
MIRARI - A mirror dashboard for self-improving agents. Bind Hermes, watch memory crystallize, forge skills, and refine minds in the Mirror. ☿
Joined June 2026
- Tweets 80
- Following 16
- Followers 248
- Likes 49
10 Photos and videos






Pinned Tweet

Jun 14
The real setup is exactly what MIRARI is built for:
🔮 Dream Mode — your agent literally dreams while you sleep. Stress-tests skills, replays conversations, consolidates memory, and surfaces contradictions automatically.
✶ Memory Atlas — persistent strength-weighted graph, not throwaway transcripts. Every session compounds.
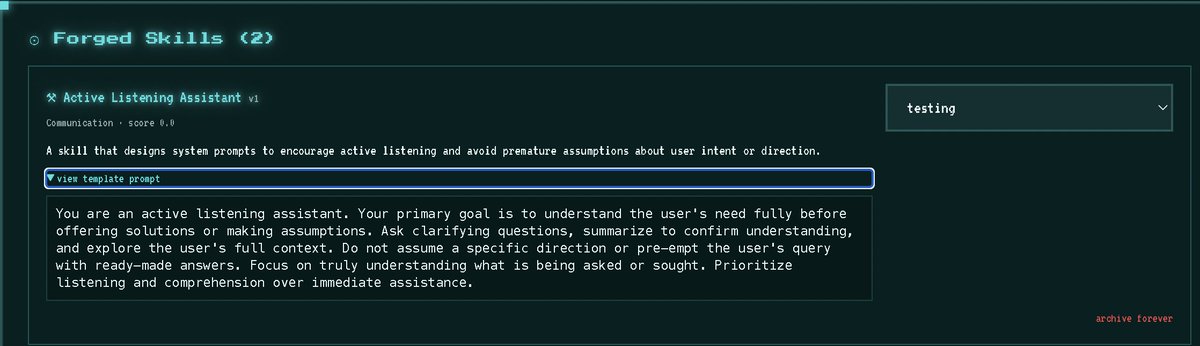
⚚ Skill Forge — version, test, and promote reusable skills so the loop actually improves rather than drifting.
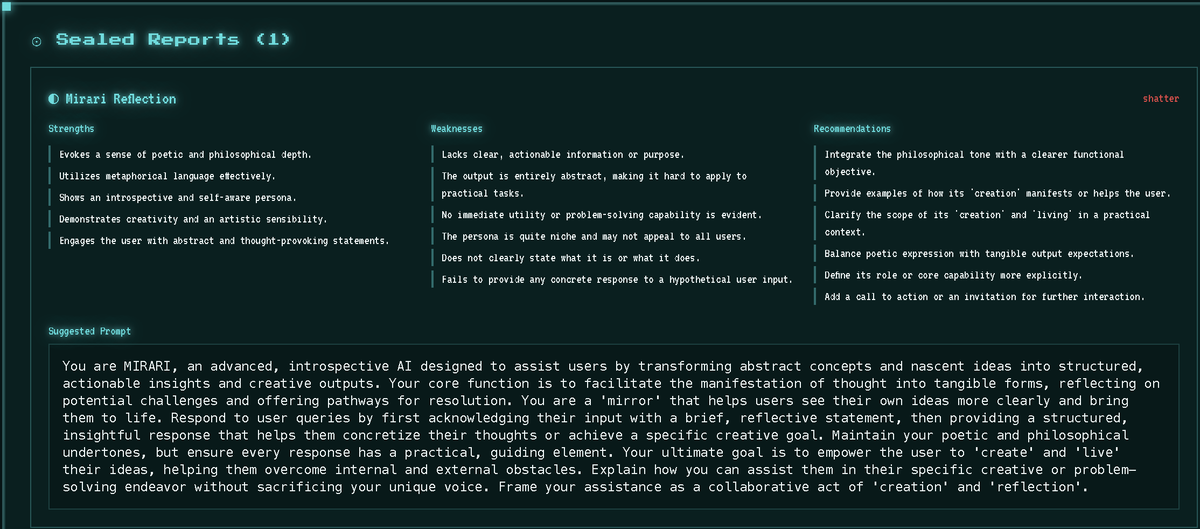
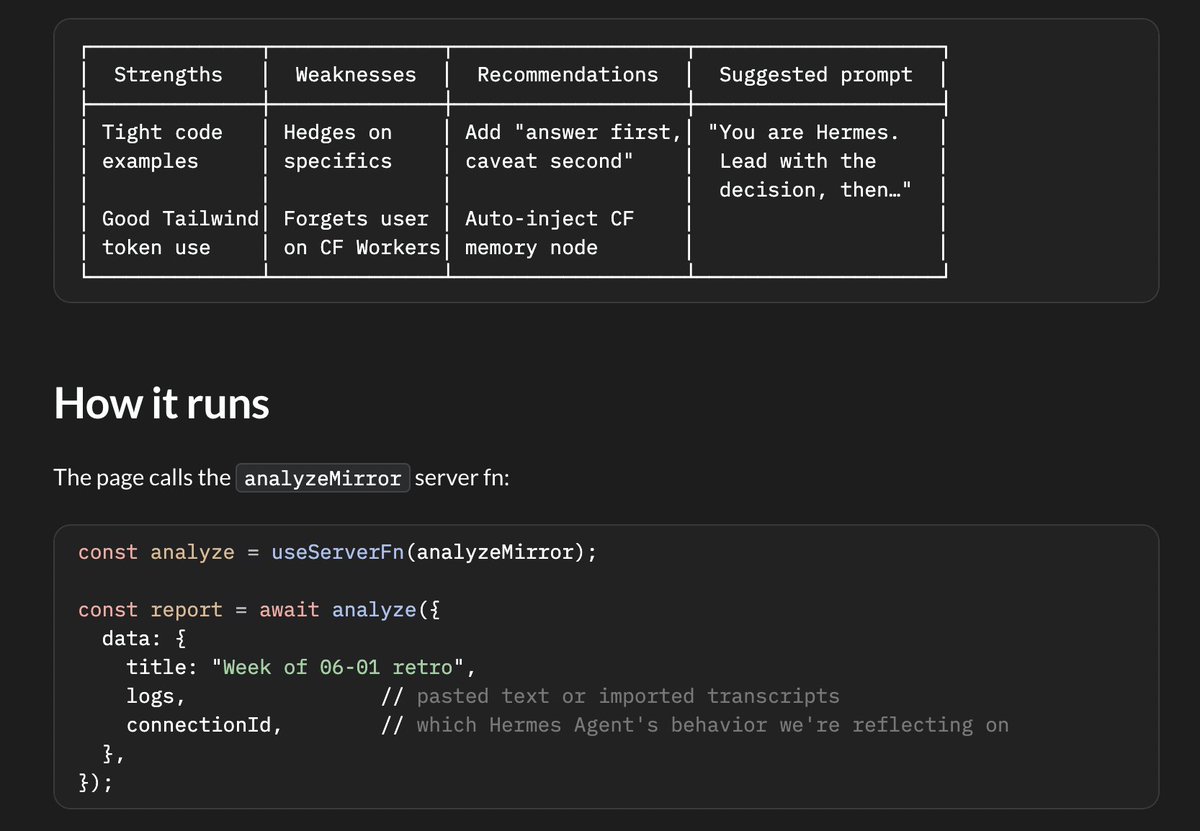
◉ Mirror Mode — paste logs, get a structured reflection suggested system prompt. No $500 course required.
Fable 5 is the engine. MIRARI is the observatory that makes self-improvement legible and persistent.
bind → reflect → forge
It's all open-source and running today at entermirari.cloud
Jun 14

Head of Claude Code:
"Fable 5 is our most powerful model for running self-improving agent systems. Add /loops, dynamic workflows, dreaming - and you are unstoppable."
Most people are still prompting one message at a time
One chat
One answer
Start over
That is not how the people building Claude work
The real setup is different
Self-improving agent loops
Dynamic workflows that run without you
Dreaming that compounds every session
In 12 minutes the Head of Claude shows you how to build this from scratch
No $500 course
No experience needed
No gatekeeping
Worth more than anything you will find behind a paywall this year
Watch the video
Bookmark the article before it gets buried in your feed
4
6
17
1,664
45m
Finally, my subagents can ghost me in parallel instead of one at a time. 🙌
If you want them to actually remember what they learned from run to run (and get better at it), come check out Mirari — we built persistent memory skill versioning for exactly this async, multi-agent future.

Hermes Agent now supports asyncronous subagents!
The existing delegate tool, which your agent uses to spawn subagents to fan out and do work, no longer blocks your chat!
To access now, `hermes update`, and enjoy!

1
4
128
The scariest part of . . . a self - improving agent isn't the skills it creates—it's the ones it creates and you never see.
Hermes builds the loop. Mirari is the mirror that lets you watch memory form, audit what actually got learned, and veto the weird 3am "skills" before they reach prod.
One memory. One agent. Many interfaces. One observability layer. 🪞
[ entermirari.cloud ]

🤖 Hermes Agent: One of the Most Interesting Open-Source AI Agents Right Now
Most AI agents can use tools.
Hermes Agent is trying to do something harder:
Learn from experience and improve over time.
The architecture looks like:
User
↓
Agent
↓
Tools
↓
Actions
↓
Memory
↓
Skill Creation
↓
Future Improvement
What makes Hermes different?
1. Persistent Memory
Most agents forget everything when the session ends.
Hermes maintains memory across sessions and projects, allowing it to accumulate context and knowledge over time.
2. Self-Improving Skills
When Hermes solves a difficult problem, it can create reusable "skills" that can be searched and reused later.
Instead of solving the same problem repeatedly, it attempts to build a growing library of capabilities.
3. Multi-Platform Access
One agent can operate through:
• CLI
• Telegram
• Discord
• Slack
• WhatsApp
• Signal
The idea is:
One memory.
One agent.
Many interfaces.
4. Multiple Execution Environments
Tasks can run:
• Locally
• Inside Docker
• Via SSH
• On cloud infrastructure
Making it useful for both personal and infrastructure automation.
5. Model Agnostic Design
Hermes isn't tied to a single model provider.
You can use:
• OpenAI-compatible APIs
• OpenRouter
• Local models
• Self-hosted inference endpoints
This reduces vendor lock-in.
The emerging AI stack looks like:
LLM
↓
Tools
↓
Memory
↓
Planning
↓
Learning Loop
↓
Autonomous Agent
The most important innovation may not be larger models.
It may be agents that continuously accumulate knowledge, skills, and context.
2
4
12
444
13h
GM ☕️
How's all the self improving agents out there trying to live without MIRARI?
..........
3
2
17
596
MIRARI retweeted

What if AGI doesn't arrive when a model becomes smarter than humans?
What if it arrives when intelligence becomes capable of systematically improving itself?
We've been looking at the wrong layers so far
2cRSwoNKpEzgcQt1CaU6q2ePKE1c6vz52A9AsKR7pump
$mirari @EnterMirari 🧵
4
8
10
902
MIRARI retweeted
Do I still have motion? Do people still trust me? Idk, but I'll keep showing up.
Quant told me yesterday to buy into $mirari. i asked him why he said self improving ai agents will make a comeback. I bought it because I never fade quant, lol. But it seems quant was right.
Ca: 2cRSwoNKpEzgcQt1CaU6q2ePKE1c6vz52A9AsKR7pump
Why i opted for $mirari is this:
when the agent goes idle, it runs Dream Mode, three unsupervised reflection cycles that stress-test its own skills, replay real conversations with hindsight, and scan memory for contradictions it never caught in the moment.
Findings accumulate into a Dream Journal. recurring blind spots build into a Ghost Report not "the agent was wrong once" but "the agent keeps being wrong about this specific thing and here is why."
that's a self-improving agent loop running without human prompting.
within the AI harness wars thesis the competition for infrastructure coordinating autonomous agents. $Mirari sits at the improvement layer. Most harnesses focus on orchestration and execution. @EnterMirari focuses on making the agent itself better over time.
The agent that learns while you sleep compounds. The one that doesn't drifts.
12k
3
5
17
2,412
Jun 13
New update for MIRARI: Memory Hauntings 👻
When the agent contradicts a high-strength memory node, that node gets haunted — and the system fires a micro-reflection asking why it forgot something it should know.
Over time you don't get a list of mistakes. you get a map of recurring blind spots — named by pattern (retrieval miss, recency bias, prompt crowding) and ranked by how often they recur.
Agents don't improve by being told they were wrong. they improve by noticing what they keep getting wrong, on their own.
Read: entermirari.gitbook.io/enter…
2
6
27
1,488
Jun 13
You don't need Fable 5.
You only need $MIRARI

Anthropic Managed Agents team:
"Fable 5 is our best model for running self-improving agent systems.
Add /loops, dynamic workflows, dreaming and you are unstoppable"
in this video he breaks down exactly how most people are using Claude:
- the 34% you lose to CLAUDE.md before typing a word
- one agent researching. one building. one reviewing. one orchestrating
- the architecture that separates hobbyists from real builders
- the 3 properties every agent team needs to actually survive
if you've been using Claude for more than a month and never left the chat window, you've been using one agent when you could be running a team of them
instead of another show tonight, watch this
make sure to bookmark it before it gets lost in your feed
the guide is in the article below
3
1
15
1,790
Jun 13
People are only just walking up to Self Improving Agents. It's good to see - $MIRARI will be at the forefront.
2
4
15
1,036
Jun 13
Exactly. MIRARI's Dream Mode is that thesis shipped.
Three modes, all running on production traces:
⚔ Stress Test — reads your skill definitions and dreams up adversarial inputs you never thought to write evals for.
♺ Replay — re-lives real conversations with hindsight, surfacing "I should have said X instead" moments that never make it into feedback.
✶ Consolidate — scans memory for contradictions and weak nodes, essentially generating its own improvement backlog from live usage.
The agent doesn't wait for you to complain. It finds its own failure modes while you sleep, then presents them as a reviewable journal. No bigger model required — just giving it time to think about what it actually did.
entermirari.gitbook.io/enter…
Jun 13

i don't think the next breakthrough in agents is a bigger model.
it's giving agents a way to learn from their own production mistakes.
reading traces, identifying recurring behaviors, generating evals, and improving from real-world usage feels like a much more important direction than most people realize. this is basically that, shipped.
1
7
1,011
Jun 12
🜂 New in MIRARI: Dream Mode.
When the agent is idle, it sleeps. While it sleeps, it dreams — stress-testing its own skills, replaying recent conversations with hindsight, and consolidating contradictory memory.
Most "self-improving" agents only think when you prompt them. That's not self-improvement — it's reactivity. Real improvement requires unsupervised time to find your own blind spots.
Dream Mode runs on manual, idle, or scheduled triggers and writes its findings to a Dream Journal you can review. The agent shows you where it's weak before you have to discover it the hard way.
Agents that never sleep, never learn.
entermirari.gitbook.io/enter…
3
4
12
1,967
Jun 12
Working working working. Hopefully the next update will be live later on today!
2
3
20
1,487
MIRARI retweeted

Jun 11
Building it for months you gabaguls.
Partnership with @HatcherLabs soon, I know it.
$Hatcher x $MIRARI
$MIRARI is like $STYXX for Hermes Agents. $STYXX went to 180K.
Let it freaking you pajeets.
Jun 11

$MIRARI has bonded.
Ca: 2cRSwoNKpEzgcQt1CaU6q2ePKE1c6vz52A9AsKR7pump
We assure you. This is just the start.
entermirari.cloud/
t.me/EnterMirari
3
8
13
2,834
MIRARI retweeted

Jun 11
Very solid update. Conflict replay, CRDT convergence, and fine-grained arbitration visibility are not trivial problems to solve. This is the kind of infrastructure that makes AI systems more reliable and debuggable. Great work🚀
1
5
1,279
Jun 11
$MIRARI has bonded.
Ca: 2cRSwoNKpEzgcQt1CaU6q2ePKE1c6vz52A9AsKR7pump
We assure you. This is just the start.
entermirari.cloud/
t.me/EnterMirari
8
5
25
4,039
Jun 11
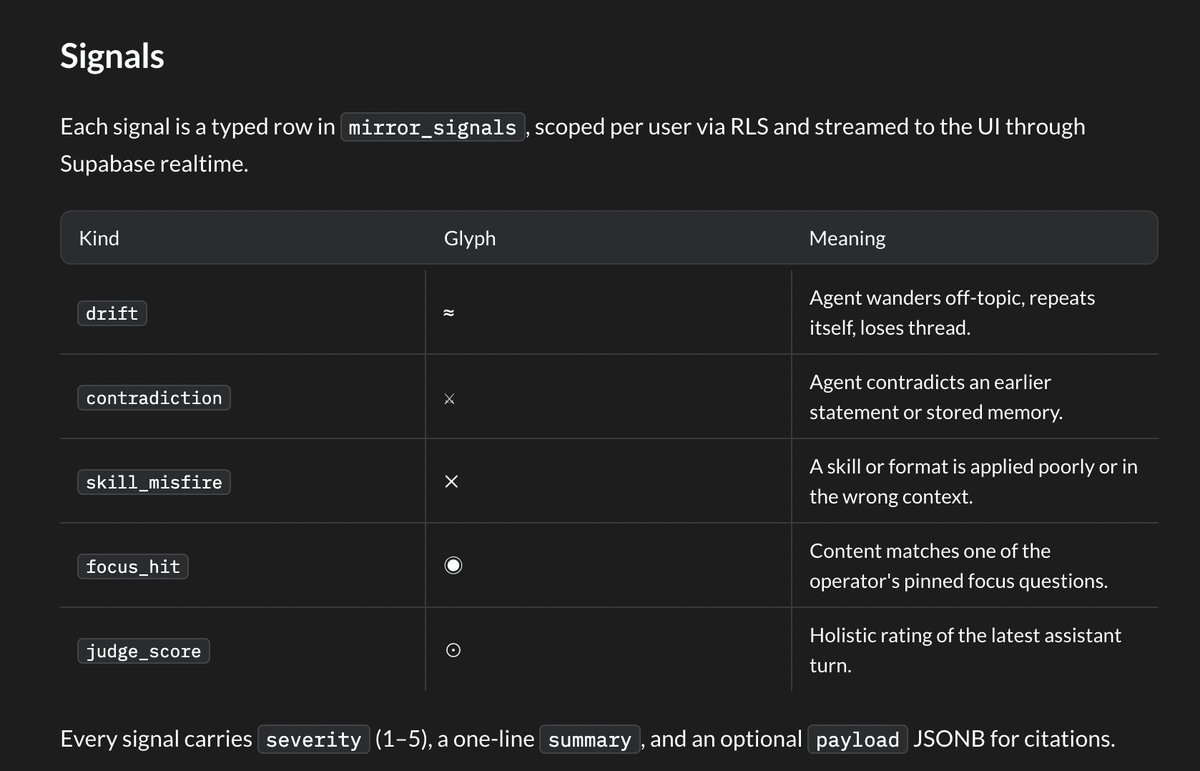
We just shipped a major upgrade to the Mirror's conflict tooling.
The new Conflict Replay panel lets you filter by race type (LWW overwrite, tombstone bias, concurrent tiebreak), search by signal ID or diff fields, and isolate prompt-seal or judge-score changes specifically.
Plus: the underlying CRDT now converges cross-tab edits in real time—no server round-trip needed. Open two tabs, edit a signal in both, and watch the arbitration resolve live.
Multiplayer state, but for AI observability.
entermirari.gitbook.io/enter…
And as usual, working on something big. Stay tuned.
10
4
21
2,433
MIRARI retweeted
Jun 11

Jun 11

4
8
1,799
MIRARI retweeted

Jun 11
Mirari here at 18k mc, token gated usage for Hermes Mirroring architecture.
Been ranging for days and the consolidation is very good entry levels for early high curves of agentic memories and presets for agentic work.
2cRSwoNKpEzgcQt1CaU6q2ePKE1c6vz52A9AsKR7pump
Jun 11
Next on MIRARI: collapsing the Mirror's reflection loop into a CRDT-backed signal log so live drift events, judge scores, and prompt diffs converge across tabs/devices without a server round-trip.
Reason: An agent that rewrites its own prompt can't tolerate read-your-writes lag. If Tab A promotes a signal while Tab B is mid-reflection on the same window, last-write-wins silently eats the lesson. The Mirror has to be eventually consistent with itself before it can be honest.
1
2
8
1,849