
Software Consultant, AI & ML Solutions Architect, developer, Code Craftsman, QA practitioner, mediocre gamer, bad photographer. Thoughts and opinions my own.
Joined July 2016
- Tweets 146
- Following 526
- Followers 76
- Likes 263
8 Photos and videos









30 Jan 2025
A nice take on this one. My personal belief is that the next evolution of #AI will come from a combination of refinements in algorithms to reduce compute cost for training and inference, and the rollout of new, ground breaking models that are open or low-cost to drive uptake
30 Jan 2025

The buzz over DeepSeek this week crystallized, for many people, a few important trends that have been happening in plain sight: (i) China is catching up to the U.S. in generative AI, with implications for the AI supply chain. (ii) Open weight models are commoditizing the foundation-model layer, which creates opportunities for application builders. (iii) Scaling up isn’t the only path to AI progress. Despite the massive focus on and hype around processing power, algorithmic innovations are rapidly pushing down training costs.
About a week ago, DeepSeek, a company based in China, released DeepSeek-R1, a remarkable model whose performance on benchmarks is comparable to OpenAI’s o1. Further, it was released as an open weight model with a permissive MIT license. At Davos last week, I got a lot of questions about it from non-technical business leaders. And on Monday, the stock market saw a “DeepSeek selloff”: The share prices of Nvidia and a number of other U.S. tech companies plunged. (As of the time of writing, some have recovered somewhat.)
Here’s what I think DeepSeek has caused many people to realize:
China is catching up to the U.S. in generative AI. When ChatGPT was launched in November 2022, the U.S. was significantly ahead of China in generative AI. Impressions change slowly, and so even recently I heard friends in both the U.S. and China say they thought China was behind. But in reality, this gap has rapidly eroded over the past two years. With models from China such as Qwen (which my teams have used for months), Kimi, InternVL, and DeepSeek, China had clearly been closing the gap, and in areas such as video generation there were already moments where China seemed to be in the lead.
I’m thrilled that DeepSeek-R1 was released as an open weight model, with a technical report that shares many details. In contrast, a number of U.S. companies have pushed for regulation to stifle open source by hyping up hypothetical AI dangers such as human extinction. It is now clear that open source/open weight models are a key part of the AI supply chain: Many companies will use them. If the U.S. continues to stymie open source, China will come to dominate this part of the supply chain and many businesses will end up using models that reflect China’s values much more than America’s.
Open weight models are commoditizing the foundation-model layer. As I wrote previously, LLM token prices have been falling rapidly, and open weights have contributed to this trend and given developers more choice. OpenAI’s o1 costs $60 per million output tokens; DeepSeek R1 costs $2.19. This nearly 30x difference brought the trend of falling prices to the attention of many people.
The business of training foundation models and selling API access is tough. Many companies in this area are still looking for a path to recouping the massive cost of model training. Sequoia’s article “AI’s $600B Question” lays out the challenge well (but, to be clear, I think the foundation model companies are doing great work, and I hope they succeed). In contrast, building applications on top of foundation models presents many great business opportunities. Now that others have spent billions training such models, you can access these models for mere dollars to build customer service chatbots, email summarizers, AI doctors, legal document assistants, and much more.
Scaling up isn’t the only path to AI progress. There’s been a lot of hype around scaling up models as a way to drive progress. To be fair, I was an early proponent of scaling up models. A number of companies raised billions of dollars by generating buzz around the narrative that, with more capital, they could (i) scale up and (ii) predictably drive improvements. Consequently, there has been a huge focus on scaling up, as opposed to a more nuanced view that gives due attention to the many different ways we can make progress. Driven in part by the U.S. AI chip embargo, the DeepSeek team had to innovate on many optimizations to run on less-capable H800 GPUs rather than H100s, leading ultimately to a model trained (omitting research costs) for under $6M of compute.
It remains to be seen if this will actually reduce demand for compute. Sometimes making each unit of a good cheaper can result in more dollars in total going to buy that good. I think the demand for intelligence and compute has practically no ceiling over the long term, so I remain bullish that humanity will use more intelligence even as it gets cheaper.
I saw many different interpretations of DeepSeek’s progress here in X, as if it was a Rorschach test that allowed many people to project their own meaning onto it. I think DeepSeek-R1 has geopolitical implications that are yet to be worked out. And it’s also great for AI application builders. My team has already been brainstorming ideas that are newly possible only because we have easy access to an open advanced reasoning model. This continues to be a great time to build!
[Original text: deeplearning.ai/the-batch/is… ]
1
56
22 Mar 2024
#AI applications in the #healthcare domain are only set to increase in the coming years. My thoughts on the #challenges and some of the #solutions to them is shared here!
22 Mar 2024

#AI can revolutionize #healthcare, but ensuring success requires a focus on #QE.
Qualitest's @DanielGeater talks about how to navigate AI's transformative power in our new blog.
Read it here bit.ly/3x2qs5j
#ArtificialIntelligence #QualityAssurance #AR #VR
1
4
156
21 Jan 2024
Unreasonably #excited about my new home #officefurniture. I used to be #cool. Ok, maybe not cool, but cooler than this.
1
1
61
7 Nov 2022
This is awesome! I love seeing #ai and #MachineLearning applied to causes like this! Google engineer identifies anonymous faces in WWII photos with AI facial recognition timesofisrael.com/google-eng… via @timesofisrael
22 Oct 2022
Do we laugh or cry though?


Daniel Geater retweeted

8 Oct 2022
All unit tests passing.

ALT Broken sink, with all parts functional, bowl is broken, the tap's casing is gone, you can see all the pipes, but still works.
106
2,198
18,304


Daniel Geater retweeted

1 Jul 2021
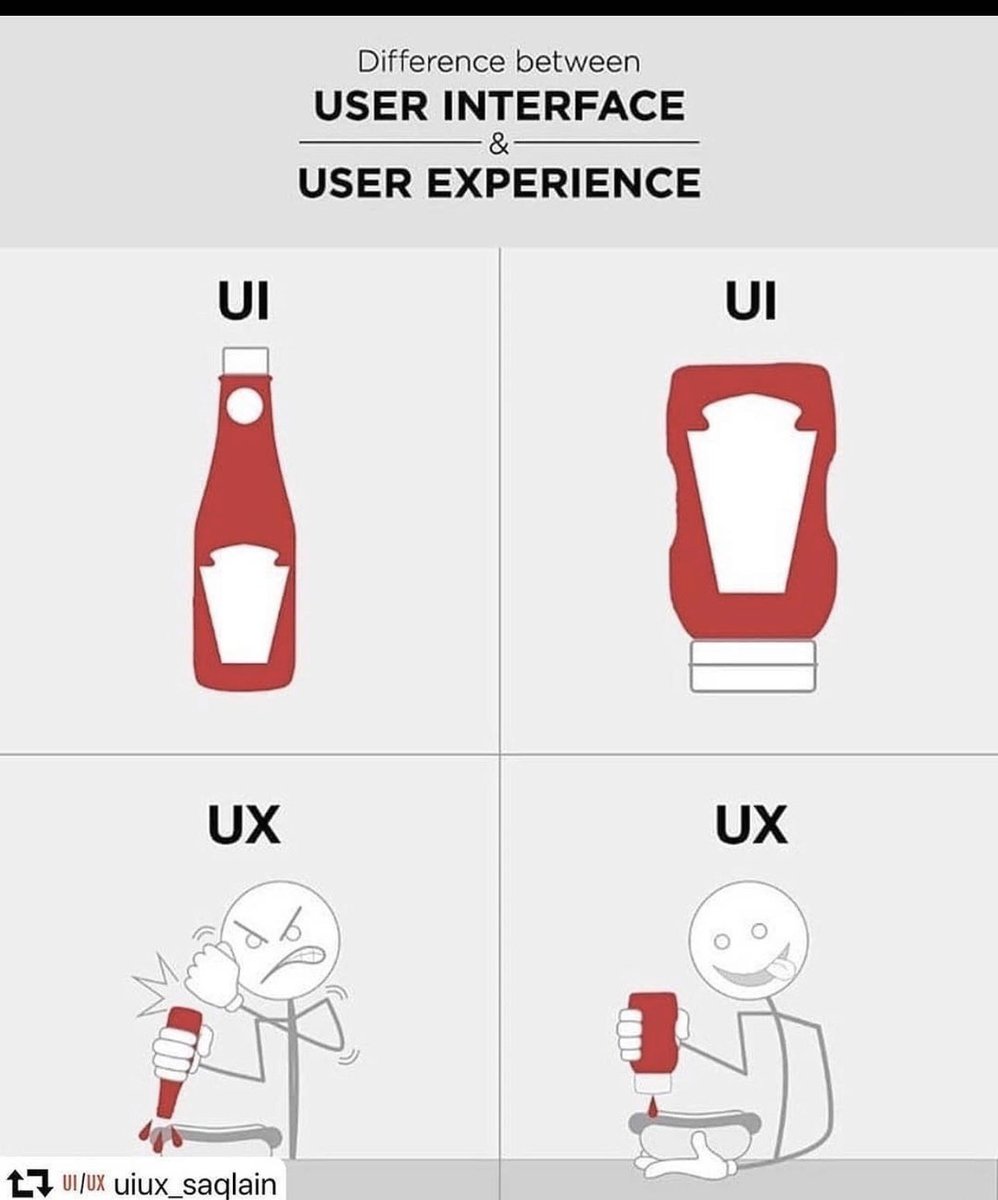
UI is the bottle.
UX is not having to think about the bottle.
96
1,551
6,645
12 Apr 2021
Always nice to start the week with a chuckle
12 Apr 2021

Being vaccinated does NOT mean you can put CSS in your JavaScript. PLEASE continue to keep your concerns separated.
9 Apr 2021
Great to see @Qualitest as a finalist for best #AI company!
9 Apr 2021
We are excited to announce that Qualitest is the Finalist in the British Data Awards 2021!
@PredatechSec
#qualityassurance #qualityengineering #softwaretesting
predatech.co.uk/british-data…

1
Daniel Geater retweeted

28 Aug 2020
Have you registered for our QA Optimization #webinar yet?
Register now to learn the practical steps to consider in order to make your #QA organization more intelligent and efficient bit.ly/316GrwO
#AI #ArtificialIntelligence
@dshotten1 @DanielGeater @MiGiacometti
1
1
19 Aug 2020
Tune in to hear me talk with @dshotten1 and @MiGiacometti on @Qualitest upcoming #webinar where we will take a look at how #AI and #ML can be used to help #optimise your #QA and #QE
19 Aug 2020
Join us for our new #webinar on ‘QA Optimization: Scientifically Optimize Your Processes with AI’ as we discuss how #AI can drive next generation test assessment and maturity models.
Register now bit.ly/316GrwO
#QualityAssurance
@dshotten1 @DanielGeater @MiGiacometti

1
Daniel Geater retweeted

10 Aug 2020
Government paid Vote Leave AI firm to analyse UK citizens' tweets theguardian.com/world/2020/a…
6
25
22
7 Aug 2020
Solid points echoing some I’ve held and shared in the past. Coverage alone doesn’t guarantee #softwarequality, it’s a useful metric and should serve as one of many #software teams use to inform decisions. It needs tempering with mature #code/#design review & #automation layering
1
Daniel Geater retweeted

4 Aug 2020
The AI-based ~QA market is evolving. @Qualitest introduces an AI-based consulting and assessment service. Here is our take on it
research.nelson-hall.com/blo…

3
5
Daniel Geater retweeted

30 Jul 2020
DeepSpeed with ZeRO optimizer greatly reduces the resources needed for model and data parallelism while massively increasing the number of parameters that can be trained. You can now register for @MSFTResearch's webinar & live Q&A to learn more about it: aka.ms/AA94sfc.
15
36







21 Jul 2020
Very interesting project by Facebook AI. I’ll be interested to see how this grows and the impact this kind of technology will have on modernising legacy applications. Someone is going to have fun doing the regression #testing on a machine translated application though!
21 Jul 2020

We’ve developed TransCoder, the first self-supervised neural transcompiler system for migrating code between programming languages. Transcoder can translate code from Python to C , for example, and it outperforms rule-based translation programs. ai.facebook.com/blog/deep-le…
1
7 May 2020
Second that, IntelliJ is my go to, although VS Code is a close second.
7 May 2020

Jetbrains IntelliJ (even though it embarrassed me today on my live stream)
1