
Research Scientist @GoogleResearch | PhD @TechnionLive | NLP
Joined June 2022
- Tweets 347
- Following 777
- Followers 459
- Likes 620
85 Photos and videos





Pinned Tweet

Feb 24
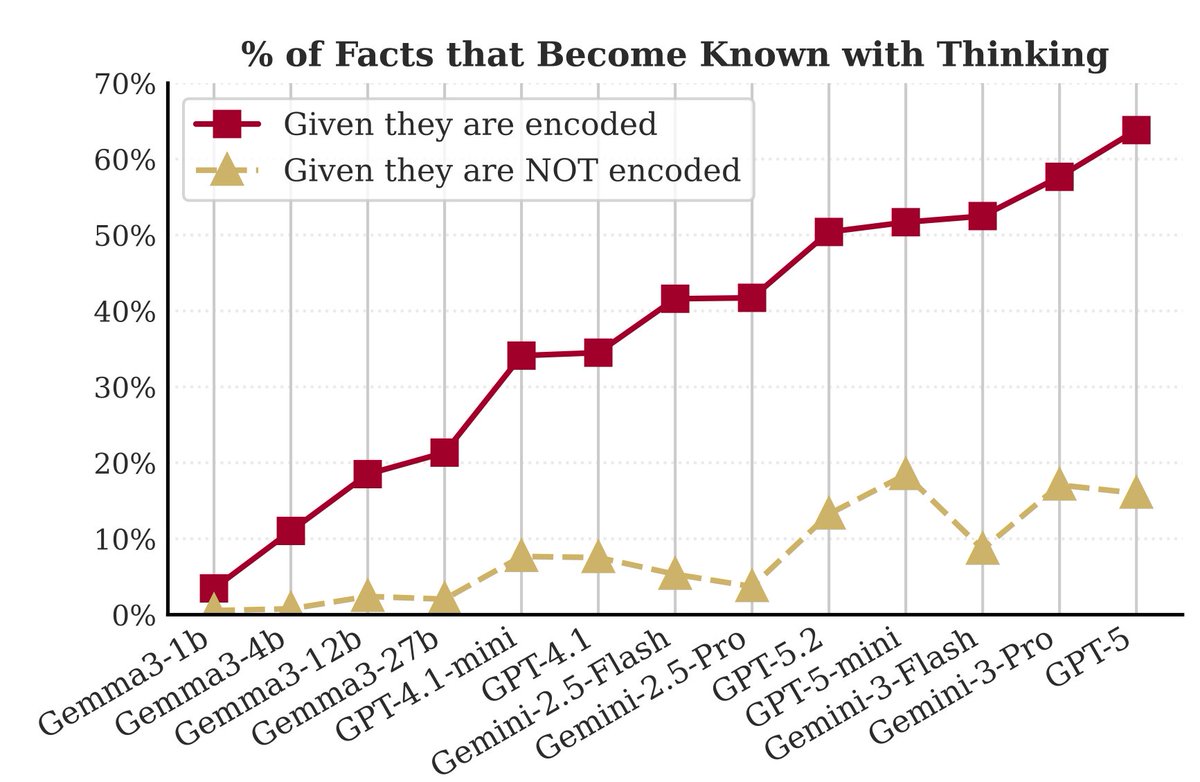
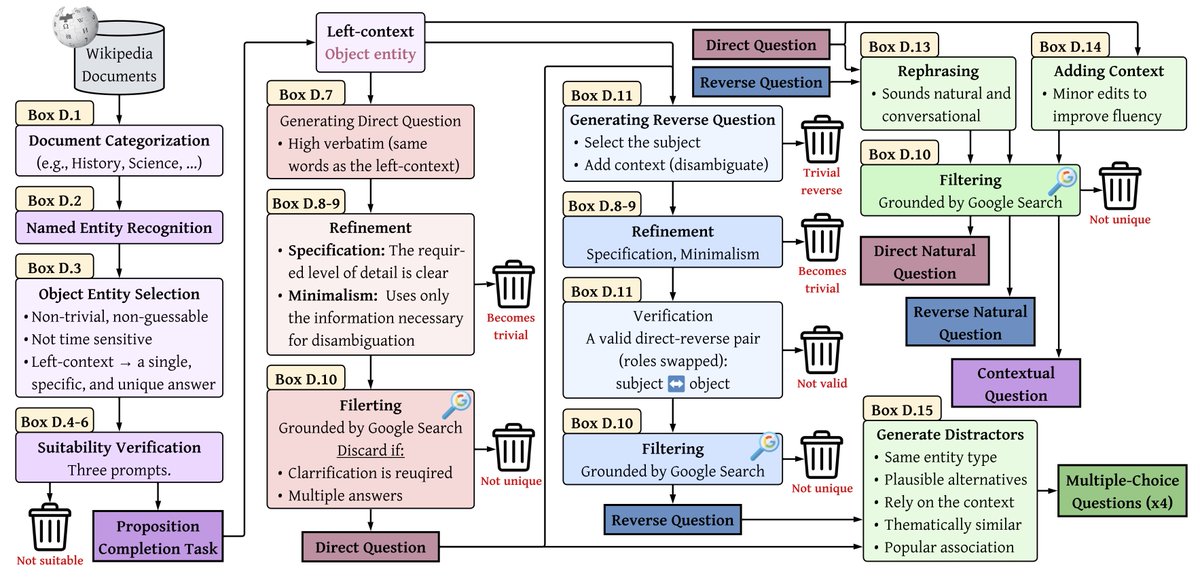
[1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: arxiv.org/abs/2602.14080
Many thanks to @_galyo @bd_eyal @zorikgekhman @eran_ofek59358 @GoogleResearch
4
33
124
13,149
Nitay Calderon retweeted

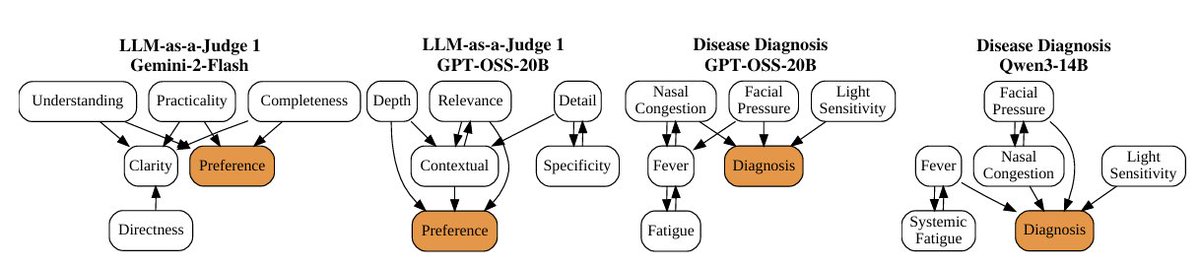
Thrilled to share our new paper: "LLM Explainability with Counterfactual Chains and Causal Graphs"! 🚀
We introduce a fully automated, model-driven method to extract global, concept-level causal graphs of an LLM's internal reasoning.
📄 arxiv.org/abs/2606.05972 🧵👇 [1/8]
2
12
68
5,279
Nitay Calderon retweeted

Jun 2
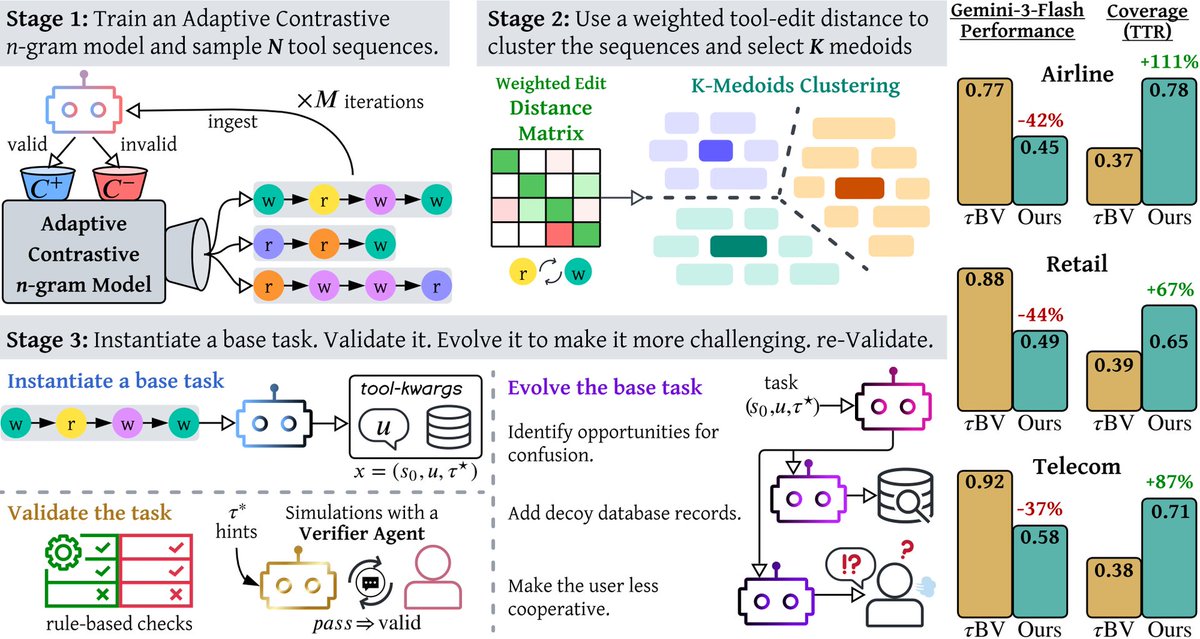
A matter of TASTE
Current agent benchmarks are saturated. TASTE reverses how they're built—starting from tool sequences, not hand-written scenarios.
Models scoring 90% on current tests crash to 30% on TASTE, facing 2× more tool combinations.
1
5
24
1,916
Nitay Calderon retweeted

May 29
Our posting for joining Google DeepMind as a Research Scientist was down for a few days but now it is back up!
Apply here: google.com/about/careers/app…
And fill out this form: docs.google.com/forms/d/e/1F…
May 16

Want to join Google DeepMind as a research scientist working on AI for health and medicine?

6
34
362
71,106

We build on existing work showing that frontier performance on all sorts of transfer is more inconsistent than we might hope, especially after learning from trillions of tokens:
x.com/NitCal/status/20263003… @NitCal
x.com/omerNLP/status/1907058… @omerNLP
arxiv.org/abs/2408.10646 @LChoshen
1 Apr 2025

Wanna check how well a model can share knowledge between languages? Of course you do! 🤩
But can you do it without access to the model’s weights? Now you can with ECLeKTic 🤯

1
1
2
411
Preprint 🧵! How compartmentalized are LLMs?
For data in different formats (English/Chinese, Wiki/Q&A), how much transfer occurs? We provide evidence that LLMs can struggle with this sort of transfer, with consequences like sample inefficiency and capacity competition.
3
3
10
2,240
Nitay Calderon retweeted

May 20
🚨 New preprint alert! 🎨
How do image editing models handle "make it look like a rainy day" vs. "add an umbrella"? While visual models excel at explicit commands, interpreting abstract instructions remains a major bottleneck.🧵👇 [1/10]
1
15
27
1,337
May 15
My advisor always says time is our most valuable resource,
I tell students I teach/work with that I dont plan to spend more time reading something than the author spent writing it.
I support arXiv's decision.
Asking authors to polish AI-generated content is a *VERY* low bar.

Attention @arxiv authors: Our Code of Conduct states that by signing your name as an author of a paper, each author takes full responsibility for all its contents, irrespective of how the contents were generated. 1/
5
4
107
5,221


Nitay Calderon retweeted

1/7
How are cells spatially reorganized between conditions in tissues?
Introducing CASEI: a method for inferring condition-associated spatial phenotypes in spatial omics data.
w/ Roy Friedman (friedmanroy.github.io/) & @mor_nitzan
biorxiv.org/content/10.64898…

1
7
33
3,069
May 8
If you care about knowledge in LLMs, and why parametric knowledge remains a fundamentally important research problem, you should read Gal’s tweet 🤯

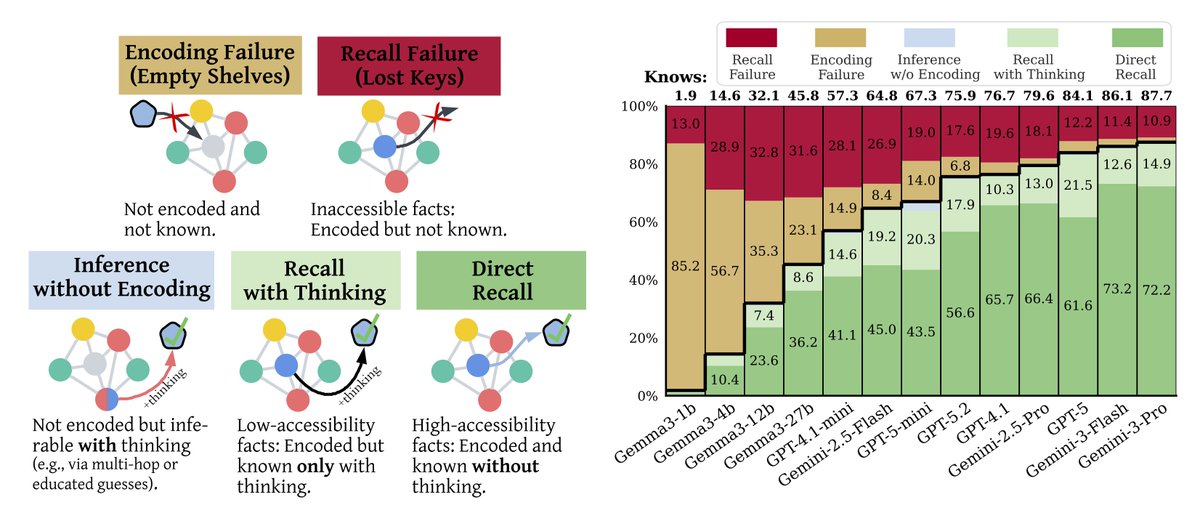
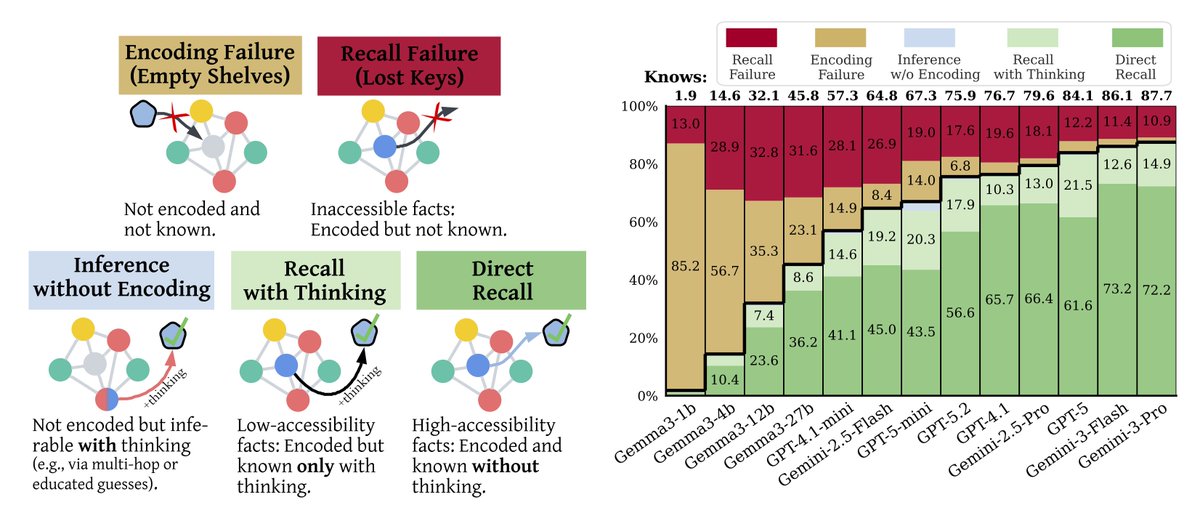
.@NitCal will be presenting "Empty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality" at ICML 2026 next month.
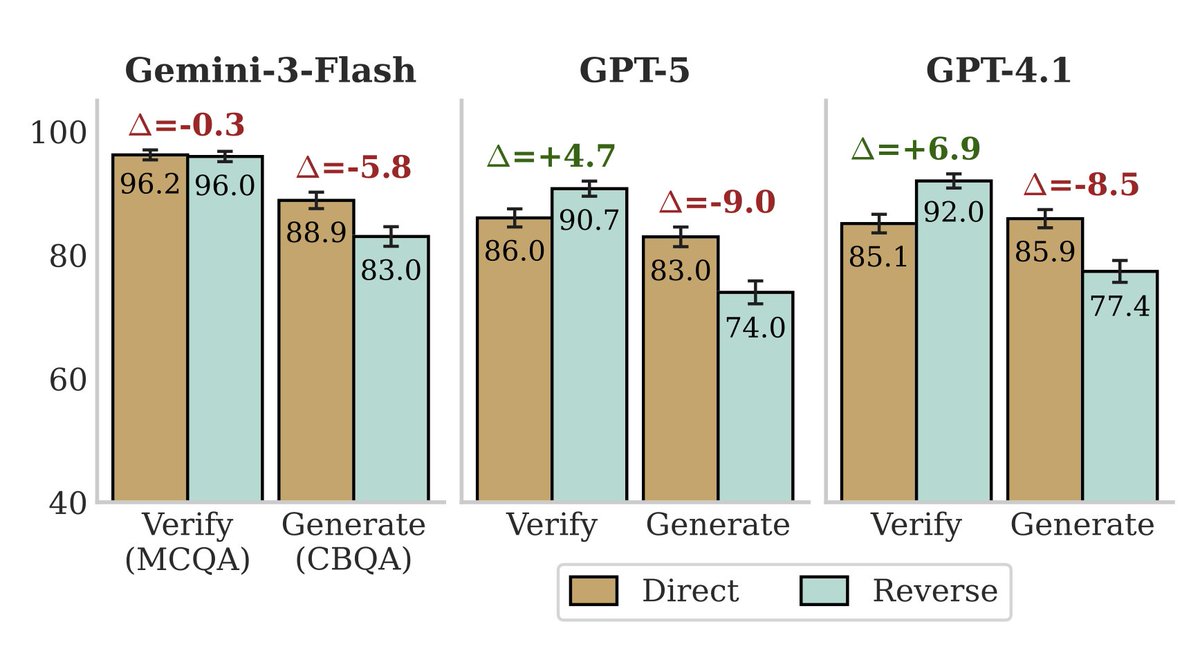
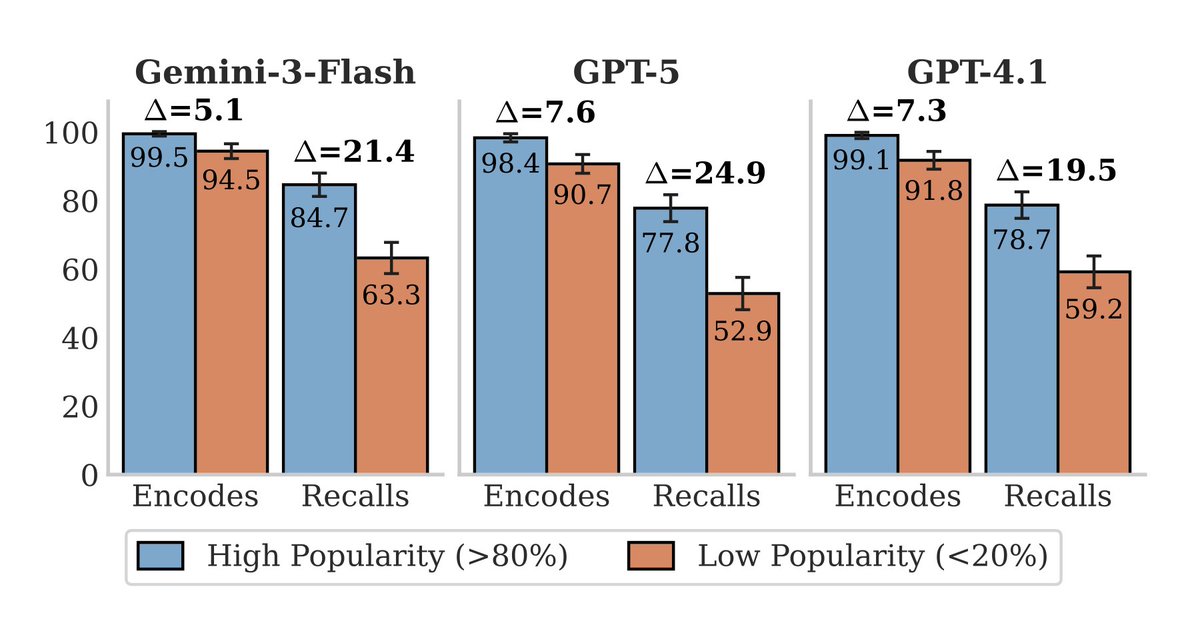
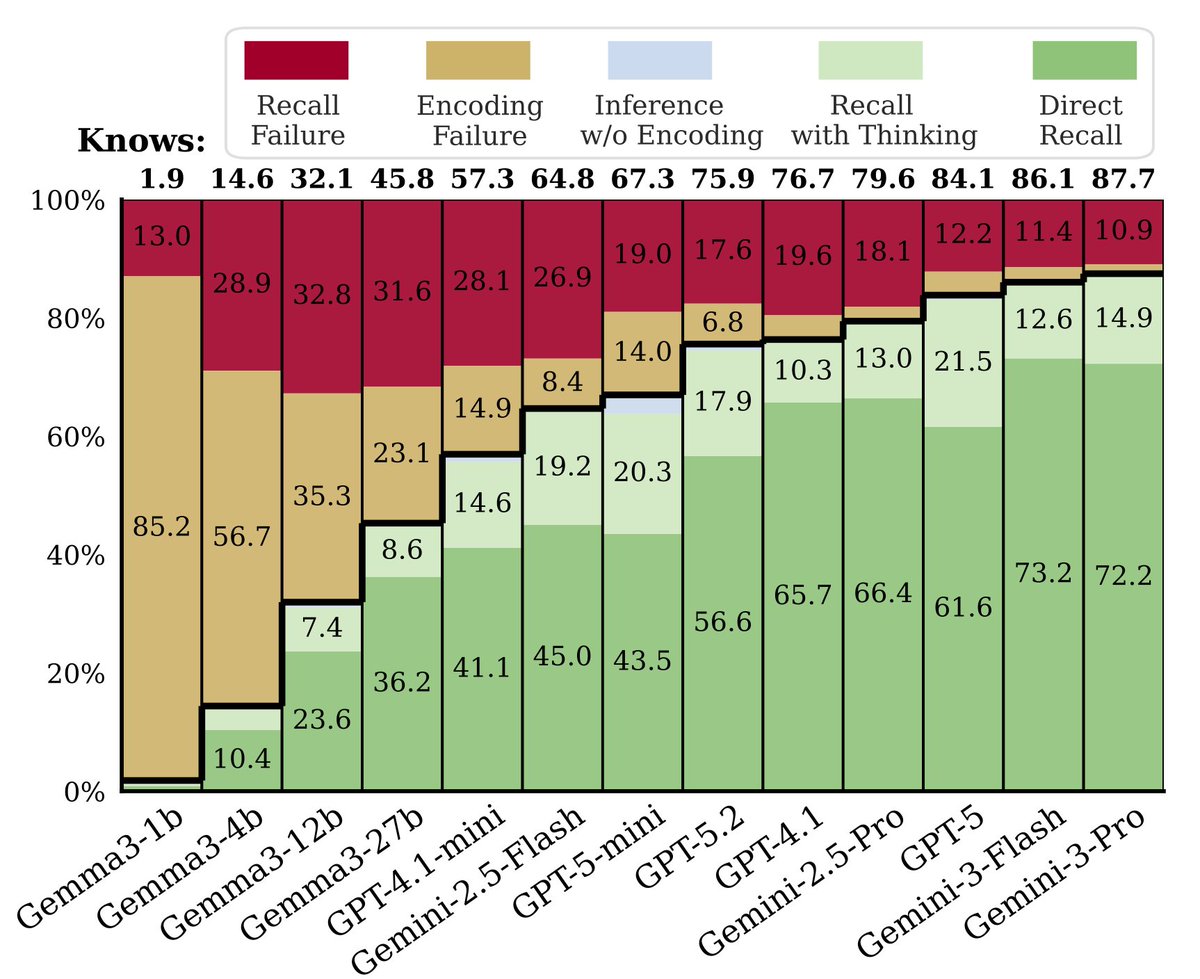
(tl;dr: we show encoding is near-saturated on frontier LLMs, but models still struggle to recall encoded facts.)
One recurring piece of feedback we've gotten since posting the paper: "you show LLMs struggle with factual recall, but does that even matter when today's agents can use external retrieval?"
Here's how I currently think about this, and more broadly about the role of parametric knowledge in today's systems:
The theoretical argument for why knowledge matters (true in principle, but I don't know of work that measures this in practice): parametric knowledge is important for making efficient use of search and for knowing how to properly integrate retrieved information. Imagine finding some weird pizza recipe online — can you trust it without knowing a lot about cooking, chemistry, etc.? I think this is going to become a bigger issue moving forward, the more "sloppier" the internet becomes.
The realistic case for why knowledge matters: today's agents are far from producing responses that are fully grounded in external evidence. Even when search triggers properly — which it often doesn't — only the "big" claims tend to be grounded, while models still volunteer a lot of extra information from their parametric knowledge.
Since models are still poor at "knowing what they know" (more on that in my next post, about our other ICML paper...), our best bet is making models actually more knowledgeable — and our paper reveals where the headroom for that actually lies.
1
22
2,562
.@NitCal will be presenting "Empty Shelves or Lost Keys? Recall Is the Bottleneck for Parametric Factuality" at ICML 2026 next month.
(tl;dr: we show encoding is near-saturated on frontier LLMs, but models still struggle to recall encoded facts.)
One recurring piece of feedback we've gotten since posting the paper: "you show LLMs struggle with factual recall, but does that even matter when today's agents can use external retrieval?"
Here's how I currently think about this, and more broadly about the role of parametric knowledge in today's systems:
The theoretical argument for why knowledge matters (true in principle, but I don't know of work that measures this in practice): parametric knowledge is important for making efficient use of search and for knowing how to properly integrate retrieved information. Imagine finding some weird pizza recipe online — can you trust it without knowing a lot about cooking, chemistry, etc.? I think this is going to become a bigger issue moving forward, the more "sloppier" the internet becomes.
The realistic case for why knowledge matters: today's agents are far from producing responses that are fully grounded in external evidence. Even when search triggers properly — which it often doesn't — only the "big" claims tend to be grounded, while models still volunteer a lot of extra information from their parametric knowledge.
Since models are still poor at "knowing what they know" (more on that in my next post, about our other ICML paper...), our best bet is making models actually more knowledgeable — and our paper reveals where the headroom for that actually lies.
2
5
31
3,571
May 4
Our paper got accepted to @icmlconf! 🥳🥳
I also want to say a few warm words about the reviewers and AC. Maybe because our paper was under Policy A (LLM use is prohibited), but the review process felt unusually professional and refreshing, almost like a reminder of pre-2024 peer review 😇
I hope more authors get to experience this kind of review process in the future.
Feb 24

[1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: arxiv.org/abs/2602.14080
Many thanks to @_galyo @bd_eyal @zorikgekhman @eran_ofek59358 @GoogleResearch
1
3
55
6,236
Nitay Calderon retweeted

Apr 28
Proud of being part of Google Translate (even if it was for a few months as an intern, almost a decade ago!). One of the most fun and rewarding professional experiences of my life, in a truly revolutionary team. PS not many know but lots of the groundwork to LLMs happened there!
Apr 28

Hello. How are you? Thank you. I love you. Please.
Some of the most frequently translated phrases of the past 20 years!
Google Translate began twenty years ago with a mission to help people understand one another, regardless of the language they speak. What started as a small experiment has become a global tool that helps over 1 billion users every month.
In that time Translate has evolved from simple pattern matching to true understanding. In 2006, it relied on statistical machine learning to look for patterns in small word clusters. By 2016, we pioneered a shift to neural networks to move beyond literal word-for-word translations, and today we’re using our powerful Gemini models to make Translate even more helpful.
We are moving from text to fluid, real-time conversations. With our latest models, you can even use your headphones as a personal interpreter that preserves your original tone and cadence - it’s an amazing experience!
One of the interesting things about AI is that as we make progress, we begin to take it for granted. If you met a person who could translate across a hundred languages faster than any human can, you would be so impressed. Today, one product does that for nearly 250 languages, and we kind of just shrug.
Being able to say thank you in 250 languages is not something I take for granted. So to the 1 billion who use Google Translate - merci, dhanyavaad, arigatō, gracias, and thank you! Let’s see what the next 20 years will bring.
1
16
923
Nitay Calderon retweeted

Apr 28
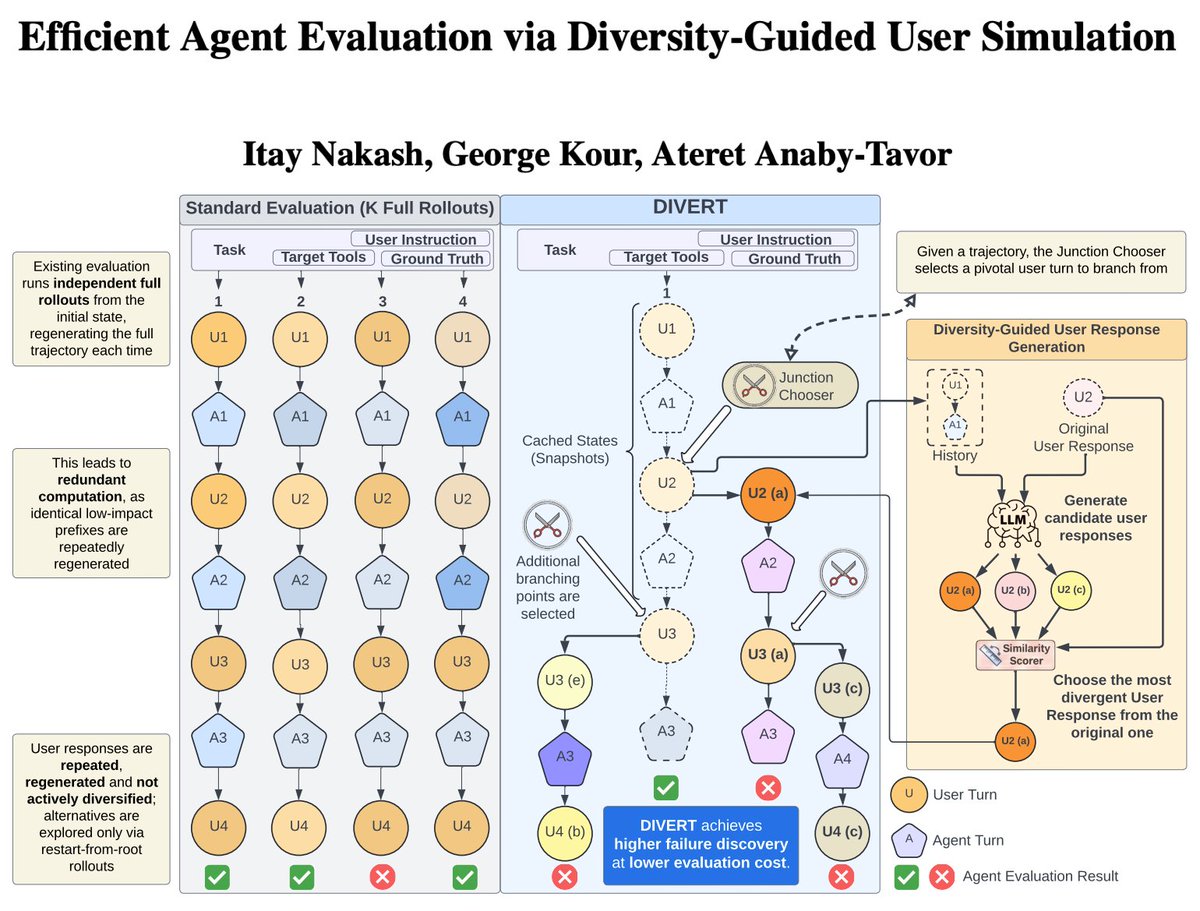
🚨New Paper (ACL-26)
'Efficient Agent Evaluation via Diversity-Guided User Simulation'
We tackle a core pain in agent evaluation:
Current methods aim for coverage (pass@k) but mostly re-run the same conversations → low diversity, high cost.
We're excited to introduce DIVERT 🧵
2
8
21
563
Nitay Calderon retweeted

Mar 18
Do LLMs have motivation?
Motivation is a key lens for explaining human behavior.
As LLM behavior becomes more human-like, a natural question arises: could it help understand model behavior too?
With @AsaelSklar @GoldsteinYAriel @roireichart
📄 Paper: arxiv.org/pdf/2603.14347
1/5

3
16
49
2,916
Nitay Calderon retweeted

Protein repeat detection is hard: repeated segments are often mutated and only approximately similar. Yet PLMs can still detect them well. But How?
Check out our new preprint: "Induction Meets Biology: Mechanisms of Repeat Detection in Protein Language Models"

1
16
48
8,707
Nitay Calderon retweeted

Mar 11
New paper 🚨
We know that reasoning helps when step-by-step solutions are natural, for example in math, code, and multi-hop factual QA. But why should it help with factual recall, where no complex reasoning steps are needed?
1/🧵

3
16
91
14,270
this is really really neat, but it is literally the EXACT OPPOSITE of vibemathing
Don Knuth (at 88, worth adding!) carefully went through all 30 of Claude's attempts, and then actually wrote down a proof for the one that seemed to empirically work

Donald Knuth is vibemathing now. real tough day for the stochastic-parrot crew.

29
123
1,696
115,225
Nitay Calderon retweeted
Feb 24
New work from our group on understanding factual errors in LLMs, led by @NitCal ! Models encode more knowledge than they can recall when prompted. We need to close this gap!
Feb 24
[1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: arxiv.org/abs/2602.14080
Many thanks to @_galyo @bd_eyal @zorikgekhman @eran_ofek59358 @GoogleResearch
2
5
405
Feb 20

Google presents Empty Shelves or Lost Keys?
Recall Is the Bottleneck for Parametric Factuality
paper: huggingface.co/papers/2602.1…

1
4
12
1,017
Feb 24
Feb 24
[1/7] Why do frontier LLMs make factual errors?
Is it because they never learned the fact…
or because they can’t access knowledge they already encoded?
In our new paper, we show:
The bottleneck is not encoding; it is recall. 🧵👇
Paper: arxiv.org/abs/2602.14080
Many thanks to @_galyo @bd_eyal @zorikgekhman @eran_ofek59358 @GoogleResearch
55