: arxiv.org/pdf/2604.18556
@huggingface : huggingface.co/collections/I…
Credits: Alireza Dadgarnia, Soroush Tabesh, Mahdi Nikdan, Michael Helcig, Eldar Kurtić, and Max Kleinegger
We thank @RedHat_AI and @verdacloud for the support!
2
12
605
Dan Alistarh retweeted

May 11
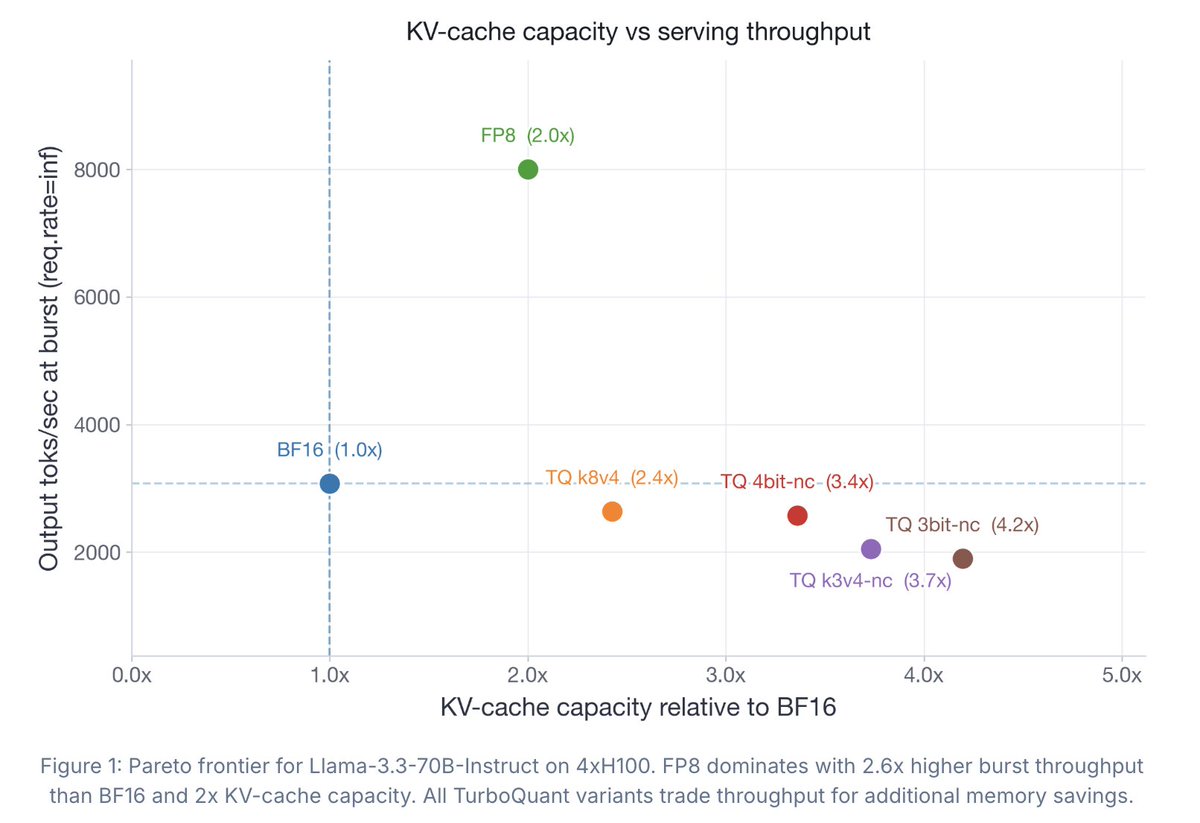
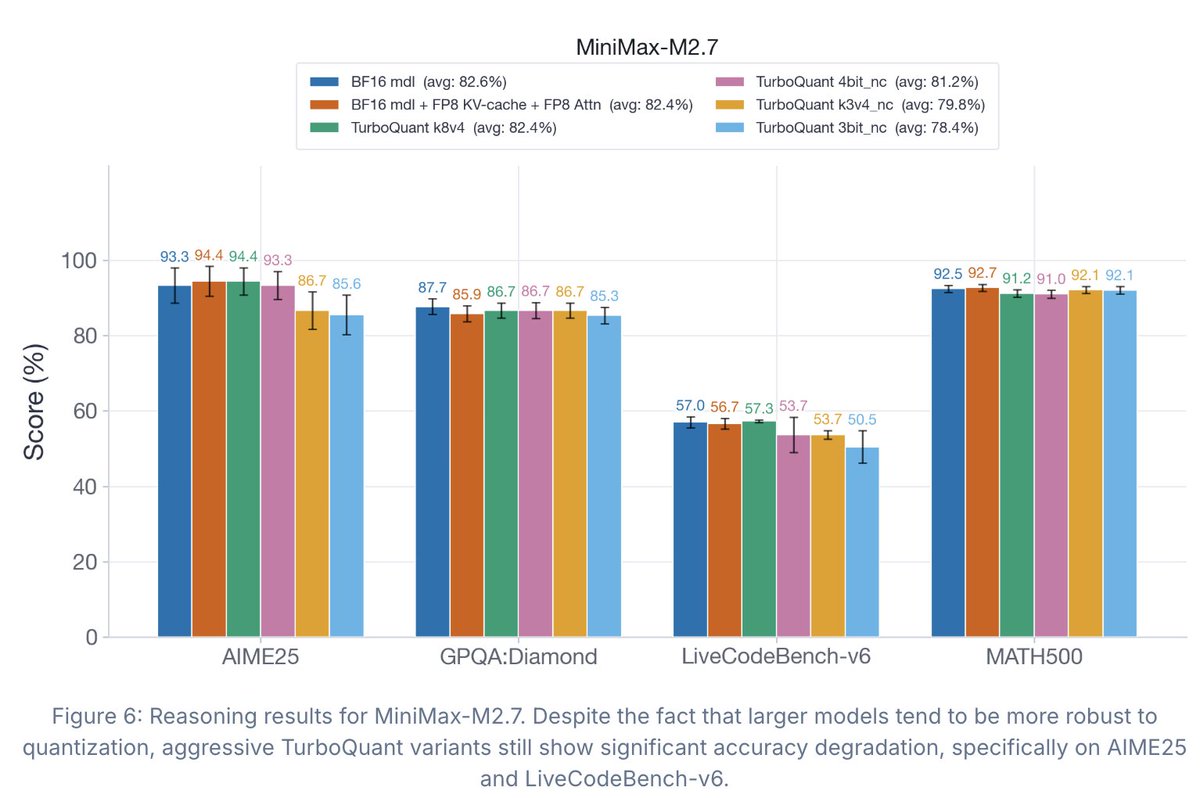
TurboQuant has drawn a lot of attention recently, but the accompanying evals didn't tell the full story.
So we ran what I believe is the first comprehensive study of TurboQuant: where it helps, where it falls short, and how it impacts accuracy, latency, and throughput.
Findings:
11
52
322
80,526
Dan Alistarh retweeted

Apr 23
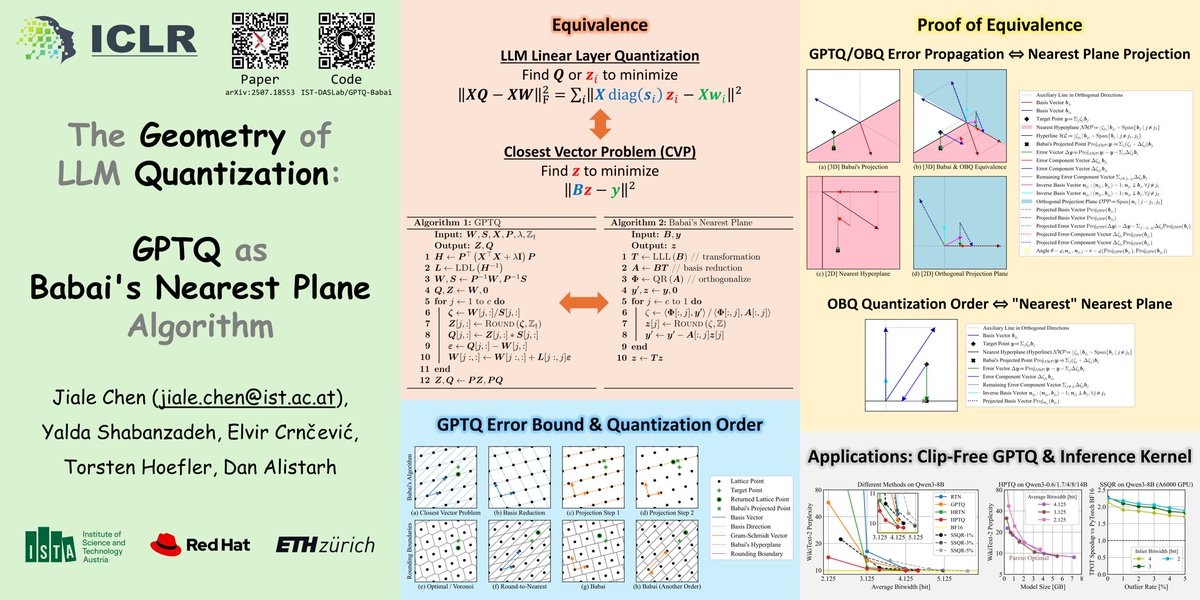
🚀 Our #ICLR2026 paper: The Geometry of LLM Quantization: GPTQ as Babai's Nearest Plane Algorithm
We show GPTQ is exactly Babai's nearest plane algorithm, giving a geometric view of LLM quantization and inspiring improved PTQ methods.
Efficient GPTQ Triton kernels included!
1
7
46
2,683
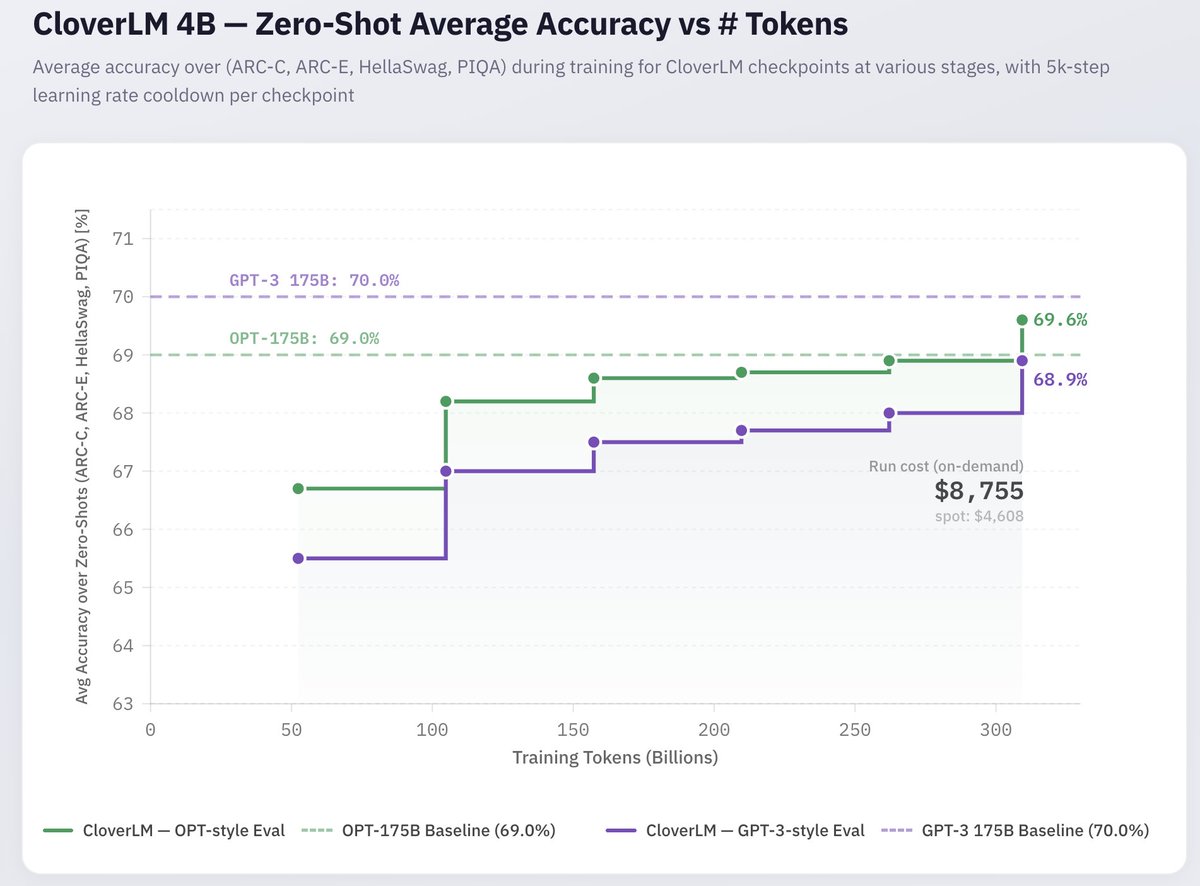
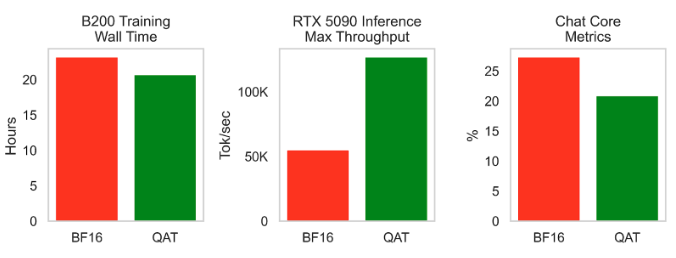
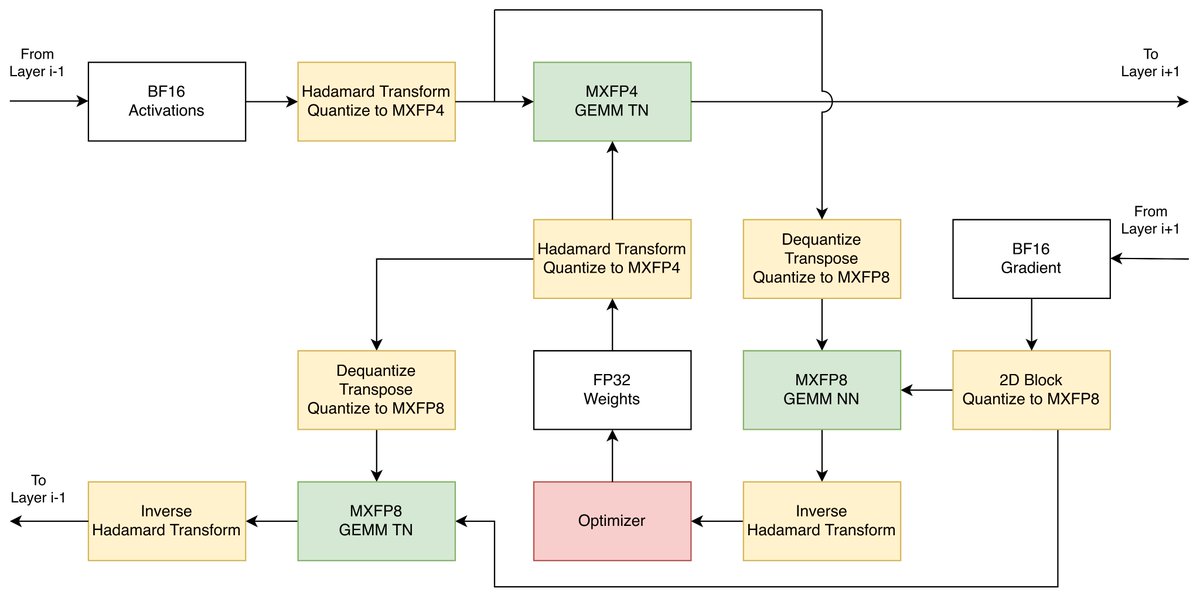
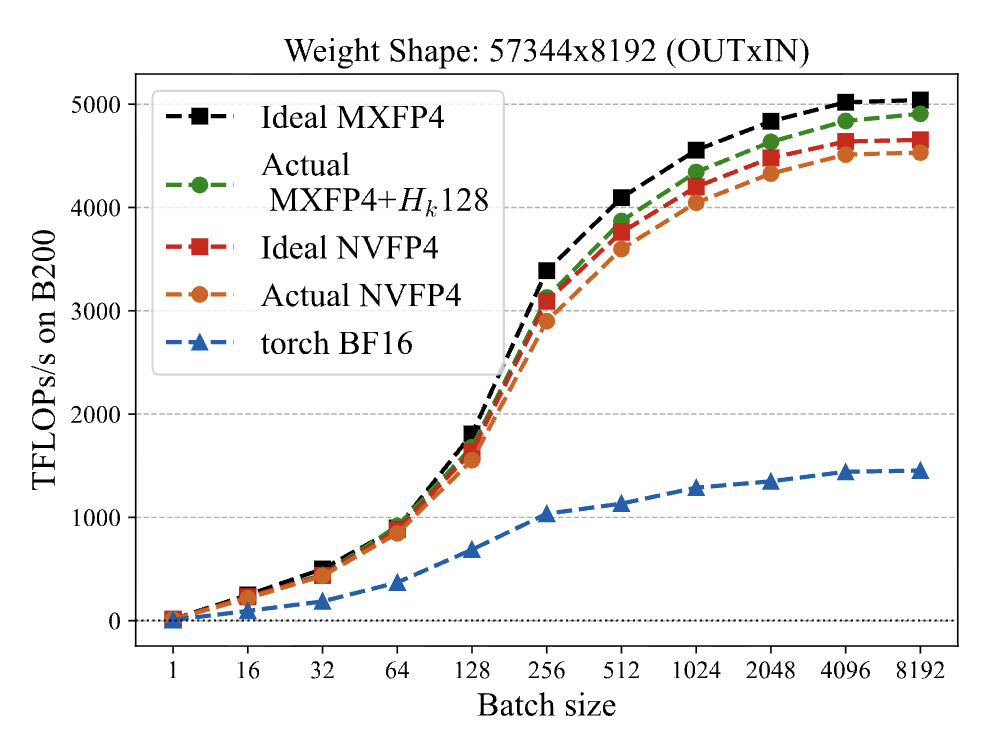
Mar 25
Speedrunning GPT-2 is now routine thanks to @karpathy.
But can we speedrun GPT3-175B?
We attempted to match accuracy on a <$10K budget; while we didn't quite reach it, our first results show that quality data, engineering, and native FP4 can get close.
Details in 🧵
4
22
170
12,496
Mar 25
Credit goes to Erik Schultheis, Matin Ansaripour @matin_asp, Andrei Panferov @black_samorez, and George Vlassis @gvlassis98. Thanks to @verdacloud (particularly Paul Chang) for compute support, and Jen Iofinova for safety testing. This work was supported by FWF BilAI and SwissAI.
1
15
971
Mar 25
As usual, our release is fully open:
- Full report: github.com/IST-DASLab/Clover…
- QuartetII paper: arxiv.org/abs/2601.22813
- Tokenized data: huggingface.co/datasets/dasl…
- Model: huggingface.co/daslab-testin…
- Codebase: github.com/IST-DASLab/Clover…
1
17
973
Feb 18
We’re releasing MatGPTQ (Matryoshka GPTQ) an accurate and efficient post-training quantization (PTQ) method that jointly optimizes a single model across multiple bit-widths, producing a sliceable checkpoint that can be deployed across diverse hardware and memory budgets. [1/4]
1
11
53
4,487
Feb 18
On the systems side, we provide custom CUDA kernels for Ampere GPUs and vLLM integration (see below for OSS code) to fully leverage nested models:
- 3x-5.6x kernel speedups when memory-bound
- 1.5x-3.5x end-to-end speedups in vLLM
1
1
12
698
Feb 18
Credits go to @maxkleinegger and Elvir Crnčević!
- Paper: arxiv.org/abs/2602.03537
- Models: huggingface.co/collections/I…
- Code: github.com/IST-DASLab/MatGPT…
1
9
496