
ML Researcher @USAEOP | Reinforcement learning, RLHF & LLMs
Joined February 2024
- Tweets 85
- Following 184
- Followers 21
- Likes 350
17 Photos and videos













Pinned Tweet

Jan 10
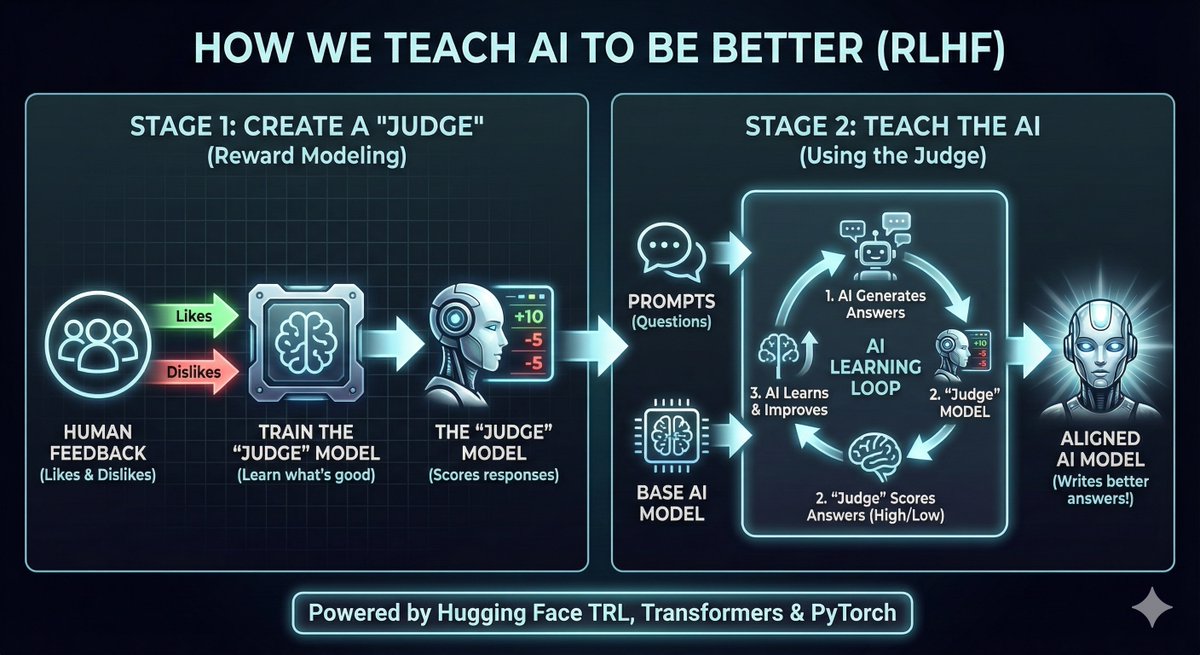
Ever wanted to learn the basics of Fine-tuning a LLM?
I just built a complete, single GPU friendly, end to end pipeline for RLHF fine-tuning using @huggingface TRL!
Here is the 2 stage process I did:
1⃣ Train a "Judge" (reward model) on human preferences (a subset of the @NVIDIAAI HelpSteer3 dataset)
2⃣ Align @GoogleDeepMind Gemma 3 with the judge using RLOO!
Try out the code below👇
#RLHF #ML #AI (Image generated by @NanoBanana )
1
2
920
Devin White retweeted

Apr 25
Self Attention vs Cross Attention by hand ✍️ Resize the matrices yourself 👉 byhand.ai/aMisxP
Two attention mechanisms, side by side. Both project X into queries; both compute attention via S = Kᵀ × Q and F = V × A. The only difference is the source of K and V.
Self attention uses X for everything. Q, K, and V all come from projecting X. Each X token attends to every other X token. The score matrix S is square — 128 × 128.
Cross attention uses X for queries and a second sequence E for keys and values. Each X token attends to every E token instead. The score matrix S is rectangular — 64 × 128.
Notice what's shared and what's not:
X is the same in both — same 36 × 128 input.
Q and K share the 16 dimension — that's what makes the dot product Kᵀ × Q valid in either case.
V dimensions are independent: self-attention uses 12, cross-attention uses 12. The choice doesn't depend on which mechanism you're using; it depends on what output dimension your downstream layer expects.
5
139
960
61,704
Devin White retweeted

Apr 25
Working on AutoRL is essential for making reinforcement learning more scalable and used in the industry.
Excited to be part of this workshop!🔥

🔥 AutoRL Workshop returns to RLC 2026 in Montréal 🇨🇦
Join us to tackle RL brittleness and advance methods that work “out of the box”.
More info: sites.google.com/view/automa…
This year's organisers are: Theresa Eimer, @DierkesJul67648, @johanobandoc, @pcastr, @HolgerHoos

3
17
1,220
Jan 10
Ever wanted to learn the basics of Fine-tuning a LLM?
I just built a complete, single GPU friendly, end to end pipeline for RLHF fine-tuning using @huggingface TRL!
Here is the 2 stage process I did:
1⃣ Train a "Judge" (reward model) on human preferences (a subset of the @NVIDIAAI HelpSteer3 dataset)
2⃣ Align @GoogleDeepMind Gemma 3 with the judge using RLOO!
Try out the code below👇
#RLHF #ML #AI (Image generated by @NanoBanana )
1
2
920
Jan 8
🚀Excited to share my latest project: A simple implementation of RLHF for Language Models using @GoogleDeepMind Gemma 3!
It demos the complete training loop from reward modeling to policy training, all powered by @huggingface TRL! Ideal for learning RLHF basics without the complexity. Thread 👇
#AI #ML #RLHF #HuggingFace #Gemma
1
4
208
Jan 8
⚙️Why This Project?
The goal of this project is to provide an easy to use template for RLHF experiments, research or just fun, while also being able to fit on a consumer GPU and being easy to use!
1
1
134
Jan 8
Try it out and let me know what you think! More updates coming soon!
Code: github.com/Dev1nW/Simplified…
1
105
31 Dec 2025
As 2025 comes to a close, I wanted to say thank you to everyone for their support throughout the year!
Some research highlights are in the thread 🧵
Looking forward to what 2026 has in store and excited for some updates coming soon!
#AI #ML #ReinforcementLearning #RLHF
1
3
103
31 Dec 2025
1 paper at a #NeurIPS workshop (@arlet_workshop)
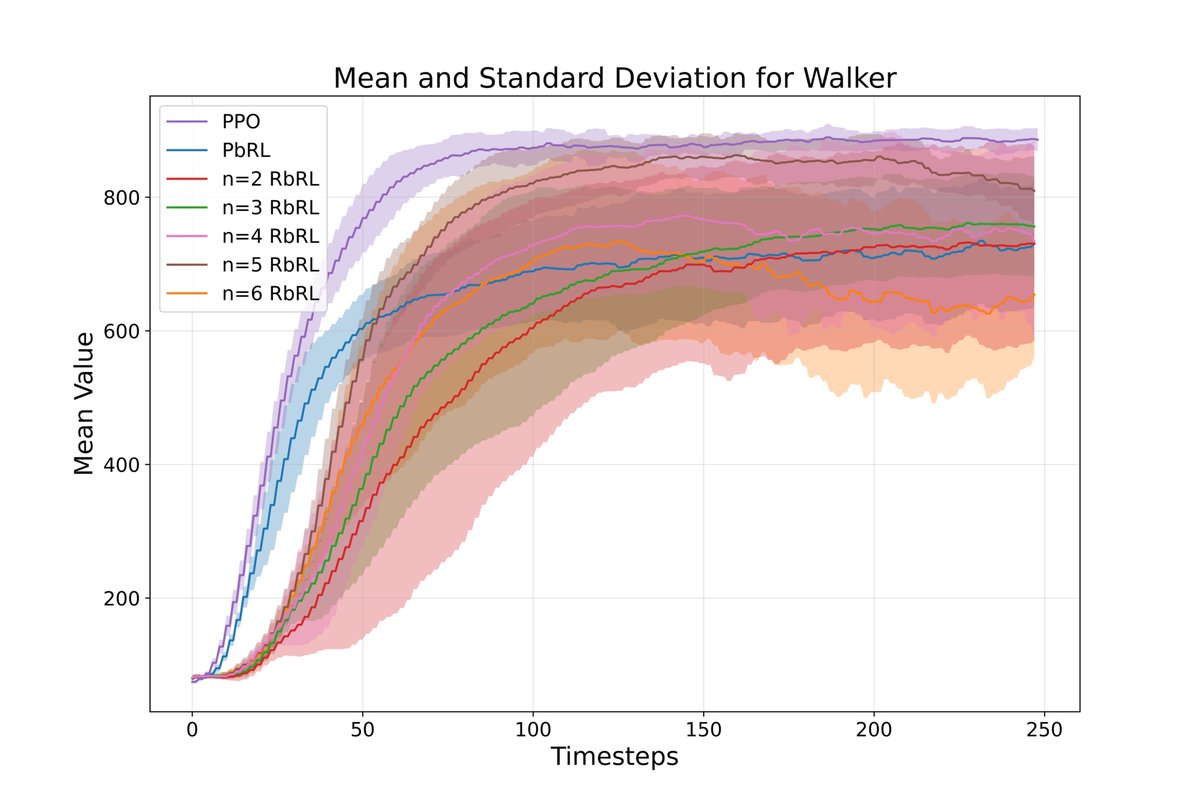
Human-Inspired Multi-Level Reinforcement Learning:
arxiv.org/pdf/2501.07502
And reached 50 citations this year!📈
1
1
86
31 Dec 2025
I’m especially thankful to all my collaborators, mentors, friends and the researchers I had the chance to meet, learn from, and exchange ideas with.
1
63
6 Dec 2025
Tomorrow at #NeurIPS2025 I’ll be presenting “Human-Inspired Multi-Level Reinforcement Learning” at the ARLET workshop.
🕤 Poster Session 2 - 3:30 PM
📍 Upper Level Room 31ABC
Working on RL/RLHF? Come say hi 👋
#ReinforcementLearning #RLHF
5
471
25 Nov 2025
Some more information on our paper at the ARLET workshop at #neurips2025!
📅 Date: Saturday, December 6, 2025
🕤 Poster Session 1: 11:15 AM
🕤 Poster Session 2: 3:30 PM
📍 Location: Upper Level Room 31ABC
📝 Paper: arxiv.org/pdf/2501.07502
#ReinforcementLearning #RLHF #AIResearch @arlet_workshop
2
294
Devin White retweeted

24 Nov 2025
We are looking for PhDs and Postdocs!
So proud of my students on achieving so many amazing things during their "very first year".
I have been asked many times how I like being faculty, especially with funding cuts. My answer is always "it is the prefect job for me"! Still deep in the honeymoon phase.
The only reason is the students are so amazing, making my transition so much easier. One year in, they already collected paper awards, orals, spotlights, etc
What makes me proudest is they are vividly alive: curious, playful, confident in their own weird way, light up when talking about ideas, and never afraid to explore "the thing might fail".
Everyone is just… themselves. And somehow, that version of themselves keeps shipping amazing work.
In today's anxious academic world, this kind of aliveness is what I will try best to protect.
Maybe the best part of being an advisor is that every student is so different and unique lol
Interestingly, coming to second year, they've got their own passions, I can't just plug my ideas into their heads. So when I get excited about sth new, my first thought is: "Okay, time to find some fresh first-years who will be thrilled about this!"
MLL lab is 1 year old, we started right in Oct 2024. We are growing and looking for more phds to join us!
1. Why our lab? (1/2)
2. Why @northwesterncs? (2/2)
In 2025 alone: NU has 7 faculty as Sloan Fellows, plus a Nobel winner! Check more below

29
144
1,017
193,861
22 Nov 2025
🚨Exciting news! Our paper “Human-Inspired Multi-Level Reinforcement Learning” was accepted to the ARLET Workshop @ NeurIPS 2025!
In this paper we not only do Rating-based Reinforcement Learning but use the ratings as demonstrations for learning as well! Excited to share more at the poster session! 🚀
#NeurIPS2025 #ReinforcementLearning #AIResearch @arlet_workshop
2
146
19 Jul 2025
Thank you to everyone who stopped by our presentations yesterday! I had a great time sharing our work and chatting with so many of you.
1
353
18 Jul 2025
If you're at #ICML2025 🇨🇦, join us today for our "Too Big to Think" oral presentation at 9:30AM (Room 215-216) and "Multi-Task Reward Learning from Human Ratings" poster at 12PM (Ballroom A)! See you there! #TinyTitans #RLHF
1
385