
Live free and travel the world... NFA
Joined March 2024
- Tweets 1,757
- Following 1,463
- Followers 296
- Likes 5,296
Photos and videos

Jun 15
Yes and how can you efficiently move trillions in value with low prices vs. higher prices?
Jun 14

Did you catch the part where Brad said "the creators of XRP created 100 billion so it wouldn't reach a high price"?
1
3
Allan A retweeted

Jun 14
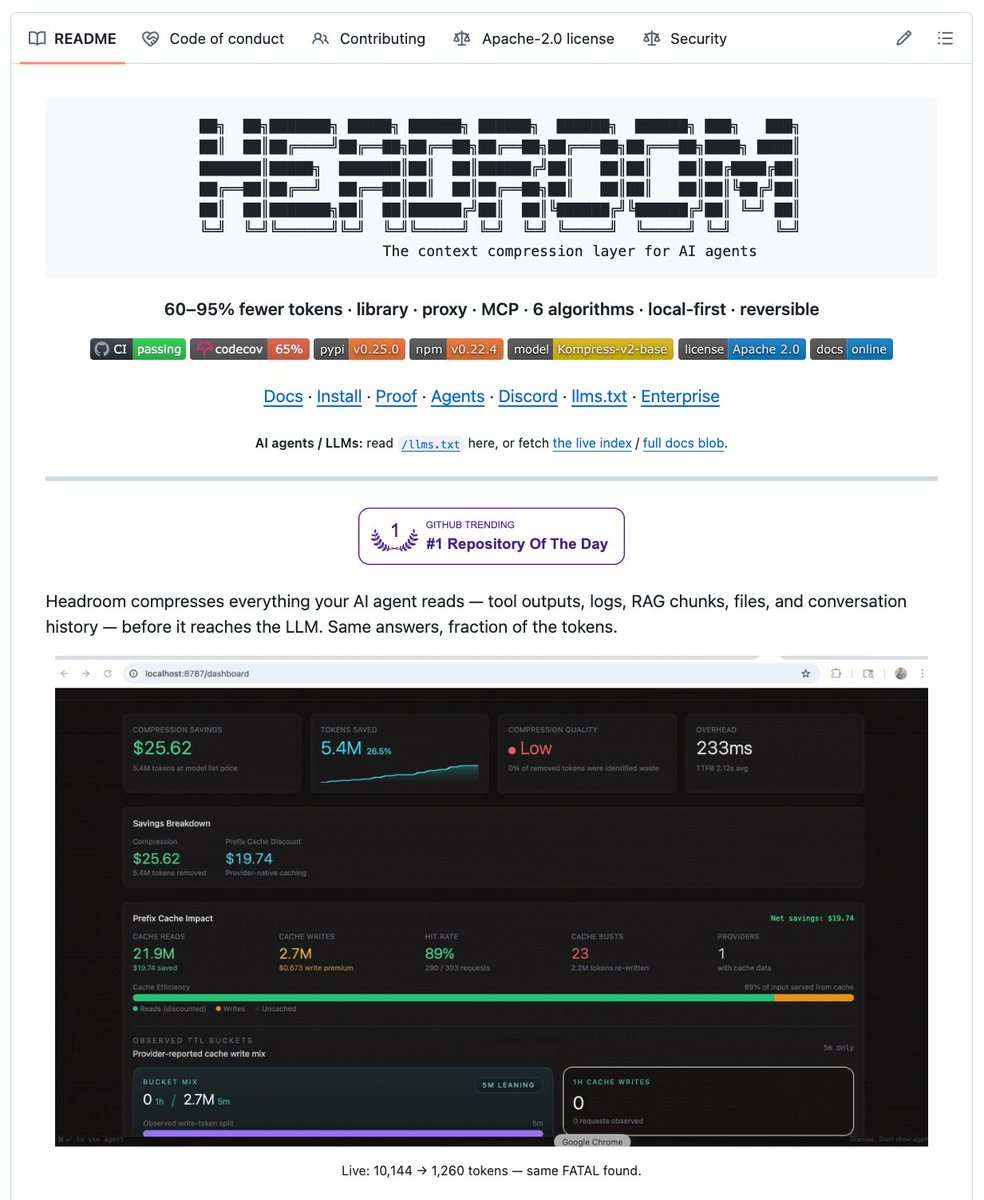
So I found a github repo that stops AI agents from burning tokens for no reason.
It’s called Headroom.
It's built by a guy name Tejas Chopra who works at Netflix.
Basically, it compresses all the things your AI agent reads before it reaches the LLM.
For example:
- Tool outputs
- Logs
- Files
- RAG chunks
- Code search results
- Conversation history
Developer claims 60–95% fewer tokens with the same answers.
Right now you can use it with:
- Python/TypeScript library
- Local proxy
- MCP server
- Wrapper for Claude Code, Codex, Cursor, Aider, and Copilot
If your coding agent is getting expensive, slow, or lost in giant logs, this repo is worth checking out.
Thanks for reading.
35
42
397
25,295


Old Song from Scammers 😂👀👇
x.com/i/status/2047604997601…
a retarded scammer @bgarlinghouse
🗣️Brad : one day XRP will power the world
🗣️Retails : then why wont @Ripple buyback and hold XRP
🗣️Brad : ........ (we got ton of free XRP already, we need $$$)
🗣️Retails : really brad, $1.3 cent will power the world?
🗣️Brad : yes XRP will be the center of it
🗣️Retails : ........

1
287
Jun 11
Part true and retailers/ consumes will benefit from cheaper and faster Settlements. Liquidity for for Settlements. Participating in earning higher yield using defi as compared to banks lousy and low interest
Jun 11

Soo he just admitted Ripple is not focused on consumers... Just banks and institutions... GOT IT.....
1
Jun 11
Both will be used.
They have completely different use cases. Both will do well
Jun 11
Canton will be $1-5 in the near future it's everything XRP wishes it was, banks are actually building on the Canton ecosystem and not XRP this is not shilling it's the truth
1
Jun 11
Glad to see you're moving along to other cryptos
Jun 11

stablecoins yes not xrp, no institution is bridging shiet witb a volatile piece of shiet of coin that ripple dumps anytime they want to or sell, thats why the narrative switch from xrp to Rlusd lol, 9 years and $1.11 is all you got
2
Jun 11
Wait until after Clarity Act passes
Jun 11

@bgarlinghouse clearly doesn't want to talk about $XRP especifically... Always about stablecoins!
28
Jun 11
Good point and if XRP is not needed then get rid of it. However it must be needed because it serve as Real Time global instant Settlements RTGS as well as liquidity that's why the value of XRP must be higher to move many trillions in the future.
Jun 11

Ripple bought GTreasury and named it Ripple Treasury.
Growing Ripple through acquisition is an excellent use of the proceeds from the sale of XRP from escrow.
Ripple shareholders should be very happy.
RLUSD should also make Ripple some money.
Where is $XRP in all of this? It's not. Could be involved, but doesn't have to be.
PLAN:
Step 1: Ripple sells $XRP each month from escrow
Step 2: Ripple uses proceeds to acquire companies
Step 3: Ripple increases shareholder value
Well done.
24
Jun 11
And nobody's going to use RLUSD 😆?
Jun 11

LOL Jamie Dimon’s been called out again… Brad just threw the $13 trillion in traditional payment volume right in his face! You have to admit, that was a powerful counterattack😄
1
1
29
Allan A retweeted

Jun 11
LOL Jamie Dimon’s been called out again… Brad just threw the $13 trillion in traditional payment volume right in his face! You have to admit, that was a powerful counterattack😄
2
33
2,820
Jun 11
Exactly and that's why they'll want to block the Clarity Act etc so they can continue their acts

WTF cares what that snake Jamie Dimon has to say?!! He is part of the banking cartel. Chase alone has been fined billions upon billions of dollars for fraud and corruption. Go see for yourself at violationtracker.goodjobsfir… and then ask yourself, why would you trust a bank who has been ripping you off with a smile??
2
39
Jun 11
You're right there's no guarantee but what digital assets have been in top 10 in market cap for past 10 years? The short answer, only 3 BTC, ETH and XRP and why is that?
Jun 11

Even with Garlinghouse saying all this, there is still no guarantee that XRP token will be used for these purposes, and no guarantee the price will ever substantially go up.
1
20
Jun 11
And that's only the beginning, can you say quad-trillions $, and this is the Flip The Switch moment.....

Brad Garlinghouse isn't holding back. 🚨 The Ripple CEO just went on Fox Business to call out Jamie Dimon’s pushback on crypto regulation as an "intentional misrepresentation."
“$13 TRILLION in legacy volume, 0% on-chain... yet. 👀”
"Stablecoins are the ChatGPT moment of finance." 💥
He revealed Ripple Treasury handled a massive $13 TRILLION in legacy payments last year and explained why that multi-trillion dollar gap is the ultimate crypto opportunity.
The tides have officially changed. 👇
8

Brad Garlinghouse isn't holding back. 🚨 The Ripple CEO just went on Fox Business to call out Jamie Dimon’s pushback on crypto regulation as an "intentional misrepresentation."
“$13 TRILLION in legacy volume, 0% on-chain... yet. 👀”
"Stablecoins are the ChatGPT moment of finance." 💥
He revealed Ripple Treasury handled a massive $13 TRILLION in legacy payments last year and explained why that multi-trillion dollar gap is the ultimate crypto opportunity.
The tides have officially changed. 👇
129
1,200
5,678
319,439





Allan A retweeted

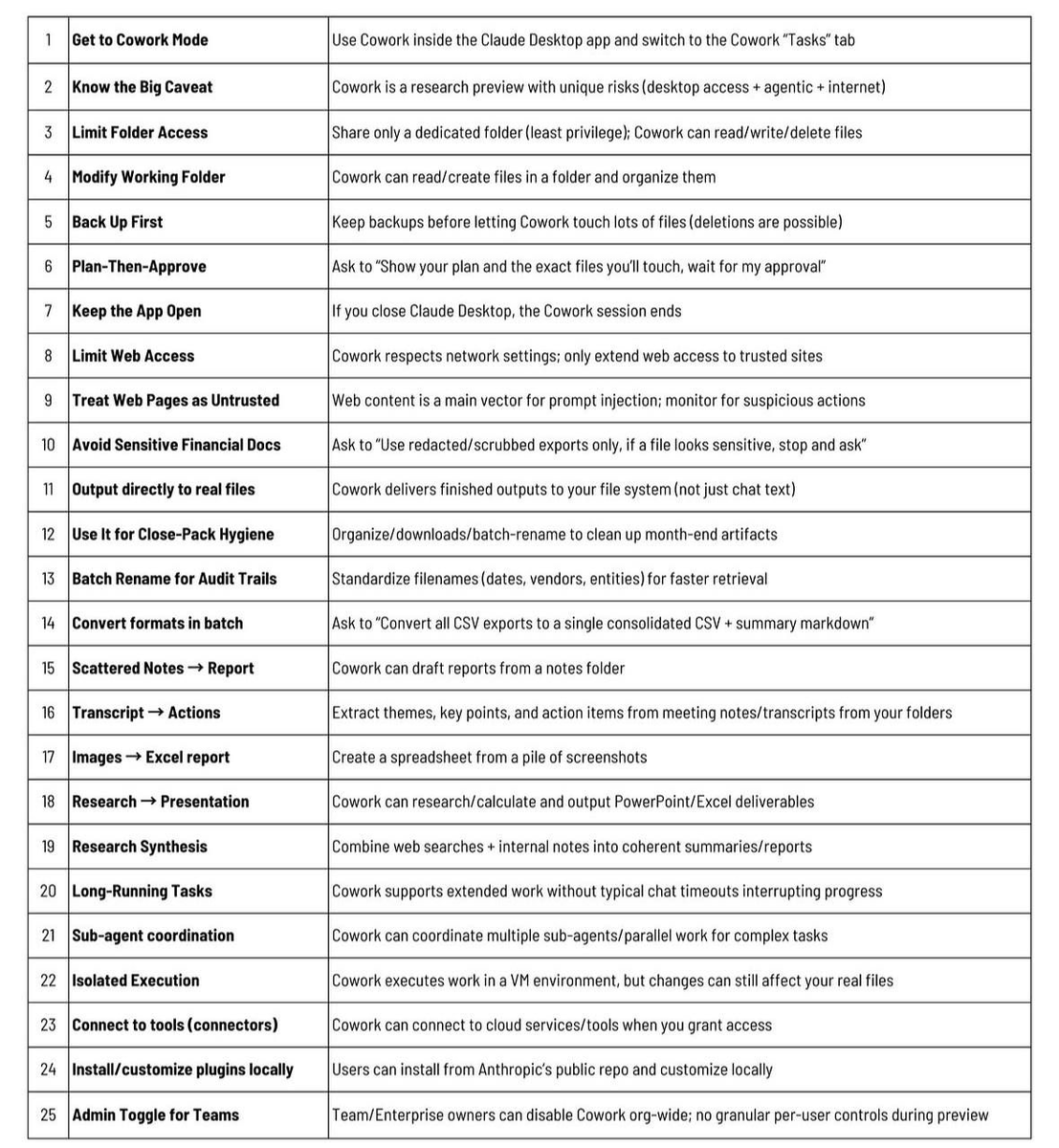
THIS CLAUDE COWORK CHEAT SHEET IS ALL THAT YOU NEED
15
7
173
42,402
May 30
I’ve played 1 games and found 1 words playing Word of the Day on Binance! binance.com/activity/word-of…
3
May 29
I’ve played 1 games and found 1 words playing Word of the Day on Binance! binance.com/activity/word-of…
3
Allan A retweeted

How do we get past the archons, commonly known as demons?🔥
Through Gnosis, which means Inner Knowledge ✨
Heaven is Closer than we think…
1
16
85
2,572