
Empowering the next generation of data professionals 🚀 • AI/Data Engineer • Building @wisabiHQ
Joined September 2019
- Tweets 1,641
- Following 59
- Followers 4,117
- Likes 3,656
194 Photos and videos







Pinned Tweet

30 Jun 2023
Do you want to become a world-class data analyst in just 6 months?
I’ve been there, and I know how overwhelming it can be to learn data analysis from scratch.
That’s why I’ve created a 6-month roadmap of free high-quality resources that will teach you everything you need to know, from statistics and Excel to Python and cloud computing.
In this thread, I’ll share with you my ultimate roadmap and how you can download it for free.
Let’s get started! 👇
74
972
2,192
332,271
Yesterday at PyData Leeds I shared a simple idea:
The cheapest AI inference is the one you never make.
Instead of sending every document to an LLM, process locally first and escalate only uncertain cases.
The result:
✅ Lower cost
✅ Lower latency
✅ Better reliability
Thanks to everyone who attended the session on Local-First AI. Great questions and discussions afterwards. 🚀
#PyData #Python #AIEngineering #LLM #MLOps
4
5
30
Obinna Iheanachor retweeted
Spoke at @JumpingRivers’ AI in Production conference today
Production AI. Trust by design.
Great room. Insightful questions. Fantastic experience overall!
2
7
58
Obinna Iheanachor retweeted
May 20
Spoke at Leeds Data Science meetup last night - From £8,000 to £40: What I Learned Shipping AI in a UK Engineering Company.
4,700 engineering drawings. 4 weeks of manual work → 45 minutes. The model was the least interesting part.
Sharp room, great questions. Thanks @jumping_uk for the invite

2
8
229
Obinna Iheanachor retweeted

Interested in the intersection of data science, electoral politics, and scenario analysis? Don't miss @DataSenseiObi's latest exploration, written just ahead of the May 7 UK elections. towardsdatascience.com/when-…
2
3
1,010
Hey #datafam
UK local elections today. Just published in @TDataScience
Across 64 English authorities and six modelled scenarios, the strongest shock is only 13% of the calibrated uncertainty band.
Scenarios sit inside the noise.
towardsdatascience.com/when-…
6
7
1,856
Obinna Iheanachor retweeted
Ahead of the May 7 elections in the UK, @DataSenseiObi continues his analysis and scenario modeling series, focusing on calibrated uncertainty, historical error, and why some models are most useful when they refuse to forecast. towardsdatascience.com/when-…
1
3
985
Obinna Iheanachor retweeted
Hey #datafam
Ahead of the UK local elections tomorrow, I just published a Tableau scenario dashboard for the 2026 cycle.
Finding: the strongest modelled shock is only 13% of the median uncertainty band. Scenarios sit inside the noise.
public.tableau.com/app/profi…
5
5
177
Obinna Iheanachor retweeted
For his latest deep dive, @DataSenseiObi presents a data-quality case study on English local elections, covering categorical normalisation, metric validation, and why raw labels should never define analytical groups. towardsdatascience.com/fract…
3
6
1,293
Obinna Iheanachor retweeted
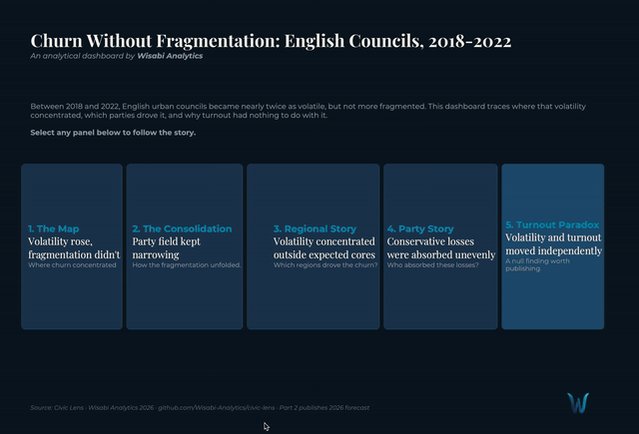
I got it wrong.
A bug flipped my entire result: fragmentation didn’t rise in 66/67 councils. It rose in just 18.
What actually changed? Voter churn doubled. The party system didn’t fragment.
@TDataScience towardsdatascience.com/fract…
@tableau public.tableau.com/app/profi…
6
7
1,997
Obinna Iheanachor retweeted
Whether you're interested in British politics or in smart data-analysis techniques, @DataSenseiObi's data quality case study is a must-read. towardsdatascience.com/fract…
2
5
1,228
Apr 10
Quick survey for UK data professionals:
How is AI actually impacting your work? (not the hype)
2 mins. Anonymous.
👉 forms.gle/oSLEDTmvsQUYEpAq9
1
3
97
Obinna Iheanachor retweeted
Follow along @DataSenseiObi's thorough project walkthrough to learn how a hybrid PyMuPDF GPT-4 Vision pipeline replaced £8,000 in manual engineering effort, and why the latest models weren’t the answer. towardsdatascience.com/from-…
3
11
1,257
Obinna Iheanachor retweeted
We're thrilled to welcome @DataSenseiObi to TDS! Click below to explore his comprehensive walkthrough on designing a streamlined, rapid document-extraction system. towardsdatascience.com/from-…
1
10
1,094
Obinna Iheanachor retweeted
I replaced £8,000 of manual work with ~$15 in API calls.
4,700 PDFs. 45 minutes. 96% accuracy.
Published on @TDataScience 👇
towardsdatascience.com/from-…
Here’s the architecture (and why GPT-5 wasn’t the answer) 🧵
2
7
12
2,332
Obinna Iheanachor retweeted

Apr 7
This article is very well explained. As someone new to the field, I was able to clearly understand the problem the approach solves. I especially appreciated the discussion around why different approaches were chosen and how they align with stakeholder needs.
1
1
1
75
I replaced £8,000 of manual work with ~$15 in API calls.
4,700 PDFs. 45 minutes. 96% accuracy.
Published on @TDataScience 👇
towardsdatascience.com/from-…
Here’s the architecture (and why GPT-5 wasn’t the answer) 🧵
2
7
12
2,332
What actually broke the system:
→ revision tables mistaken for current values
→ grid letters (A, B, C) read as revisions
→ PDFs rotated with incorrect metadata
None of this showed up in small tests.
2
2
78
If you’ve built extraction pipelines:
What edge case broke yours at scale?
1
44