
Creating parallelism frameworks @BlubridgeAI
Joined September 2025
- Tweets 44
- Following 67
- Followers 31
- Likes 50
19 Photos and videos




Why let your Dataloader be the bottleneck?
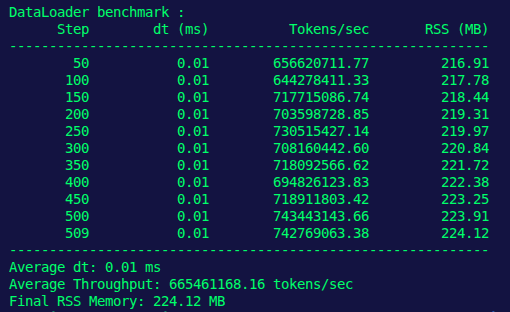
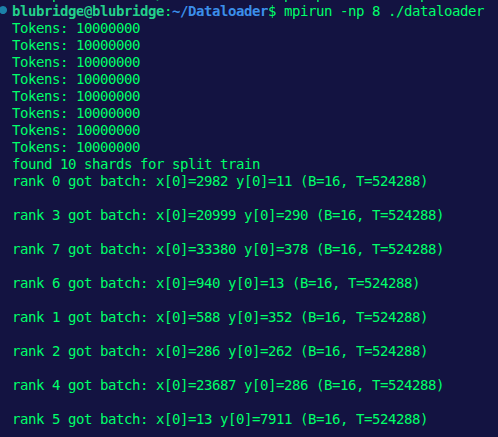
Built a custom C /CUDA dataloader hitting 665M tokens/sec on a single GPU and sub-millisecond batch loading (0.01ms) with minimal CPU overhead for AI training and ML pipelines.
Here’s the secret sauce behind the speed👇 (1/6)
2
4
8
313
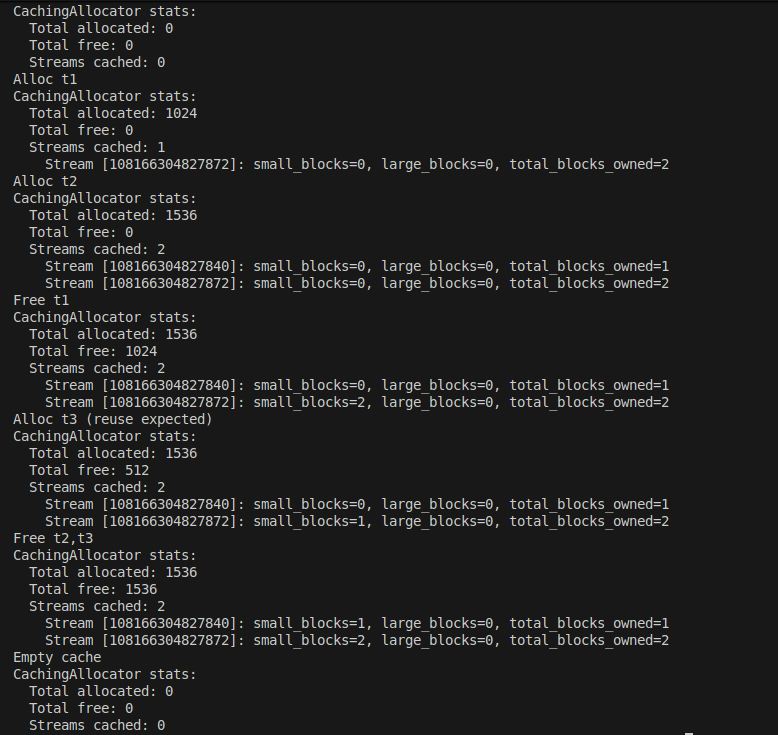
Why allocate tensors every step and pay the latency cost?
We pre-allocate Input/Target tensors and reuse them across the entire training run–no on-the-fly allocation, zero fragmentation, zero allocation lag. More stable memory, faster batches, smoother training. (5/6)
1
1
3
30
What does this optimization stack deliver?
665M tokens/sec throughput with 0.01ms batch latency and only 224MB RSS footprint.
Result: High-throughput C /CUDA dataloading for GPU training and scalable ML pipelines. (6/6)
1
3
30
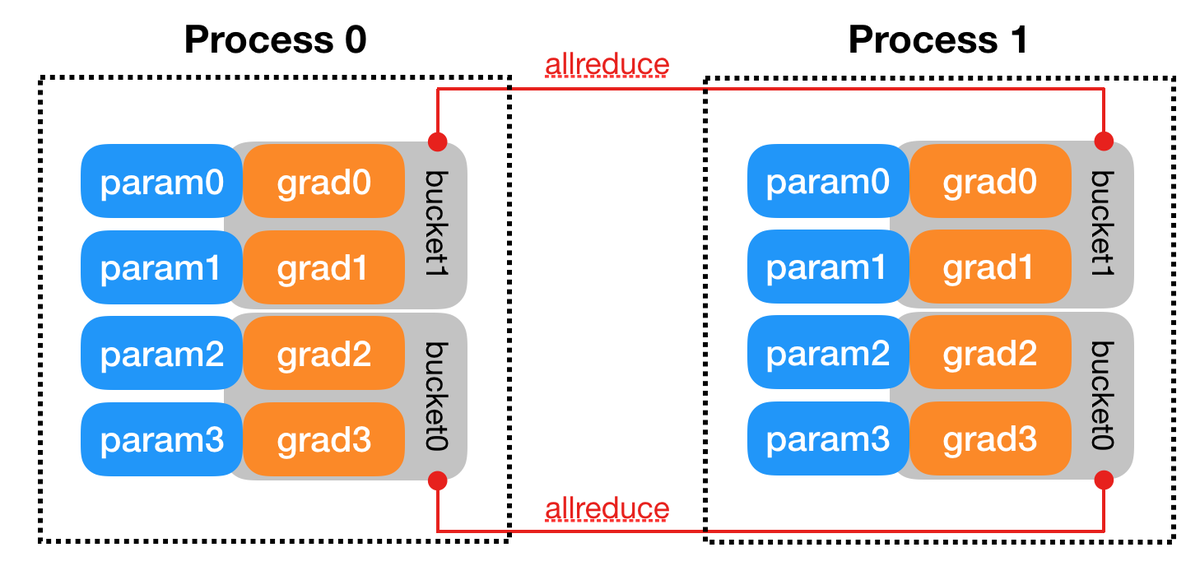
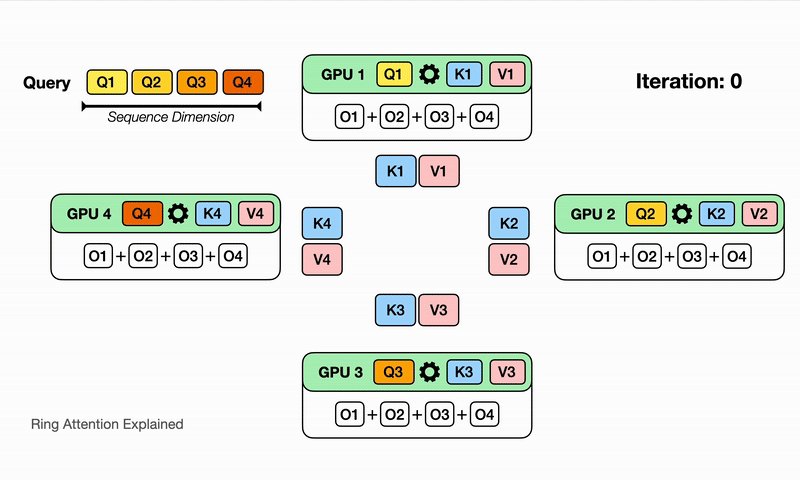
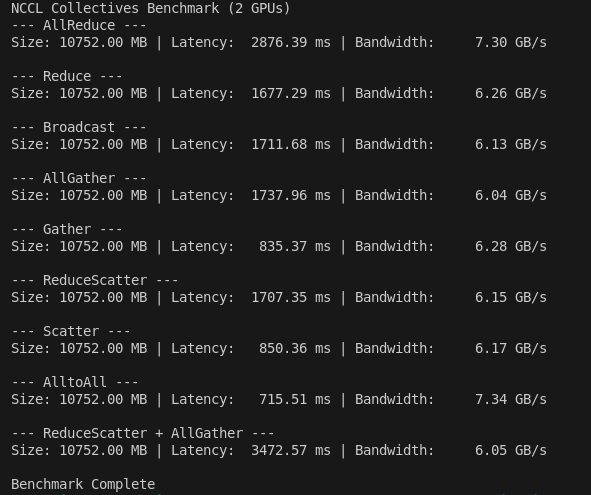
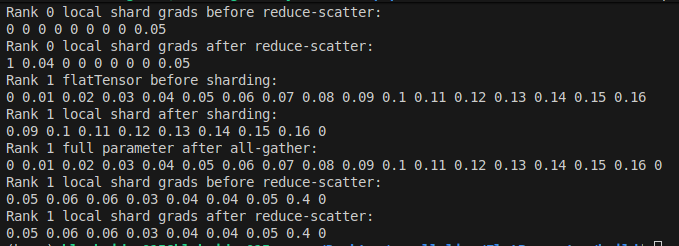
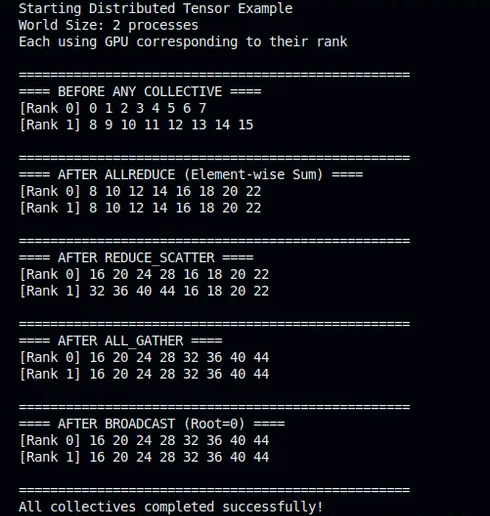
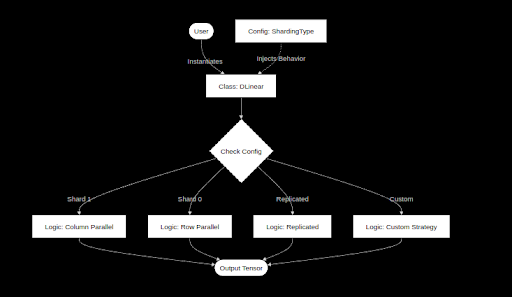
Why is distributed systems design always a trade-off?
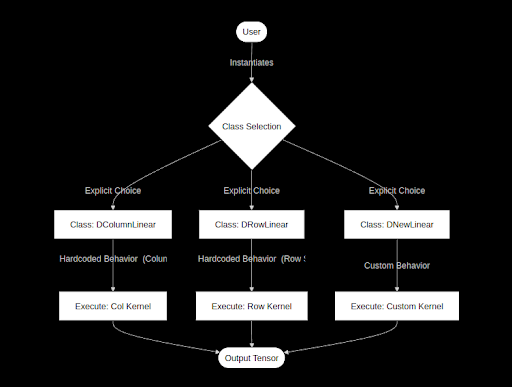
We compared two C tensor parallelism frameworks:
Config-driven CustomDNN vs explicit DistributedNN.
Usability scales faster.
Flexibility scales deeper.
Choosing between them shapes performance, and control (1/8)
1
2
6
154
The Verdict: What are you building?
Build the Engineer’s Choice (DistributedNN) if:
You’re building a training engine.
You want debuggable and explicit data flows.
When it crashes, the stack trace says:
DColumnLinear::forward–not DLinear::forward
Clarity beats cleverness. (7/8)
1
3
5
36
Summary
CustomDNN: flexibility > readability (the PyTorch way).
DistributedNN: explicitness > abstraction (the systems way).
When performance and sanity are on the line, I lean explicitly.
Implicit magic is great—until you’re debugging a race condition across 8 GPUs. (8/8)
3
5
33
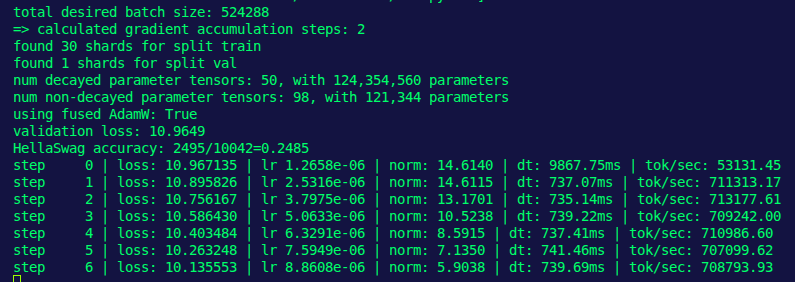
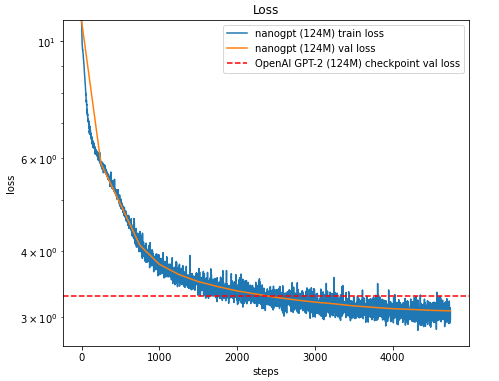
What happens when you train GPT-2 the right way?
We trained a GPT-2 124M model using @Data_team89 's SOTA training pipeline—and the results exceeded expectations.
It shows how data quality, scalable systems design, and efficient training still matter in modern LLMs. (1/4)
2
6
13
2,029
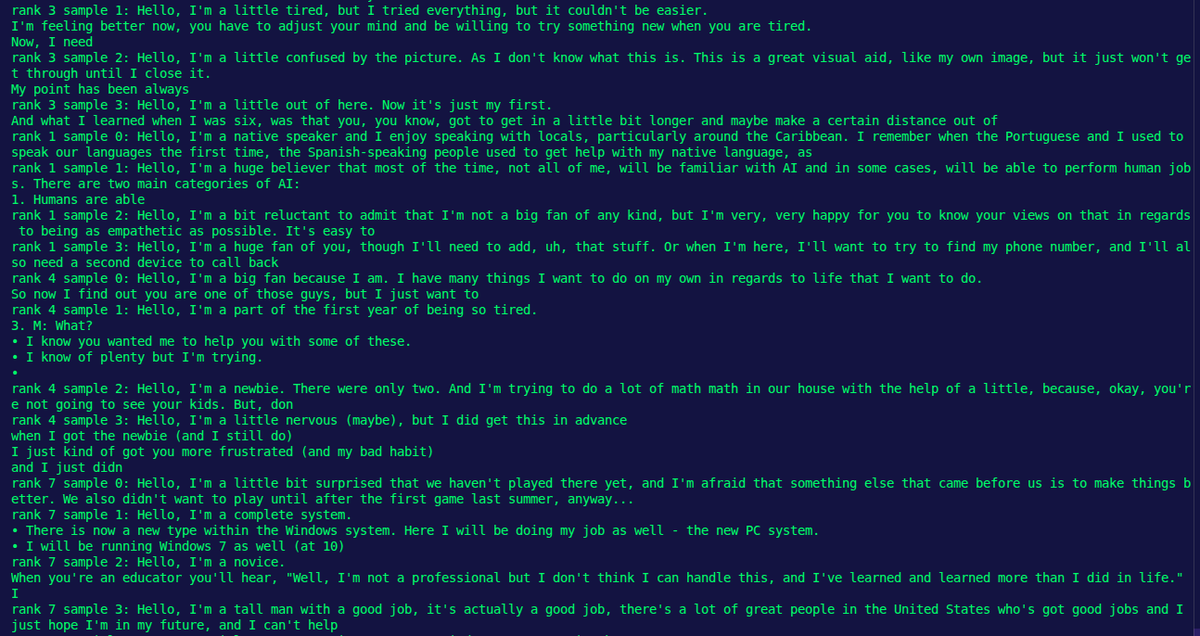
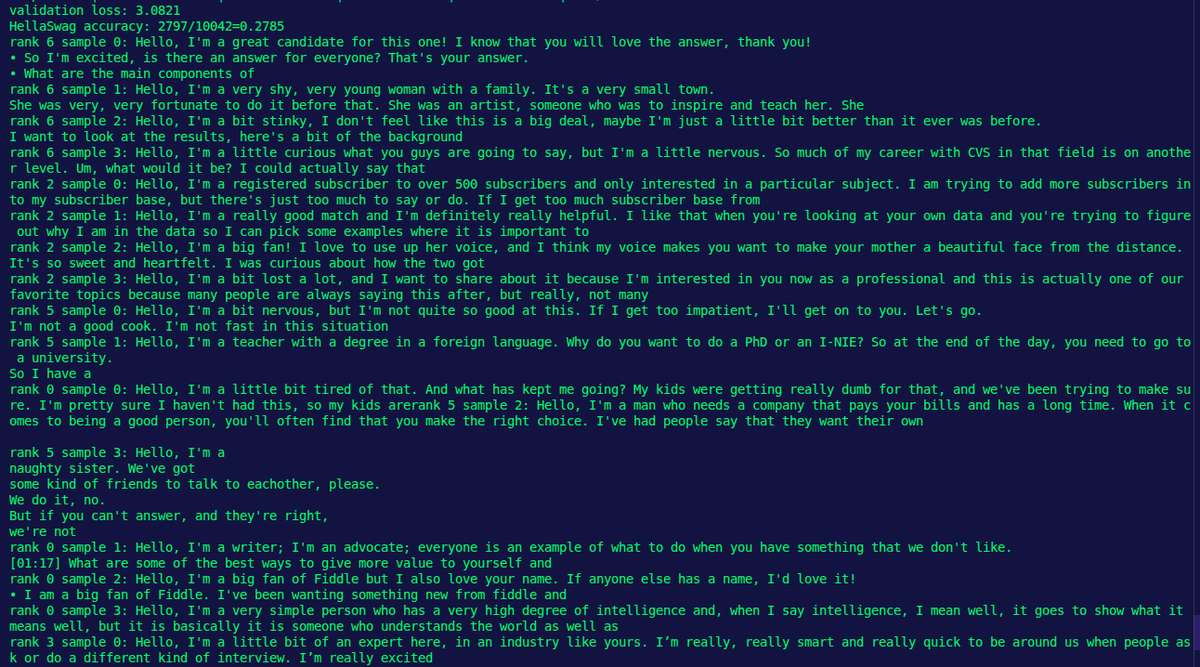
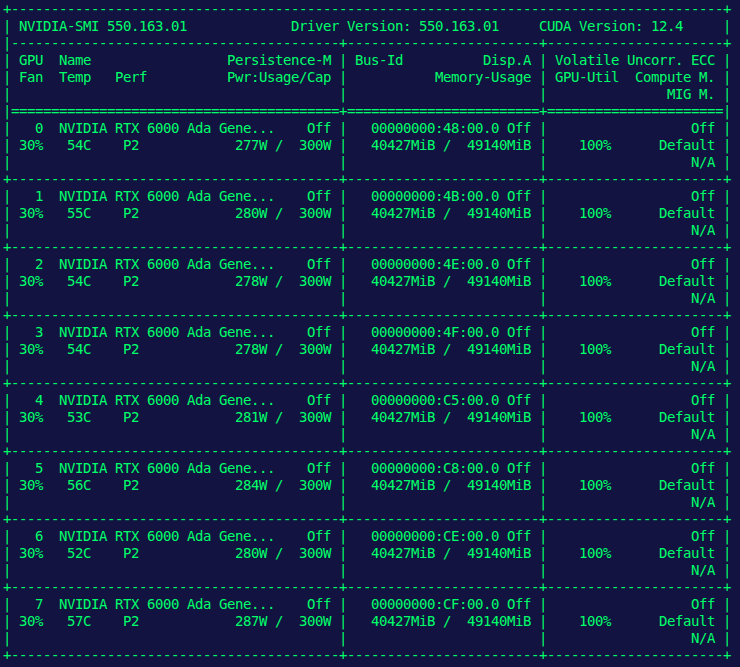
We applied Distributed Data Parallel (DDP) training across 8× NVIDIA A6000 GPUs to scale LLM training efficiently.
During evaluation, we used the prompt “Hello, I’m a”. The model produced a range of coherent, interesting completions. (3/4)
1
1
7
116
One response stood out from our GPT-2 124M model:
“Hello, I'm a little tired, but I tried everything, but it couldn't be easier.
I'm feeling better now.
You have to adjust your mind and be willing to try something new when you are tired.”
Which output do you like best? (4/4)
2
7
96