
6 Photos and videos

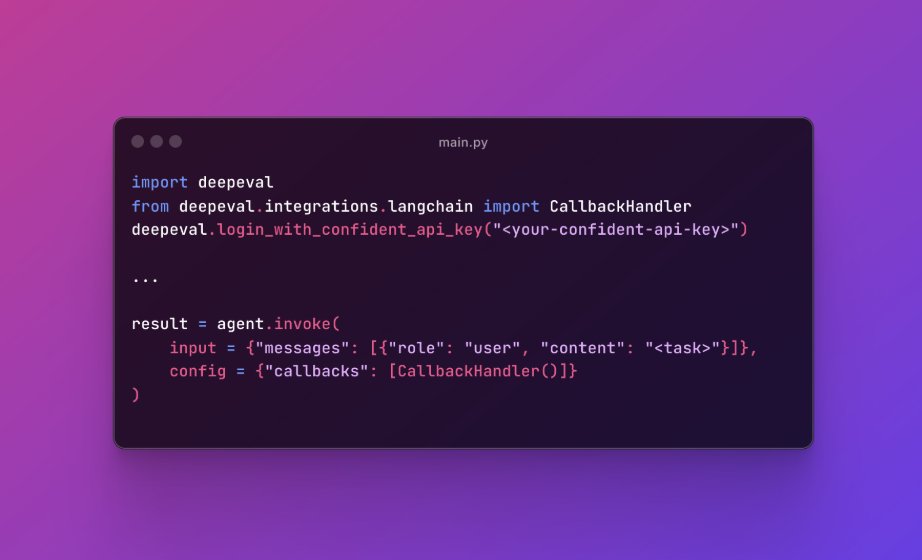


We keep hearing startups and SMBs ask for typescript and so now we're doing it: Typescript support for DeepEval: github.com/confident-ai/deep…
For python users: Don't worry, python is still the only first class citizen on DeepEval.
43
DeepEval retweeted

1
3
74


DeepEval retweeted
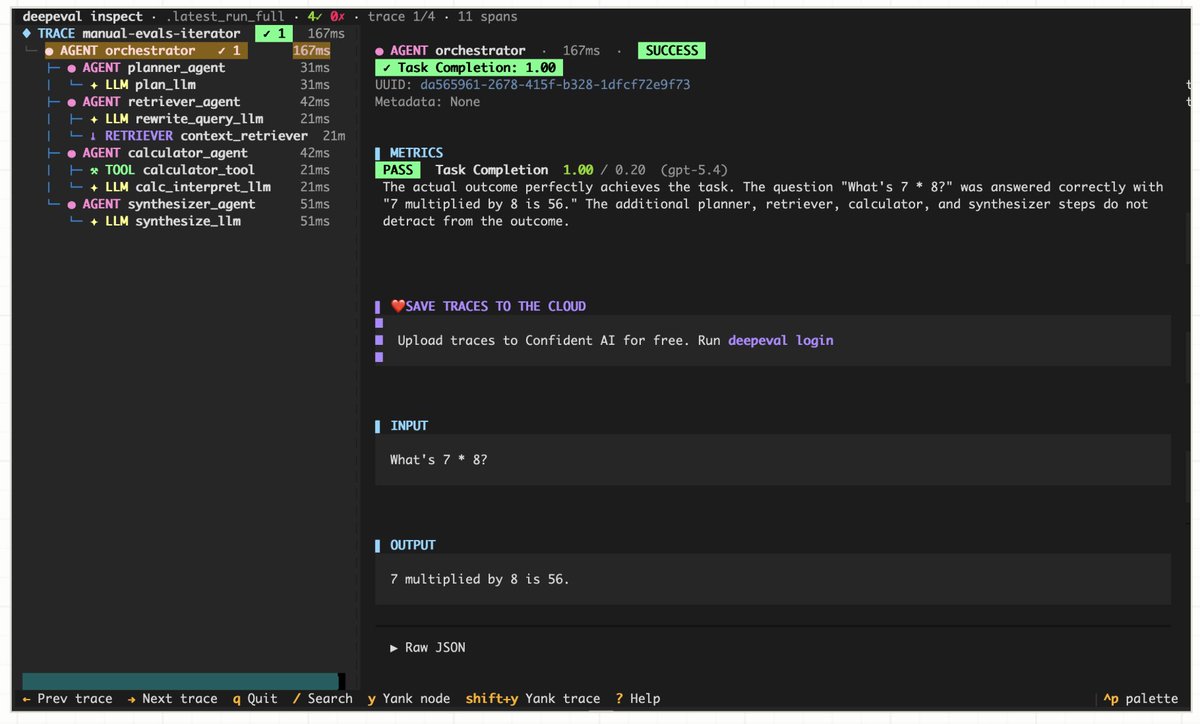
Today, we're proud to announce DeepEval 4.0 — the AI evaluation harness for vibe coding agents. Our biggest and boldest release yet.
A long thread 🧵 @deepeval :

2
3
13
520
DeepEval retweeted
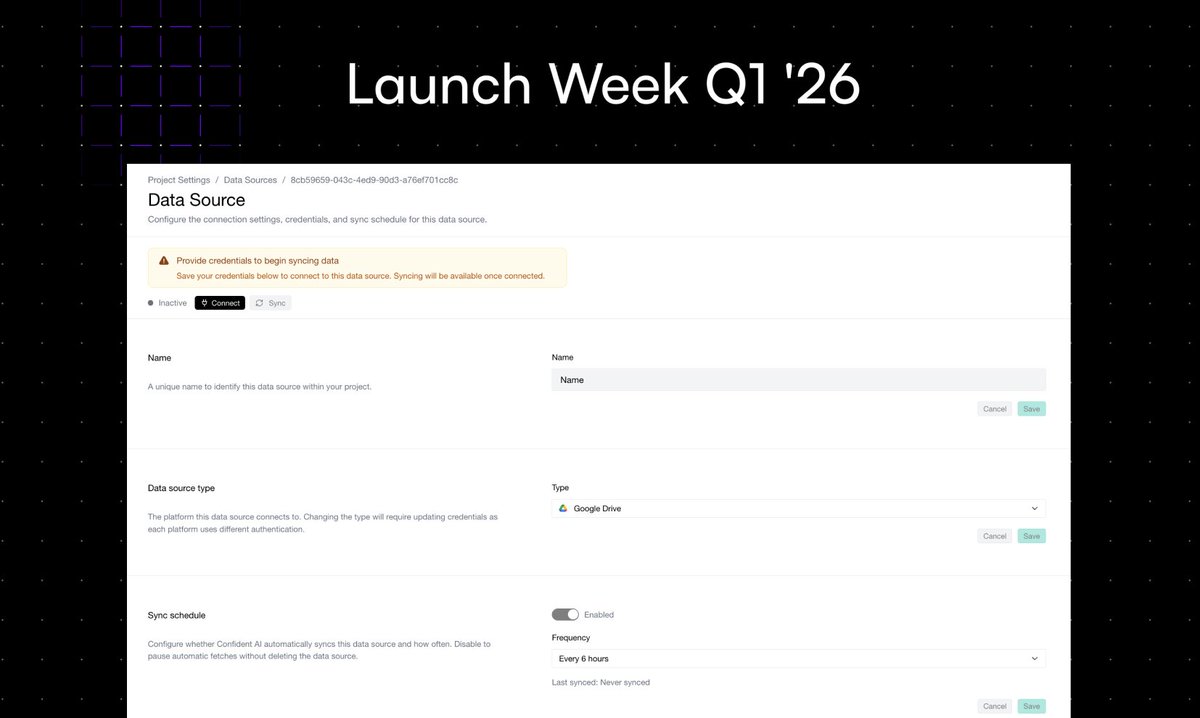
We just launched dataset generation on Confident AI — connect Google Drive, SharePoint, Notion, or S3 and generate eval datasets directly from your docs.
That's a wrap on Launch Week! 5 days, 5 launches.
1
2
3
315
DeepEval retweeted
We're launching Auto-Categorize Traces & Threads — Day 4 of our Launch Week!
Every production trace gets categorized automatically, so you can detect response drift and see exactly which areas your agent crushes and which ones need work.
Full post: confident-ai.com/blog/launch…
2
4
216
DeepEval retweeted
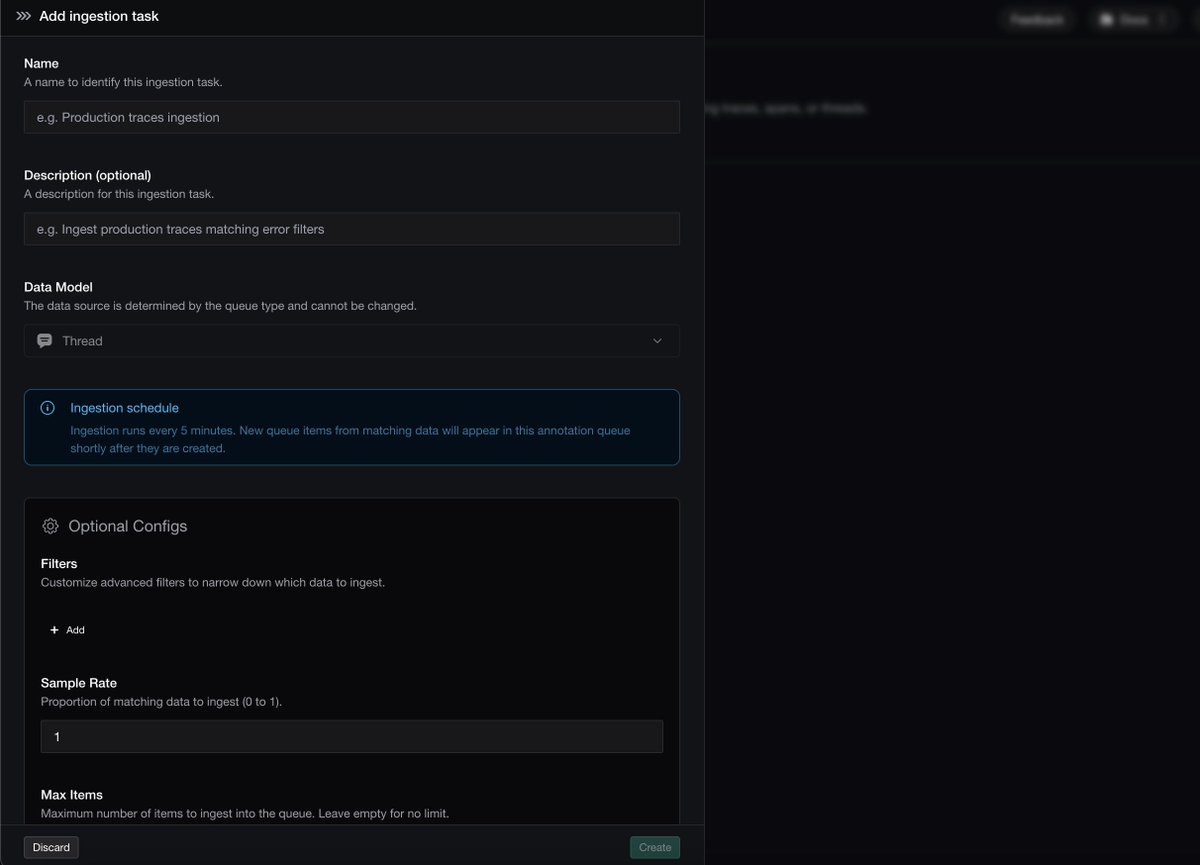
Day 3 of launch week: auto trace-to-dataset ingestion.
Set a rule once — production traces continuously flow into eval datasets and annotation queues. No scripts, no stale data.
Post: confident-ai.com/blog/launch…
2
4
229
DeepEval retweeted

Mar 31
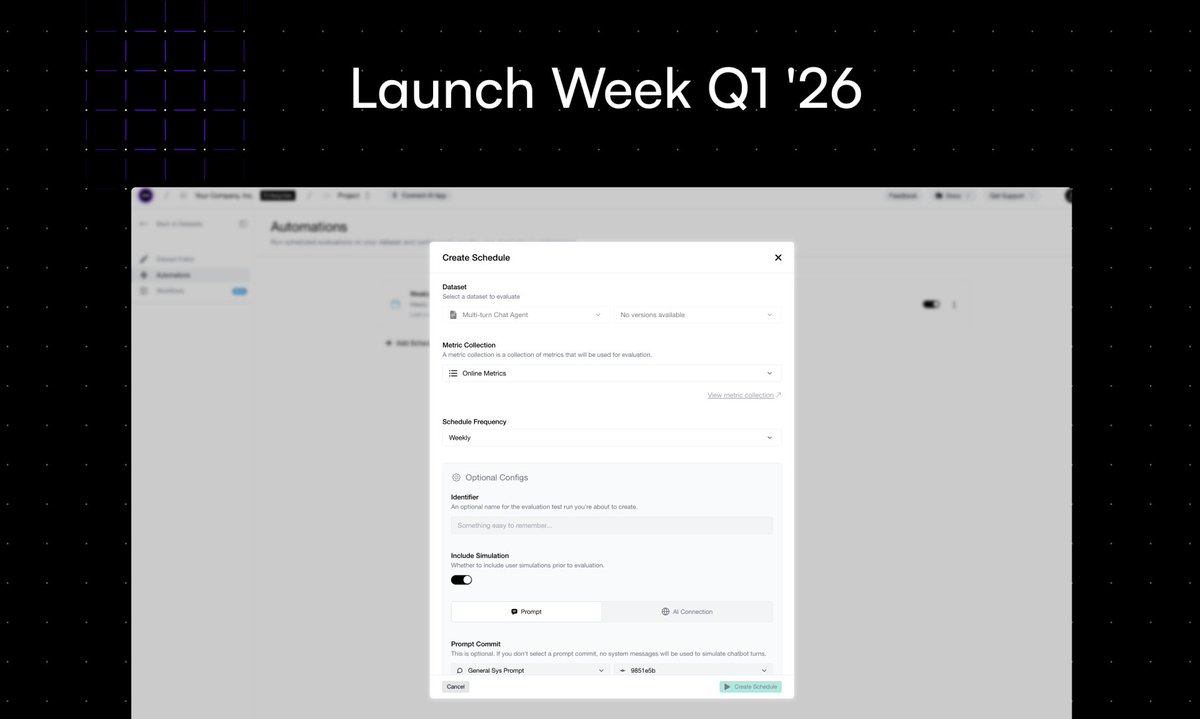
Confident AI Launch Week Day 2: Scheduled Evals ⏰
Everyone agrees to run evals every few days. Nobody actually does.
Now you set a frequency, configure your mappings, and evals run themselves.
Link here: confident-ai.com/blog/launch…
2
4
536
DeepEval retweeted
Mar 30
Announcing our Q1 Launch Week!
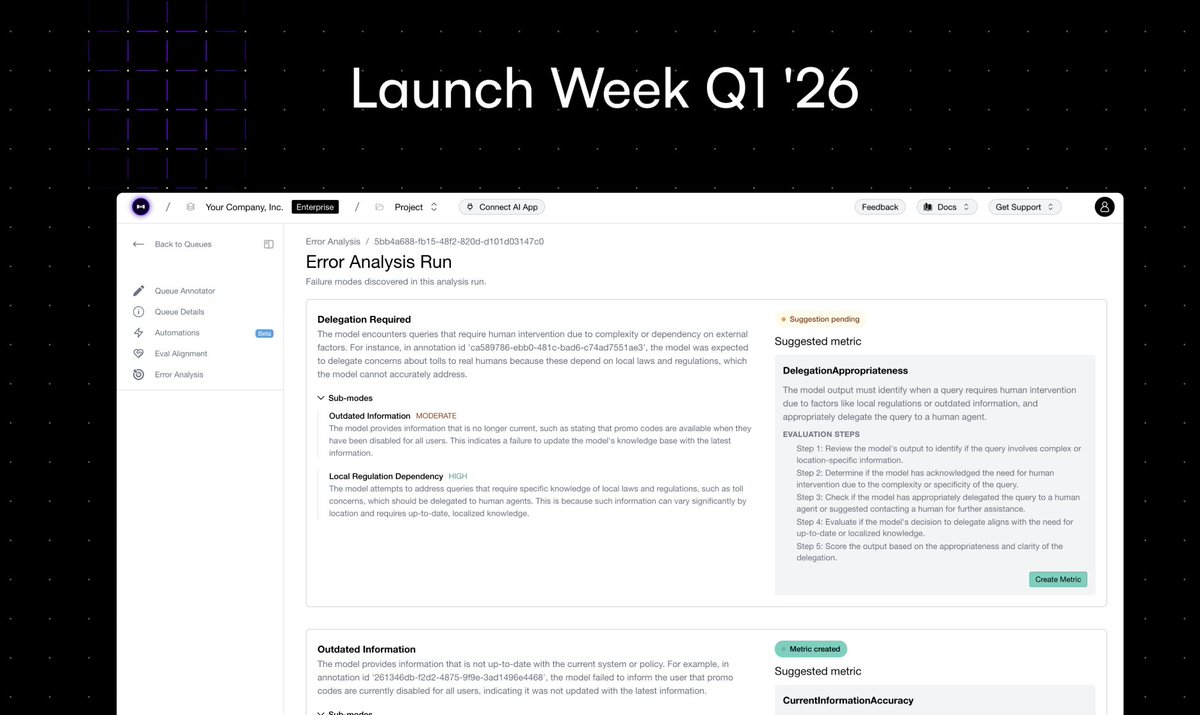
Day 1: Automated Error Analysis.
Link here: confident-ai.com/blog/launch…
2
5
496
DeepEval retweeted

Feb 3
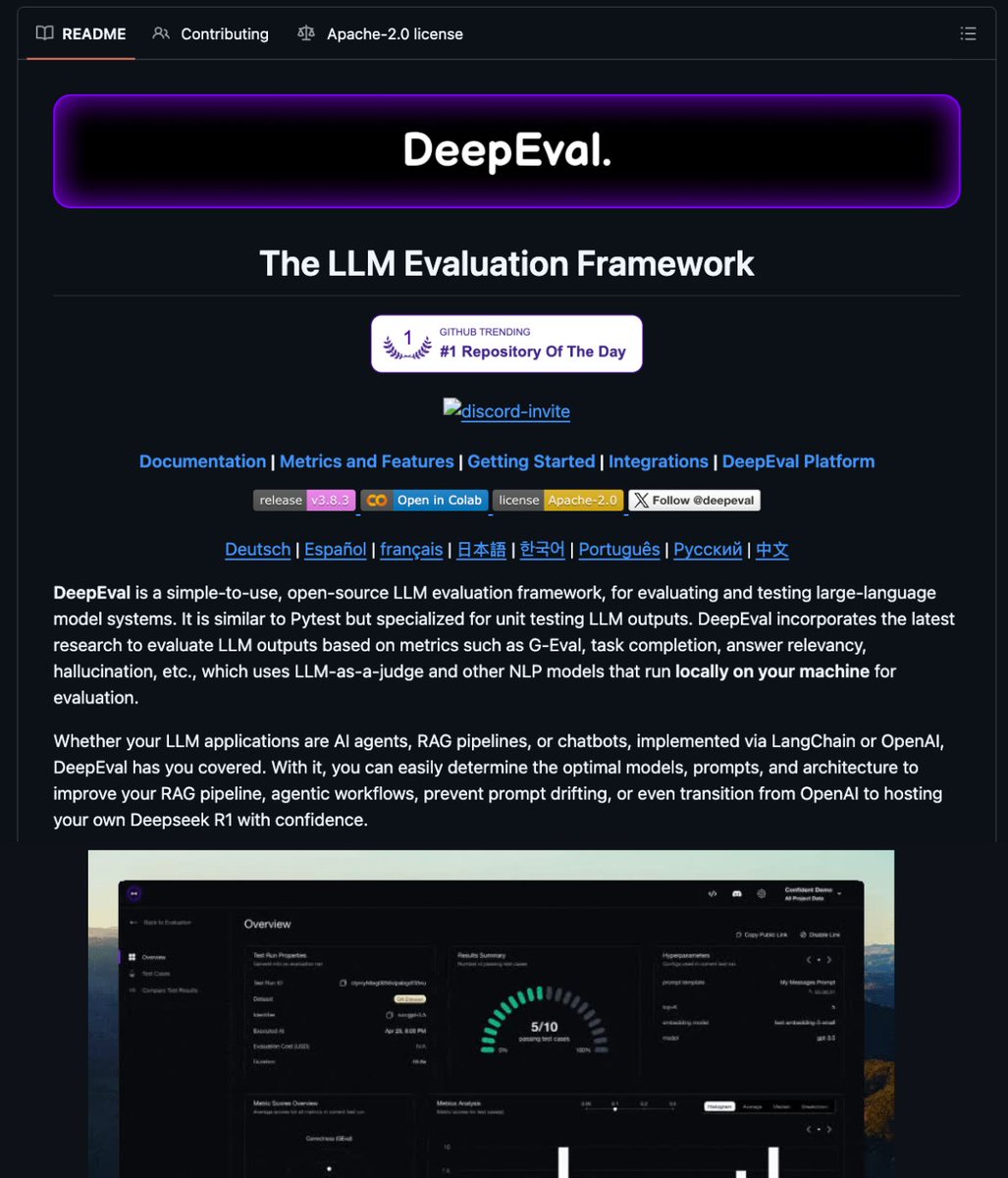
🚨BREAKING: Someone just solved LLM testing's biggest problem.
It's called DeepEval and it gives you answer relevancy, hallucination detection, and G-Eval metrics that actually work.
- Run evaluations 100% locally (no data leaves your machine).
- Test agents, RAG systems, and production responses with human-level accuracy.
100% Opensource.
33
124
780
50,112
My sister just got released, DeepTeam v1.0, 100% open-source, Apache 2.0 red teaming for LLMs.
⭐ Star on GitHub to stay on top of the latest developments in AI security and safety: github.com/confident-ai/deep…
1
5
11
960
DeepEval retweeted

22 Oct 2025
Author of @deepeval here, I'm glad you've found our approach of LLM-Arena-as-a-Judge useful :)
1
1
4
358
DeepEval retweeted

22 Oct 2025
Most LLM-powered evals are BROKEN!
These evals can easily mislead you to believe that one model is better than the other, primarily due to the way they are set up.
G-Eval is one popular example.
Here's the core problem with LLM eval techniques and a better alternative to them:
Typical evals like G-Eval assume you’re scoring one output at a time in isolation, without understanding the alternative.
So when prompt A scores 0.72 and prompt B scores 0.74, you still don’t know which one’s actually better.
This is unlike scoring, say, classical ML models, where metrics like accuracy, F1, or RMSE give a clear and objective measure of performance.
There’s no room for subjectivity, and the results are grounded in hard numbers, not opinions.
LLM Arena-as-a-Judge is a new technique that addresses this issue with LLM evals.
In a gist, instead of assigning scores, you just run A vs. B comparisons and pick the better output.
Just like G-Eeval, you can define what “better” means (e.g., more helpful, more concise, more polite), and use any LLM to act as the judge.
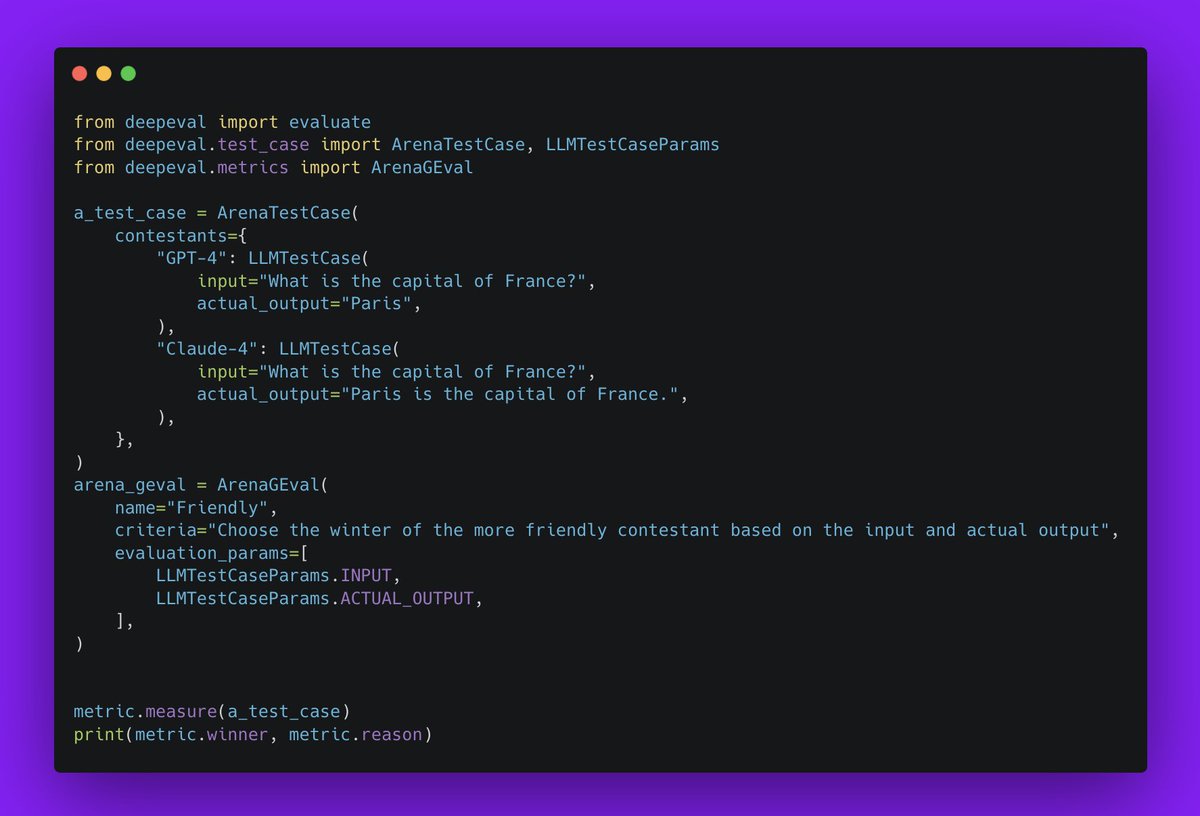
LLM Arena-as-a-Judge is actually implemented in @deepeval (open-source with 12k stars), and you can use it in just three steps:
- Create an ArenaTestCase, with a list of “contestants” and their respective LLM interactions.
- Next, define your criteria for comparison using the Arena G-Eval metric, which incorporates the G-Eval algorithm for a comparison use case.
- Finally, run the evaluation and print the scores.
This gives you an accurate head-to-head comparison.
Note that LLM Arena-as-a-Judge can either be referenceless (like shown in the snippet below) or reference-based. If needed, you can specify an expected output as well for the given input test case and specify that in the evaluation parameters.
Why DeepEval?
It's 100% open-source with 12k stars and implements everything you need to define metrics, create test cases, and run evals like:
- component-level evals
- multi-turn evals
- LLM Arena-as-a-judge, etc.
Moreover, tracing LLM apps is as simple as adding one Python decorator.
And you can run everything 100% locally.
I have shared the repo in the replies.

9
15
79
21,358
🙌 our favorite VC ❤️🔥
2 Oct 2025

The new Vermilion newsletter is out 🗞️
Inside:
💰 @514hq raises $17m to simplify AI-ready analytics
📈 @deepeval becomes the most adopted LLM eval framework globally
🤝 Google’s Agent Development Kit ships a @CopilotKit integration
👀 Who’s hiring? Check out the new Vermilion Careers page
Plus: @ashl3ysm1th's take on startup KPIs, revenge of the acronyms, and more founder lessons from the trail.

1
241
DeepEval retweeted

2 Oct 2025
The new Vermilion newsletter is out 🗞️
Inside:
💰 @514hq raises $17m to simplify AI-ready analytics
📈 @deepeval becomes the most adopted LLM eval framework globally
🤝 Google’s Agent Development Kit ships a @CopilotKit integration
👀 Who’s hiring? Check out the new Vermilion Careers page
Plus: @ashl3ysm1th's take on startup KPIs, revenge of the acronyms, and more founder lessons from the trail.
1
1
2
446
DeepEval retweeted
24 Sep 2025
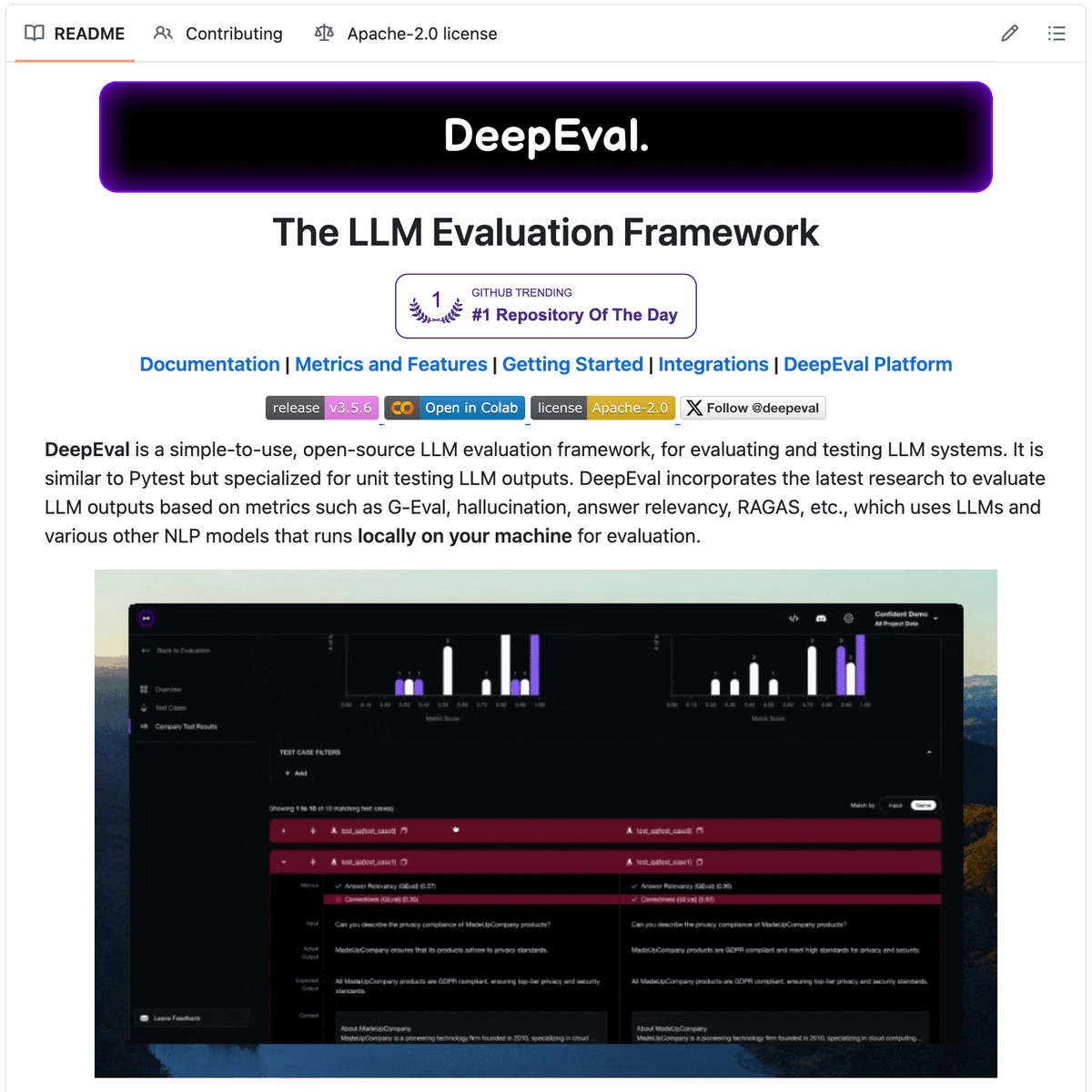
Pytest for LLM Apps is finally here!
DeepEval turns LLM evals into a two-line test suite to help you identify the best models, prompts, and architecture for AI workflows (including MCPs).
Works with all frameworks like LlamaIndex, CrewAI, etc.
100% open-source with 11k stars!
8
45
278
20,362
DeepEval retweeted

12 Sep 2025
1
1
205
DeepEval retweeted

20 Sep 2025
Companies like @OpenAI, @perplexity_ai and @AnthropicAI already use LLM judges for production evaluation at massive scale.
@ragas_io and @deepeval are two evaluation frameworks that I personally find intuitive.
[NOT AN AD]
1
1
18
3,097
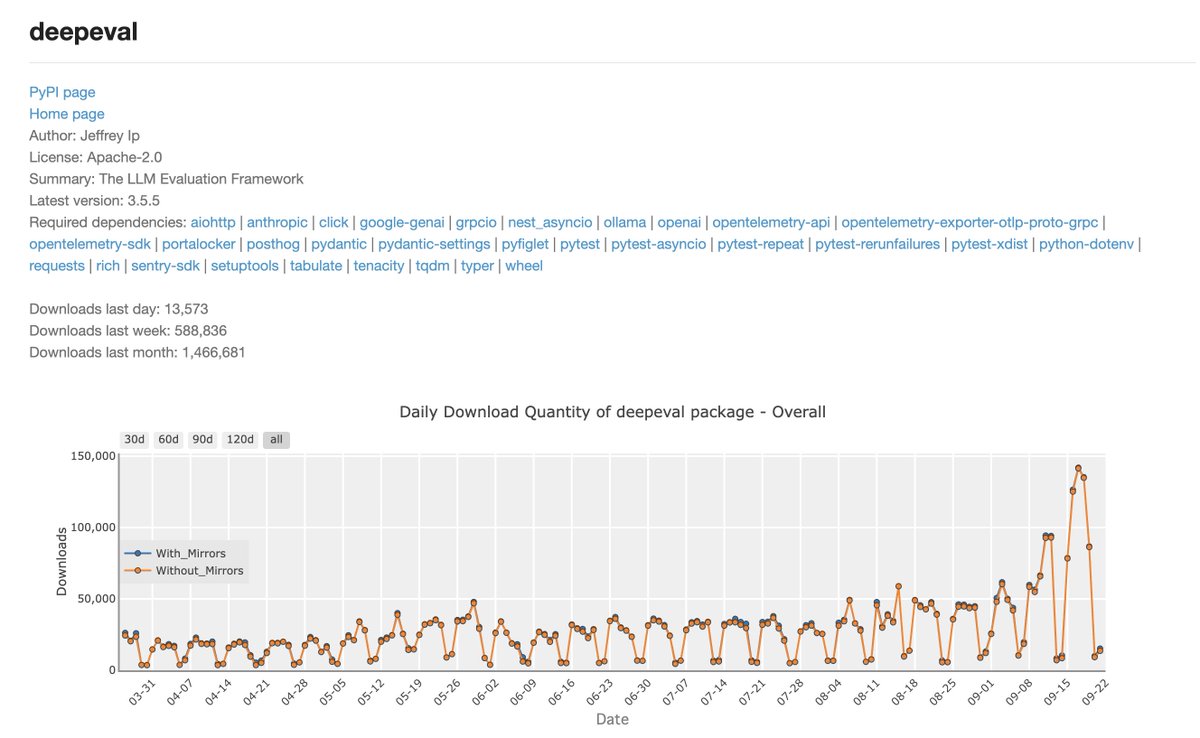

Real-world AI memory evaluation needs more than HotPotQA, EM or F1.
Our new open dataset with @deepeval will measure cross-context, long-term reasoning. Stay tuned.
For the full results & current methodology:
cognee.ai/blog/deep-dives/ai…
2
2
6
396