
Joined August 2021
- Tweets 169
- Following 337
- Followers 4,018
- Likes 203
50 Photos and videos





Pinned Tweet

28 May 2025
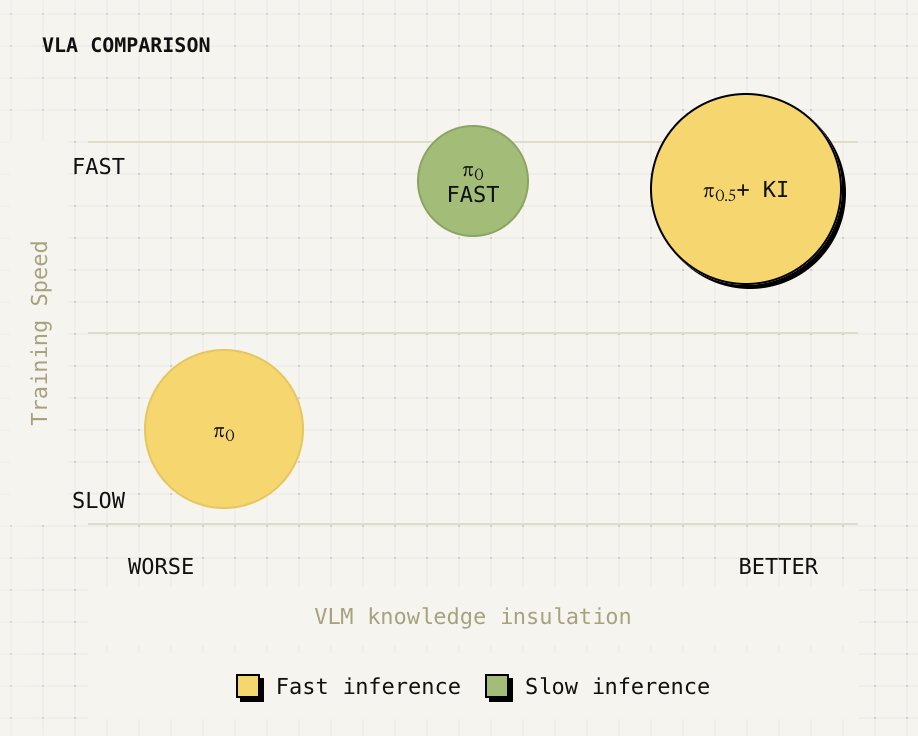
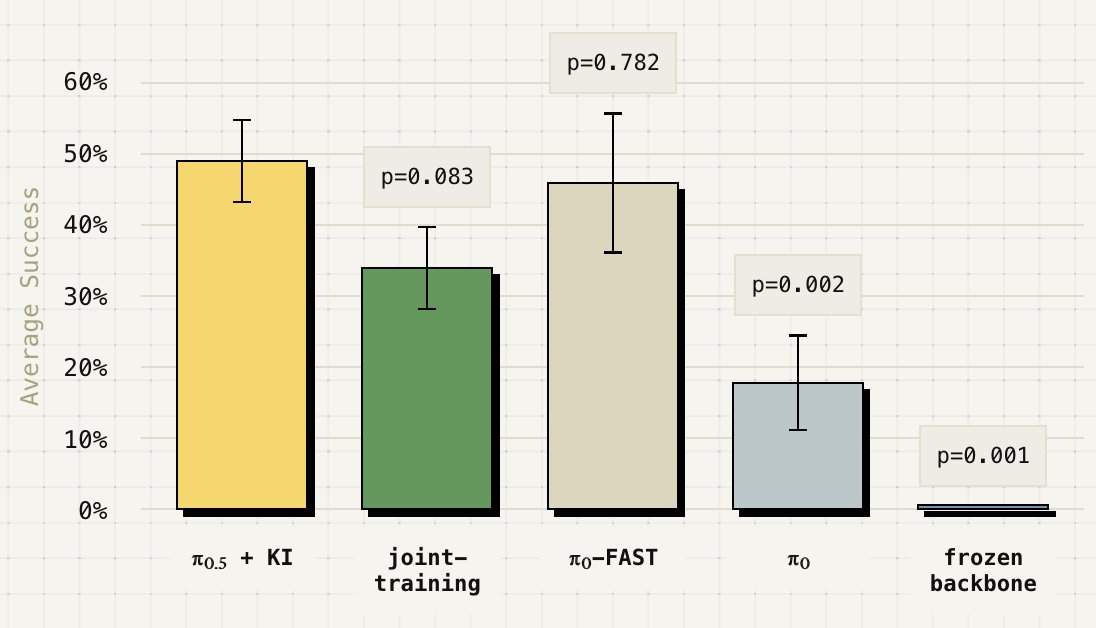
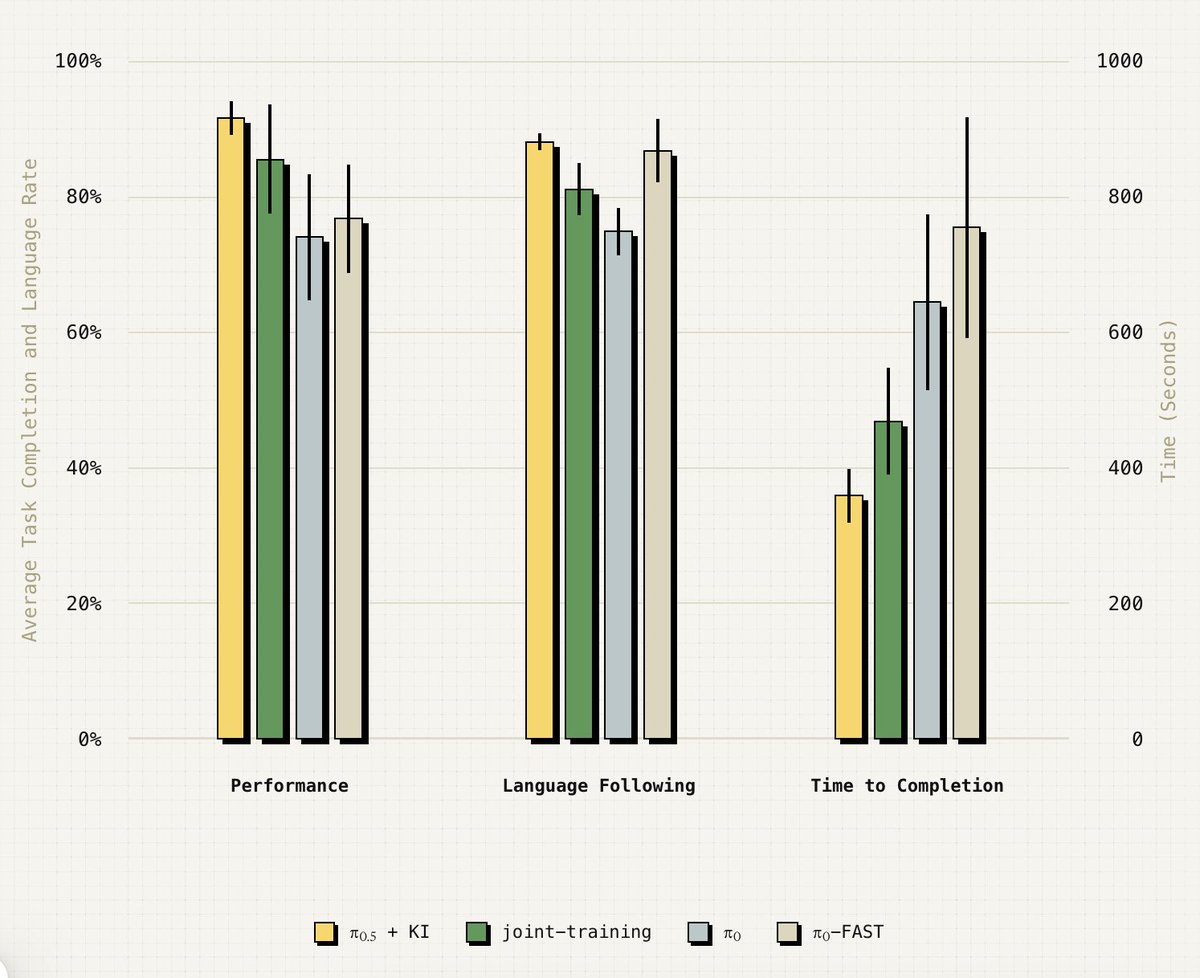
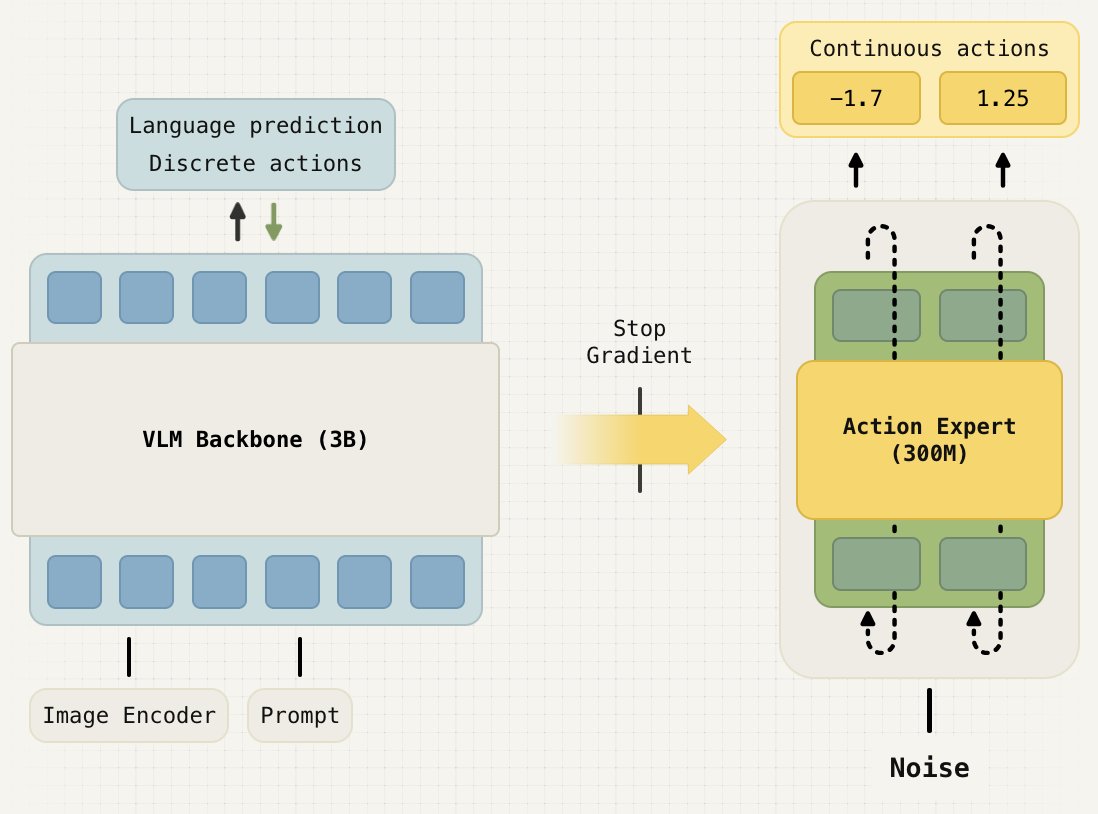
How to build vision-language-action models that train fast, run fast & generalize? In our new paper, we formalize & analyze the approach of our π-0.5 model & further improve it with a single stage recipe.
Blog: pi.website/research/knowledg…
Paper: pi.website/download/pi05_KI.…
6
26
220
19,543
Apr 16
The most exciting aspect of modern machine learning, in my opinion, is that one can train models that just work for many tasks, without finetuning.
π0.7 is a major step in that direction for robots

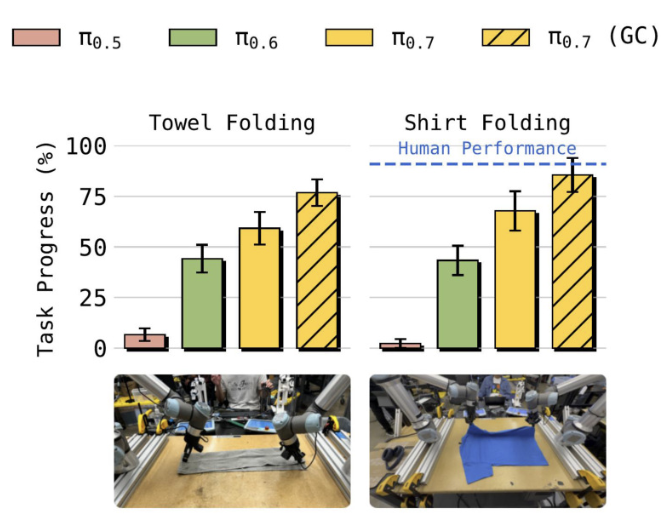
Our newest model, π0.7, has some interesting emergent capabilities: it can control a new robot to fold shirts for which we had no shirt folding data, figure out how to use an appliance with language-based coaching, and perform a wide range of dexterous tasks all in one model!
3
2
41
8,045
Apr 16
and we see strong cross embodiment generalization for dexterous tasks
2
181
Apr 16
π0.7's training recipe builds upon Knowledge Insulation x.com/DannyDriess/status/192…
and our recent memory work x.com/DannyDriess/status/202…
Mar 3

Many real-world tasks require memory to be successful. Yet, most robots don’t have any form of memory. Today, we are going to change that. We developed a system called MEM that introduces memory into VLAs on multiple scales
1
223
Danny Driess retweeted

We developed an RL method for fine-tuning our models for precise tasks in just a few hours or even minutes. Instead of training the whole model, we add an “RL token” output to π-0.6, our latest model, which is used by a tiny actor and critic to learn quickly with RL.
37
292
2,191
429,706
Danny Driess retweeted

Mar 3
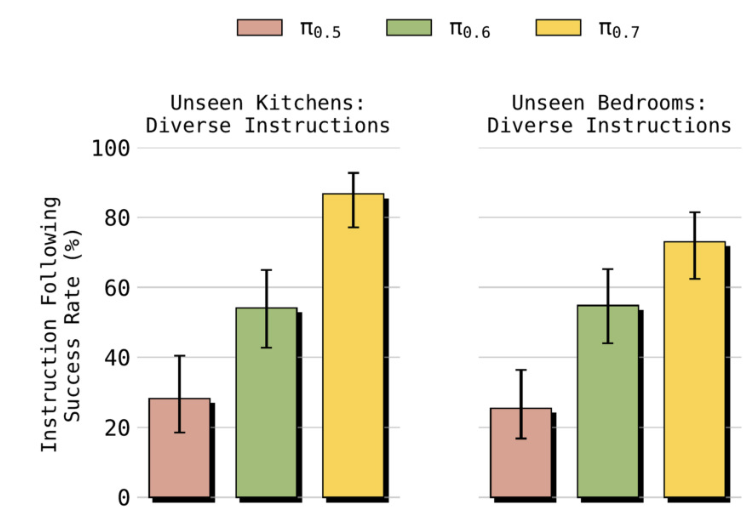
this robustness allows the policy to do diverse, long horizon tasks in unseen environments
for example, the demo kitchen was built *after* the potatoes policy was fully trained — I just wrote the high level prompt to tell it where to go look for items and it did the rest

1
2
34
2,740
Danny Driess retweeted

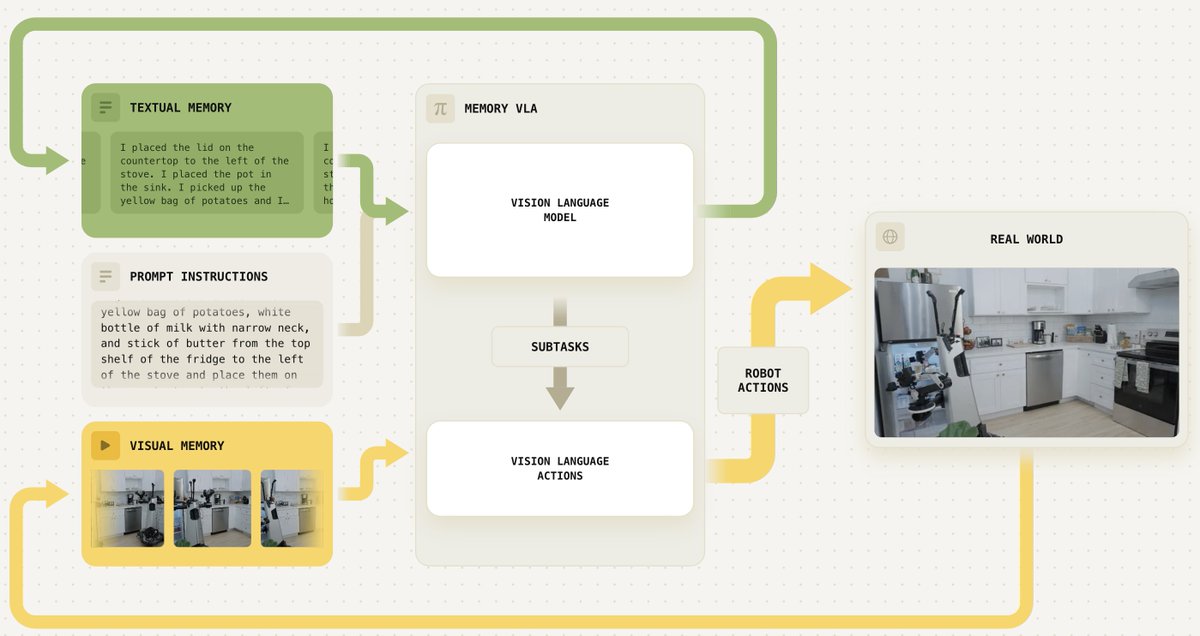
We equipped PI policies with memory!
And taught our robots to do long-horizon real world tasks such as preparing the items for a recipe, cooking a grilled cheese and cleaning the kitchen!
We’ve developed a memory system for our models that provides both short-term visual memory and long-term semantic memory.
Our approach allows us to train robots to perform long and complex tasks, like cleaning up a kitchen or preparing a grilled cheese sandwich from scratch 👇
8
15
89
10,198
Danny Driess retweeted

Mar 3
This one has been a long time coming: today we’re introducing MEM, an approach for giving VLAs short-term and long-term memory.
Memory is such an obvious capability, but adding it isn’t easy (most VLAs today are memory-less). A short thread on challenges, solutions, and the new capabilities MEM unlocks for us.
8
11
113
9,551
Mar 4
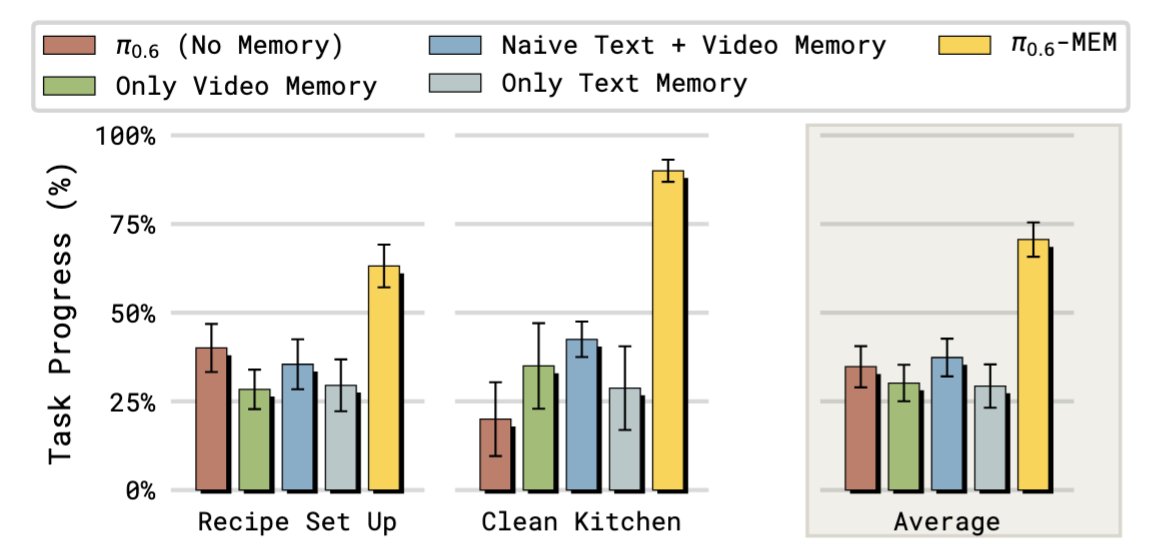
If you look at this plot here, you can see that both short- and long-term memory were important to make long-horizon tasks work well
We’ve developed a memory system for our models that provides both short-term visual memory and long-term semantic memory.
Our approach allows us to train robots to perform long and complex tasks, like cleaning up a kitchen or preparing a grilled cheese sandwich from scratch 👇
2
15
972
Mar 3
Many real-world tasks require memory to be successful. Yet, most robots don’t have any form of memory. Today, we are going to change that. We developed a system called MEM that introduces memory into VLAs on multiple scales
We’ve developed a memory system for our models that provides both short-term visual memory and long-term semantic memory.
Our approach allows us to train robots to perform long and complex tasks, like cleaning up a kitchen or preparing a grilled cheese sandwich from scratch 👇
5
11
63
5,598
Mar 3
The key idea behind Multi-Scale Embodied Memory (MEM): use different modalities to represent memory at different time scales.
📹 For short horizon memory, we developed an efficient video encoder that lets the model remember fine-grained details about its recent interactions.
📜 For long horizon memory, we train the model to summarize events in text, allowing it to remember events for up to 15 min.
1
3
447
Mar 3
One aspect I am particularly excited about is that memory enables the model to adapt its strategy while solving the task, something we can coin “in-context adaptation”.
In this example, it is unclear from a single image whether the fridge opens from the left or the right. Hence, a model without memory (left) might fail to open the fridge repeatedly. In contrast, with memory (right), our model learns “in-context” that the fridge opens differently, and adjusts its strategy accordingly.
3
353
Danny Driess retweeted
General-purpose AI models are behind some of the most exciting applications we now can't live without. We envision that an analogous “physical intelligence layer” built with models like π0.6 will similarly spur a new wave of applications for the physical world.
We’ve recently begun working with a handful of companies that have deployed their robots to do real-world, useful things.
pi.website/blog/partner/?v=1
9
91
743
177,093
Feb 16
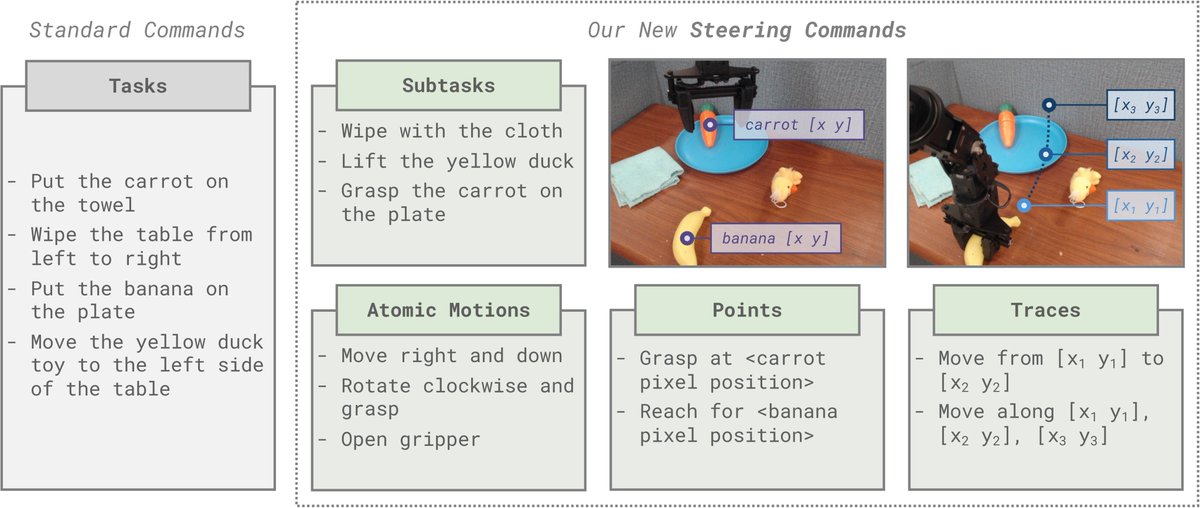
Check out our latest work on steerable policies. Instead of having only language as the interface to a VLA, steerable policies follow point queries, motion traces, atomic subtasks and more, which allows us to make better use of VLMs controlling them. More in @verityw_'s thread

How can robot policies be trained to best leverage VLMs' CoT reasoning and in-context learning for generalization?
The key is Steerable Policies: vision-language-action models that can be flexibly controlled in many ways!
steerable-policies.github.io
1/9

1
1
9
694
Feb 16
What I like about this: If I want to explain someone how to solve a task, I rarely use language alone, I might point at things, wave in the air, without restricting myself to only one interface to communicate my intent. This work brings this idea into VLAs.
1
1
240
Feb 16
Project led by @verityw_ with @JagdeepBhatia8, @CatGlossop, Nikhil Mathihalli, @riadoshi21, @tangerinecoder, @KarlPertsch, @svlevine
1
256
18 Nov 2025
The base model powering π*0.6 is trained with Knowledge Insulation x.com/DannyDriess/status/192…
18 Nov 2025
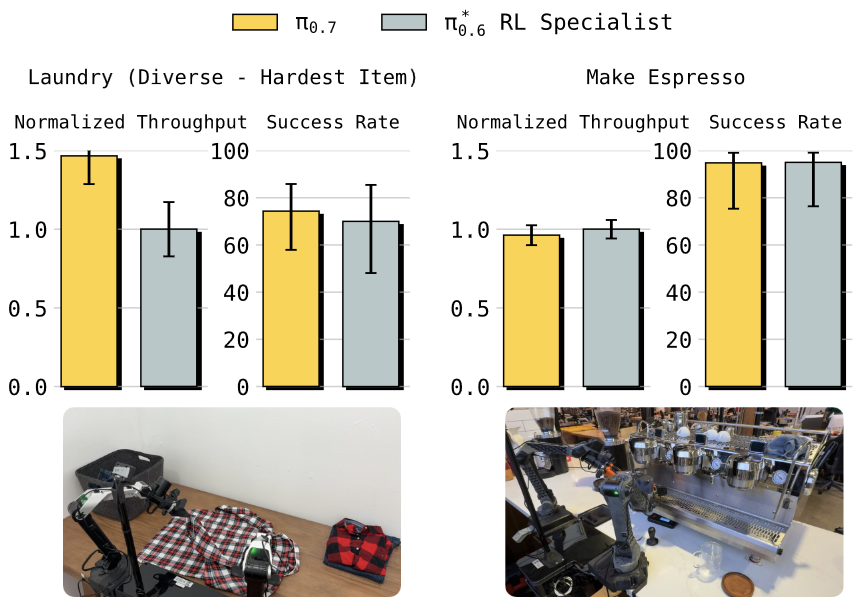
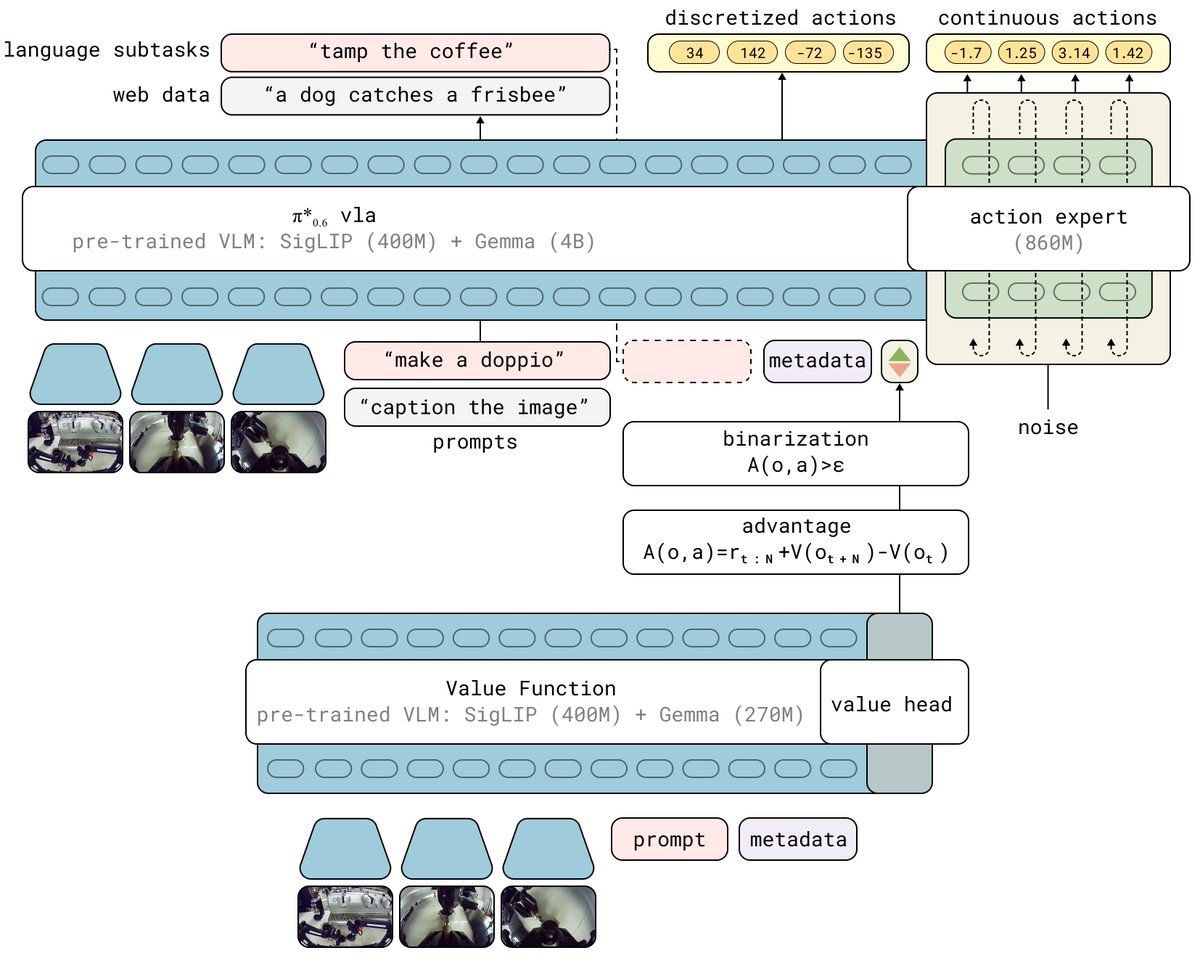
Our model can now learn from its own experience with RL! Our new π*0.6 model can more than double throughput over a base model trained without RL, and can perform real-world tasks: making espresso drinks, folding diverse laundry, and assembling boxes.
More in the thread below.
1
11
1,189
18 Nov 2025
The idea behind significantly improving the performance on hard real-world tasks is to train a value function, condition the model on advantages computed from the value function, and running an iterative improvement loop where the model learns from it’s own data.
1
6
331