
maximizing shareholder value; mostly ml here;
Joined February 2020
- Tweets 10,314
- Following 981
- Followers 20,414
- Likes 9,052
1,159 Photos and videos









Jun 12
onwards and upwards🚀

> wrote this blog last year, in fact i did not share this in my network at all.
> today i noticed it has 22k views, quite happy tbh.

1
789
Jun 10
pretty much what MLA does. but that's an architectural choice to be taken before pre-training.
borrowed from MLA, but applied to any model out there to compress the effective KV Cache. I wonder if there is an open recipe about it.
and vLLM should figure out a way to support it. (in my knowledge it doesn't, yet)
Jun 10

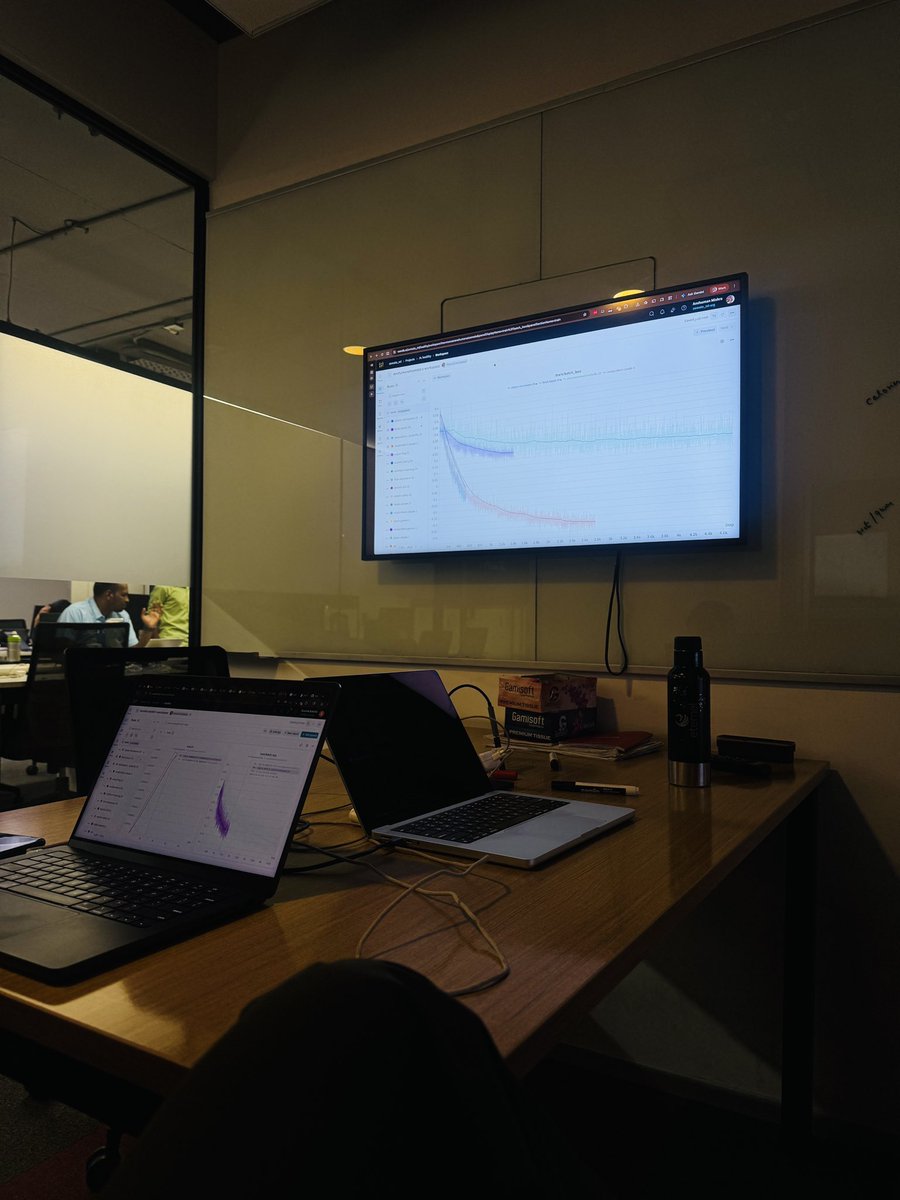
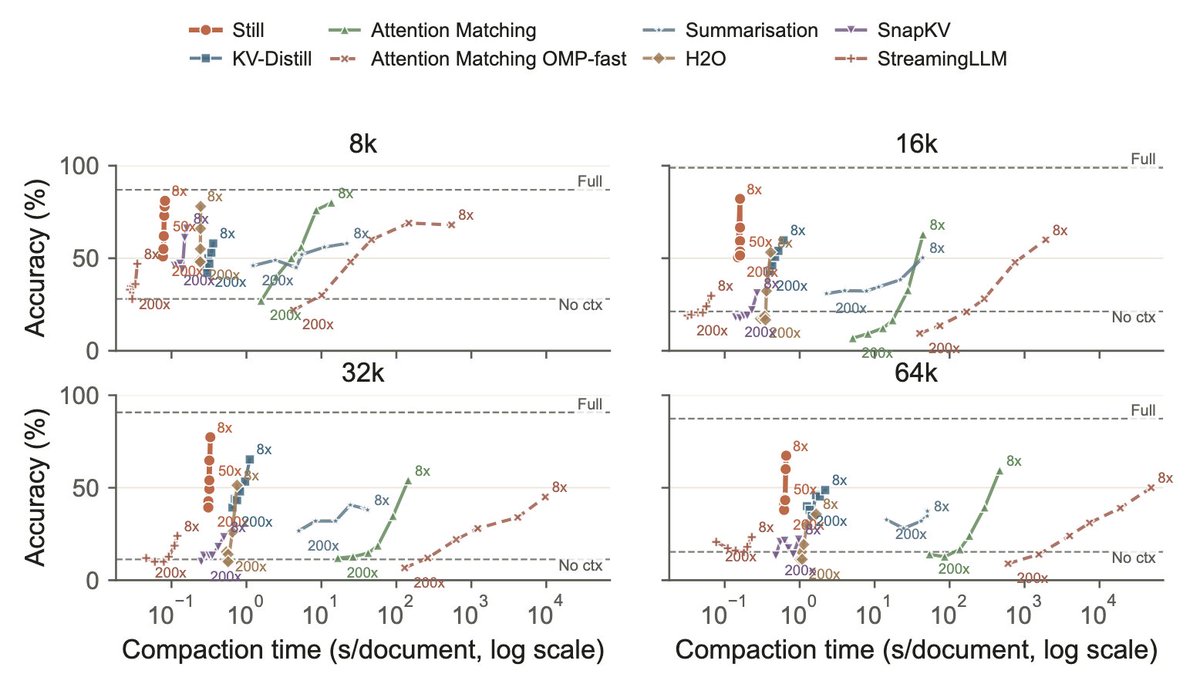
1/ You can shrink a language model's KV cache by 200×, in a single forward pass, and it still answers correctly.
At 256k context that's 36 GiB of cache down to ~360 MiB, with no change to the base model.
Here's how we did it 👇
1
1
7
3,376
anshuman retweeted

May 27
We have released the biggest protein data collection on Hugging Face, guys!
We have been working on this for more than 3 weeks now, starting from curating the raw data, doing a lot of filtering, splitting the datasets, sharding them, and doing a lot of analysis. Everything is summarized in our recent blog post.
May 27

LLMs got FineWeb, The Pile, RedPajama, Dolma. Protein ML got per-paper supplementary tables and FTP mirrors scattered across a dozen institutions.
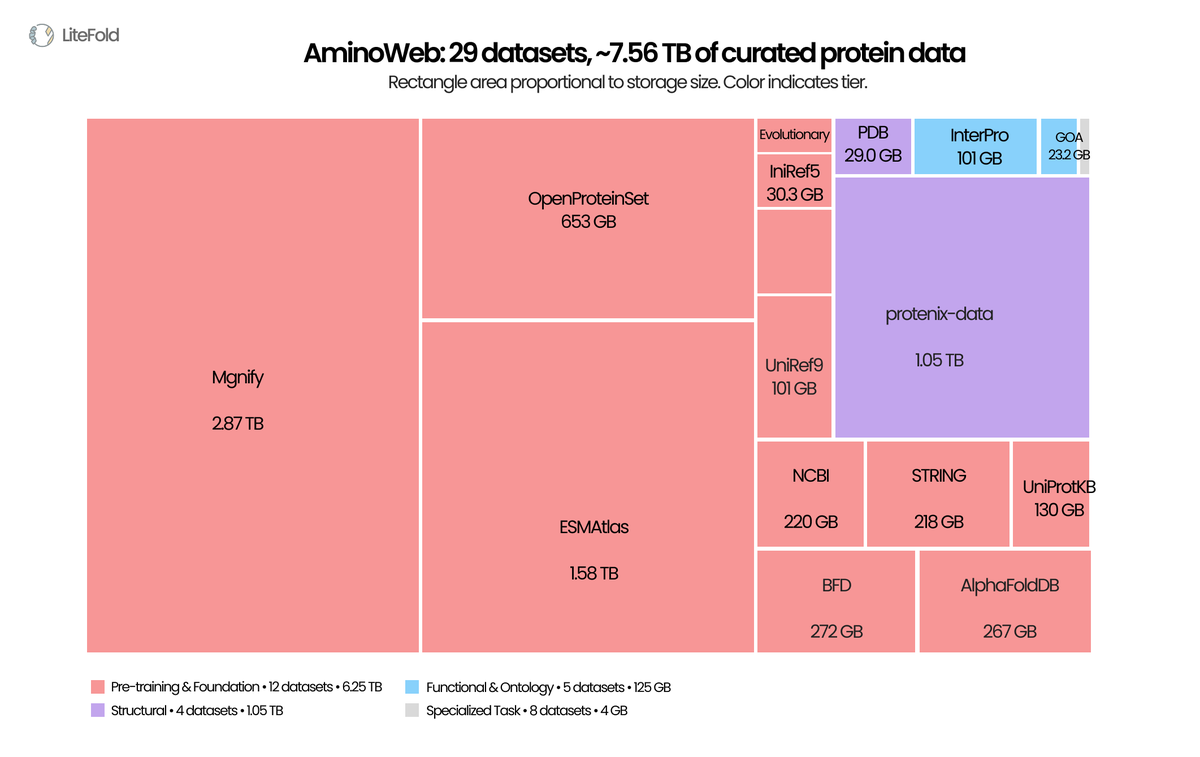
Today we're releasing AminoWeb on @huggingface : 29 cleaned, ML-ready protein datasets, ~7.5 TB total. Sequence, structure, function, MSA, variant-effect, stability, binding. UniProt, PDB, AlphaFoldDB, ESMAtlas, ProteinGym, MegaScale, Protenix, and more.
Typed Parquet. Homology-aware splits. Preserved score conventions. Full provenance per record.
Protein ML scaled architectures for years while the data layer stayed fragmented. We've also shared the full curation pipeline, case studies, and observations in the companion blog post.
Access the data: huggingface.co/LiteFold
Read the release blogpost: litefold.ai/blog/aminoweb
38
71
360
87,739
anshuman retweeted

May 13
Today we release Token Superposition Training (TST), a modification to the standard LLM pretraining loop that produces a 2-3× wall-clock speedup at matched FLOPs without changing the model architecture, optimizer, tokenizer, or training data.
During the first third of training, the model reads and predicts contiguous bags of tokens, averaging their embeddings on the input side and predicting the next bag with a modified cross-entropy on the output side. For the remainder of the run, it trains normally on next-token prediction. The inference-time model is identical to one produced by conventional pretraining.
Validated at 270M, 600M, and 3B dense scales, and at 10B-A1B MoE.
The work on TST was led by @bloc97_, @gigant_theo, and @theemozilla.

150
415
3,695
448,210
May 12
go read it folks.
ps: leetgpu reminds me of codeforces era

1
5
1,281
anshuman retweeted

May 5
Excited to release the Ultimate guide to RL environments!
Definitions of RL environments differ wildly in the LLM era, so we spent the last month building several RL environments across 6 different frameworks, domains and complexities to map out which are easiest to build with and which can be scaled to 1000s.
50
165
1,295
243,995
anshuman retweeted

Apr 29
🚀 Introducing FlashQLA: high-performance linear attention kernels built on TileLang.
⚡ 2–3× forward speedup. 2× backward speedup.
💻 Purpose-built for agentic AI on your personal devices.
💡Key insights:
1. Gate-driven automatic intra-card CP.
2. Hardware-friendly algebraic reformulation.
3. TileLang fused warp-specialized kernels.
FlashQLA boosts SM utilization via automatic intra-device CP. The gains are especially pronounced for TP setups, small models, and long-context workloads.
Instead of fusing the entire GDN flow into a single kernel, we split it into two kernels optimized for CP and backward efficiency. At large batch sizes this incurs extra memory I/O overhead vs. a fully fused approach, but it delivers better real-world performance on edge devices and long-context workloads.
The backward pass was the hardest part: we built a 16-stage warp-specialized pipeline under extremely tight on-chip memory constraints, ultimately achieving 2× kernel-level speedups.
We hope this is useful to the community!🫶🫶
Learn more:
📖 Blog: qwen.ai/blog?id=flashqla
💻 Code: github.com/QwenLM/FlashQLA

38
107
941
74,426

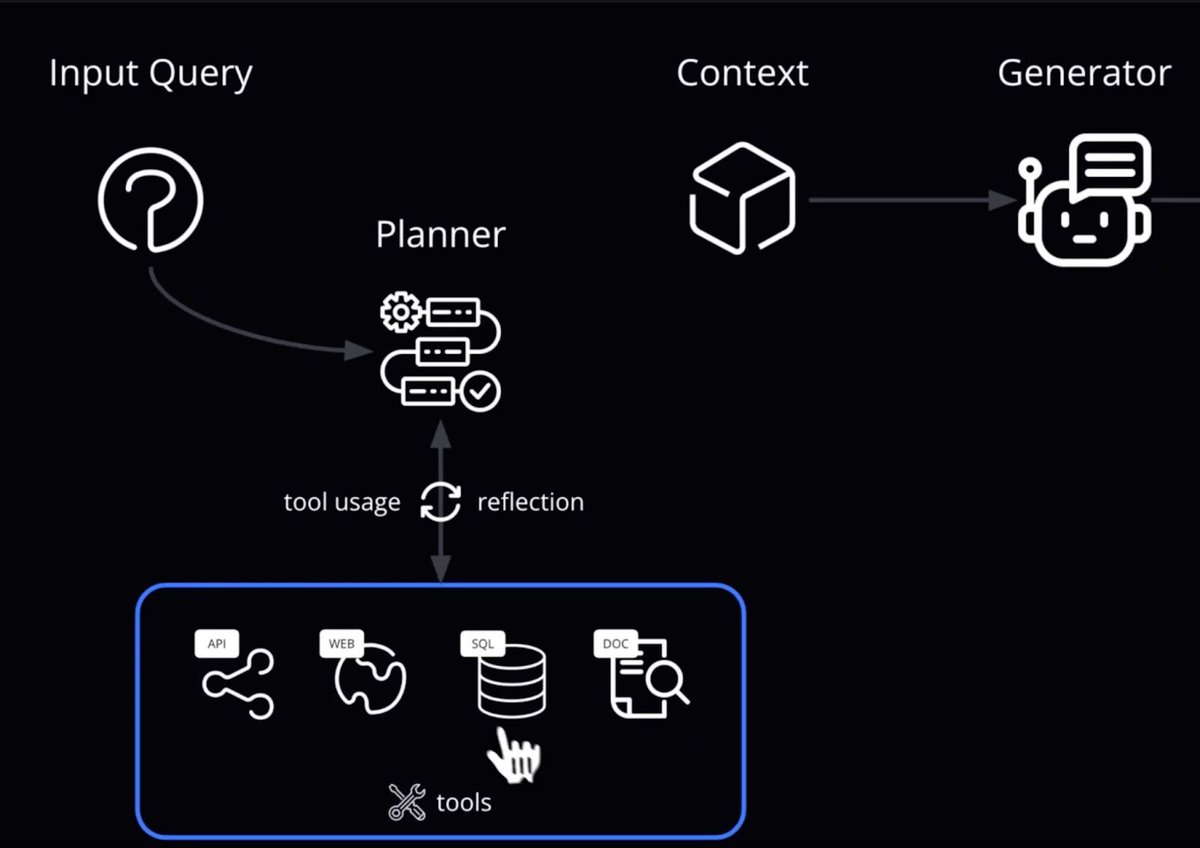
Introducing Latent Briefing, a way for agents to quickly share their relevant memory directly. Result: 31% fewer tokens used, same accuracy.
Multi-agent systems are powerful, but can be wildly inefficient. They pass context as tokens, so costs explode and signal gets lost. We built an algorithm that allows agents to communicate KV cache to KV cache.
37
92
1,770
669,766
Mar 29
btw this never happened.

we are so excited to partner with Disney on sora and ai generated content!
they will also be investing $1B

8
1,640
Mar 26
not building it with codex then.
claude code it is.
Mar 25

hey @gdb , does openai accept oss contributions from outsiders?
talking about github.com/openai/codex here.
building little something that solves a lot of my problems.
it's sort of working well with claude code but codex is something i want to integrate as well.
need hooks support in codex. happy to contribute!
thanks.
1
1
1,157
Mar 25
hey @gdb , does openai accept oss contributions from outsiders?
talking about github.com/openai/codex here.
building little something that solves a lot of my problems.
it's sort of working well with claude code but codex is something i want to integrate as well.
need hooks support in codex. happy to contribute!
thanks.
1
5
2,164
Feb 24
Workers/Serverless Functions are THE infra for Agents.
At this point @modal and @Cloudflare are best positioned for this.
18
1,711
Feb 20
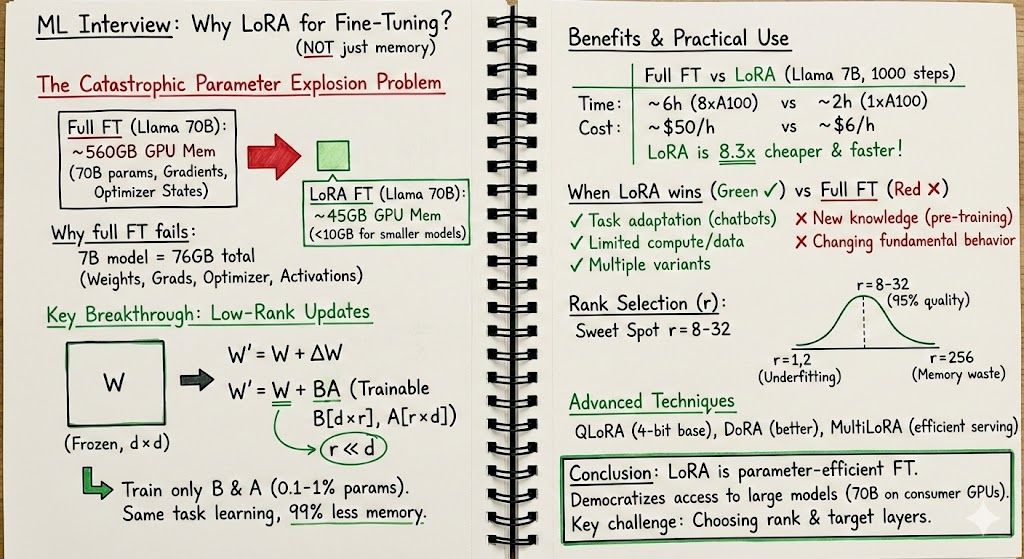
You're in a ML Engineering Interview at Meta, and the interviewer asks:
"Why use LoRA for fine-tuning? Can't we just update all the weights?"
Here's how you answer:
7
16
239
13,194
Feb 20
Selecting Rank is the key challenge in LoRA -
> Rank too low (r=1, 2): Underfitting, can't capture task complexity
> Rank too high (r=256): Memory waste, approaching full fine-tuning cost
> Sweet spot (r=8-32): 95% of full fine-tuning quality
1
1
676
Feb 20
Rule of thumb:
- Simple tasks (sentiment): r=4-8
- Complex tasks (instruction following): r=16-64
- Very complex tasks: r=64-128 or consider QLoRA
Test multiple ranks. Sometimes r=8 matches r=64 performance.
1
614