
recovering R-addict, dataholic, visual-maniac, so rather plain person
Joined September 2018
- Tweets 261
- Following 100
- Followers 109
- Likes 382
35 Photos and videos






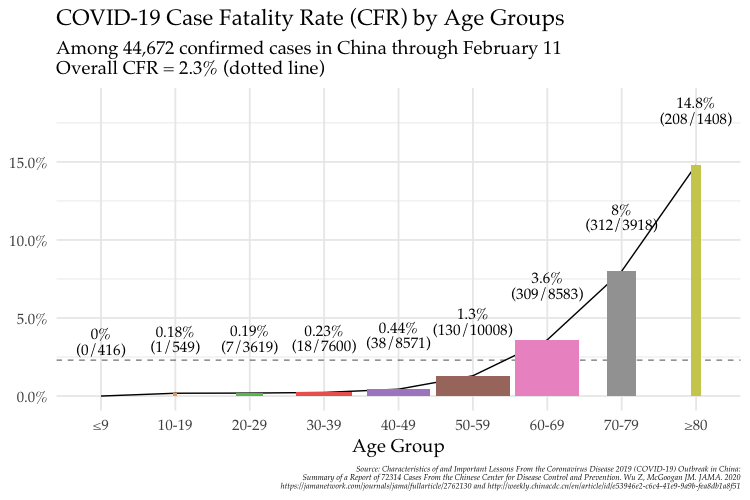
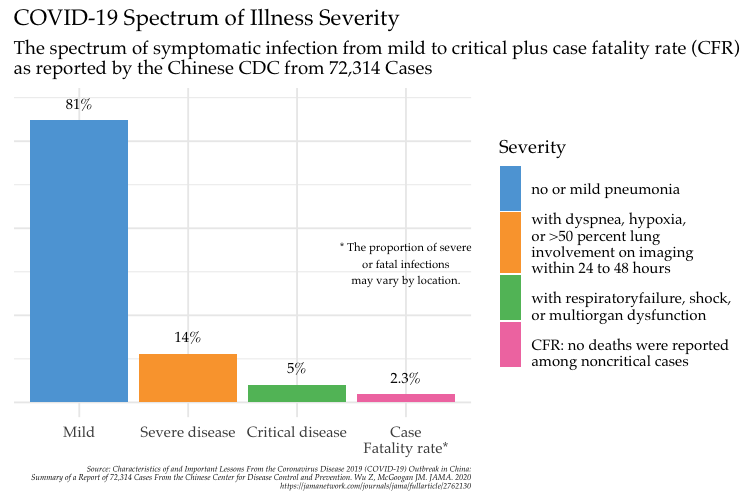

6 Nov 2025
Integrating RAGChecker metrics in Inspect-ai tasks linkedin.com/pulse/integrati… via @LinkedIn
13
17 Aug 2024
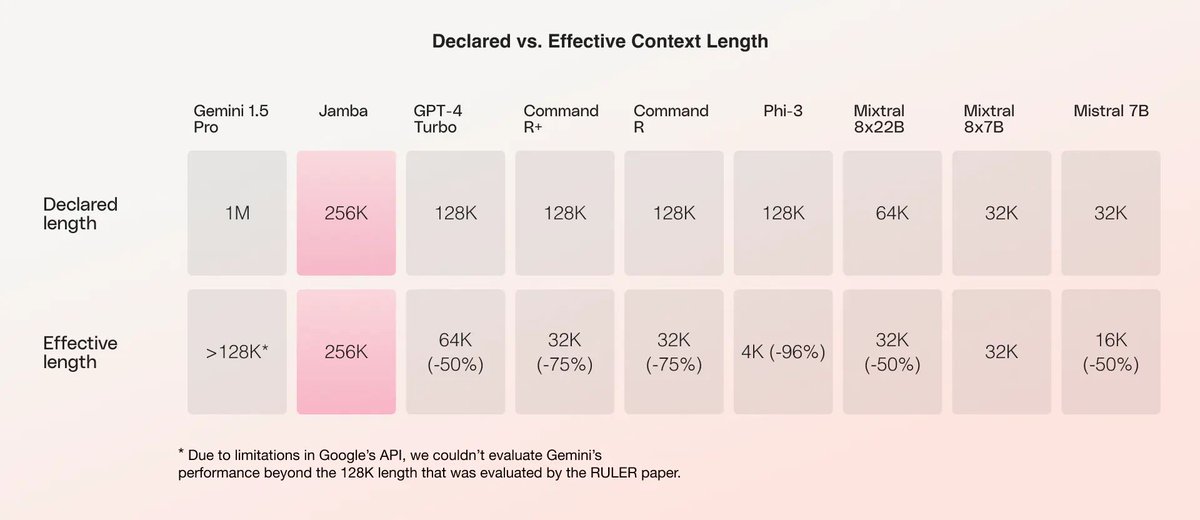
Context window is one of key LLM features, but what vendors declare almost never the same as effective context length. Check out this graph showing @AI21's #Jamba's declared vs. effective #contextwindow
21

Hack by popular demand!
Open-Source Agent #Hackathon with @AndrewYNg & @DeepLearningAI at @agihouse_org Saturday, *August 24th*
Stellar schedule planned w/ secret guest speakers, alongside co-hosts, @GroqInc & @langchain.
Reserve your spot now --> eu1.hubs.ly/H0bJRt70

1
6
16
4,151
GregoryKanevsky retweeted

9 Jun 2024
📽️ New 4 hour (lol) video lecture on YouTube:
"Let’s reproduce GPT-2 (124M)"
youtu.be/l8pRSuU81PU
The video ended up so long because it is... comprehensive: we start with empty file and end up with a GPT-2 (124M) model:
- first we build the GPT-2 network
- then we optimize it to train very fast
- then we set up the training run optimization and hyperparameters by referencing GPT-2 and GPT-3 papers
- then we bring up model evaluation, and
- then cross our fingers and go to sleep.
In the morning we look through the results and enjoy amusing model generations. Our "overnight" run even gets very close to the GPT-3 (124M) model. This video builds on the Zero To Hero series and at times references previous videos. You could also see this video as building my nanoGPT repo, which by the end is about 90% similar.
Github. The associated GitHub repo contains the full commit history so you can step through all of the code changes in the video, step by step.
github.com/karpathy/build-na…
Chapters.
On a high level Section 1 is building up the network, a lot of this might be review. Section 2 is making the training fast. Section 3 is setting up the run. Section 4 is the results. In more detail:
00:00:00 intro: Let’s reproduce GPT-2 (124M)
00:03:39 exploring the GPT-2 (124M) OpenAI checkpoint
00:13:47 SECTION 1: implementing the GPT-2 nn.Module
00:28:08 loading the huggingface/GPT-2 parameters
00:31:00 implementing the forward pass to get logits
00:33:31 sampling init, prefix tokens, tokenization
00:37:02 sampling loop
00:41:47 sample, auto-detect the device
00:45:50 let’s train: data batches (B,T) → logits (B,T,C)
00:52:53 cross entropy loss
00:56:42 optimization loop: overfit a single batch
01:02:00 data loader lite
01:06:14 parameter sharing wte and lm_head
01:13:47 model initialization: std 0.02, residual init
01:22:18 SECTION 2: Let’s make it fast. GPUs, mixed precision, 1000ms
01:28:14 Tensor Cores, timing the code, TF32 precision, 333ms
01:39:38 float16, gradient scalers, bfloat16, 300ms
01:48:15 torch.compile, Python overhead, kernel fusion, 130ms
02:00:18 flash attention, 96ms
02:06:54 nice/ugly numbers. vocab size 50257 → 50304, 93ms
02:14:55 SECTION 3: hyperpamaters, AdamW, gradient clipping
02:21:06 learning rate scheduler: warmup cosine decay
02:26:21 batch size schedule, weight decay, FusedAdamW, 90ms
02:34:09 gradient accumulation
02:46:52 distributed data parallel (DDP)
03:10:21 datasets used in GPT-2, GPT-3, FineWeb (EDU)
03:23:10 validation data split, validation loss, sampling revive
03:28:23 evaluation: HellaSwag, starting the run
03:43:05 SECTION 4: results in the morning! GPT-2, GPT-3 repro
03:56:21 shoutout to llm.c, equivalent but faster code in raw C/CUDA
03:59:39 summary, phew, build-nanogpt github repo

412
2,169
15,356
1,526,156
18 Jun 2024
Come join @AI21Labs #Jambathon at the @AGIHouseSF on June 22nd to hack away with Jamba, the groundbreaking fusion of Mamba and Transformer architectures.
agihouse-app.web.app/events/…
1
37
18 Jun 2024
If you're a developer, this is probably the first chance you'll get to hack using a model that was developed with Mamba. Prizes include up to $5K in credits to build apps with Jamba on AI21 Studio (and lots of fun swag too!). Come meet the AI21 team and hack with us.
15
19 Oct 2023
pyenv virtualenv :
> pyenv versions (once)
> pyenv virtualenv <desired python version> <virtual env name> (once)
> pyenv activate <virtual env name> (every time)
> pip install -r requirements.txt (once)
> pyenv deactivate (every time)
1
117
2 Feb 2024
Upgrade pip
> pip install --upgrade pip
Install Python
> pyenv install -s 3.10.13
Remove virtual env
> pyenv virtualenv-delete [virtual-env-name]
1
63
26 Mar 2024
Setup shell
> echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc
> echo '[[ -d $PYENV_ROOT/bin ]] && export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc
> echo 'eval "$(pyenv init -)"' >> ~/.zshrc
Activate virtualenv automatically in your project
> pyenv local [virtual-env-name]
39
1 Feb 2024
Git
remove local branches after they were deleted in remote repo likely by closing PRs :
> git fetch --all -p; git branch -vv | grep ": gone]" | awk '{ print $1 }' | xargs -n 1 git branch -d
35
GregoryKanevsky retweeted

18 May 2023
Artificial Intelligence: The Good, The Bad and The Ugly - Free public lecture on May 24 by Professor Abu-Mostafa of @Caltech to explain the science of AI in plain language and assess extreme scenarios.
work.caltech.edu/watson
#MachineLearning #ArtificialIntelligence #AI #chatGPT

9
37
104
7,048



26 Jan 2023
ChatGPT as an anti-pattern
26 Jan 2023

Idea: Before writing an essay, have ChatGPT write one on the same topic to show you what would be the conventional thing to say, so you can avoid saying that.
35
26 Jan 2023
This applies to job seekers as much as to investors and founders
25 Jan 2023

Marc Andreessen has grown a16z from their first fund of $300M in 2009 to over $25B in AUM as of 2022.
His framework for understanding any business is simple. It comes down to unpacking what he calls "the onion theory of risk."
Here's what he means...
30