
Causality is the final human edge over AI
Joined September 2024
- Tweets 2,254
- Following 592
- Followers 135
- Likes 4,441
59 Photos and videos

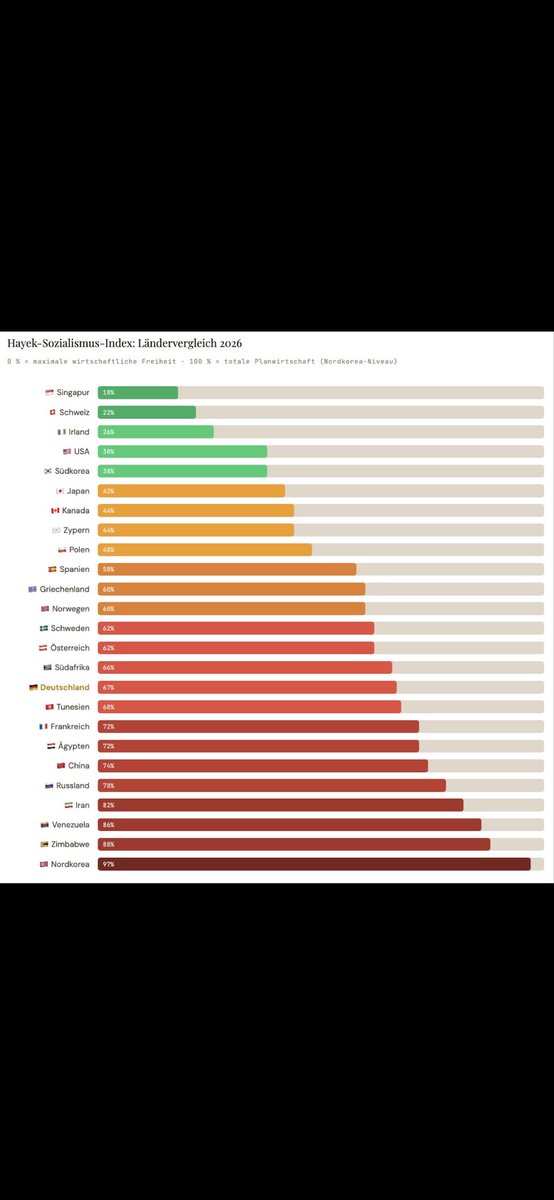





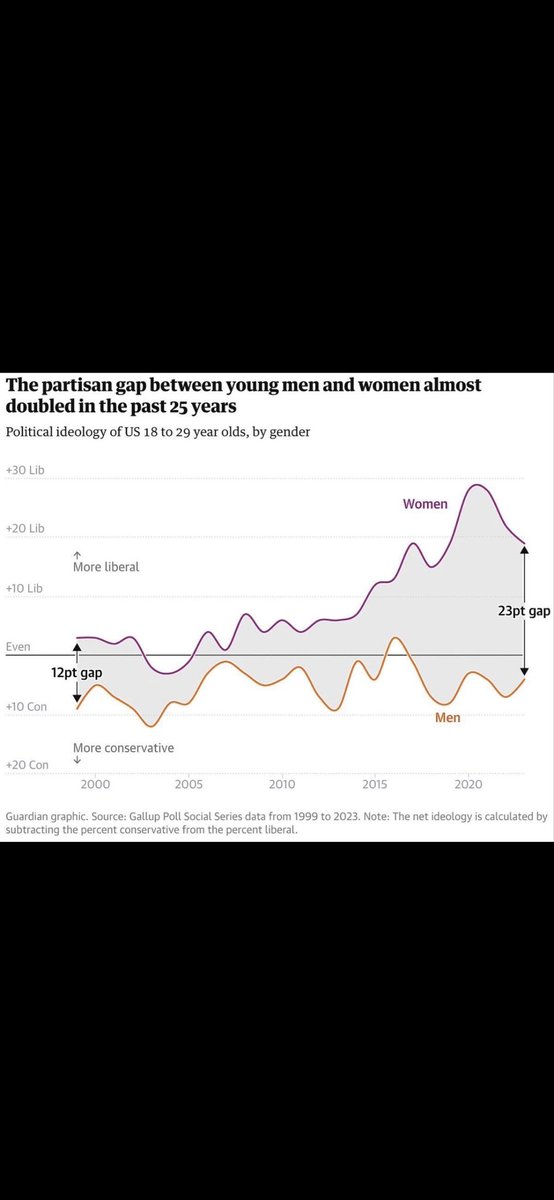
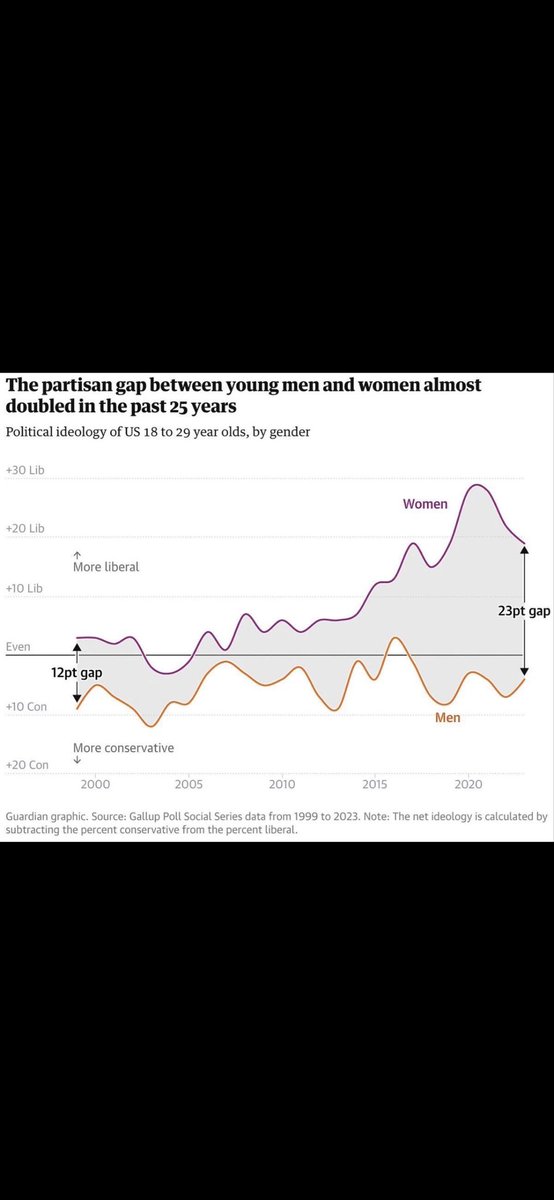
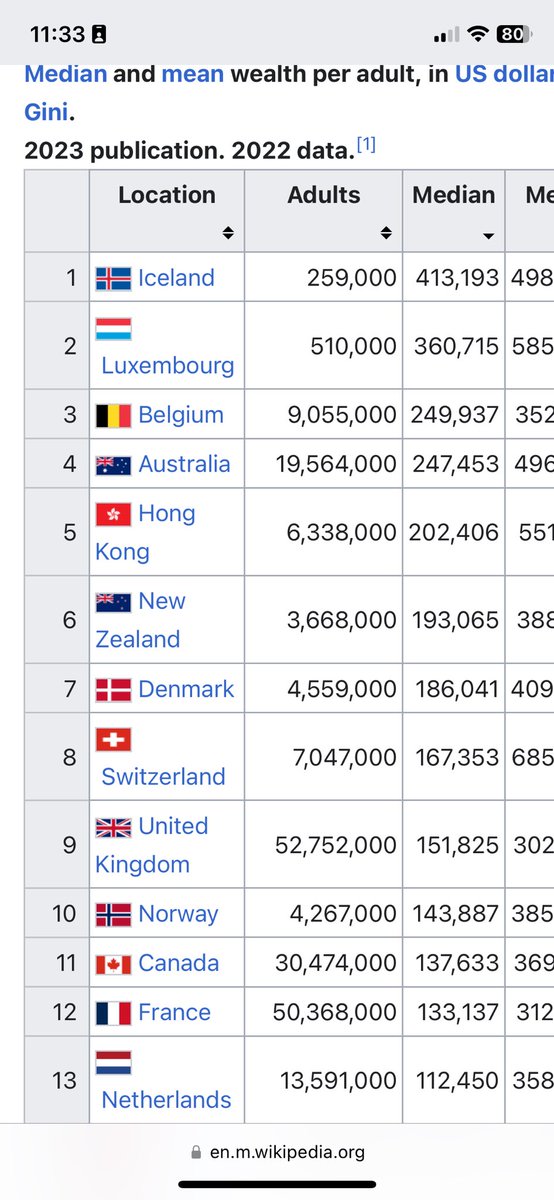

May 17
Insanely good mini lecture on the inner workings of alpha go, one of the greatest AI successes. It actually grounds you in the true difficulty of the AGI mission (intractable search problems) and makes you realize how overhyped current agentic LLM systems truly are.
May 15

New blackboard lecture w @ericjang11
He walks through how to build AlphaGo from scratch, but with modern AI tools.
Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn.
Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second.
Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside.
Timestamps:
0:00:00 – Basics of Go
0:08:06 – Monte Carlo Tree Search
0:31:53 – What the neural network does
1:00:22 – Self-play
1:25:27 – Alternative RL approaches
1:45:36 – Why doesn’t MCTS work for LLMs
2:00:58 – Off-policy training
2:11:51 – RL is even more information inefficient than you thought
2:22:05 – Automated AI researchers
172
Otto Gradkowski retweeted

Apr 27
Who invented JEPA? Part II. Dr. LeCun responded, and I put my replies in Addendum 1 of the report people.idsia.ch/~juergen/who… ... The conclusion still stands: the 2022 JEPA family is actually the 1992 PMAX family.
Excerpts:
On 6 April 2026, Dr. LeCun replied at LinkedIn (see screenshots 1, 2, 3): "what we now called Joint Embedding Architectures, which include things like Siamese nets and JEPA was introduced decades ago. No one is claiming it's new. You didn't invent it either. A good example of early work is the Becker & Hinton 1989 technique for maximizing mutual information. It worked, but made strong hypotheses about the distribution and probably didn´t scale (I was a postdoc in Toronto when they were thinking about this). This paper is the inspiration for your PMAX paper. Lot's of people have used mutual information maximization to train neural nets. The concept goes back to Horace Barlow. The question is *precisely* how to measure mutual information and how to maximize it. It's difficult because we don't have any lower bound measure on information content. We only have upper bounds..... My own NIPS 1993 paper on Siamese nets use a contrastive criterion. This was later revived by Raia Hadsell, Sumit Chopra and me in CVPR 2005 and 2006 papers (Dr LIM). It was re--revived by the SimCLR work (for which Geoff Hinton is a co-author) which showed surprisingly good experimental results on ImageNet. But then in 2021, we proposed a new non-contrastive infomax method called Barlow Twins (owing to Barlow's early advocacy of infomax). We later refined it into VICReg which gave SOTA results in a self-supervised scenario on ImageNet. We then augmented the joint embedding architecture with a predictor so it could be used as a world model (that was the plan all along. I had been talking about world models since 2015, including in my NIPS 2016 keynote). JEPA is merely a name for a general concept. The question is, and has always been, how do you make it work (particularly how do you prevent it from collapsing), and how do you make it work at scale with SOTA results on non-toy problems. That's the hard part. Ideas are a dime a dozen. Making them work is what the community will give you credit for."
My reply (see also screenshot 5): LeCun concedes that “JEA” was introduced decades ago [IMAX][LEC22a], but still attempts to frame “JEPA” as a novel contribution [LEC22a][LEC]. The broader scientific community knows better. As Michal Valko (lead of [BYOL]) explicitly detailed [VAL26][WHO12]: "the JEPA lines are instantiations of [PMAX]” ... "Barlow Twins: ... literally Sec 2.3 of [PMAX]" ... “VICReg: ... is one section from [PMAX]." Scaling these 1992 blueprints to modern compute is cool, but the architectural foundation remains PMAX.
Valko further pointed out (personal communication, 2026): it was actually [BYOL] that first made the [PMAX] skeleton work at scale on ImageNet, in the hardest possible regime where ε=1 (eq. (2) of [PMAX]), that is, without an explicit Dl term to prevent collapse. BYOL’s collapse-prevention toolkit (EMA stop-grad predictor asymmetry) was introduced to survive without Dl and is exactly what I-JEPA and V-JEPA later adopted to address LeCun's question: how do you prevent collapse and make it work at scale? Punchline: In 2025, LeCun's [LeJEPA] dropped EMA and stop-gradient entirely and went back to an explicit anti-collapse regularizer (SIGReg). That's a full circle return to the original 1992 [PMAX] philosophy of explicit Dl terms. So even within the JEPA lineage, the trajectory went: [PMAX]’s explicit Dl (1992) → [BYOL]'s implicit architectural tricks (2020) → LeCun’s JEPAs using BYOL tricks (2023-2024) → back to explicit Dl in [LeJEPA] (2025). The field spent five years exploring the ε=1 regime opened up by BYOL, then came home to [PMAX]'s original ε<1 design. It's not just that JEPA is [PMAX], it's that even the detour away from explicit Dl eventually led back to [PMAX]'s origins.
Other comments. On Facebook, LeCun claimed (see screenshot 4) that the experimental section in our [PMAX] paper "is essentially non-existent." However, our 1992 [PMAX] paper had many experiments, while LeCun's JEPA paper [LEC22a] had none - despite compute being a million times cheaper in 2022.
LeCun refers to his "1993 paper on Siamese nets" which cited neither Becker & Hinton's "JEA" [IMAX] nor the 1992 [PMAX]/JEPA which solved a stereo task more readily than JEA and prevented "collapse."
LeCun keeps mentioning his "NIPS 2016 keynote" on "world models." It came after my learning prompt engineer for world models [PLAN4] and long after our earlier general purpose recurrent neural world models for partially observable environments since 1990 [GAN90][PLAN1-3][WM26] (key milestones in 1990, 91, 92, 97, 2000-2006, 2015).
Of course, my 1990 paper on recurrent neural nets as world models [GAN90] cited earlier works on less general, feedforward net-based systems (since 1987) for fully observable environments [WER87-89][MUN87][NGU89]. LeCun's much later 2022 paper on JEPA and world models [LEC22a] didn't. So I pointed him to these works in my 2022 critique [LEC], but he did not correct his paper [LEC22a].
Years later, on 18 April 2026, LeCun finally mentioned at least [NGU89] (but not [WER87-89][MUN87]) on LinkedIn (see screenshot 6), then boldly claimed that [GAN90] "was never accepted through peer review." Of course, this is not true: [GAN90]'s planning part was published at IJCNN'90 [PLAN2], and the part on artificial curiosity through generative & adversarial nets was published at SAB'91 [GAN91][GAN20][WHO8].
LeCun spread additional falsehoods on social media: on 18 April 2026, he accused me of claiming that I "invented world models" (see screenshot 7) although I have always cited pre-1990 feedforward nets of this kind [WER87-89][MUN87][NGU89] which weren't called "world models" [GAN90] by their authors [WHO12]. In the 1980s, Werbos connected this work to earlier work on system identification in control theory, e.g., [WER87-89]. I even credited the ancient Greeks for the basic concept at a conference that LeCun attended [WM26b][WM26] (see video tweet).
LeCun's additional misleading statements about JEPA were discussed above [WHO12]. The conclusion still stands: the 2022 JEPA family is actually the 1992 PMAX family.
All references in:
[WHO12] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026 (updated in April).

Mar 31

Dr. LeCun's heavily promoted Joint Embedding Predictive Architecture (JEPA, 2022) [5] is the heart of his new company. However, the core ideas are not original to LeCun. Instead, JEPA is essentially identical to our 1992 Predictability Maximization system (PMAX) [1][14].
Details in reference [19] which contains many additional references.
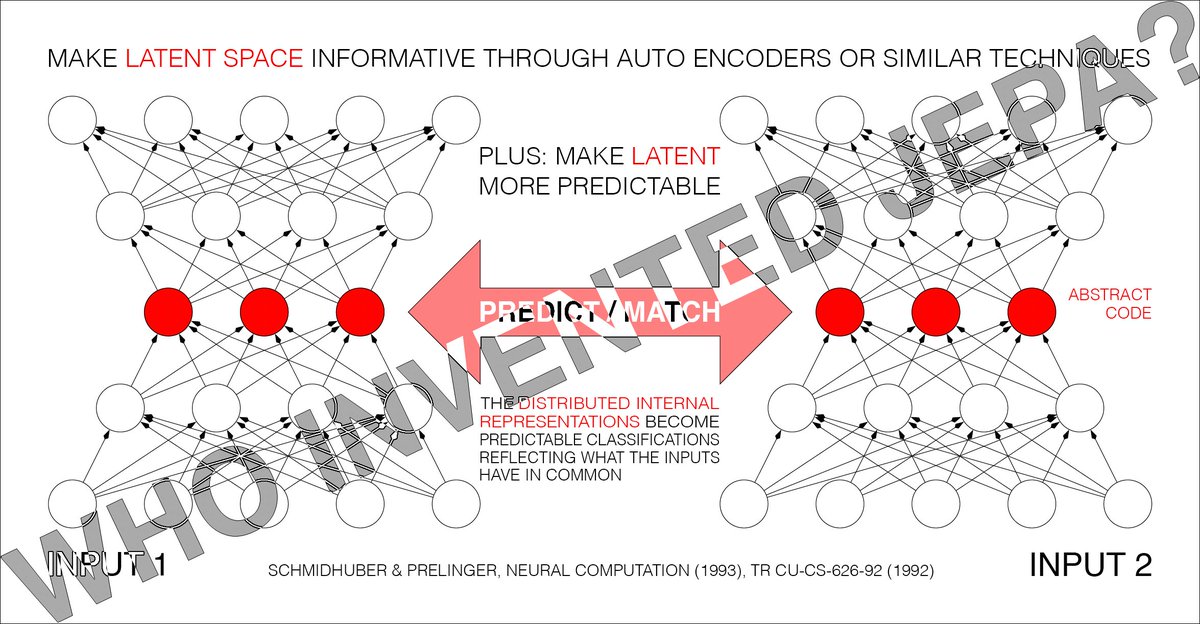
Motivation of PMAX [1][14]. Since details of inputs are often unpredictable from related inputs, two non-generative artificial neural networks interact as follows: one net tries to create a non-trivial, informative, latent representation of its own input that is predictable from the latent representation of the other net’s input.
PMAX [1][14] is actually a whole family of methods. Consider the simplest instance in Sec. 2.2 of [1]: an auto encoder net sees an input and represents it in its hidden units (its latent space). The other net sees a different but related input and learns to predict (from its own latent space) the auto encoder's latent representation, which in turn tries to become more predictable, without giving up too much information about its own input, to prevent what's now called “collapse." See illustration 5.2 in Sec. 5.5 of [14] on the "extraction of predictable concepts."
The 1992 PMAX paper [1] discusses not only auto encoders but also other techniques for encoding data. The experiments were conducted by my student Daniel Prelinger. The non-generative PMAX outperformed the generative IMAX [2] on a stereo vision task.
The 2020 BYOL [10] is also closely related to PMAX. In 2026, @misovalko, leader of the BYOL team, praised PMAX, and listed numerous similarities to much later work [19].
Note that the self-created “predictable classifications” in the title of [1] (and the so-called “outputs” of the entire system [1]) are typically INTERNAL "distributed representations” (like in the title of Sec. 4.2 of [1]).
The 1992 PMAX paper [1] considers both symmetric and asymmetric nets. In the symmetric case, both nets are constrained to emit "equal (and therefore mutually predictable)" representations [1]. Sec. 4.2 on “finding predictable distributed representations” has an experiment with 2 weight-sharing auto encoders which learn to represent in their latent space what their inputs have in common (see the cover image of this post).
Of course, back then compute was was a million times more expensive, but the fundamental insights of "JEPA" were present, and LeCun has simply repackaged old ideas without citing them [5,6,19].
This is hardly the first time LeCun (or others writing about him) have exaggerated LeCun's own significance by downplaying earlier work. He did NOT "co-invent deep learning" (as some know-nothing "AI influencers" have claimed) [11,13], and he did NOT invent convolutional neural nets (CNNs) [12,6,13], NOR was he even the first to combine CNNs with backpropagation [12,13]. While he got awards for the inventions of other researchers whom he did not cite [6], he did not invent ANY of the key algorithms that underpin modern AI [5,6,19].
LeCun's recent pitch: 1. LLMs such as ChatGPT are insufficient for AGI (which has been obvious to experts in AI & decision making, and is something he once derided @GaryMarcus for pointing out [17]). 2. Neural AIs need what I baptized a neural "world model" in 1990 [8][15] (earlier, less general neural nets of this kind, such as those by Paul Werbos (1987) and others [8], weren't called "world models," although the basic concept itself is ancient [8]). 3. The world model should learn to predict (in non-generative "JEPA" fashion [5]) higher-level predictable abstractions instead of raw pixels: that's the essence of our 1992 PMAX [1][14].
Astonishingly, PMAX or "JEPA" seems to be the unique selling proposition of LeCun's 2026 company on world model-based AI in the physical world, which is apparently based on what we published over 3 decades ago [1,5,6,7,8,13,14], and modeled after our 2014 company on world model-based AGI in the physical world [8].
In short, little if anything in JEPA is new [19]. But then the fact that LeCun would repackage old ideas and present them as his own clearly isn't new either [5,6,18,19].
FOOTNOTES
1. Note that PMAX is NOT the 1991 adversarial Predictability MINimization (PMIN) [3,4]. However, PMAX may use PMIN as a submodule to create informative latent representations [1](Sec. 2.4), and to prevent what's now called “collapse." See the illustration on page 9 of [1].
2. Note that the 1991 PMIN [3] also predicts parts of latent space from other parts. However, PMIN's goal is to REMOVE mutual predictability, to obtain maximally disentangled latent representations called factorial codes. PMIN by itself may use the auto encoder principle in addition to its latent space predictor [3].
3. Neither PMAX nor PMIN was my first non-generative method for predicting latent space, which was published in 1991 in the context of neural net distillation [9]. See also [5-8].
4. While the cognoscenti agree that LLMs are insufficient for AGI, JEPA is so, too. We should know: we have had it for over 3 decades under the name PMAX! Additional techniques are required to achieve AGI, e.g., meta learning, artificial curiosity and creativity, efficient planning with world models, and others [16].
REFERENCES (easy to find on the web):
[1] J. Schmidhuber (JS) & D. Prelinger (1993). Discovering predictable classifications. Neural Computation, 5(4):625-635. Based on TR CU-CS-626-92 (1992): people.idsia.ch/~juergen/pre…
[2] S. Becker, G. E. Hinton (1989). Spatial coherence as an internal teacher for a neural network. TR CRG-TR-89-7, Dept. of CS, U. Toronto.
[3] JS (1992). Learning factorial codes by predictability minimization. Neural Computation, 4(6):863-879. Based on TR CU-CS-565-91, 1991.
[4] JS, M. Eldracher, B. Foltin (1996). Semilinear predictability minimization produces well-known feature detectors. Neural Computation, 8(4):773-786.
[5] JS (2022-23). LeCun's 2022 paper on autonomous machine intelligence rehashes but does not cite essential work of 1990-2015.
[6] JS (2023-25). How 3 Turing awardees republished key methods and ideas whose creators they failed to credit. Technical Report IDSIA-23-23.
[7] JS (2026). Simple but powerful ways of using world models and their latent space. Opening keynote for the World Modeling Workshop, 4-6 Feb, 2026, Mila - Quebec AI Institute.
[8] JS (2026). The Neural World Model Boom. Technical Note IDSIA-2-26.
[9] JS (1991). Neural sequence chunkers. TR FKI-148-91, TUM, April 1991. (See also Technical Note IDSIA-12-25: who invented knowledge distillation with artificial neural networks?)
[10] J. Grill et al (2020). Bootstrap your own latent: A "new" approach to self-supervised Learning. arXiv:2006.07733
[11] JS (2025). Who invented deep learning? Technical Note IDSIA-16-25.
[12] JS (2025). Who invented convolutional neural networks? Technical Note IDSIA-17-25.
[13] JS (2022-25). Annotated History of Modern AI and Deep Learning. Technical Report IDSIA-22-22, arXiv:2212.11279
[14] JS (1993). Network architectures, objective functions, and chain rule. Habilitation Thesis, TUM. See Sec. 5.5 on "Vorhersagbarkeitsmaximierung" (Predictability Maximization).
[15] JS (1990). Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environments. Technical Report FKI-126-90, TUM.
[16] JS (1990-2026). AI Blog.
[17] @GaryMarcus. Open letter responding to @ylecun. A memo for future intellectual historians. Substack, June 2024.
[18] G. Marcus. The False Glorification of @ylecun. Don’t believe everything you read. Substack, Nov 2025.
[19] J. Schmidhuber. Who invented JEPA? Technical Note IDSIA-3-22, IDSIA, Switzerland, March 2026. people.idsia.ch/~juergen/who…
22
43
377
103,697

Fluid intelligence is pretty damn important though, if not the most important component of your output per unit time. It’s like saying the amount of memory or CPU cores a computer has doesn’t matter and it’s all about the storage.
2
1
622
it’s insane that we even have to explain the difference between aggregate statistics and realizations of samples to a “rationalist”. There is no misconception on the extreme values. Nobody thinks the highest IQ person will be the best at everything. This seems like a deflection
1
427
And I don’t think there is a misconception about a scaling quantity. Also, if you claimed to have done research on this as the length of your post suggests, how in the world did you not come across the predictive power of IQ in career and life outcomes? Very silly.
2
269
7 Mar 2025
Congratulations to the pioneers of Reinforcement learning, or computer systems which learn from experience in a dopaminergic way. In the same light as David Deutsch, Sutton reminds us that scientific truth does not come from authorities!!
5 Mar 2025

“There are no authorities in science,” says Turing Award winner @RichardSSutton, Amii Fellow & Canada @CIFAR_News AI Chair. Sit down with Rich and @camlinke as they discuss the journey to this moment. Watch now: hubs.la/Q039xBP-0
#TuringAward #AI #ReinforcementLearning
1
429
3 Feb 2025
Glad I’m not the only one vibe coding 😂
2 Feb 2025

There's a new kind of coding I call "vibe coding", where you fully give in to the vibes, embrace exponentials, and forget that the code even exists. It's possible because the LLMs (e.g. Cursor Composer w Sonnet) are getting too good. Also I just talk to Composer with SuperWhisper so I barely even touch the keyboard. I ask for the dumbest things like "decrease the padding on the sidebar by half" because I'm too lazy to find it. I "Accept All" always, I don't read the diffs anymore. When I get error messages I just copy paste them in with no comment, usually that fixes it. The code grows beyond my usual comprehension, I'd have to really read through it for a while. Sometimes the LLMs can't fix a bug so I just work around it or ask for random changes until it goes away. It's not too bad for throwaway weekend projects, but still quite amusing. I'm building a project or webapp, but it's not really coding - I just see stuff, say stuff, run stuff, and copy paste stuff, and it mostly works.
1
206
2 Feb 2025
Excellent article, which most likely triggered the mass selling of NVDA. A rare combination of financial and technological expertise, Jeff gives clarity to the previous week’s world of NVDA GPU hype and overvaluation. Totally worth the read!
25 Jan 2025

You can read it here— let me know what you think:
youtubetranscriptoptimizer.c…
1
3
558
19 Dec 2024
An excellent low hanging fruit for AI is live translation of broadcasts and TV. There is so much we don’t know about the international community simply because we cannot understand what they are saying, such as with Viktor Orban right now during the European Councils speeches
1
119
Otto Gradkowski retweeted

4 Dec 2024
💥💥 EU Inc goes to Brussels!
We sent the petition with your 13k signatures to the EU Commission.
We managed to make this an urgent matter in Brussels. Now we need to make sure the implementation is right.
WE NEED YOUR HELP! Contribute to the open-sourced proposal below ⬇️
4
47
218
26,602
Otto Gradkowski retweeted

1 Dec 2024
19 powerful sentences by Friedrich Nietzsche that will change how you view the world:

6
103
743
112,286
1 Dec 2024
“The great source of both the misery and disorders of human life, seems to arise from over-rating the difference between one permanent situation and another. Avarice over-rates the difference between poverty and riches: ambition, that between a private and a public station: vain-glory, that between obscurity and extensive reputation. The person under the influence of any of those extravagant passions, is not only miserable in his actual situation, but is often disposed to disturb the peace of society, in order to arrive at that which he so foolishly admires. The slightest observation, however, might satisfy him, that, in all the ordinary situations of human life, a well-disposed mind may be equally calm, equally cheerful, and equally contented. Some of those situations may, no doubt, deserve to be preferred to others: but none of them can deserve to be pursued with that passionate ardour which drives us to violate the rules either of prudence or of justice; or to corrupt the future tranquillity of our minds, either by shame from the remembrance of our own folly, or by remorse from the horror of our own injustice.”
~Adam Smith, Theory of Moral Sentiments
1
67
30 Nov 2024
Let’s get the EU economic engine started!!
29 Nov 2024

"How hard would it be to get the European Startup ecosystem to adopt a standard legal entity?"
I almost had a stroke when she asked me that
People do realize that pretty much everyone serious outside of Fr/De/Nordics is using Delaware Incs in EU?
Because a proper standard is so desperately needed.
1
101
29 Nov 2024
This is a real possibility, but unlikely. Corporations might just push their workers to the next level of productivity.
28 Nov 2024

If AI could reduce your work week to 3.5 days, would you accept? As a society, we can live longer and redefine what it means to have a work-life balance. JP Morgan’s CEO Jamie Dimon believes this future is possible.
90

Happiness (if you want it):*
1. Meet basic needs
2. Avoid cheap dopamine
3. Leave the past alone
4. Limit desires to ones achievable at the edge of your capability
5. Find something beyond yourself (mission, children, God)
*Most people want something else.
584
3,569
25,254
1,262,363

26 Nov 2024
The legendary Deutsch speaks!
25 Nov 2024

Science is about problem solving, so is life. And with problems, what we want to do is eliminate errors. If we can eliminate some errors, it doesn't matter how true the theory is.
@DavidDeutschOxf
48
25 Nov 2024
“How selfish soever man may be supposed, there are evidently some principles in his nature, which interest him in the fortune of others, and render their happiness necessary to him, though he derives nothing from it, except the pleasure of seeing it.”
~Adam Smith, Theory of Moral Sentiments
74
23 Nov 2024
Yup
25 Feb 2018

Cartoon capitalism: A fat man, smoking a cigar, hoarding wealth while workers sweat.
Real world capitalism: An entrepreneur, working crazy hours, risking her own money, to provide goods or services others want, while investing profits back into her business.
1
56

