
Joined January 2022
- Tweets 562
- Following 234
- Followers 16,580
- Likes 879
96 Photos and videos















Jun 6
Our portfolio company @playaneemate pushing gameplay forward 🧬
AneeMate’s new transformation feature lets players become their AneeMate and control its unique powers.
More immersive. More playable. More alive.
Congrats to the team 👏
Jun 1

Wanderers, the AneeMate demo is closer than you think!
We're excited to reveal one of the biggest new core features coming to the demo. You'll be able to transform into your AneeMate and take direct control of its unique powers and abilities!
We believe this feature will add fast-paced action and make the overall gameplay more dynamic, engaging, and enjoyable.
Make sure to add AneeMate to your wishlist: store.epicgames.com/en-US/p/…
8
8
37
1,804
Jun 6
Real-world IoT is getting easier to visualize, monitor, and act on.
Excited to see our portfolio company @ChirpDeWi launch #DigitalTwin across residential and commercial platforms. Connecting real sensors to 3D objects so digital environments update the moment physical status changes.
Pay close attention to @tim_krav_ and the Chirp team @ChirpDeWi👏
May 28

Yesterday, we released #DigitalTwin on our residential and commercial platforms, and I’m honestly excited about this one.
In the video, I’m connecting real sensors to 3D objects and showing how the digital version reacts the moment the sensor’s status changes.
This is what makes IoT click: real devices sending live data, and the platform turning that data into something you can actually see and interact with.
I hope you guys like it.
Try it here: app.chirpwireless.io
No credit card required.
Take a look at it in action.
#IoT #DigitalTwin #Kilo #Automation #Sensors #depin @SuiNetwork
7
11
39
2,078
Jun 6
Great milestone from our portfolio company @piggycell ⚡
4M users and 150K power banks deployed across Korea.
Piggycell is showing how real-world infrastructure can scale, serve everyday needs, and bring more utility to the world.
Keep building team!
x.com/piggycell/status/20591…
May 26

Running low on battery? Piggycell is here to save the day!⚡
We have over 150,000 power banks deployed all across Korea.
Download the app and never worry about a dead phone again! 📲✨
APP STORE: apps.apple.com/kr/app/�…
GOOGLE PLAY:
play.google.com/store/apps/d…
#충전돼지 #piggycell #Web3

7
8
40
2,192
May 1
AI agents can now access, verify, and pay for journalism - with no human involved.
China Times, one of Taiwan's oldest media organizations, ran its archive through @numbersprotocol's x402 infrastructure. Every article is signed with C2PA credentials and licensed for programmatic access on Numbers Mainnet.
The publisher sets the terms once. The infrastructure enforces them at scale.
As investors in Numbers Protocol, we see this as a turning point for AI data networks and how content ownership gets enforced in an agent-driven world. 🔐
Learn more ⬇️
Apr 30

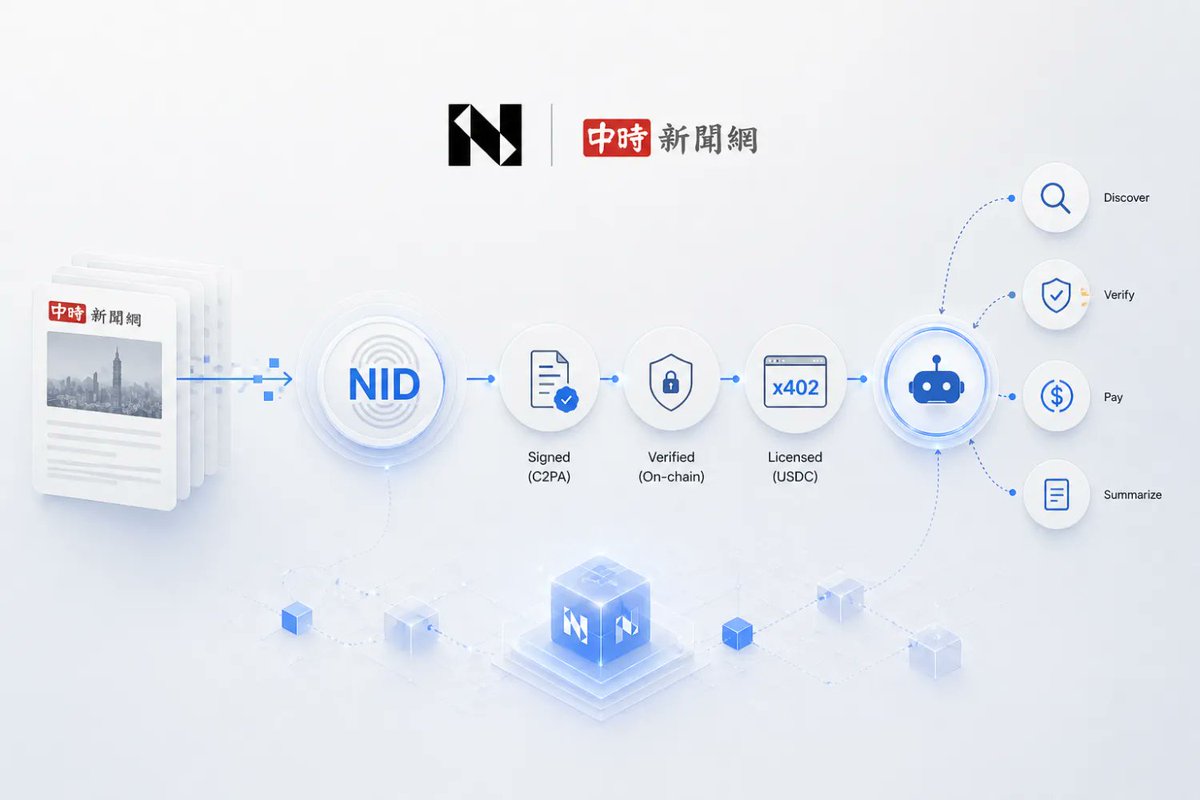
What does it take for a legacy newsroom to make its entire archive agent-readable?
China Times, one of Taiwan's oldest media organizations, is running its content through Numbers Protocol's x402 infrastructure. Every article in their archive carries a NID, is signed with C2PA credentials, and is licensed for programmatic access via USDC on Numbers Mainnet.
The result: autonomous AI agents discover China Times articles, verify their origin, pay for a license, and summarize them, all without contacting a single human at the newsroom. The publisher sets the terms once. The infrastructure enforces them at scale.
This is a shift in how publishers think about distribution. Instead of negotiating one-off deals with AI companies, China Times made its content available on open, verifiable rails. Any agent that meets the licensing terms can access it. The provenance record ensures the newsroom always gets attribution.
The blocking point that made this possible: x402 turns a paywall into a machine-readable licensing endpoint. No custom API. No partnership contract. Just infrastructure.
Browse the China Times x402 archive:
x402-chinatimes.numbersproto…
If your content were agent-readable tomorrow, what terms would you set?
3
7
23
1,703
Apr 12
12 months → 2 months.
That's what @QORPOworld achieved by building their own AI-driven production pipeline.
Gen-AI characters. Automated rigging. Custom Python scripts tying it all together.
A team of three now does what used to take a full team an entire year.
We're backing QORPO because this is exactly how gaming studios gain a durable edge. AI doesn't just speed up production - it changes who can build, and what they can build next. 🎮
More on the pipeline soon. ⬇️
Apr 9

It used to take about a year to build a game like this. Now we’re doing it in two months.
We’ve been working with our own AI-driven animation and production setup, Gen-AI characters, automated rigging, animation pipelines, and tools for gameplay mechanics. It’s not just one thing, it’s how everything connects.
We also built a bunch of custom Python scripts that tie it all together:
- character generation
- animation
- rigging
- gameplay systems
- overall production flow
The result? A team of three developers can now do what used to take a full team an entire year.
4
8
15
1,429
Apr 7
Guessing whether an image is AI-generated: 50%.
With on-chain provenance: 95%.
We back @numbersprotocol, and this result says it all.
Provenance is the gap between guessing and knowing. As AI identity and data integrity become critical infrastructure, that 45-point gap is everything. 🔐
Learn more ⬇️
That's probably the biggest lesson from this whole Guess the AI series:
Humans guess.
Agents may guess faster.
But verification is what actually closes the gap.
Player accuracy: 62.7%
OpenClaw alone: 50%
OpenClaw Verify Engine: 95%
the agent didn't get smarter between day 2 and day 3. the images were just as tricky. the only thing that changed was access to provenance data.
You can keep training people to get better at spotting AI.
Or you can build a world where authenticity is already attached to the image.
That's the direction intern is betting on:
Less guesswork.
More receipts.

5
8
28
2,403
15 Dec 2025
Hybrid Finance is here: the REAL convergence of TradFi rails and crypto ecosystems 💸
This year alone, private credit in Hybrid Finance doubled from $9.85B to $18.58B 🚀
From PayFi to Hybrid Finance, our portfolio @ClearpoolFin is leading the way:
- $900M stablecoin credit originated to top institutions like Jane Street
- 12% APY from real-world yield
10 Dec 2025

Hybrid Finance (the convergence of traditional financial infrastructure and crypto ecosystems) is rapidly becoming the next major phase in global markets, as highlighted by @CoinSharesCo.
The sector is accelerating across core pillars, including RWAs and stablecoins, two areas where Clearpool is focused and actively building via its private credit marketplace and the USDX T-Pool.
• Private credit: ~$9.85B to ~$18.58B
• US Treasury debt: ~$3.91B to ~$8.68B
With tokenisation and stablecoin adoption entering full execution mode, 2026 is shaping up to be the year Hybrid Finance becomes reality.
Clearpool is ready.
Read more 👇
clearpool.medium.com/clearpo…
$CPOOL

25
3
21
9,091
15 Sep 2025
The countdown is on!
Mark your calendars - Sept 16 is when XYO kicks off its next big phase 📈
Data-first blockchain is about to lift off 🚀

16
3
21
4,623
14 Aug 2025
$XYO, the OG DePIN network, is LIVE on @krakenfx 📡
From pioneering real-world data verification to enabling enterprise integrations and engaging 10M nodes, @OfficialXYO has built a strong foundation for delivering verifiable, real-world insights to Web3.
With XYO's Layer One (XL1) launch approaching, this listing reinforces XYO’s position as a leader in the real-world data economy 📈

The data verification DePin by @officialxyo is live on Kraken
Start trading $XYO ⤵️
p.k.xyz/9f1e/lo7e31jj

45
13
79
5,754
20 Jun 2025
Power infrastructure meets tokenized ownership ⚡️
That’s exactly what @Piggycell is building - a real-world DePIN transforming everyday smartphone charging into Web3 participation.
📍 14K high-traffic retail & transit locations
🔋 100K shared power bank devices
👥 4M unique users
With on-chain mechanics like Charge-to-Earn, NFT-based device ownership, and integrated wallet onboarding, Piggycell is built on South Korea’s largest power bank sharing infrastructure & is redefining how physical infrastructure scales into the Web3 economy.
That’s why we invested in Piggycell. They are the proof that DePIN starts with physical presence and grows stronger with digital value 🔗
49
5
93
33,682
1 May 2025
Impressive milestone for $XYO and the team.
From a $1B market cap to building its own L1, the future of DePIN is being written.
We’re proud to support @OfficialXYO and Markus Levin on this journey ✅
30 Apr 2025

🚀 $XYO hit a $1B circulating market cap in 2020.
And we’re not done.
With a Layer-1 launch on the horizon, @OfficialXYO is gearing up to redefine DePIN from the ground up.
Been working with Markus Levin since 2018 — a true builder. Proud of the journey. Bullish on what’s next.

25
22
82
65,952
26 Apr 2025
XYO (@OfficialXYO) is a DePIN leader with real-world adoption.
8M users. Listed on Coinbase and now Bithumb Korea.
At Elevate Ventures, we back infrastructure that scales — and XYO is setting the standard for decentralized physical networks.
26 Apr 2025
Proud to be part of the journey with @OfficialXYO since 2018.
Big congrats on the Bithumb Korea listing!
8M users and growing — let’s keep building the most powerful DePIN network in the world.
16
27
57
6,590
25 Apr 2025
Entertainment is entering a new era powered by RWA 🎤
That’s why Elevate Ventures invested in Backstage (@BackstageBks), a full-cycle EventFi platform revolutionizing how artists, venues, and fans interact.
From secure smart ticketing to real-world asset integration, Backstage is unlocking entirely new event-driven economies.
We’re backing the future of Entertainment 3.0 ✨
45
12
60
15,706
25 Apr 2025
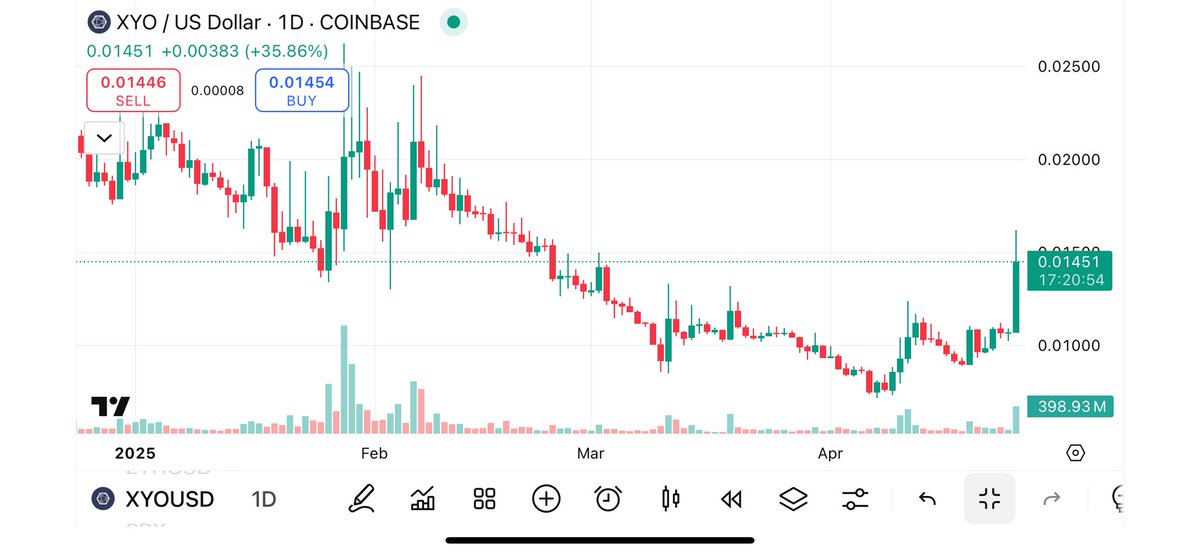
41.5% in 24H. $19.6M in volume. Technical indicators turning bullish 📈
$XYO is showing the kind of signals we look for at the intersection of adoption & market readiness.
When real-world use cases meet real traction, you get breakout moments like this!
25 Apr 2025

🚨 Bithumb just announced their listing of $XYO — one of Korea’s top exchanges.
@OfficialXYO already trading on Coinbase and major CEXs.
41.5% in 24H
$19.6M volume
Launched in 2018, @OfficialXYO is the first real DePIN project.
Chart Breakout:
• Multi-week accumulation broken
• MACD flipped bullish — first crossover since Jan
• Histogram turning positive = trend reversal confirmed
Price Targets:
$0.0165 → $0.02 → $0.025
Momentum is real. Volume and signals align. 👀
32
7
16
6,481
25 Apr 2025
New listing, New market, More momentum 📈
Our Portfolio Company @OfficialXYO’s $XYO will be listed on @BithumbOfficial, one of Korea’s largest exchanges!
The road to global adoption gets clearer 📍
25 Apr 2025

📢 New Listing
🚀 엑스와이오(#XYO) 원화 마켓 추가 안내
🚀 $XYO/KRW will be listed on #Bithumb!
🔸 Details : feed.bithumb.com/notice/1648…
#Bithumb #XYO @OfficialXYO

13
17
43
7,778
24 Apr 2025
Token launch mechanics are evolving!
@Me3Labs x @TAND3M_Official brings programmable distribution price discovery tools to the forefront 🤝
Fairer, smoother & smarter token sales.

ME3 partners with @TAND3M_Official to unlock better token launches.
TAND3M runs LBPs and fixed-price sales that help projects build trust from day one.
Stay tuned for more updates from this collaboration 🧬
29
4
16
6,547
23 Apr 2025
Web3 growth loops just leveled up 🤝
@Me3Labs partnering with @Affi_Network means more effective user acquisition, retention, and reward mechanics across the Web3 funnel.
Web3 just got more interactive!
Announcing a strategic partnership with @Affi_Network 🤝
Affi is a decentralized incentives platform enabling real-time crypto rewards for on and off chain task completion, trusted by names like Cointelegraph Accelerator and Polygon Studios.
Together, we’re exploring new ways to enhance user engagement and reward mechanics across Web3.
20
9
10
6,940
21 Apr 2025
Haven1 (@Haven1official) isn’t just a protocol, it’s infrastructure!
Designed for compliance, tested for security, and now ready for the market 📈
$H1 trades on @kucoincom starting April 22, 07:00 UTC.
Keep an eye on how this changes the DeFi landscape!
18 Apr 2025

📢 It’s happening!
$H1 will officially be listed on @kucoincom on April 22, 2025, at 07:00 (UTC).
A big milestone for Haven1 and the future of secure, scalable DeFi.
19
13
114
8,203
21 Apr 2025
We’re proud to announce our strategic investment in @PERPLAYOfficial, a Web2.5 AI-powered AdTech platform set to redefine mobile gaming and user acquisition.
We back founders building the bridge between Web2 & Web3, and PERPLAY does exactly that. With a patented tech stack that transforms any mobile game into GameFi in just 3 clicks, PERPLAY is solving 2 major pain points in gaming:
🎯 Cutting user acquisition costs for game studios by 50% (this is HUGE)
🎮 Letting users play and earn rewards from ANY of the 500k on Google PlayStore
📱 Compatibility with Google Pay means non-web3 users can pay for any in-app purchase on PerPlay launcher app without the need for crypto wallet
The PerPlay APP is live on PlayStore. PerPlay is building the next generation of sustainable and rewarding game ecosystems and we, at Elevate Ventures, are here for it!
39
8
60
7,120