
AI Science, Quantum Computation, Quantum Many-body Physics
Joined July 2023
- Tweets 10
- Following 16
- Followers 63
- Likes 3
Photos and videos
Di Luo retweeted

11 Mar 2025
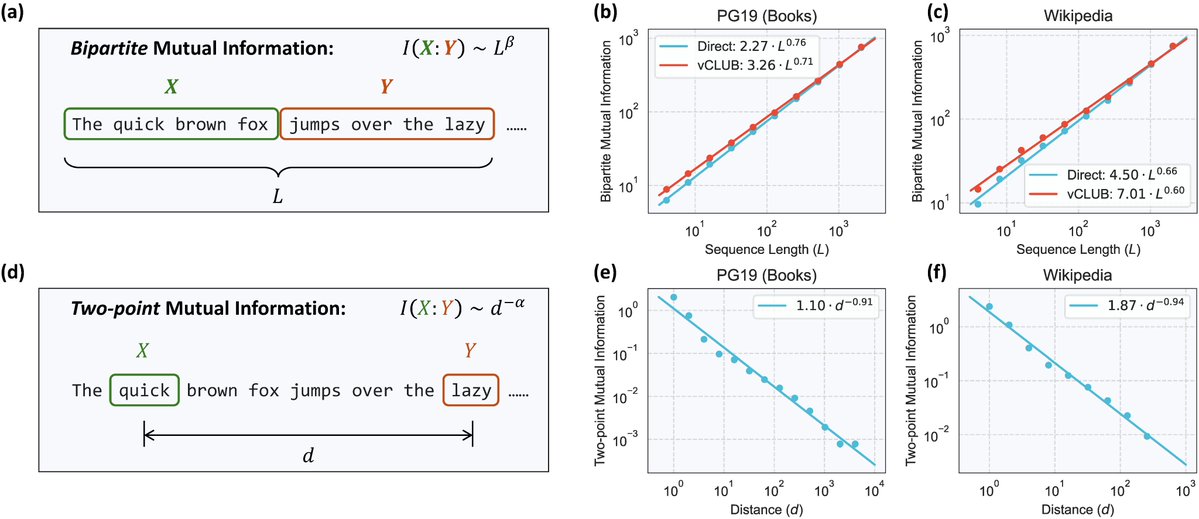
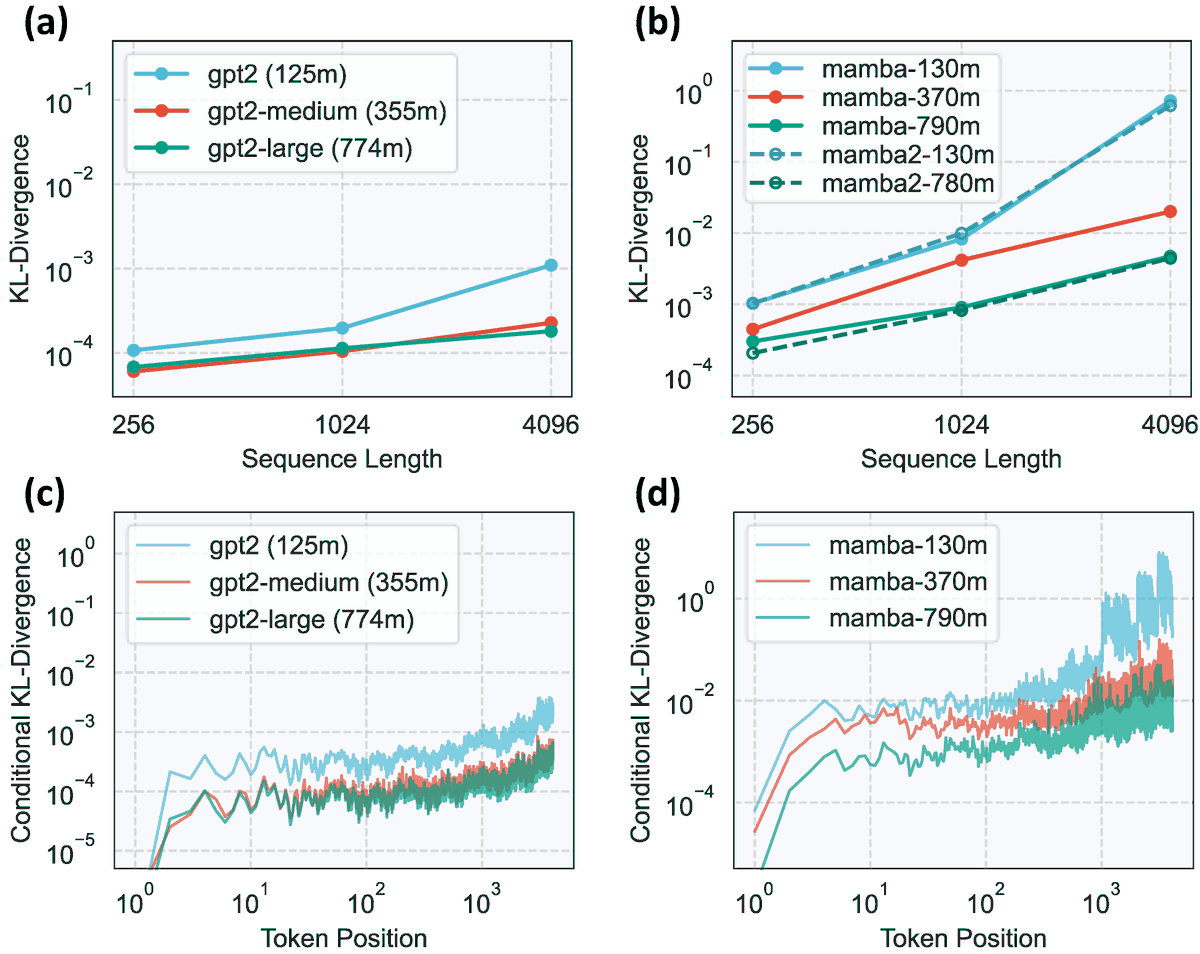
🚀 Excited to share our latest paper: L²M: Mutual Information Scaling Law for Long-Context Language Modeling
📌We identified a new scaling law that emerges as a general pattern in long texts: this leads to important insights in designing more powerful and efficient large language models
🔍 Key Highlights:
· 📈 Discovered a fundamental pattern in how information is shared across text at different scales, showing power-law growth as texts get longer
· 🧠 Proved that LLMs need growing memory capacity to effectively handle longer documents—similar to how humans need to remember more when reading a book versus a sentence
· 🔮 Our findings show that promises of "infinite context length" face natural limits—how well models handle longer texts depends on how their memory capacity scales
· ⚙️ Tested these findings across different model architectures, confirming the link between memory scaling and long-text performance
· 💡 Offers practical insights for building better AI models that can work with everything from short messages to entire books
📝 Read our paper: arxiv.org/abs/2503.04725
🤗 See our paper on Huggingface: huggingface.co/papers/2503.0…
💻 Explore our code: github.com/LSquaredM/mutual_…
With Zhuo Chen, Oriol Mayné i Comas, Zhuotao Jin, Di Luo, Marin Soljačić
#MachineLearning #AI #LanguageModels #LLMs #LongContextModeling #InformationTheory

2
5
13
1,485
Di Luo retweeted
7 Nov 2024
🚀 Thrilled to share that QuanTA, our innovative approach to highly parameter-efficient high-rank fine-tuning of LLMs, has been accepted to NeurIPS 2024! Looking forward to connecting on December 13!
📄 arxiv.org/abs/2406.00132
💻github.com/quanta-fine-tunin…

3
4
11
594

We are excited to present our work on "TENG: Time-Evolving Natural Gradient for Solving PDEs with Deep Neural Nets toward Machine Precision" at #ICML2024! Join us at Hall C 4-9, Poster #210, on July 24th, 11:30 am-1 pm CEST and virtually at Zoom: mit.zoom.us/j/97552446636.
1
2
463
Explore our poster: icml.cc/virtual/2024/poster/…
Read our paper: proceedings.mlr.press/v235/c…
See you there! 🚀 #MachineLearning #AI for Science #PDEs #ICML
277
Welcome attempts and feedback on our SciCode!
16 Jul 2024

SciCode is our new benchmark that challenges LMs to code solutions for scientific problems from advanced papers. The challenges were crafted by PhDs;
~10% of our benchmark is based on Nobel-winning research.
GPT-4 and Sonnet 3.5 get <5% ACC.
scicode-bench.github.io/ 🧵 1/6

302
🚀 Excited to share our latest paper: "QuanTA: Efficient High-Rank Fine-Tuning of LLMs with Quantum-Informed Tensor Adaptation"!
📄 Read the paper: arxiv.org/abs/2406.00132
💻 Explore the code: github.com/quanta-fine-tunin…
#NLP #LLM #Finetuing #MachineLearning #Quantum #GenAI
3
6
18
2,207
Di Luo retweeted

12 Dec 2023
Paper: arxiv.org/abs/2211.01365. Discussion: openreview.net/forum?id=IKQO…. Di Luo (@DiLuo28) (Co-first authors), Jiayu Shen (Co-first authors), Rumen Dangovski (@dangovski), and Marin Soljačić (rle.mit.edu/marin/).
1
1
2
244