
Joined September 2025
- Tweets 23
- Following 23
- Followers 16
- Likes 8
1 Photos and videos

Blubridge - Data retweeted

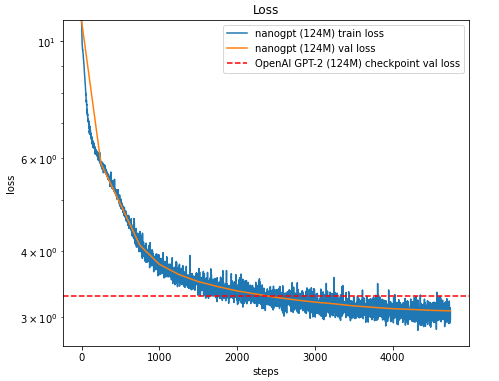
What happens when you train GPT-2 the right way?
We trained a GPT-2 124M model using @Data_team89 's SOTA training pipeline—and the results exceeded expectations.
It shows how data quality, scalable systems design, and efficient training still matter in modern LLMs. (1/4)
2
6
13
2,029

A tiny change can change everything.
The Lorenz system demonstrates the “butterfly effect,” where subtle differences in initial conditions lead to very different outcomes. This simulation visualizes that divergence across 10 starting points.
Check it out ⤵️ 🦋
33
382
2,762
224,140
Blubridge - Data retweeted

26 Nov 2025
Our team presented the process behind "Blu-WERP", our pipeline that sets a new industry standard for scalable, high-quality LLM pretraining data this month.
In our paper, we demonstrate training and evaluation details, including the data preparation pipeline, from JusText extraction to Benchmark-targeted classification that enabled us to outperform DCLM by 4.0% and FineWeb by 9.5% aggregate across 9 benchmarks.
Learn more: arxiv.org/abs/2511.18054
6
17
438

8 Nov 2025
Your favorite LLM's benchmark score is basically meaningless. The same model can jump 30 points on the same test just by changing the prompt format. We're in a measurement crisis and nobody's talking about it.
1
2
74
8 Nov 2025
Why this matters: During training, you need reliable signals. Did your model actually improve or did you just tweak the eval? Is architecture X better than Y or did you use different shots? The field is making billion-dollar decisions on unreliable data.
1
2
54
8 Nov 2025
What we need: Fully documented, reproducible evaluation protocols. Every prompt template, every normalization method, every shot selection—published and versioned. No more "trust me" benchmarks. The future of AI progress depends on us measuring things the same way.
2
44
3 Nov 2025
1) Good parsers are essential for model pretraining — they strip boilerplate (nav, ads, footers), keep content-rich passages, reduce noise & storage, lower compute cost, and improve retrieval generation. Better data → better models.
1
2
48
3 Nov 2025
4)Better approach: run stronger content parsers. Tools like Resiliparse, Trafilatura, and jusText strip boilerplate and surface coherent paragraphs. Per Nemo Curator evaluations, jusText/trafilatura tends to outperform the others in output quality and retention.
1
2
45
3 Nov 2025
5)Takeaway: for pretraining / domain adaptation, prefer parser-cleaned text (optimize signal-to-noise). Always sample & evaluate (retention vs quality) before scaling up.
2
31
27 Oct 2025
1️⃣ Why Deduplication Matters
Redundant text inflates token counts, distorts word frequencies & causes train–test overlap. For LLM pretraining, this leads to memorization & wasted compute. We needed scalable methods to detect both exact & near duplicates.
1
2
55
27 Oct 2025
8️⃣ Comparison Summary
MinHash = fast near-dupe detection.
Suffix arrays = accurate but heavy.
Bloom filters = efficient, scalable & simple.
The Old-Both Bloom design delivered production-ready performance for billion-document LLM pipelines.
1
2
43
27 Oct 2025
9️⃣ Takeaway
Bloom-filter-based deduplication gave the best mix of accuracy scalability. It efficiently removed both exact & near-duplicate text, keeping our LLM corpus clean, diverse & memory-efficient.
2
33