
Unlock effective ecommerce strategies, optimize marketing efforts, and solve real-world business challenges with data insights using Python ,maths and Big Data
Joined January 2019
- Tweets 334
- Following 227
- Followers 48
- Likes 783
14 Photos and videos









25 Oct 2025
Doctors expected stents to reduce stroke risk — but a major study found the opposite.
How statistics was used to decode what's true? You will learn how treatment and control groups are created and its importance.
youtu.be/jKnWq9nP9Vk
52
29 Jan 2025
Deepseek Performance and it is clear winner among all models: Link- arxiv.org/pdf/2501.12948
99
29 Jan 2025
DeepSeek: Outperforming OpenAI at a Fraction of the Cost! Link- arxiv.org/pdf/2501.12948
75
Digital and Fintech Analytics retweeted

21 Dec 2024
Quickly turn a GitHub repository into text for LLMs with Gitingest ⚡️ Replace "hub" with "ingest" in any GitHub URL for a text version of the codebase.
61
376
3,207
285,800
Digital and Fintech Analytics retweeted

8 Dec 2024
I revisit this Sam Altman post nearly every month:

66
1,754
15,781
2,532,965
Digital and Fintech Analytics retweeted

15 Nov 2024
I wish I had had this animation when teaching Markov chain Monte Carlo. Could also help think about the behaviour of deep learning optimisation with non-vanishing gradients.
14 Nov 2024

We often think of an "equilibrium" as something standing still, like a scale in perfect balance.
But many equilibria are dynamic, like a flowing river which is never changing—yet never standing still.
These dynamic equilibria are nicely described by so-called "detailed balance"
3
33
270
22,838
Digital and Fintech Analytics retweeted

14 Nov 2024
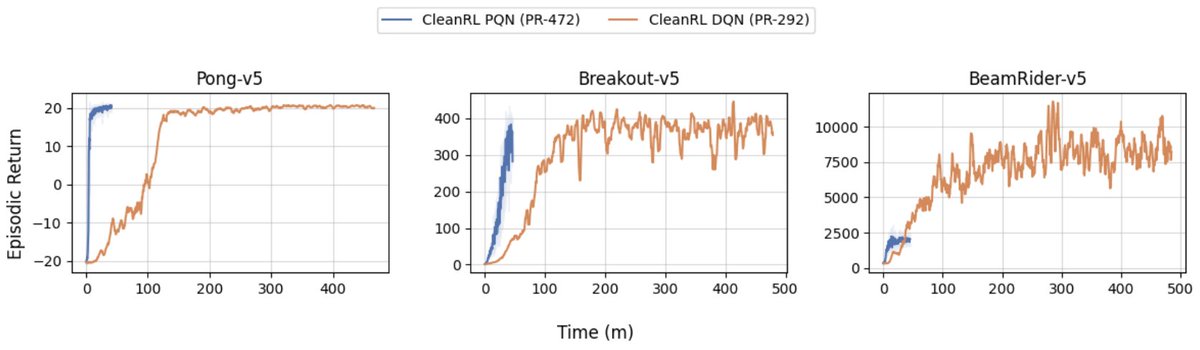
PQN is the best thing that has happened to model-free RL in a while, and people haven't realized it yet 🚀⚡️
14 Nov 2024

@creus_roger just implemented a @cleanrl_lib Parallel Q-Networks algorithm (PQN) implementation!
🚀PQN is DQN without a replay buffer and target network. You can run PQN on GPU environments or vectorized environments. E.g., in envpool, PQN gets DQN's score in 1/10th the time
4
11
43
6,542
Digital and Fintech Analytics retweeted

9 Nov 2024
Nice collection of LLM papers, blogs, and projects, focussing on OpenAI o1 and reasoning techniques.
What it offers:
📌 Curates papers, blogs, talks, and Twitter discussions about OpenAI's o1 and LLM reasoning
📌 Tracks frontier developments in LLM reasoning capabilities and techniques

3
100
459
30,248
Digital and Fintech Analytics retweeted

2 Nov 2024
Looks better than using the standard web chat interface

10
89
1,178
99,786
Digital and Fintech Analytics retweeted

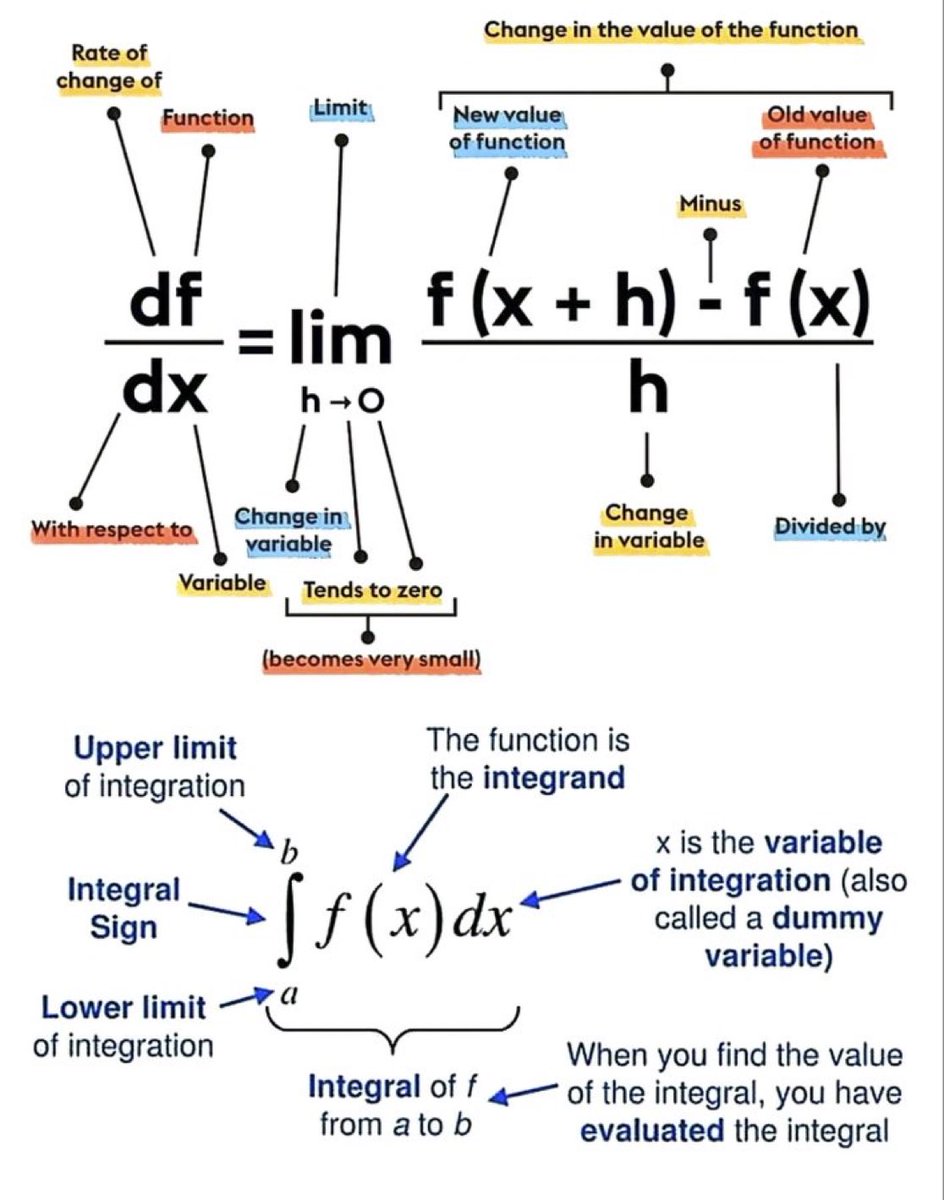
1 Nov 2024
Differential & Integral Calculus
5
316
1,648
130,674

getting this to #1 should be top prio. when you type SearchGPT into the extension store it spits out a bunch of garbage
chromewebstore.google.com/de…
5
10
186
81,360
Digital and Fintech Analytics retweeted

30 Oct 2024
Video lectures, Stanford CS 234 Reinforcement Learning spring 2024, by Emma Brunskill
web.stanford.edu/class/cs234…
youtube.com/playlist?list=PL…
5
89
464
31,744
Digital and Fintech Analytics retweeted
29 Oct 2024
Must-read papers for LLM-based agents.
A nice collection in this Github

5
151
809
59,432
Digital and Fintech Analytics retweeted

23 Oct 2024
Cold emails are hard and good ones can change a life. Here is my email to @NandoDF that started my career in ML (at the time I was a PM at Google) docs.google.com/document/d/1… Real effort (incl feedback) went into drafting it. Thanks to @EugeneVinitsky for nudging me to put it online
16
61
739
326,436
Digital and Fintech Analytics retweeted

22 Oct 2024
✨Announcing 5 incredible tutorials at @LogConference 2024:
1. Geometric Generative Models by @bose_joey, @AlexanderTong7, @helibenhamu
2. Neural Algorithmic Reasoning II: from Graphs to Language by @PetarV_93, Olga Kozlova, @fedzbar, Larisa Markeeva, Alex Vitvitskyi, @_wilcoln
1
23
95
26,361
Digital and Fintech Analytics retweeted

22 Oct 2024
Already on HF: huggingface.co/genmo/mochi-1…!

Introducing Mochi 1 preview. A new SOTA in open-source video generation. Apache 2.0.
magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/announce
7
21
185
27,289
Digital and Fintech Analytics retweeted

22 Oct 2024
📣Check out our #NeurIPS24 paper Geometric Trajectory Diffusion Models (GeoTDM), a new diffusion-based generative model that captures the temporal evolution of the ubiquitous geometric systems!!
Paper: arxiv.org/abs/2410.13027
Code: github.com/hanjq17/GeoTDM
🧵1/8
1
33
146
21,527
Digital and Fintech Analytics retweeted

7 Sep 2024
I just spent my Saturday writing >5000 words fully documenting every single feature of FastHTML handlers.
So please, read it, because I went slightly crazy doing this and I need to believe this helps someone out there...🤪
docs.fastht.ml/ref/handlers.…

38
78
912
47,061
Digital and Fintech Analytics retweeted

7 Sep 2024
Save it.

70
5,712
29,218
2,837,623
Digital and Fintech Analytics retweeted

6 Sep 2024
Since a number of people asked, this is what I mean by deep learning way of understanding reinforcement learning.
It's all about one question: how can I differentiate through the total reward my agent is collecting?
The total reward (i.e., the value function) is the objective function of RL. When we see an objective function in deep learning, our goal is to differentiate through it to compute a gradient. You can view many RL techniques and fundamental problems as ways to fulfill that unstoppable desire to differentiate through the value function.
If the world your agent is operating in is differentiable you can do it the easy way. If everything is deterministic or reparameterizable à la VAE, you have a complete computational graph. Just compute that gradient and push that value function up.
What if you don't have access to the world dynamics? You still want to compute that gradient. Learn a world model from data, then you will generate a valid computational graph and it will give you a gradient to push that value function up.
Your world model doesn't work as expected or it's computationally expensive? You can predict the value in a direct way with a critic, a value function approximator, and differentiate through it. With a critic, you can just do one forward and a backward pass. Direct gradient to your agent. No compounding errors, no messed up gradients, nothing too expensive.
Learning a critic by just predict the rewards you are observing is requiring too much data? You can use temporal difference, it's a nice concept that exploits the structure of decision-making to speed up learning for a critic. Then you will be able to compute your gradient.
You can understand a lot about reinforcement learning as just a quest to compute that gradient of the value function. It's not all of it, but I find it always useful to think about it.
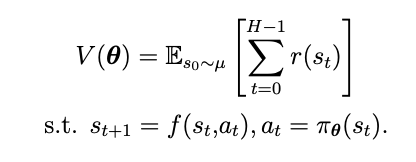
9
37
301
30,748