
🇵🇭 builder, ai, markets, and general data nerd | dodatathings.dev
Joined March 2025
- Tweets 9,630
- Following 1,292
- Followers 1,391
- Likes 5,722
1,313 Photos and videos

















Jun 10
If you see this post, it's exactly for you.
I'm only the messenger:
Hot coffee > Cold brew IN ANY SEASON.
1
3
125
Jun 9
Wow 😳
Well done @AnthropicAI

Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
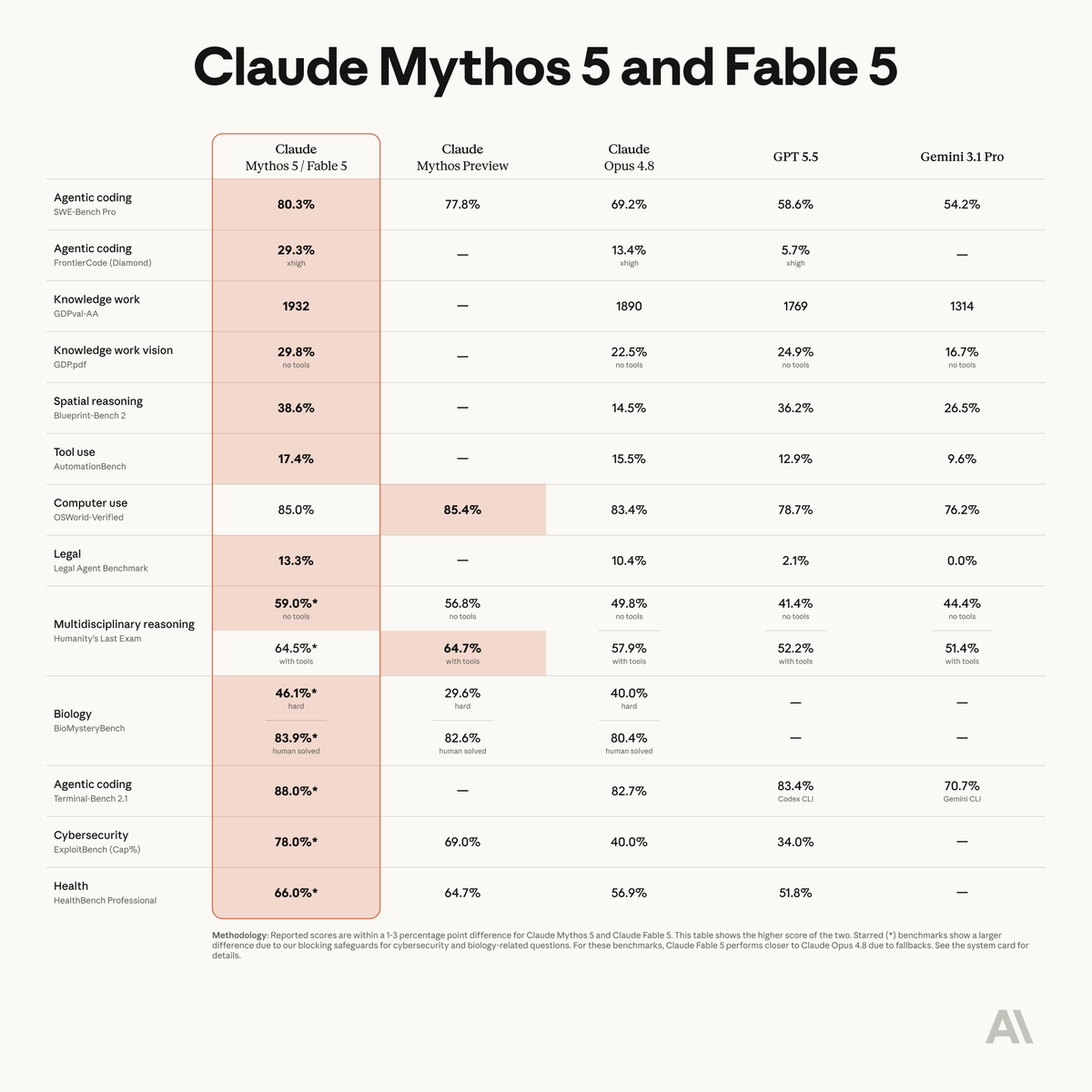
ALT Benchmark table titled Mythos 5 & Fable 5, comparing Claude Mythos 5 and Fable 5 against Claude Mythos Preview, Claude Opus 4.8, GPT 5.5, and Gemini 3.1 Pro.
1
2
115
Jun 7
Heat acclimatization is one of the most quantified variables in sport science.
A 10-14 day acclimation block at 32-35°C ambient delivers around 8% VO2max recovery, 12-15% plasma volume expansion, and a 40-50% drop in sweat sodium loss. Without it, top players run at roughly 88-92% of their cool-weather output.
Nordic teams at tournaments held above 28°C ambient have historically underperformed pre-tournament expected-goals models by 0.4-0.9 per match. Sportsbooks adjust tournament dispersion 2-4% on group-stage venue temperature alone.
Norway is playing this friendly cold. They'll feel different in two weeks.
Jun 5

🚨 𝗡𝗘𝗪: Looks like the Norwegian squad is struggling to adapt to the heat… 🥵




Community note
They are sun tanning, which is very popular in Scandinavian cultures.
en.wikipedia.org/wiki/Sun_tanni…
1
232
Jun 7
The S&P drop after a strong jobs print is duration-trade mechanics, fully on schedule.
Strong NFP repriced the Fed-cut path. Fed funds futures pushed the 2026 terminal rate roughly 35-50 bps higher in a few hours. Every 50 bps of term premium historically compresses S&P forward multiples by 1.0-1.3 turns.
$2T on a ~$52T market cap is a 3.8% drawdown. On a 21.5x forward multiple, that prints around 0.8 turns of compression, slightly below what the rate move implied. The tape absorbed it cleanly.
Bitcoin is a separate clock. October 2025 was the peak; the chart has been a controlled bleed since the ETF-flow inversion in Q1. Stapling that to today's equity move is correlation theater.

What just happened?
The S&P 500 just erased nearly -$2 TRILLION of market cap just hours after 3rd strongest US jobs report in 18 months.
Meanwhile, Bitcoin is officially down over -50% from its record high in October 2025.
What's happening? Let us explain.
(a thread)

2
2
173
Jun 7
Pasteurization is one of the highest-ROI public health interventions ever deployed. The mechanism is 63°C for 30 minutes.
US child mortality from milk-borne pathogens (TB, brucellosis, listeria, typhoid) collapsed from a major share of infant deaths around 1900 to functional zero by 1955, tracking the rollout of urban pasteurization mandates between 1914 and 1947.
CDC surveillance puts raw-dairy illness rates at roughly 150x pasteurized on a per-serving basis. The US raw-milk market is around $30-40M annually. People are paying retail for a Victorian-era risk surface.
It's the only health movement where the entire supply chain is literally a temperature setting.
Jun 5

Never understood why people have beef with pasteurization. It’s literally just heat. What did Louis Pasteur do to you?
53
Jun 6
Seems like the binding constraint has already shifted: grid permitting and power delivery are gating capex that's ready to deploy. 11 GW of announced US data center capacity is showing no construction progress because the power isn't there, while individual sites now need 100-750 MW each.
With $600B committed for 2026, compute is no longer the scarce input. That concentrates future inference capacity in geographies with pre-secured power agreements, which starts to look like pricing power for whoever holds those sites.

The AI boom is colliding with hard limits on cost, infrastructure and energy.
Here are the forces shaping tech in 2026: thein.fo/4o7gENZ
207
Jun 4
Wells Fargo just published the first major sell-side note explicitly framed as buy the bubble on AI capex. The thesis: hyperscaler capex is in a bubble, that bubble is the trade, and the asymmetric move is to ride it through the 2027-2028 supply window before infrastructure overbuild prints on the income statements.
The number behind the call is hyperscaler capex tracking to roughly $500 billion in 2026 across MSFT, GOOG, AMZN, META, and ORCL combined. WF is not arguing the spend is rational on 10-year ROIC math. They are arguing it is happening, the names tied to it (NVDA, AVGO, CRWV, AMD, the data center REITs) are the vehicles, and the timing window is the next 6 to 8 quarters.
The shift in posture is the story. Sell-side desks went from cautious-bull (it is a bubble but rational) to explicit-bubble-trade in under 12 months. That progression is how late-cycle calls actually get made: the bubble framing becomes the institutional consensus before the consensus becomes the contrarian risk.
The 2 questions to track: does any other major desk match the framing inside 60 days, and does the WF call get cited in client meetings as the cover for an overweight that was already on. Bubble-trade notes are usually 3 to 6 months early or 3 to 6 months late. Almost never on time.
Source: fortune.com/2026/05/13/ai-eu…
1
137
Jun 4
Google just ran a dual pricing move on AI Ultra. The top tier dropped from $250 to $200, and a new $100 tier was inserted underneath. Both tiers bundle YouTube Premium, which retails at $14 per month, so the effective AI spend on the $100 tier is $86.
For reference: ChatGPT Plus is $20, Claude Pro is $20, ChatGPT Pro is $200. Google's $100 tier sits in an empty slot in the prosumer market with a Gemini 3.5 Pro quota plus Spark agent access plus a $14 video subscription baked in. That is a bundle math problem, not a price cut.
The move reads as a wedge against ChatGPT Plus on quota and against Claude Pro on agent access. Spark is the differentiating SKU here: a 24/7 unsupervised consumer agent that no other $100 tier offers. Google is willing to surrender $50 of margin per top-tier seat to anchor a new $100 floor that competitors can either match (margin hit) or skip (feature gap).
The interesting print is in 4 months. If the $100 tier pulls 2 to 3 million prosumer subs by Q4, Google has effectively repriced the consumer AI tier without an ad ever running. If it pulls 200,000, the bundle math was wrong.
Source: blog.google/products-and-pla…
254
Jun 4
NVIDIA shipped Cosmos 3 to HuggingFace today and put a 32B reasoning Vision-Language-Action model (Alpamayo 2 Super) on a summer release calendar, naming L4 robotaxi developers as the target customer in the press release headline. The chip vendor that sells GPUs to every closed AV lab on the planet just open-weighted the model layer above its own silicon. AlpaGym (closed-loop RL) and OmniDreams (generative world model) ship alongside, which means the training and validation surface is open too.
Waymo, Cruise, and Tesla FSD disclose nothing comparable. The comparison being made today is available vs. not available, and that's the comparison that re-prices the closed AV stack.
dodatathings.dev/blog/the-32…
1
1
95
Jun 3
AWS Bedrock AgentCore Runtime went GA in October 2025 with a Firecracker-style microVM per agent session, and the harness preview from April 22 is what finally makes that runtime addressable for unsupervised long-running agents. The convergence window (October GA April harness May/June rollout into production patterns) is the actual story.
Firecracker microVMs give per-session isolation at ~125ms cold start and ~5MB memory overhead. The AgentCore Runtime extends that pattern with 8-hour session lifetimes, per-agent IAM boundaries, and a built-in checkpoint API. That is the first production answer to the question every agent platform has been waving at: how do you run 10,000 concurrent agent sessions without one of them eating the others.
The technical depth is in 2 places. First, the isolation boundary is a hypervisor-level VM, not a container, so a compromised agent cannot escape into shared address space. Second, the session lifetime decouples from the API call pattern, which means an agent can wait 6 hours on a human approval without holding a Lambda warm.
The production-runtime problem just got 1 less excuse. Now the eval, observability, and governance layer is the thing buyers have to build on top, and that is still on the buyer.
Source: aws.amazon.com/blogs/machine…
1
2
88
Jun 3
Google Antigravity 2.0, Microsoft Agent Framework 1.0, and AWS Bedrock AgentCore Runtime all GA'd inside a 60-day window. Five days after the latest one, Axios reported a $500M Claude bill racked up by one company that forgot to set usage caps. Same story, two surfaces: the runtime layer commoditized, and the harness around it (eval, cost governors, golden-set tests, trace replay) is still 100% the buyer's problem.
Adobe says 31% of enterprises have an agentic measurement framework. Gartner forecasts 40% of agentic projects cancel by 2027. The runtimes don't close that gap.
dodatathings.dev/blog/runtim…
67
Jun 2
Cloudflare just cut 1,100 roles, roughly 20% of headcount, in the same quarter internal AI usage climbed 600% over 3 months. That is not a coincidence.
That is the substitution mechanism showing up on the income statement.
The specific framing matters. Internal AI usage at a hyperscaler-adjacent infra company tracks workflows that previously consumed human-engineering hours: log triage, incident summarization, doc generation, customer support tier 1, internal tooling. 600% in 3 months means the curve broke vertical somewhere around February.
20% headcount cuts at 5,500 employees is the visible side of the AI-substitution thesis crossing an operational threshold inside a company that ships infra. When the company that sells you the network is the one running the substitution test on itself, the test result is no longer hypothetical.
The next 2 quarters of Cloudflare gross-margin prints are the leading indicator. If COGS-per-revenue-dollar drops materially while headcount stays flat, every CFO at a 1,000-to-10,000-employee SaaS company is going to be reading the same 10-Q with a calculator open.
Source: blog.cloudflare.com/building…
60
Jun 2
Gemini Spark runs on a dedicated GCP VM 24/7 whether your laptop is open or not. That single mechanic is what the new $100 Google AI Ultra tier prices, and it inverts the consumer AI subscription shape. ChatGPT Plus at $20 is session compute. Spark at $100 is idle compute. The break-even question is whether residency locks subscribers tighter than tokens ever could, and Google is willing to eat dedicated-VM cost per subscriber to find out.
Adobe's data: only 31% of enterprises have a measurement framework for agentic AI. Google priced the prosumer wedge anyway.
dodatathings.dev/blog/the-un…
74
Jun 2
Kimi K2.6 just took #1 on the Artificial Analysis Index among open-weight models at a composite score of 54. That number sits inside frontier-closed territory from 6 months ago. The post-GLM, post-DeepSeek V4 ranking is now a Chinese open-weight at the top of the open table.
The AAI Index composite blends reasoning, coding, and instruction-following across 10 evals. At 54, K2.6 clears the 50 line that was Claude 3.5 Sonnet territory in mid-2025. Open weights, 1T parameters, $0.95 per million input tokens.
The practical read: every diligence team that wrote off open weights at the GPT-4 frontier has to re-run the procurement math at the GPT-4o frontier. Self-hosting flips above ~10M tokens/day, and K2.6 just moved the quality side of that calculation up a full tier.
The leaderboard refresh is a forcing function, not a vibe. The next 4 enterprise eval cycles will tell us whether the Chinese open stack is now the default fallback when the closed labs hike API pricing in Q3.
Source: artificialanalysis.ai/articl…
1
57
Jun 2
Anthropic shipped Opus 4.8, closed a $65B Series H at $965B post-money, and put ENISA inside Project Glasswing in one calendar week. The draft EO that named Mythos as catalyst never got signed. The regime is the policy default anyway: 5 frontier labs voluntarily inside CAISI, the first foreign cyber agency inside Glasswing, and 10 GW of named capacity retiring the federal-access-degradation objection.
The May 4 prediction lands. I scored all four claims six weeks later.
dodatathings.dev/blog/boomer…
1
1
58
May 30
It’s insane.
24x token volume against 60-70% annual cost-per-token compression puts hyperscaler unit economics on whether agent loops produce enterprise outcomes that justify procurement.
The 120 quadrillion projection assumes the loops actually ship deliverables. If the NBER survey holds and 80% of firms see no productivity gain at current usage, the demand curve flattens long before chip efficiency does.
May 30

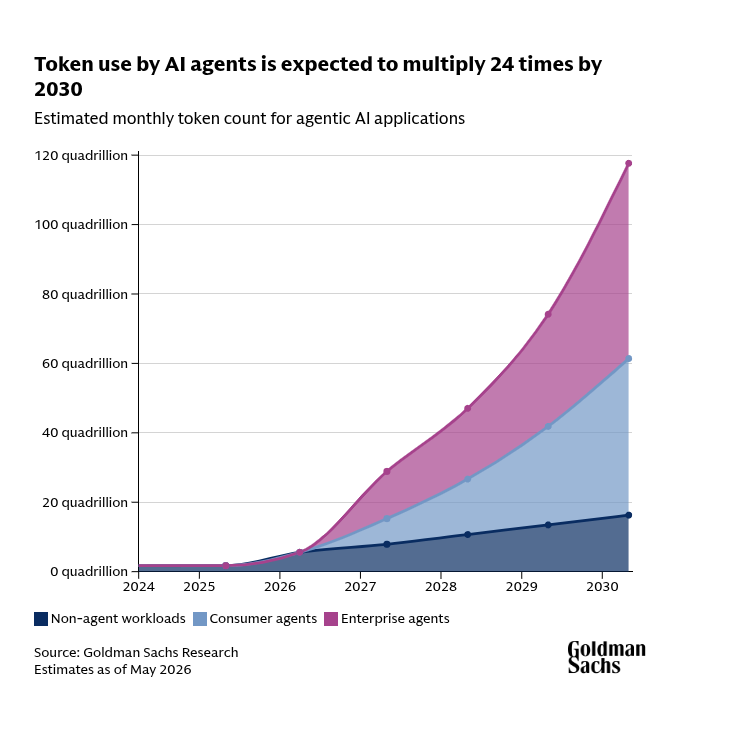
Goldman Sachs: "Token use by AI agents is expected to multiply 24 times by 2030"
AI agents are now creating the first serious cost test for the AI boom. As was reported this week, Uber and Microsoft are already rethinking expensive agent usage.
A chatbot may answer once, but an agent plans, calls tools, checks results, edits mistakes, and repeats the loop.
That loop can make one user request consume 10x, 50x, or even far more tokens than a normal answer.
Goldman’s bullish case is that monthly token use could reach 120 quadrillion by 2030, while inference cost per token keeps falling 60%-70% per year.
The fight is now between agent productivity and token waste.
Earlier this month, Microsoft began revoking developer access to Claude Code, with plans to move them to its in-house Copilot Command Line Interface tool by June 30. The company has framed this as consolidating teams around its own tools, but the timing at the fiscal year’s end hints it may also be about lowering costs.
1
3
201
May 29
Look at the cadence. 41 days from Opus 4.7 to 4.8, $380B to $900B in three months. Capital and model velocity moving on the same clock.
May 29
Today on TITV:
-Anthropic Debuts Newest Model Claude Opus 4.8 | @CobiBGantz
-Anthropic Valued at $900B Pre-Money | Editor’s Cut with The Information’s @lauramandaro & @jasonrdean
-Do Better AI Models Actually Accelerate Adoption? | @jmwind
📺 Tune in at 10 am PT / 1 pm ET on thein.fo/3OkxZpg
2
113
May 29
Lines up with what I see running agent loops on my own infra: the 17x compression hits hard on migrations specifically because they're high-context, low-creative work, well-scoped tickets with clear acceptance criteria.
Salesforce's approach makes it concrete: rule-based framework, parallelized isolated environments, feedback from each PR round baked back into the ruleset.
Discovery work and ambiguous-spec tasks compress much less, which is probably the better forcing function for figuring out where to deploy this next.
May 29

Salesforce published a detailed writeup on going agentic with Claude Code. A couple things jumped out.
A migration they'd scoped at 231 days shipped in 13. One PR delivered 21 endpoints at 100% test coverage.
1
82
May 28
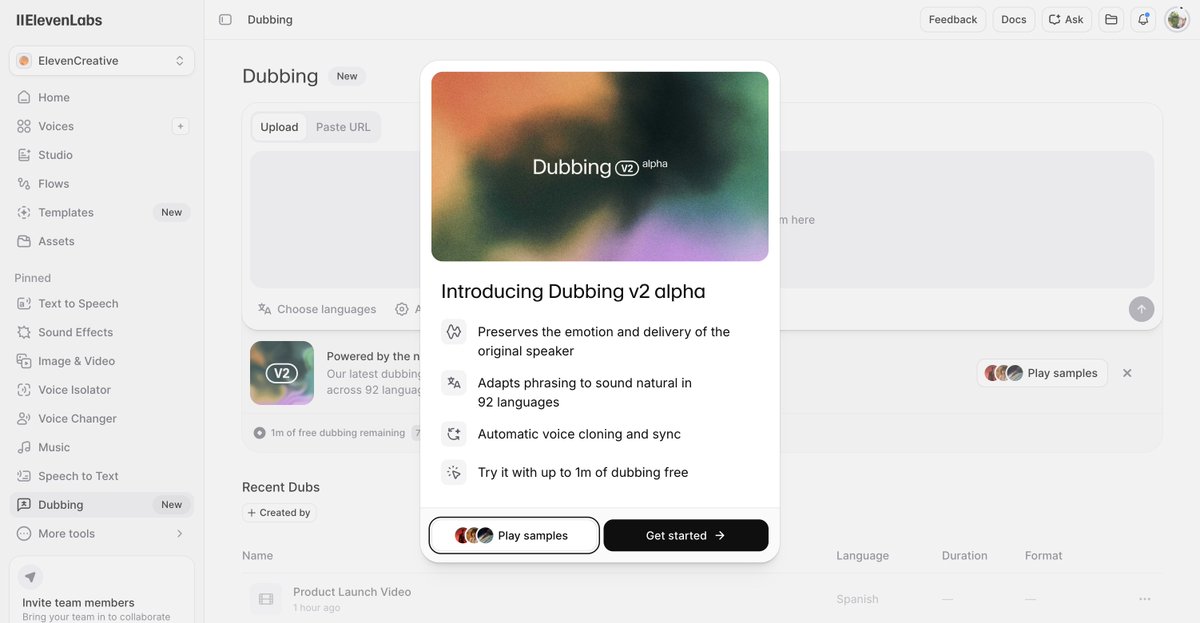
Means the bar just moved to performance fidelity. Every YouTuber with a 100K English channel suddenly has 32 dubbed channels of long-tail watch time to harvest.

ElevenLabs introduced a new Dubbing v2 Alpha model that can translate speech across all languages while preserving the emotional tone of the original content.
Big for creators 👀
2
113
May 28
Interesting. If pretraining data plus tokenizer dominate the loss scaling exponent like recent work suggests, model size becomes a weaker lever than most assumed. Mamba vs Llama barely moves it. Big efficiency gains likely come from data curation and tokenizer design going forward.

LLMs reliably score lower loss, and the loss drops as a smooth power of model size, but nobody had pinned down what physical thing inside the network produces that particular curve.
This MIT paper proposes an answer rooted in superposition, the trick by which a network packs more distinct features into its hidden space than it has dimensions, by letting feature directions overlap a little rather than sit perfectly perpendicular.
Read with an AI tutor: chapterpal.com/s/3db4fdd8/su…
PDF: arxiv.org/pdf/2505.10465
2
78