
Joined May 2018
- Tweets 2,337
- Following 2,086
- Followers 11,007
- Likes 1,639
542 Photos and videos










Pinned Tweet

May 18
🇬🇧 London, June 10.
@vllm_project & @_llm_d_ Inference Meetup, hosted by Red Hat AI, @nvidia, and @SteliaAI.
Talks on vLLM updates, speculative decoding, llm-d in production, AI safety, and more.
Plus food, drinks, and the people building this stuff. luma.com/iuecyow4
1
4
14
6,170
Jun 10
Very impressive! Congrats @GoogleDeepMind and the vLLM teams for immediate support.
Jun 10

Congrats to @GoogleDeepMind on DiffusionGemma 🎉 A 26B diffusion language model on the Gemma4 backbone, and the first dLLM natively supported in vLLM.
It denoises 256-token blocks in parallel instead of generating one token at a time: 1200 output tok/s at batch size 1 on a single H200 (FP8).
Built on model runner v2's ModelState plus the existing speculative decoding path, with minimal scheduler or runner changes. FP8 and NVFP4 checkpoints are on the @RedHat_AI hub. Thanks to the @GoogleDeepMind, @RedHat_AI, and @NVIDIAAI teams!
🔗 vllm.ai/blog/2026-06-10-diff…
3
30
1,732
Jun 8
You bring the agent. Red Hat AI makes it production ready.
Red Hat Summit demo: Kagenti for multi-agent import and discovery, SPIFFE/SPIRE for cryptographic workload identity, MCP gateway for secure tool connectivity, OpenTelemetry for end-to-end trace of every reasoning step and tool call, and guardrails that block harmful responses.
youtube.com/watch?v=PiLIijbt…
3
12
863
Red Hat AI retweeted

Jun 8
We’re coming to London this Wednesday!
In collaboration with @NVIDIAAIDev and @SteliaAI , we’re hosting another @vllm_project / @_llm_d_ meetup featuring a great lineup of talks:
• Introduction to the vLLM project
• Inference acceleration via speculative decoding
• Building a managed vLLM service with llm-d
• From cold start to hot tokens
• Data-driven AI safety
Reserve your seat at luma.com/iuecyow4 @RedHat_AI
2
5
585
Jun 8
Most AI agents forget everything between conversations. Hermes Agent doesn't.
It creates reusable skills from completed tasks, persists user memory across sessions, and runs a built-in cron scheduler for autonomous workflows. Deployed on OpenShift AI with @vllm_project for GPU inference, under 10 minutes with oc apply.
Deployment manifests and UBI 9 Dockerfile: github.com/aicatalyst-team/h…
developers.redhat.com/articl…
5
29
10,041
Red Hat AI retweeted

Jun 7
In 2017, I was one of the millions learning ML from @AndrewYNg.
Never imagined that 9 years later, @vllm_project would be collaborating with @DeepLearningAI on a course.
Feeling grateful for the journey 🙏
Jun 4
🎉 The vLLM community just got a free course, built by @RedHat_AI with @DeepLearningAI. It walks through the full optimize → deploy → benchmark lifecycle for serving open models.
Three labs, each on a live vLLM server:
- Compress: quantize a Qwen model with LLM Compressor, then measure the size vs. accuracy tradeoff
- Serve: deploy with vLLM's OpenAI-compatible API and watch continuous batching, PagedAttention, and prefix caching in the live metrics
- Benchmark: simulate traffic with GuideLLM and check quality with lm-eval
A lot of the work went into visualizing what actually happens under inference, thanks to @cedricclyburn: how tokens flow through the model, how the KV cache grows in GPU memory, and what changes when you move from FP16 to INT8/INT4.
~1.5 hours, 9 lessons, 3 labs. Free on DeepLearning.AI.
📝 Read more: vllm.ai/blog/2026-06-03-deep…
8
14
460
44,180
Red Hat AI retweeted

Jun 5
Thanks to Steve Watt for being my first guest on the new season of Technically Speaking! We dive into how we look at emerging tech roadmaps and where we place our internal technology bets at @RedHat: red.ht/49ztcHR.
1
4
11
2,733
Jun 6
Speculators v0.5.0 ships DFlash training support. The Red Hat AI team trained a Gemma 4 31B speculator with it. It beats Eagle 3 and a standalone FP8 quantized verifier on inter-token latency. Combine DFlash with FP8 and the gains stack.
Serve it:
vllm serve -tp 2 RedHatAI/gemma-4-31B-it-speculator.dflash
developers.redhat.com/articl…
2
3
23
1,487
Red Hat AI retweeted

Jun 4
New course on serving LLMs efficiently -- how do you serve models to many concurrent users at low latency and reasonable cost? This short course is built with @RedHat and taught by @cedricclyburn.
Efficient LLM serving requires efficient memory management. A 70B-parameter model takes ~140 GB just to load the weights. On top of that, every active request needs its own chunk of GPU memory, the KV cache, to store the token context it has built up so far. In this course, you'll learn to reduce a model's memory footprint with quantization and serve it using vLLM, which handles many concurrent requests efficiently through smart memory management.
Skills you'll gain:
- Quantize a model and measure the accuracy tradeoff
- Serve a model with vLLM and watch it handle concurrent requests efficiently
- Benchmark your deployment and make informed tradeoffs between speed, cost, and accuracy
Join and learn to serve LLMs efficiently:
deeplearning.ai/courses/fast…
92
140
1,072
104,224
Jun 5
Quantized checkpoints for Nemotron 3 Ultra are up on HuggingFace. FP8 Dynamic, FP8 Block, and W4A16 G128. All three ready to serve with @vllm_project. Running it? Tell us what you're getting.
Links 👇
2
2
35
15,470
Jun 5
FP8 Dynamic: huggingface.co/RedHatAI/NVID…
FP8 Block: huggingface.co/RedHatAI/NVID…
W4A16 G128: huggingface.co/RedHatAI/NVID…
1
9
577
Jun 4
Back at it. @_soyr_ and the team got Nemotron 3 Ultra running on @vllm_project day 0, live curl request to a running endpoint on H200s. Gemma 4 12B on OpenShift AI yesterday too, also day 0. The team delivers.
Jun 4
🚀 Day-0 support for NVIDIA Nemotron 3 Ultra on vLLM!
Ready to be served with the latest vLLM stable release, the new open frontier reasoning model is built for long-running autonomous agents:
🧠 550B total / 55B active — Hybrid Transformer-Mamba MoE
📚 Up to 1M token context
⚡ NVFP4 BF16
🛠️ Tool calling, coding, deep research, orchestration
Read our detailed model launch blog and recipes! recipes.vllm.ai/nvidia/NVIDI…
1
2
25
1,891

At #RHSummit, theCUBE’s @RealStrech & @knightrm spoke with @joefern1 & @addvin about how @RedHat AI 3.4 provides the foundation for #privateAI #sovereignAI to support business use cases.
💡 Get more insights!
thecube.net/events/red-hat/r…
#EnterpriseAI #Cloud #AI #AIOwnership
1
3
44,246
Red Hat AI retweeted

Jun 4
🎉 The vLLM community just got a free course, built by @RedHat_AI with @DeepLearningAI. It walks through the full optimize → deploy → benchmark lifecycle for serving open models.
Three labs, each on a live vLLM server:
- Compress: quantize a Qwen model with LLM Compressor, then measure the size vs. accuracy tradeoff
- Serve: deploy with vLLM's OpenAI-compatible API and watch continuous batching, PagedAttention, and prefix caching in the live metrics
- Benchmark: simulate traffic with GuideLLM and check quality with lm-eval
A lot of the work went into visualizing what actually happens under inference, thanks to @cedricclyburn: how tokens flow through the model, how the KV cache grows in GPU memory, and what changes when you move from FP16 to INT8/INT4.
~1.5 hours, 9 lessons, 3 labs. Free on DeepLearning.AI.
📝 Read more: vllm.ai/blog/2026-06-03-deep…

New short course: Fast & Efficient LLM Inference with vLLM, built in partnership with @RedHat and taught by @cedricclyburn.
Learn to quantize an open-source LLM, serve it with vLLM, and benchmark your deployment across speed, cost, and accuracy.
Free to enroll: hubs.la/Q04jXfpR0
7
39
330
55,802
Jun 4
Gemma 4 12B dropped today. Apache 2.0, multimodal: text, image, audio, and video. 256K context, built-in thinking, native tool calling.
Running on Red Hat OpenShift AI with @vllm_project on Day 0:
3
24
120
15,870
Red Hat AI retweeted
Jun 3
Congrats to the @googlegemma team on the Gemma 4 12B launch 🎉 Day-0 support on vLLM is ready to go.
It's an encoder-free unified multimodal model — text, image, audio, and video all project straight into the LLM's embedding space, no separate vision or audio towers. 256K context, built-in thinking, native tool calling.
Reasoning tool parsers (`gemma4`), vision, and audio all served through the OpenAI-compatible API.
🔗 Recipe: recipes.vllm.ai/Google/gemma…
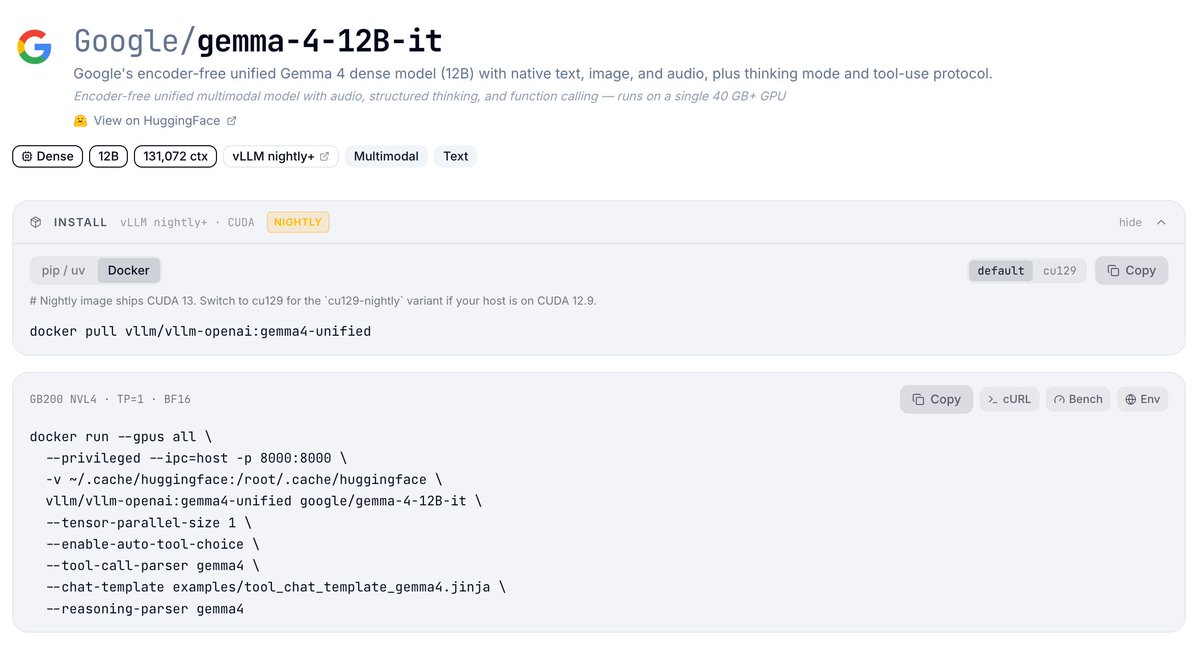
Jun 3

Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

8
35
394
24,449
Red Hat AI retweeted

Jun 3
this course may be on @vllm_project but all the content around LLM fundamentals and compression is applicable to ANY model serving engine. ENJOY :D
2
7
420
Jun 3
This one has been in the works for a while. @cedricclyburn teaching LLM inference, compression, and benchmarking with @vllm_project -- free course with @DeepLearningAI. Proud of this one.
New short course: Fast & Efficient LLM Inference with vLLM, built in partnership with @RedHat and taught by @cedricclyburn.
Learn to quantize an open-source LLM, serve it with vLLM, and benchmark your deployment across speed, cost, and accuracy.
Free to enroll: hubs.la/Q04jXfpR0
3
9
45
4,503
Jun 3
Just in: @NVIDIA is giving away a DGX Spark to a lucky meetup participant in London next week. See you there!
Jun 1

🇬🇧 London, June 10.
@vllm_project & @_llm_d_ Inference Meetup hosted by Red Hat AI, @nvidia, and @SteliaAI at Sustainable Ventures, County Hall.
On the agenda: vLLM project update, speculative decoding, llm-d in production, and AI safety evaluation.
luma.com/iuecyow4
2
12
1,330
Red Hat AI retweeted

Jun 2
Love seeing the work @RedHat_AI and @vllm_project are doing to make Laguna XS.2 easier to run.
Red Hat AI trained a DFlash speculator: a 0.6B drafter that predicts 8 tokens per pass, with Laguna verifying the output.
So builders get faster generation without changing output quality.
With vLLM support and FP8/NVFP4/INT4 checkpoints through LLM Compressor, it’s also easier to tune for different latency, memory, and hardware constraints.
Grateful for the team building the infra that makes open models easier to use, serve, and improve!
May 30
Laguna XS.2 from @poolsideai is a 33B MoE built for agentic coding.
Red Hat AI trained a DFlash speculator for it: 0.6B drafter, 8 tokens per pass, no quality loss.
FP8, NVFP4, and INT4 checkpoints via LLM Compressor.
Models in comments. Speedup with @vllm_project:
2
4
26
2,517
Jun 2
🇹🇷 Istanbul, 17 June.
@vllm_project & @_llm_d_ meetup hosted by Red Hat AI, @nvidia, and BeyondGuard at İTÜ Taşkışla.
On the agenda: vLLM project update, distributed inference, speculative decoding, securing vLLM in production, live demos, and more.
luma.com/cq02xd57
2
28
2,080