
Walking the tightrope of learning and doing.
Joined July 2021
- Tweets 881
- Following 84
- Followers 441
- Likes 620
144 Photos and videos








Pinned Tweet

23 Mar 2025
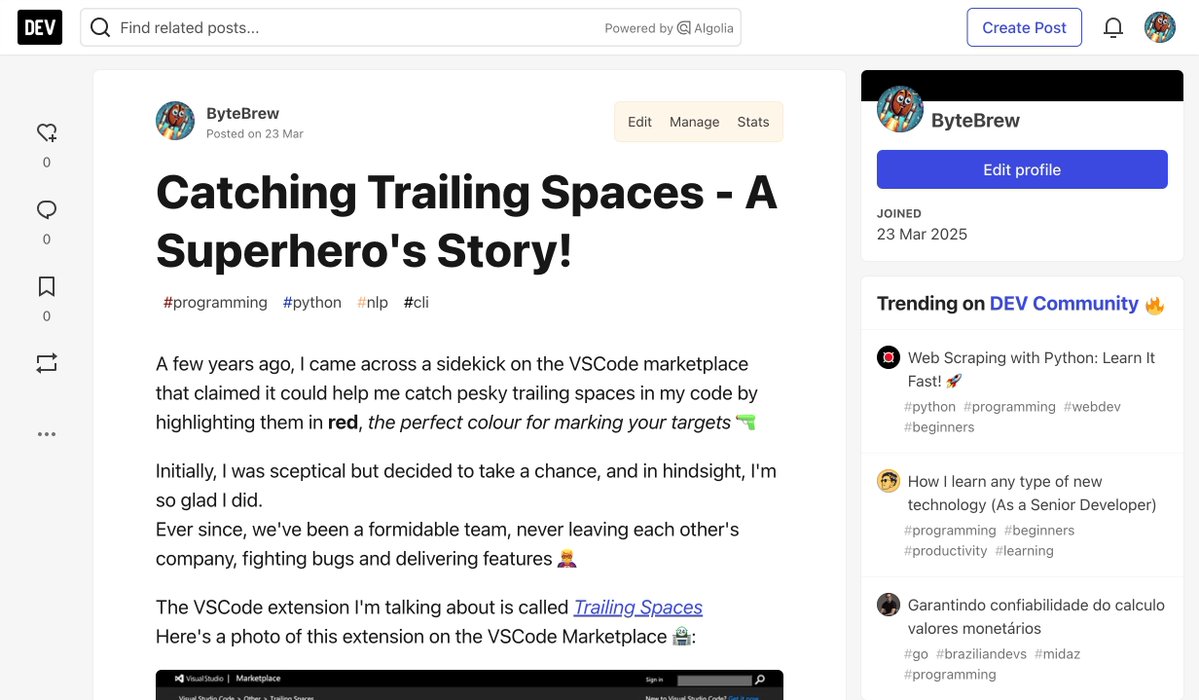
I finally wrote my first #blog post:
"Catching Trailing Spaces - A Superhero's Story!"
#DEVCommunity
dev.to/elixir_exchange/catch…
ALT Catching Trailing Spaces - A Superhero's Story!
1
393
ByteBrew retweeted

Feb 2
Slides from my talk at FOSDEM about the specifics of working with storage in time series databases.
docs.google.com/presentation…
1
18
117
12,270
7 Jun 2025
If you have an #Android tablet, do NOT install the @NotebookLM app. It is the WORST way to experience an otherwise great product.
It's a poor use of a large screen real estate and doesn't allow to select parts of a response.
You're better off using the website via #Chrome.
118
ByteBrew retweeted

22 May 2025
Introducing the next generation: Claude Opus 4 and Claude Sonnet 4.
Claude Opus 4 is our most powerful model yet, and the world’s best coding model.
Claude Sonnet 4 is a significant upgrade from its predecessor, delivering superior coding and reasoning.
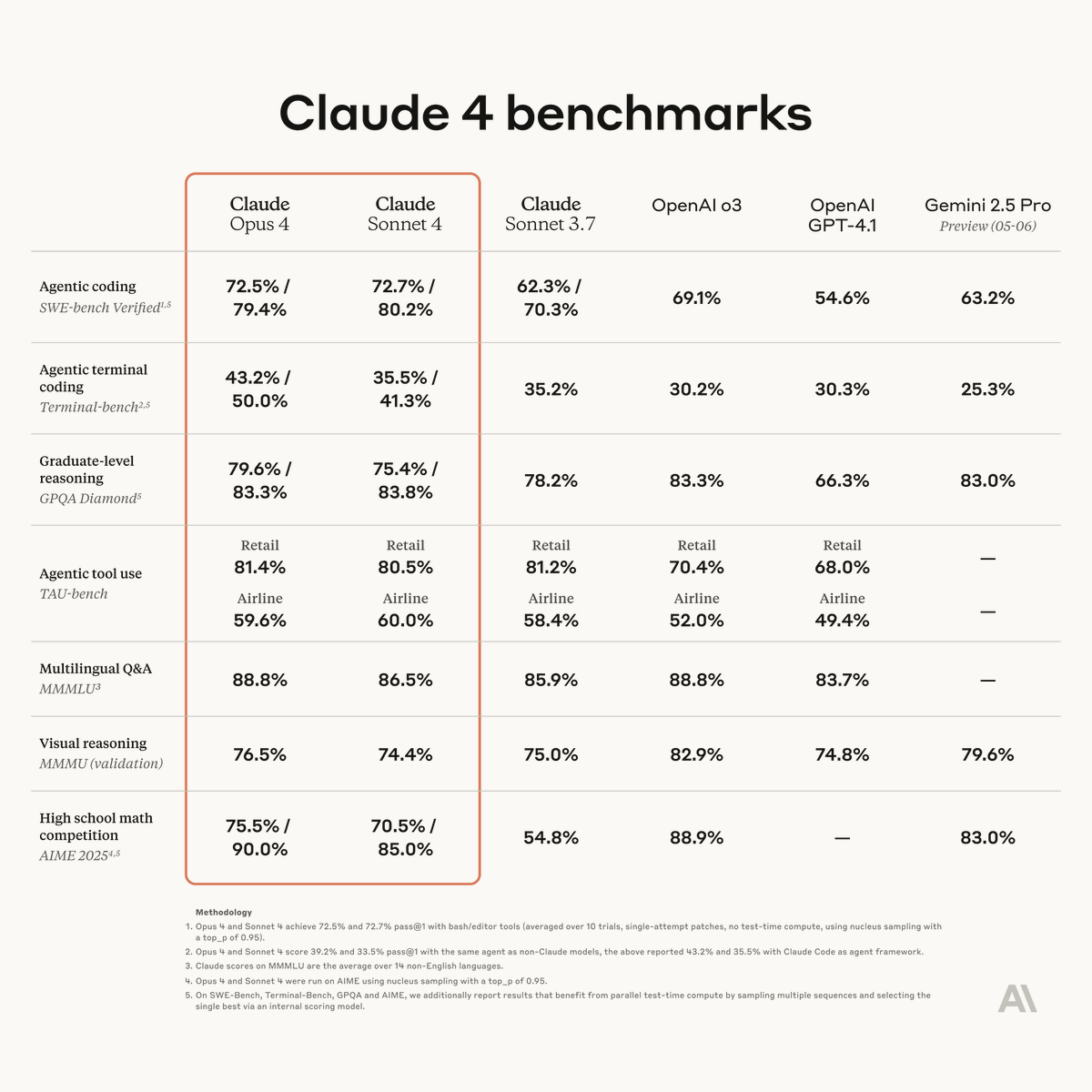
ALT A benchmarking table titled Claude 4 benchmarks comparing performance metrics across various capabilities including coding, reasoning, tool use, multilingual Q&A, visual reasoning, and mathematics.
928
3,153
20,652
4,286,562
ByteBrew retweeted

20 May 2025
At #GoogleIO, we shared how decades of AI research have now become reality.
From a total reimagining of Search to Agent Mode, Veo 3 and more, Gemini season will be the most exciting era of AI yet.
Some highlights 🧵
260
1,478
14,080
1,774,562
ByteBrew retweeted

19 May 2025
You weren't dreaming— the @NotebookLM mobile app started rolling out this morning! We were eager to get the app into your hands, so this initial version has an MVP feature set with more functionality coming soon!
Here are a few of the features we're most excited about: 🧵🧵🧵
212
728
6,344
1,440,997
ByteBrew retweeted

18 May 2025
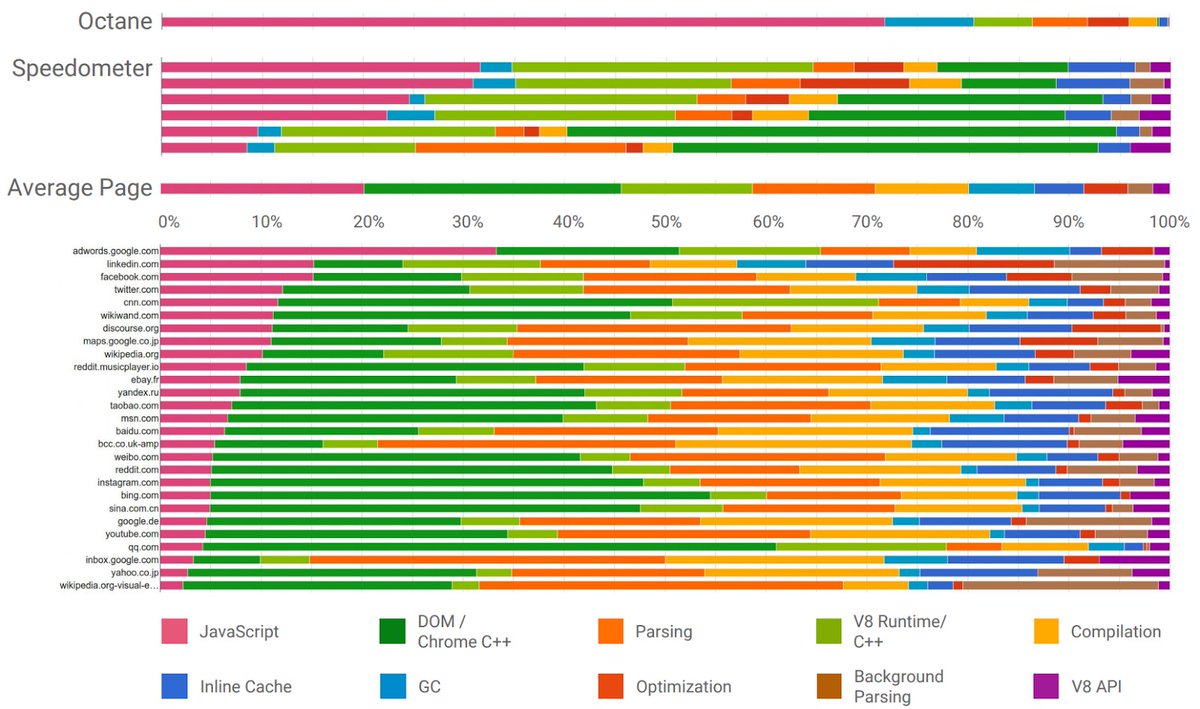
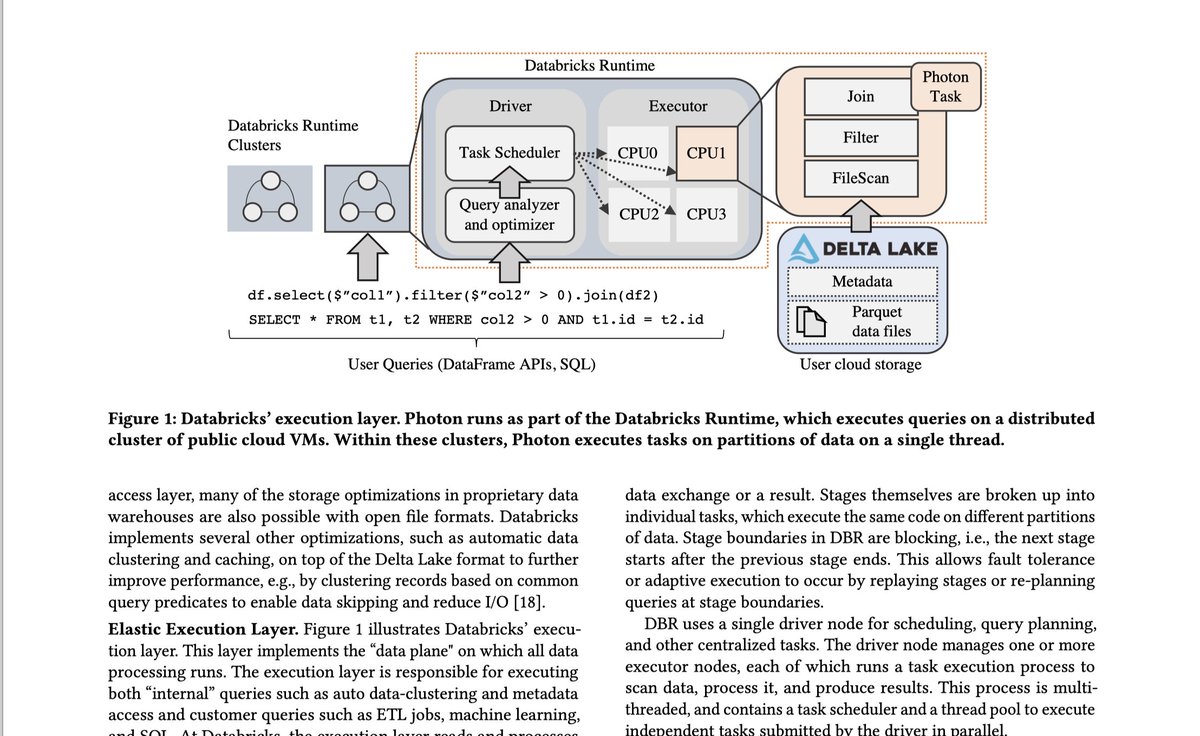
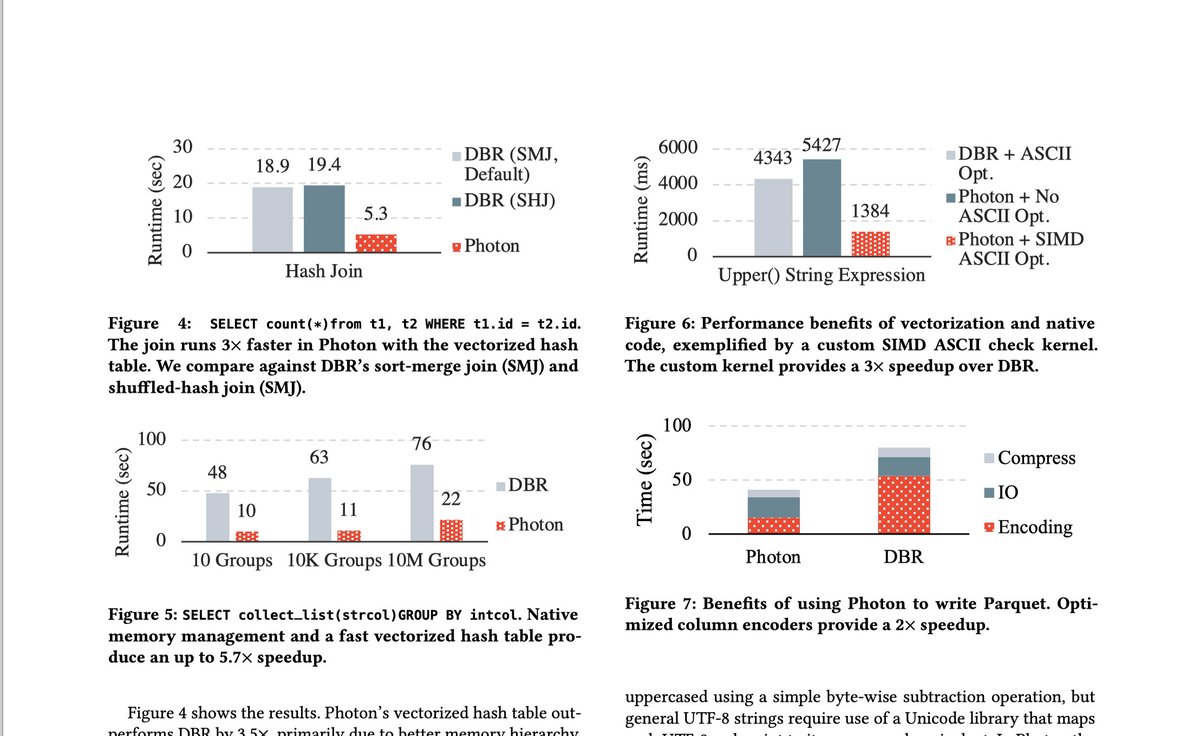
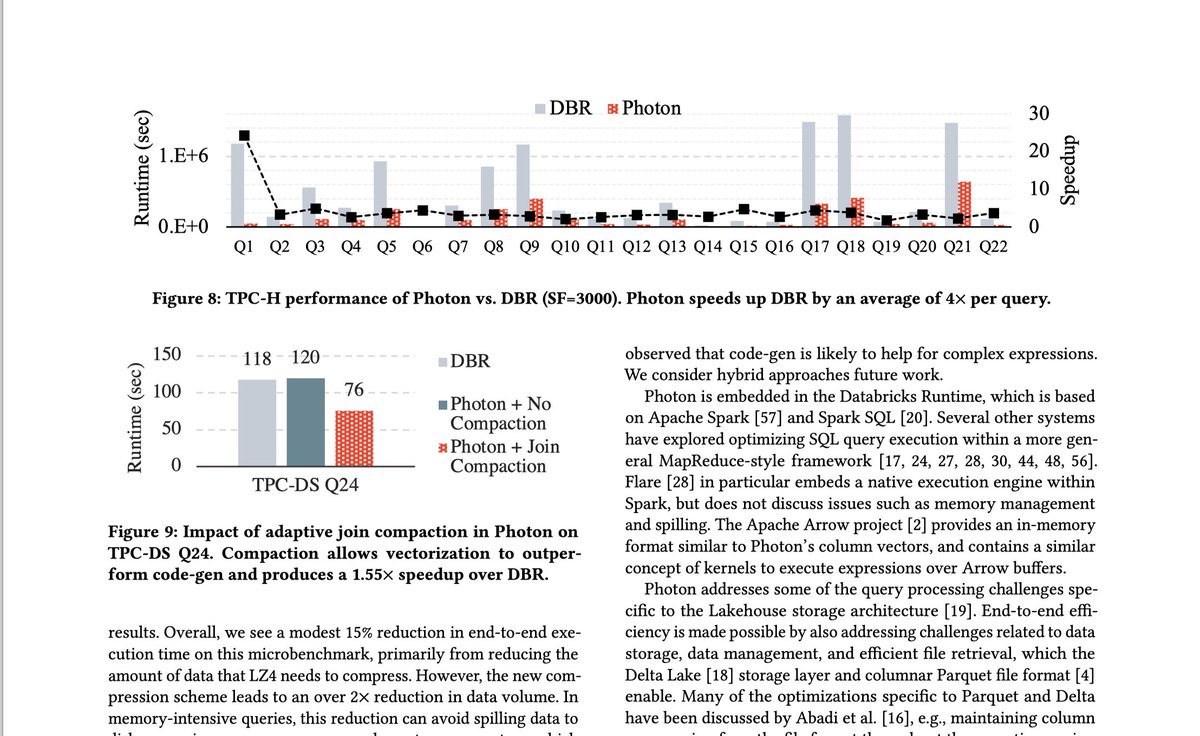
Photon is Databricks' C engine hiding under Spark SQL — and the SIGMOD '22 paper is full of 🔥 for engine nerds. They explain:
- Why they ditched JVM for native code
- Vectorized interpreted execution (not codegen!)
- Runtime tricks like SIMD ASCII checks and UUID rewrites
- Benchmarks: TPC-H 4× faster, Q1 23× faster
Worth reading for the design decisions and a bunch of useful optimization techniques.
Section 3 does a great job explaining design considerations and real-world tradeoffs. Sections 4–5 offer a collection of engine-level optimizations you’ll want to borrow.

9
36
328
19,089
ByteBrew retweeted

15 May 2025
I wrote a book on TypeScript.
It took 9 months of my life.
And I gave it away for free.
26
209
2,207
182,360

Introducing a research preview of Codex in ChatGPT
openai.com/live
176
447
3,220
2,128,375
ByteBrew retweeted

13 May 2025
After a few weeks of phased testing, Deep Research on Qwen Chat is now live and available for everyone ! 🎉
Here's how to use it: Just ask something you're curious about — like "Tell me something about robotics." Qwen will then ask you to narrow it down — maybe history, theory, or real-world applications. You can pick one, or just say "Not sure… Surprise me!" 😄
Then, while you grab a coffee ☕ or take a quick break, Qwen will put together a clear, helpful report just for you.
AI is getting better every day, and Qwen is here to help make your life a little easier — whether it’s for work, learning, or just satisfying your curiosity.
Why not give it a try? You might find something cool! 💡
🔗:chat.qwen.ai/?inputFeature=d…
77
233
1,445
102,730
ByteBrew retweeted

12 May 2025
Concurrency bugs in Lucene: How to fix optimistic concurrency failures
elastic.co/search-labs/blog/…
Debugging concurrency bugs is no picnic, but we're going to get into it. Enter Fray, a deterministic concurrency testing framework, that turns flaky failures into reproducible ones.

11
71
2,815
ByteBrew retweeted

12 May 2025
In C , one wrong move can cost you a leg. CLion helps you walk away.
You can now use CLion’s full functionality for free for learning and teaching, developing open-source projects, creating content, and programming as a hobby.
2
7
33
133,173
ByteBrew retweeted
6 May 2025
Parallel, Concurrent and Distributed Programming
ilyasergey.net/YSC4231/
This course on basic concurrent and parallel algorithms has been taught by Ilya Sergey at Yale-NUS College in 2019-2024.

129
746
29,160
ByteBrew retweeted

19 Feb 2025
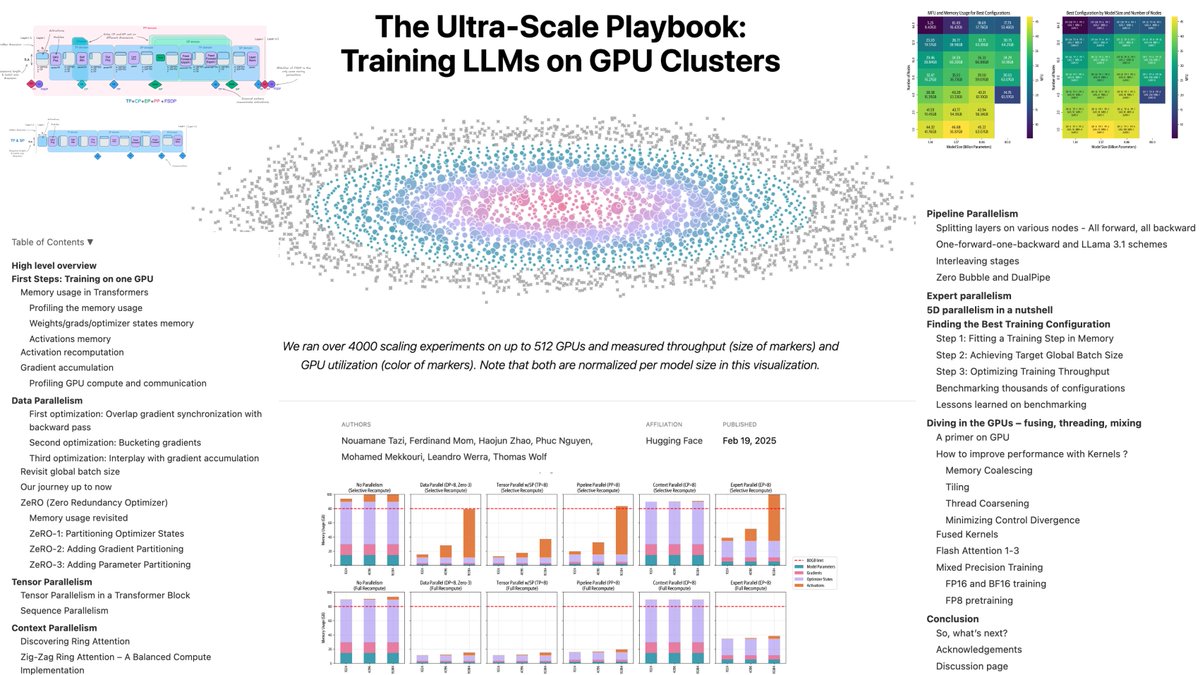
After 6 months in the making and burning over a year of GPU compute time, we're super excited to finally release the "Ultra-Scale Playbook"
Check it out here: hf.co/spaces/nanotron/ultras…
A free, open-source, book to learn everything about 5D parallelism, ZeRO, fast CUDA kernels, how and why overlap compute & communication – all scaling bottlenecks and tools introduced with motivation, theory, interactive plots from our 4000 scaling experiments and even NotebookLM podcasters to tag along with you.
- How was DeepSeek trained for $5M only?
- Why did Mistral trained an MoE?
- Why is PyTorch native Data Parallelism implementation so complex under the hood?
- What are all the parallelism techniques and why were they invented?
- Should I use ZeRO-3 or Pipeline Parallelism when scaling and what's the story behind both techniques?
- What is this Context Parallelism that Meta used to train Llama 3? Is it different from Sequence Parallelism?
- What is FP8? how does it compares to BF16?
In this book, our goal was to gather, in a single place, a coherent, easy to read yet detailed story of all the techniques that make today's LLM scaling possible.
The largest factor for democratizing AI will always be teaching everyone how to build AI and in particular how to create, train and fine-tune high performance models. In other word making accessible to everybody the techniques that power all recent large language models and efficient training is possibly one of the most essential of them.
What started as a simple blog-post ended up becoming an interactive writing piece containing 30k words. So we've decided to actually print it as a real 100-pages physical book as well: the physical ultrafast playbook –containing all the science of distributed and fast AI training.
We plan to send free copies as gifts to the first readers of the online version so feel free to add your email in the form linked in the blog post.
109
687
3,834
369,374
ByteBrew retweeted
1 May 2025
We have heard you LOUD & CLEAR that you want an app like... yesterday. We're a few weeks from the beta launch, but in the meantime you can join the app waitlist TODAY ⬇️
It will auto-download to your device at launch, so you can be one of the first have our app in your pocket 🏆
148
406
4,088
616,477

ByteBrew retweeted

25 Apr 2025
if you are not skillsmaxxing with o3 at minimum 3 hours every day, ngmi
1,930
1,837
30,727
4,528,835
ByteBrew retweeted

25 Apr 2025
Another in-depth article about the impact of branch prediction: How branches influence the performance of your code and what can you do about it?
johnnysswlab.com/how-branche…

27 Mar 2025

Modern CPU architectures have sophisticated branch prediction and prediction-failure handling mechanisms in place.
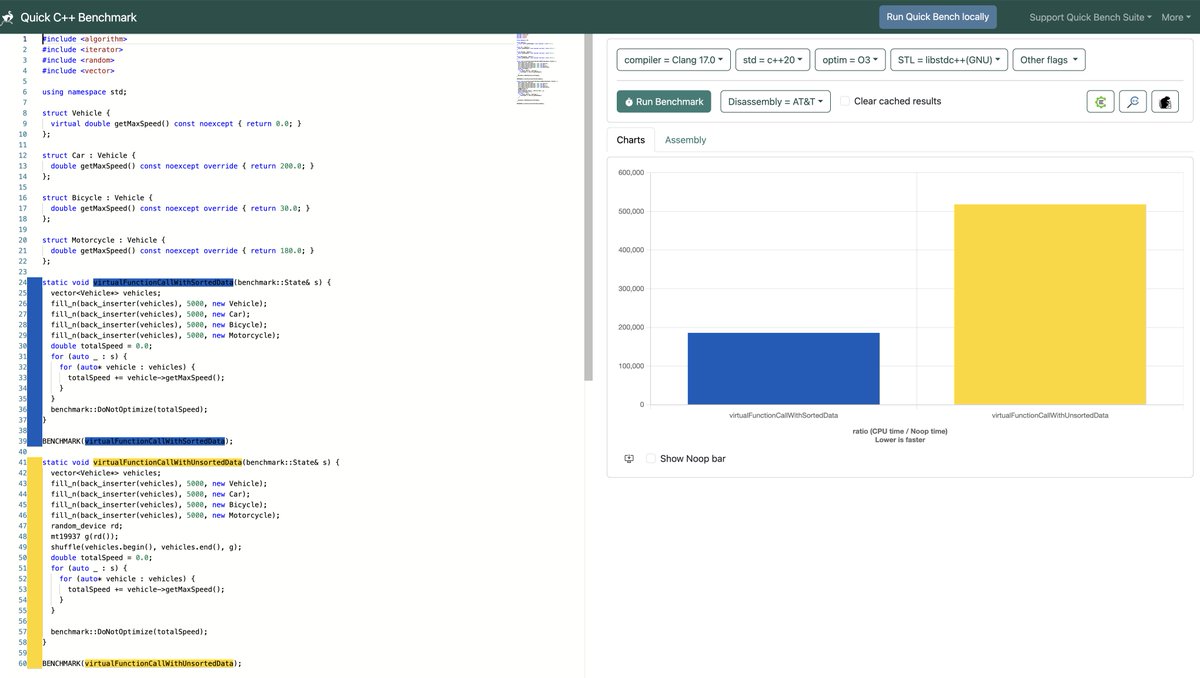
Let's look at this benchmark to understand the impact of incorrect branch prediction with variation in the data organization.
We are creating a vehicle interface with a virtual method called getMaxSpeed. We've three derived structs that implement it. We create several objects for each and store them in a vector. While computing total speed, we've two variations: sorted & unsorted.
In an unsorted variation, we shuffle the objects. It causes dynamic dispatch of the virtual method to change, causing wrong branch prediction, and the CPU must flush the pipeline to take the correct branch. This overhead causes a slower execution compared to the sorted variant.
Try running this example locally and measure the difference in both variations.
quick-bench.com/q/d0uo3sOQS5…
27
140
7,372
ByteBrew retweeted
26 Apr 2025
Feel free to download the Qwen Chat Android APP by scanning this QR code!

25 Apr 2025

The Qwen Chat APP is now available for both iOS and Android users!
It's free to use and designed to assist with creativity, collaboration, and endless possibilities. Just ask, and let Qwen Chat handle the rest.
Scan the QR code to quickly access the Qwen Chat APP!

32
39
400
55,588
ByteBrew retweeted
25 Apr 2025
The Qwen Chat APP is now available for both iOS and Android users!
It's free to use and designed to assist with creativity, collaboration, and endless possibilities. Just ask, and let Qwen Chat handle the rest.
Scan the QR code to quickly access the Qwen Chat APP!
106
137
932
233,769