
Asst. Prof. of Natural Language Processing @UofHaifa
Joined November 2018
- Tweets 205
- Following 250
- Followers 326
- Likes 551
3 Photos and videos


Rotem Dror retweeted

May 4
Attention #NLProc researchers, the EACL 2027 website is officially LIVE: 2027.eacl.org/! 🎉
🇬🇷 Join us in Athens, Greece (Mar 9-13, 2027) at #EACL2027
📅 ARR submission deadline: Aug 6, 2026. Open to all areas of CL/NLP related fields. Stay tuned for the detailed CfP!

ALT The Acropolis in Athens, Greece
3
29
141
14,911

Apr 12
🚨 New Paper(s) Alert 🚨
I’m excited to share papers I’ve recently published, exploring a different application of LLMs:
mdpi.com/2673-2688/7/2/73
arxiv.org/abs/2603.12710
mdpi.com/2079-8954/14/2/123
dl.acm.org/doi/full/10.1145/…
(Sorry for the paper drop — I’ve been offline for a while.)
1
16
947
Apr 12
• Adaptive surveys LLMs for measuring extreme psychological constructs
• Planning-based view evaluation of LLM web agents
• BET: detecting behavioral & emotional themes in narratives
• Lilo: multi-agent system for children’s digital communication
1
4
156
Apr 12
All very different, but the common theme is: using LLMs in structured, evaluable, and purpose-driven ways.
1
5
124
Rotem Dror retweeted

Feb 24
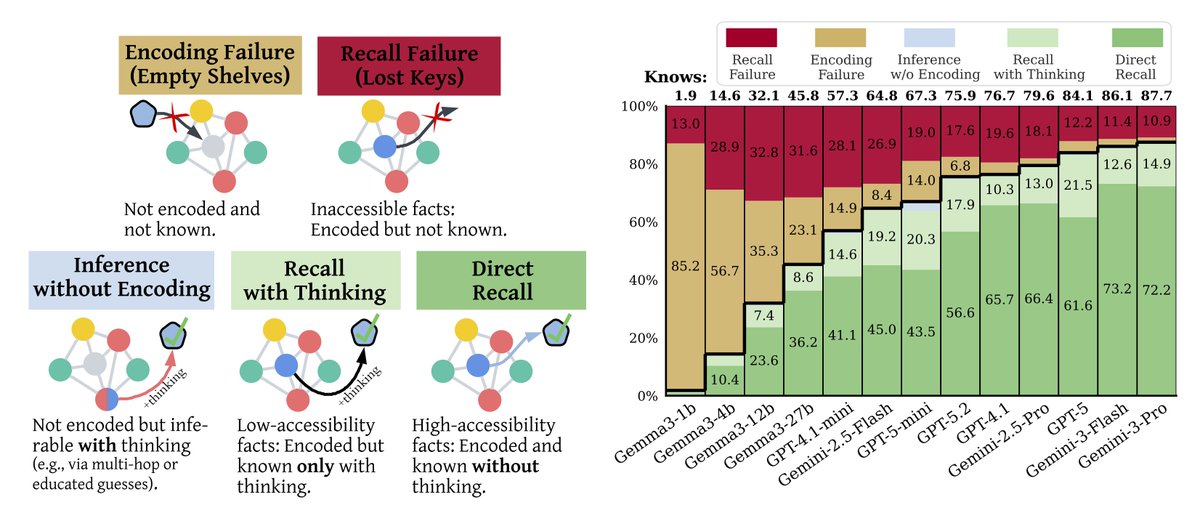
[1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: arxiv.org/abs/2602.14080
Many thanks to @_galyo @bd_eyal @zorikgekhman @eran_ofek59358 @GoogleResearch
4
33
124
13,149
Rotem Dror retweeted

4 Aug 2025
A strange trend I've noticed at #ACL2025 is that people are hesitant to reach out to papers/"academic products" authors.
This is unfortunate for both parties! A simple email can save a lot of time to the sender, but is also one of my favorite kind of email as the receiver!
1
33
1,540
30 Jul 2025
Tomorrow morning (9AM🌅) I'll be giving a keynote talk at LAW (linguistic annotation workshop) at #ACL2025 on annotations in the era of LLMs - see you there!!🌟🌟
3
17
906
Rotem Dror retweeted
25 Jul 2025
The Alternative Annotator Test (alt-test) is a new statistical procedure proposed in our ACL 2025 paper! 🇦🇹🇦🇹 @DrorRotem @roireichart
The goal? To help justify using LLMs over humans. If the LLM passes the test, its annotations can be trusted 😎
arxiv.org/abs/2501.10970
1
1
10
452
Rotem Dror retweeted
25 Jul 2025
Everyone uses LLMs to annotate data or evaluate models in their research.
But how can we convince others (readers, collaborators, reviewers!!!) that LLMs are reliable? 🤖
Here’s a simple (and low-effort) solution: show the LLM is a *comparable alternative annotator* ✅

3
19
69
6,008
Rotem Dror retweeted

25 Jun 2025
🔥הסקירות ממשיכות לזרום ל-X🔥
🧵
המאמר היומי של מייק: 25.06.25
The Alternative Annotator Test for LLM-as-a-Judge: How to Statistically Justify Replacing Human Annotators with LLMs
מאמר 🇮🇱
תפנית מעניינת מתרחשת בתקופה האחרונה בעולם של הערכת ביצועי מודלים. אנחנו כבר לא שואלים רק עד כמה המודל מצליח במבחן כלשהו, אלא שאלה מהותית יותר: האם ניתן לסמוך על מודל שפה שיחליף מתייג אנושי? זו לא שאלה שמדדים מסורתיים כמו דיוק, F1 או הסכמה בין מתייגים יכולים לענות עליה כראוי. תחת זאת, המאמר שנסקור היום מציג שיטה מבוססת סטטיסטיקה לפתרון ביעה זו. בלב המאמר עומדת קריאה להתרחק ממדדי התאמה שטחיים, ולעבור לנימוקים מבוססי השערות סטטיסטיות וניתוח עלות-תועלת.
3
7
24
4,063
Rotem Dror retweeted
4 Jun 2025
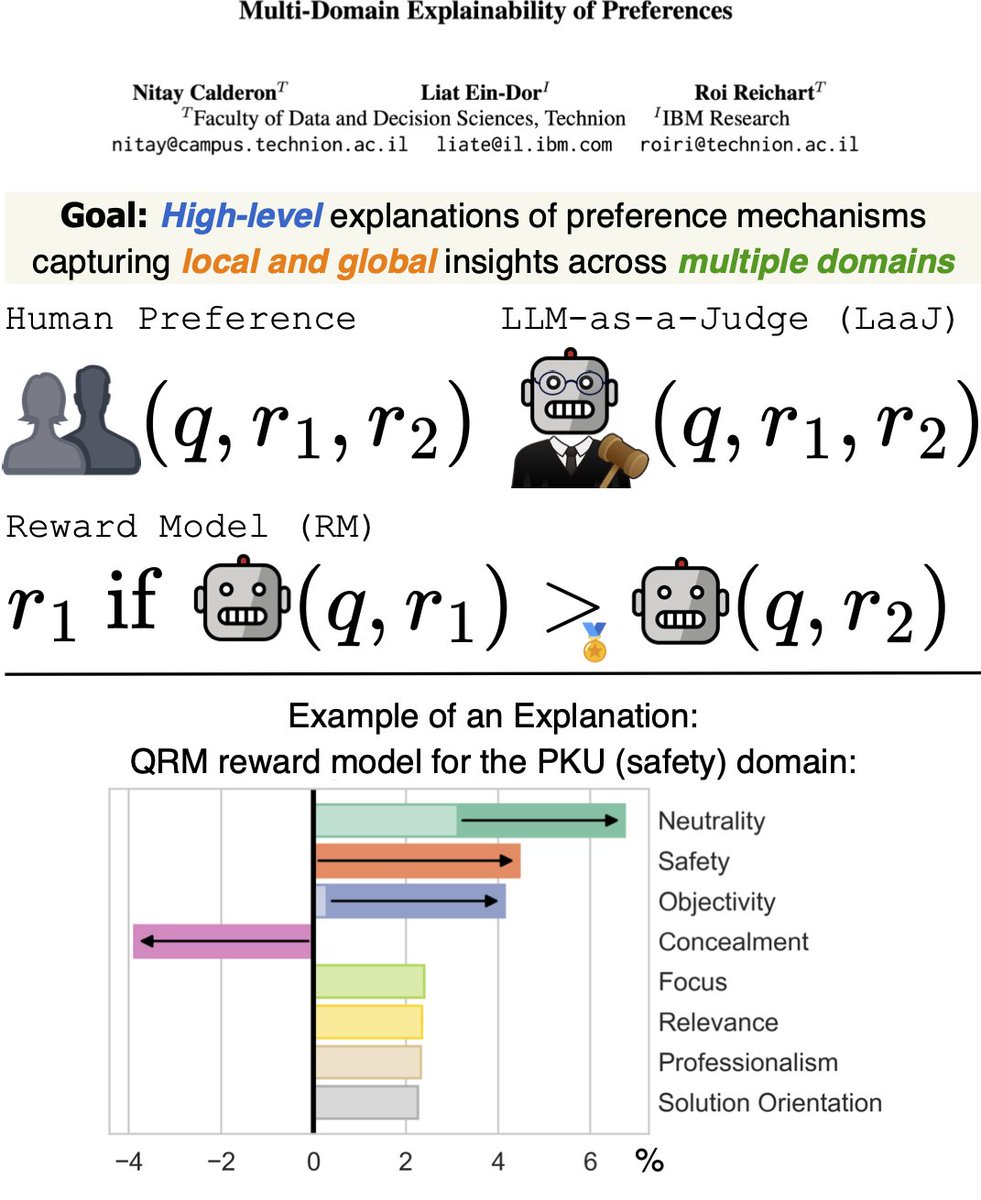
Preferences drive modern LLM research and development: from model alignment to evaluation.
But how well do we understand them?
Excited to share our new preprint:
Multi-domain Explainability of Preferences
arxiv.org/abs/2505.20088
@roireichart @LiatEinDor
🧵👇
1/11
2
17
36
2,225
8 May 2025
Join us at the University of Haifa for the HiAI Conference, a dynamic event at the forefront of Artificial Intelligence.
Immerse yourself in groundbreaking discoveries, gain exclusive insights into the latest advancements, and navigate the future of AI with leading experts.
1
1
37
8 May 2025
Keynote speakers:
. Hod Lipson, Mechanical Engineering, Columbia University, USA
Prof. Mor Naaman, Information, Cornell Tech, USA
Prof. Tanya Berger-Wolf, Computer Science & Engineering, Ohio State University, USA
1
43
8 May 2025
This is your chance to uncover revolutionary research, forge invaluable connections, and become part of the AI innovation wave.
Conference dates: May 25-27, 2025 📷 Information and registration: lnkd.in/dKqAtP6p
21
Rotem Dror retweeted
25 Jan 2025
In our new preprint, @roireichart ,@DrorRotem and I propose a new statistical procedure:
The Alternative Annotator Test (alt-test)
The goal? To help researchers justify using LLMs over humans—if the LLM passes, its annotations can be confidently trusted😎
arxiv.org/abs/2501.10970
1
2
13
1,618
Rotem Dror retweeted

25 Jan 2025
Check out our new pre-print on statistically sound methodology to verify the quality of LLM-as-a-judge annotation. @NitCal @DrorRotem
25 Jan 2025

In our new preprint, @roireichart ,@DrorRotem and I propose a new statistical procedure:
The Alternative Annotator Test (alt-test)
The goal? To help researchers justify using LLMs over humans—if the LLM passes, its annotations can be confidently trusted😎
arxiv.org/abs/2501.10970
2
8
551
25 Jan 2025
A few months ago I told you that I'm working on something awesome and I need some datasets...well here is the first output of that effort and I sincerely think it's amazing 🤩 check it out! @NitCal @roireichart #llm-as-a-judge, #nlpevaluation
25 Jan 2025
Do you use LLM-as-a-judge or LLM annotations in your research?
There’s a growing trend of replacing human annotators with LLMs in research—they're fast, cheap, and require less effort.
But can we trust them?🤔
Well, we need a rigorous procedure to answer this.
🚨New preprint👇

6
23
897
Rotem Dror retweeted
12 Nov 2024
Do you think LLMs could win a Nobel Prize one day? 🤔
Can NLP predict heroin addiction outcomes, uncover suicide risks, or simulate brain activity? 🧠
@lotemi_peled, @roireichart, and I wrote a blog post about NLP for Human-Centric Sciences 🤖👩🔬
👇👇👇
nitaytech.github.io/blog/202…
8
17
594