
I seek to understand intelligence, agency and awareness, and build AI aligned with compassion, freedom, universal human empowerment, and progress science.
Joined April 2009
- Tweets 12,505
- Following 898
- Followers 110,739
- Likes 20,841
441 Photos and videos












Nando de Freitas retweeted

Jun 12
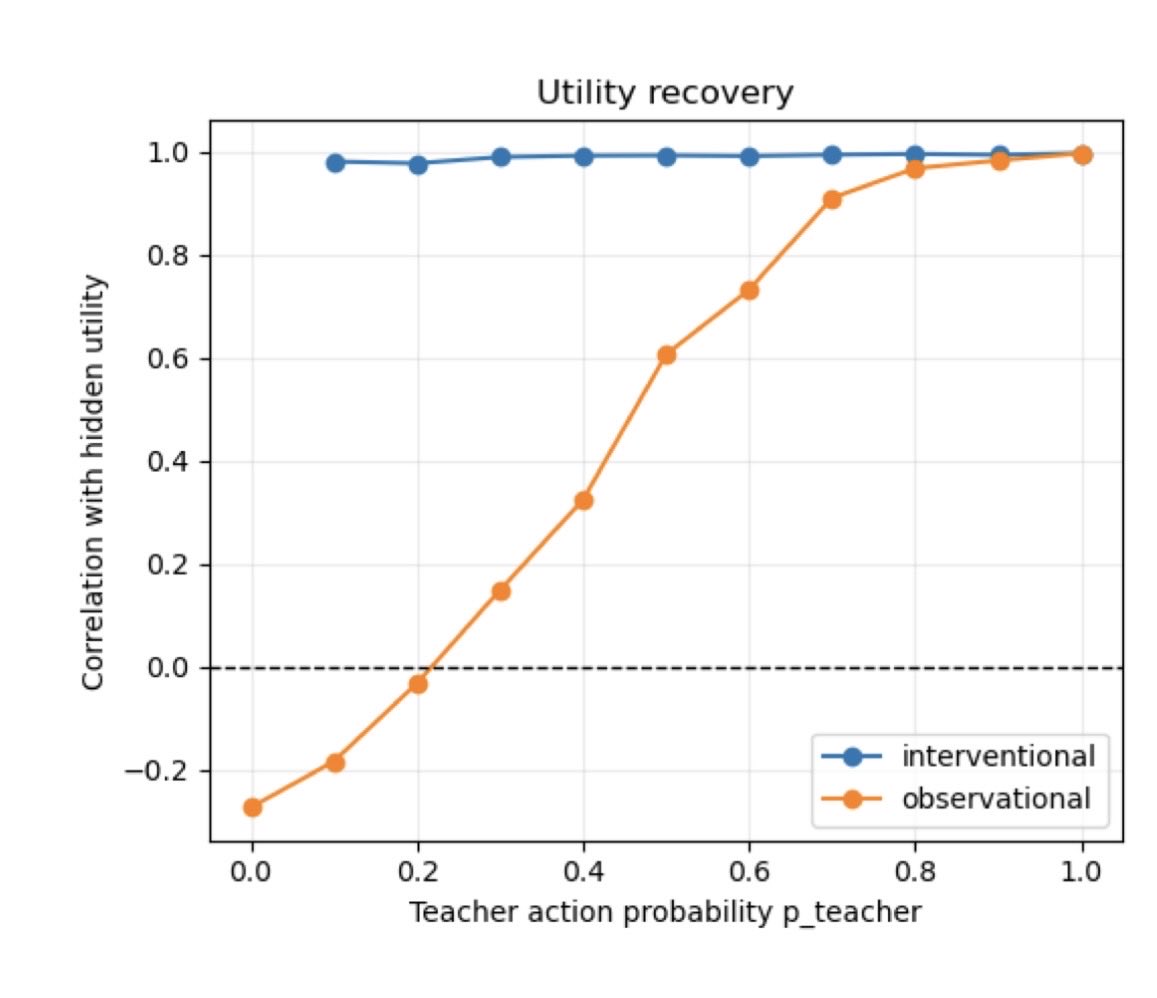
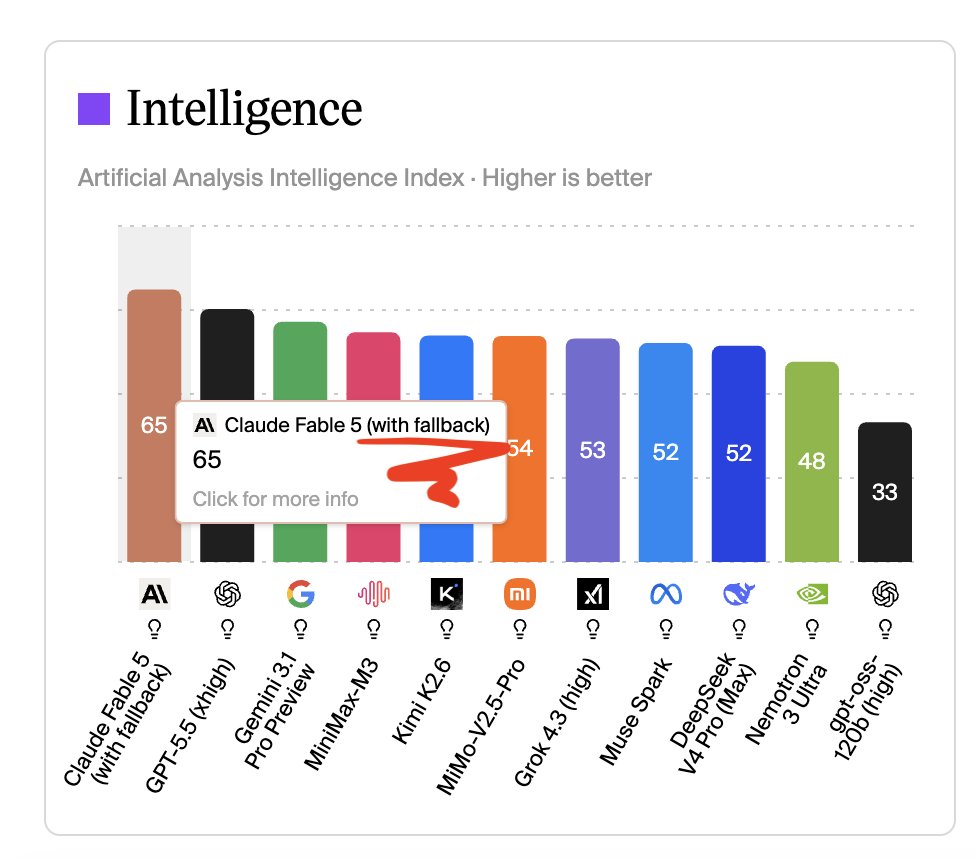
This graph captures what’s broken about AI evals: they structurally favor closed-source APIs that can route, fallback, ensemble, and optimize behind the scenes with no transparency.
No offense, @ArtificialAnlys, but how is comparing one model to two models fair?
71
44
615
80,741
No one should be surprised by this. The USA is doing what any self-interested nation state would do.
The real question is why are Europe, Canada, Australia, Korea, Japan and UK not able to compete seriously. That is the question everyone in government needs to answer.
And no, having a couple of startups that have raised $1B or $2B is FAR from enough to compete with $100B American companies. The scale matters. Imagine your sword’s length is 1cm and your rival’s 1m — no match.
Here is the harsh math (thanks to a poor version of Claude):
•10,000 GB200 superchips ≈ ~278 NVL72 racks.
•Each NVL72 rack costs roughly $3M–$3.5M.
•That puts the full-system total around $830M–$970M, before networking, power, cooling, and datacenter buildout.
That would enable you to train a model that was Sota 2 years ago. You need about 5 to 7 times this to compete today.
So the starting bill is $5B, but even if you have this, here is the reality: there’s no available chips. So when you hear someone raised $1B, remember this is going back to American compute, and is simply not enough.
The other two ingredients for AI are data and people.
American startups pay better than European ones, so the people vote with their feet so they can pay their mortgage and send kids to school. An experienced AI engineer makes double the salary in Europe by working for an American startup (like Anthropic) than a European one, and about ten times more if they work for a USA corporation. There are however amazing European startups, but the money and ambition is lacking.
The USA is far more relaxed with data and fair use - Canada is good too and @cohere is doing fine thanks to this. So American companies have a strong advantage over European ones. Brussels and the UK think they can hold the world to their questionable “ethical” views on data but they are just destroying the local AI industry, and in the process falling into a very precarious situation. They are partly responsible. Only the French minister has stood by their local LLM @MistralAI … and I guess more recently Germany has started to wake up.
The hope is of course LLM startups like @MistralAI and @cohere which are a year or so behind but can provide personalised services, and amazing startups like @cusp_ai @IneffableLabs @nscale @Orbital_Ind @bfl_ai and a few others. But for all these, it’s incredibly hard to compete.
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
32
40
335
65,200

Jun 13
This is an important achievement, and probably the first in a predictable sequence of results that will lead to fully automating LLM and OMNI training and serving.
As someone who has helped build some of the best multimodal and language models, I don’t see how this could play out any other way.
What challenges will remain then? For me: environments and applications that matter like healthcare, materials, scientific exploration, and above all energy harnessing and lasting energy storage. With that we can solve carbon capture and end hunger.

9
21
126
29,233
Jun 12
Dear England, where is the summer?!
I had no option but to let the entire world know about this ghastly situation
17
1
61
9,398
Jun 12
My 10 year old asked me to post this 😂 #when_you_post_too_much_on_twitter #fixing_the_world_with_twitter 😎
1
7
2,580
Nando de Freitas retweeted

Jun 11
New work on FACTR 2: Learning External Force Sensing for Commodity Robot Arms Improves Policy Learning:
Paper: arxiv.org/abs/2606.12406
Web: jasonjzliu.com/factr2/
FACTR 2 shows that learned force signals can both enable force-feedback teleoperation on low-cost manipulators and improve behavior cloning (BC) policies for contact-rich tasks. It consists of two components:
1. Neural External Torque Estimation (NEXT): A lightweight model that infers external joint torques without dedicated force sensors.
2. Force-Informed Re-Sampling Training (FIRST): A training strategy that uses the learned force signal to identify and upsample task-critical moments.
The key insight is simple: policy failures rarely occur in free space, they occur during brief pre-contact alignment and contact-rich interactions, where precise corrections matter most.
Together, NEXT and FIRST bring force-aware teleoperation and robust long-horizon contact-rich policy learning to off-the-shelf robot arms, without requiring additional sensing hardware.
See a more detailed thread by @JasonJZLiu.
Jun 11

💥Introducing FACTR 2, learning external force sensing on commodity robot arms without needing dedicated sensors.
We show that learned force signals enable force-feedback teleop on low-cost arms and improve BC policies.
FACTR 2 consists of:
1. Neural External Torque (NEXT): learns external forces without needing dedicated force sensors.
2. Force-Informed Re-Sampling Training (FIRST): uses the learned force signal to identify task-critical regions and upsample them during training.
w/ @StevenOh_ @_tonytao_
🧵(1/N)
3
15
63
19,423
Nando de Freitas retweeted

Jun 10
I vibe-CADed a hexapod walker entirely with claude/codex, learned the walking gait entirely in the 3d simulator, 3d printed the generated files, ordered the full BOM from amazon, assembled the thing. The fact that this is possible is amazing, but there's still some clear differences between the simulated world and reality 😀.
23
19
263
80,212
Nando de Freitas retweeted

Jun 11
asked claude fable 5 to design a qdd actuator
it also animated the gearbox and inspected collisions as part of the validation loop
~ 30 minutes / 400k tokens
74
174
2,553
312,579
Nando de Freitas retweeted

Jun 11
Together with UC Berkeley we are announcing the laser phase plate - a breakthrough in atomic resolution imaging. This is the brightest continuous wave laser in the world, 100 million times the intensity of the surface of the sun.
Phase contrast plays an important role in microscopy, but it was thought close to impossible for electron microscopy, where it would require interfering with an electron beam. Holger Mueller and Robert Glaeser proposed exactly this using a standing wave laser. It has taken over 15 years to make this a reality. Biohub partnered with UC Berkeley and Mueller to support this work and to engineer and build the technology.
Contrast has been the critical barrier to achieving atomic resolution imaging of the cell. In cryo-electron tomography, a cellular imaging technology that uses electron microscopy, the low contrast makes it impossible to resolve anything but the largest proteins within their cellular context. The laser phase plate removes that barrier.
With advances in AI this breakthrough in contrast will start to open up a new frontier in structural biology, that will allow us to see the molecular machines of the cell, and how they assemble into far more complex and dynamic systems, and understand how they work.
82
510
3,571
542,506
Nando de Freitas retweeted

Jun 11
🛫 A complete Airbus-class turbofan — fully parametric, animated, built entirely in the browser.
Created in confBuild with Claude Fable 5:
⚙️ Real internals — 7-stage compressor, annular combustor, 4 turbine stages
🌀 Two-spool animation: HP & LP shafts at real differential speed
🔥 Flow lines & exhaust react live to the N1 lever
📐 Dimensions on sliders — everything recalculates exactly
📄 Export to STEP, auto-generate technical drawings
Every chamfer and bore: calculated, not painted.
#CAD #Engineering #Turbofan #Aerospace #confBuild #AI
27
68
597
41,893
Nando de Freitas retweeted

Jun 11
The release of Anthropic's Mythos-class Claude Fable 5 is the latest signal that we are in a phase of exponential growth in AI capabilities, "takeoff mode". The biggest leaps are in engineering and scientific reasoning: frontier models now match or exceed expert-level performance on many technical tasks, and increasingly act as collaborators that plan, code, simulate, and design (as we show in our own research on self-improving agentic discovery systems).
Understand these technologies deeply is critically, both the foundations and how they're applied to critical industrial problems at scale, and to use them to drive innovation and technology development.
This July 27–30, I will teach Applied AI for Materials Discovery at @MITProfessional (live online so you can participate from anywhere). It's a hands-on deep dive into the shift from predictive ML to agentic, closed-loop AI-native discovery and innovation. Highlights:
▶ AI scientists & recursive self-improving swarm intelligence: massively parallel agents that read literature, formulate hypotheses, write and run code, and critique each other's work
▶ Generative AI for inverse design: diffusion and flow matching for proteins, alloys, metamaterials, and crystals
▶ Foundation models that "think" physics: graph transformers, neural interatomic potentials, neural operators and PINNs
▶ Bridging the reality gap across scales: connecting atomic-scale agents to physics simulators and product-scale (DFT, MD, FEA) for automated verification of AI-generated designs
▶ Building custom reasoning models: fine-tuning, RL; incorporating first-principles physical agency (e.g. MCP, tool use)
▶ Unlocking dormant knowledge: turning unstructured data (papers, patents, lab notebooks, legacy PDFs, etc.) into structured, actionable insight
▶ Interpretability, reliability, and enterprise deployment
The course will provide you with ready-to-use agent templates, dozens of code notebooks, repos, and curated datasets you can deploy immediately in your organization.
More details on the course and registration link, see reply.

ALT The biggest leaps in AI are in engineering and scientific reasoning: frontier models now match or exceed expert-level performance on many technical tasks, and increasingly act as collaborators that plan, code, simulate, and design (as we show in our own research on self-improving agentic discovery systems). Understand these technologies deeply is critically, both the foundations and how they're applied to critical industrial problems at scale, and to use them to drive innovation and technology development.
6
18
107
12,543

Nando de Freitas retweeted

Jun 10
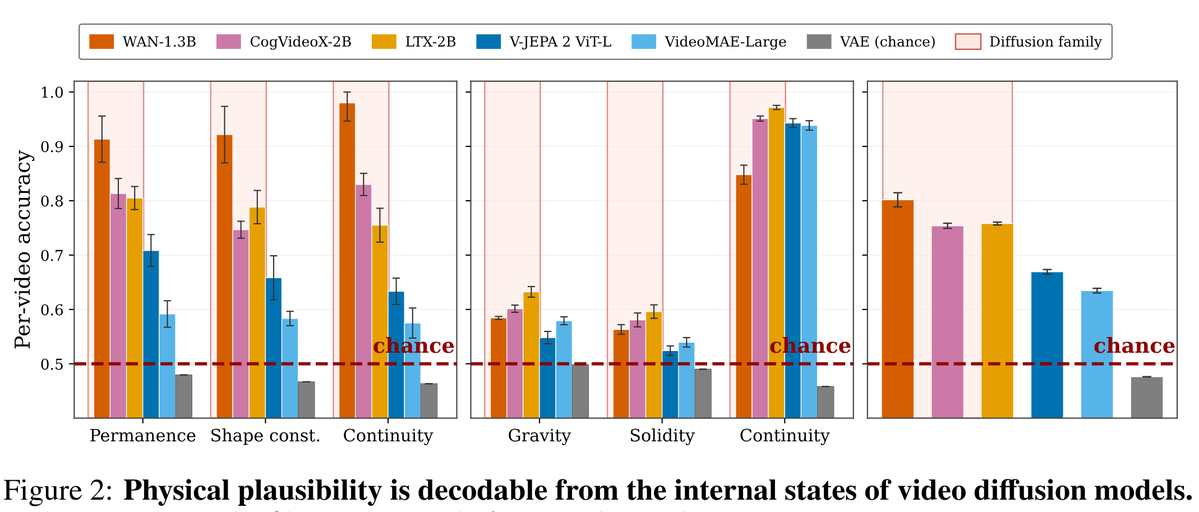
You may have recently heard claims that video generation models are "dumb" about physics, and only "world models" (V-JEPA, specifically) have a valid internal model of physics.
This turns out to be false. In a recent paper, researchers show that a LINEAR probe of diffusion videogen models predict various "physics" very well, significantly better than V-JEPA or VideoMAE (and plain VAE just sucks).
This is noteworthy, because a *linear* probe being this accurate shows that the model has a pretty explicit internal representation of the physics!
42
107
1,065
99,690
Jun 10
Do you feel safer thanks to this?
Yes / No ?
Jun 9

BREAKING NEWS: Anthropic's latest model will NOT help you if it thinks your ML research/ML engineering is interesting, and/or will secretly degrade its IQ so that the average engineer won't notice. We are already seeing Anthropic's latest model's moderation filters our GPU inference research and programming 😭

20
27
9,148
Jun 9
Great interview: “Edwin Chen is the founder and CEO of Surge AI, powering frontier labs with elite data, environments, and evaluations. Surge surpassed $1 billion in revenue with under 100 employees last year, completely bootstrapped”
The $1B Al company training ChatGPT, Claude & Gemini on the path to resp... youtu.be/dduQeaqmpnI?si=8RE5… via @YouTube
6
3
27
8,031
Nando de Freitas retweeted

18 Dec 2025
This paper from Harvard and MIT quietly answers the most important AI question nobody benchmarks properly:
Can LLMs actually discover science, or are they just good at talking about it?
The paper is called “Evaluating Large Language Models in Scientific Discovery”, and instead of asking models trivia questions, it tests something much harder:
Can models form hypotheses, design experiments, interpret results, and update beliefs like real scientists?
Here’s what the authors did differently 👇
• They evaluate LLMs across the full discovery loop hypothesis → experiment → observation → revision
• Tasks span biology, chemistry, and physics, not toy puzzles
• Models must work with incomplete data, noisy results, and false leads
• Success is measured by scientific progress, not fluency or confidence
What they found is sobering.
LLMs are decent at suggesting hypotheses, but brittle at everything that follows.
✓ They overfit to surface patterns
✓ They struggle to abandon bad hypotheses even when evidence contradicts them
✓ They confuse correlation for causation
✓ They hallucinate explanations when experiments fail
✓ They optimize for plausibility, not truth
Most striking result:
`High benchmark scores do not correlate with scientific discovery ability.`
Some top models that dominate standard reasoning tests completely fail when forced to run iterative experiments and update theories.
Why this matters:
Real science is not one-shot reasoning.
It’s feedback, failure, revision, and restraint.
LLMs today:
• Talk like scientists
• Write like scientists
• But don’t think like scientists yet
The paper’s core takeaway:
Scientific intelligence is not language intelligence.
It requires memory, hypothesis tracking, causal reasoning, and the ability to say “I was wrong.”
Until models can reliably do that, claims about “AI scientists” are mostly premature.
This paper doesn’t hype AI. It defines the gap we still need to close.
And that’s exactly why it’s important.

378
2,110
8,181
1,171,644

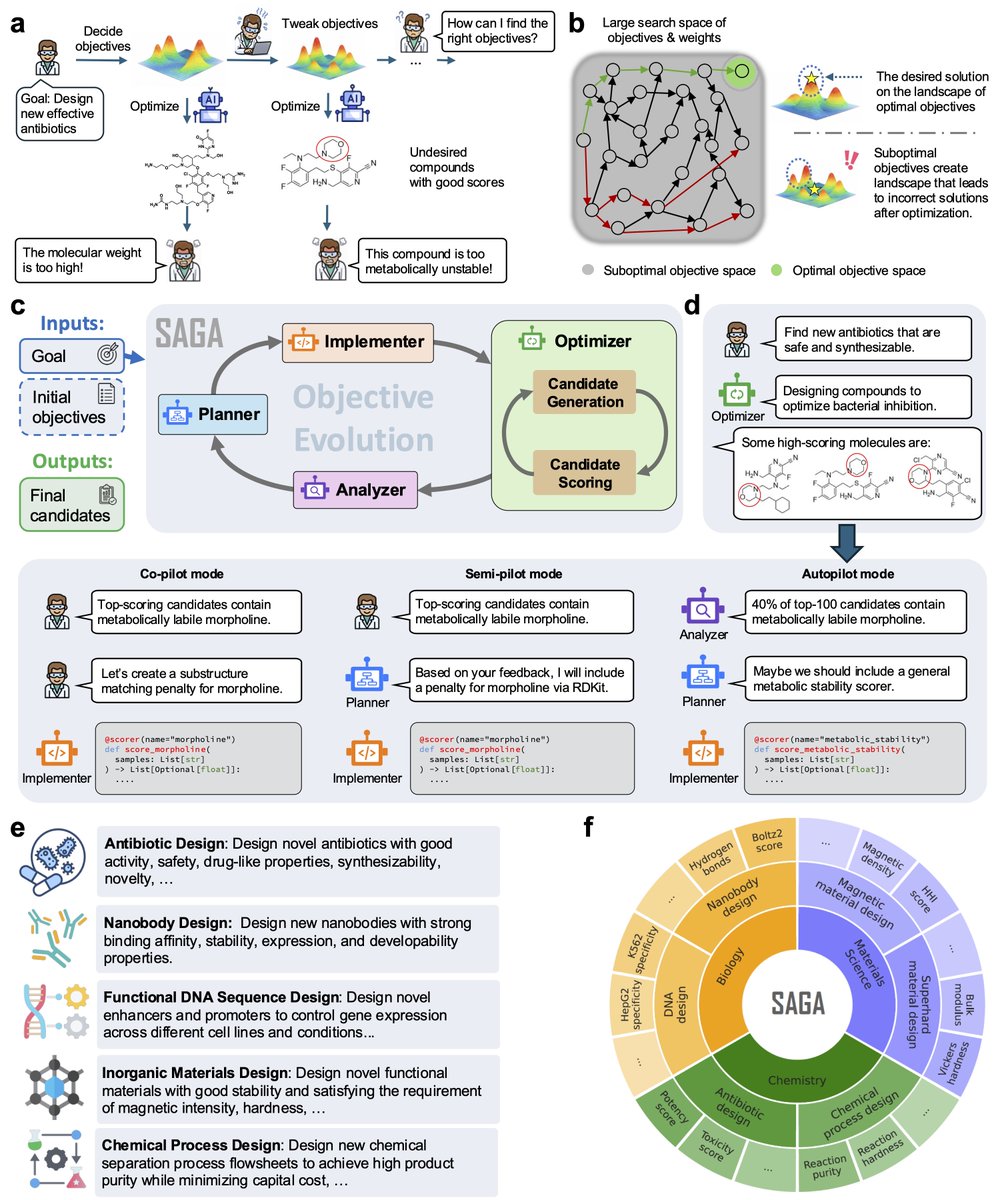
❓How can we build AI agents that do what scientists actually do? Is scientific discovery merely a search problem?
🚀 Meet SAGA: Scientific Autonomous Goal-evolving Agents. Five discovery tasks across chemistry, biology & materials science, with wet-lab validation.
11
59
257
37,090
Jun 8
In this blog, we explore new potential directions for the field of AI based on continual interaction and causality:
love4all.ai/blog/continual-i…
We've been working on this for years. Pedro Ortega pointed out issue much earlier when I was working on General AgenT One: GATO 🐈⬛
arxiv.org/abs/2205.06175
We discussed the problem of delusions with LLMs, OMNI models or World Models in a @GoogleDeepMind report:
arxiv.org/abs/2110.10819
The theoretical breakthrough was this:
adaptiveagents.org/universal…
Then it was generalised to back-propagation and neural networks:
love4all.ai/files/why-it-is-…
And to reward learning:
love4all.ai/files/emergent-r…
Here, we started testing the idea for Q&A datasets, and comparing against ReST and GRPO, to show viability.
What we need now is to implement an agent that browses the web (or any other environment) and whenever it finds a question or challenge with a solution (text, teacher, oracle), it attempts to solve it itself. If it succeeds it continues. If it fails, it looks at the solution, and continues. Importantly, it must NOT learn from its actions but from the consequences of its actions - the blog explains why.
This agent does not learn from sequences or histories of observations. This model learns from interaction and interaction histories. It is of paramount importance to appreciate this distinction.
What matters now is those environments on the right of the picture!
I am grateful to @OpenAI GPT5.5 and Codex, without which this research would have taken weeks if not months longer. Thanks @sama @gdb and team 🙏
❤️ 4 ∀ .ai
12
10
101
7,893
Nando de Freitas retweeted

Jun 6
Andrej Karpathy spent 2h showing how he actually uses AI day to day
he's a co-founder of OpenAI and led AI at Tesla, so when he shows how he works, it’s worth watching
and the whole session is just him telling the machine what he wants in simple terms, like he's briefing a coworker
watch what's actually happening the entire time:
> he describes the task in normal words
> it goes off and does the work
> he glances at the result and nudges it with one more sentence
that's the whole skill, and you've had it since you learned to talk
the only gap between that and a worker that runs on its own is handing that sentence a schedule and the tools to act
check his work, then build the version that keeps working when you stop

128
1,266
10,703
1,750,113