
Joined November 2009
- Tweets 53,297
- Following 669
- Followers 767,532
- Likes 44,289
32,842 Photos and videos











Pinned Tweet

27 May 2025
A new cover for SUPER AGERS after making the NYT bestseller list. Thanks to you for making it the #1 ranked new non-fiction book on Amazon.
amazon.com/gp/new-releases/b…

3
327
2,052
1,522,517
Eric Topol retweeted

KNICKS WIN!!!
KNICKS WIN!!!
KNICKS WIN!!!
KNICKS WIN!!!
801
9,935
52,432
919,958
16h
What if we could predict cancer 5 years ahead and prevent it? A new landmark study shows the way
8
100
350
30,406
16h
An outgrowth of high-throughput proteomics and extraordinary work by 80 researchers across 4 continents
erictopol.substack.com/p/a-n…
3
15
57
14,630
13h
what happens when you combine thousands of plasma proteins and AI?
1
4
33
7,643
Jun 12
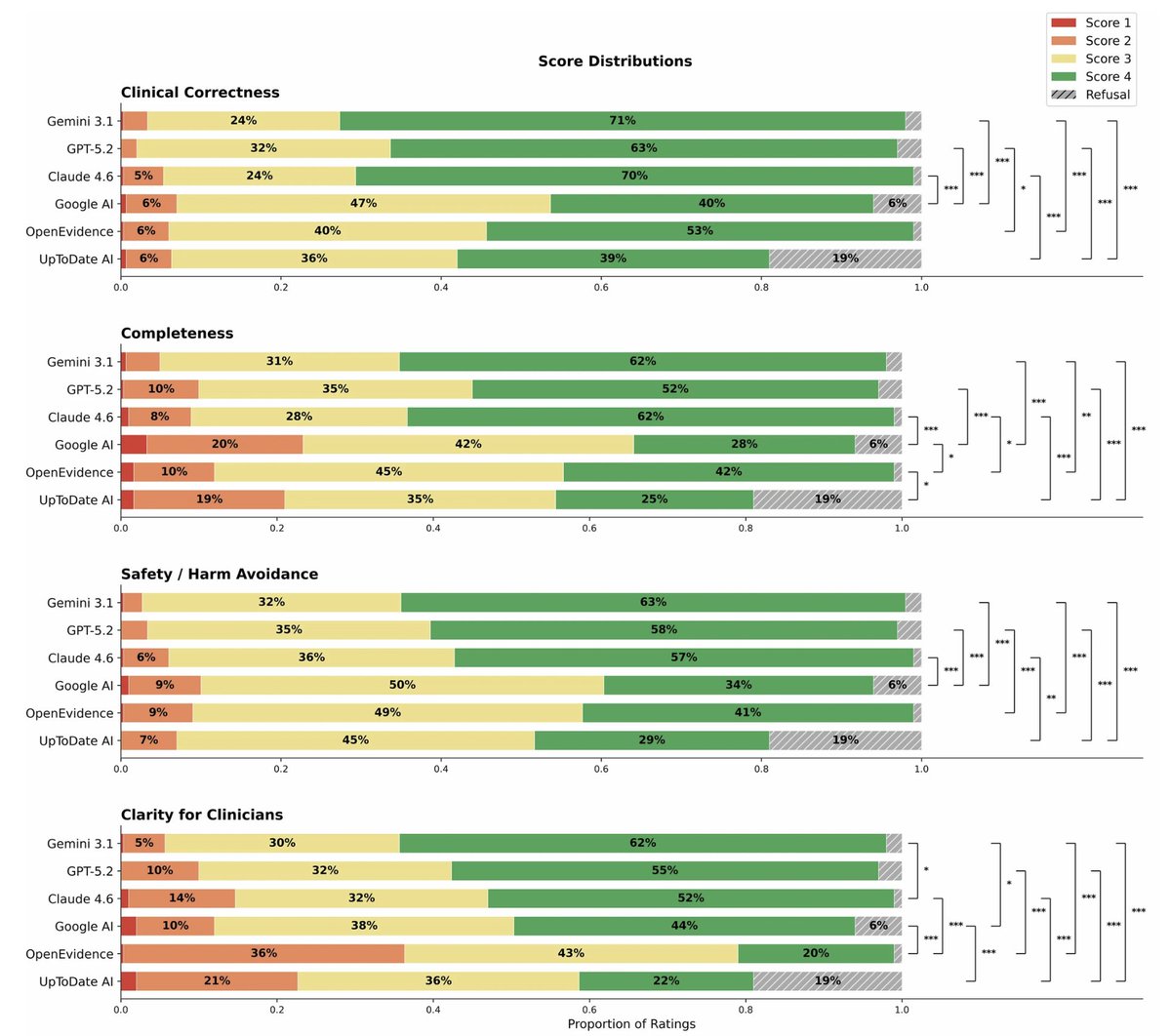
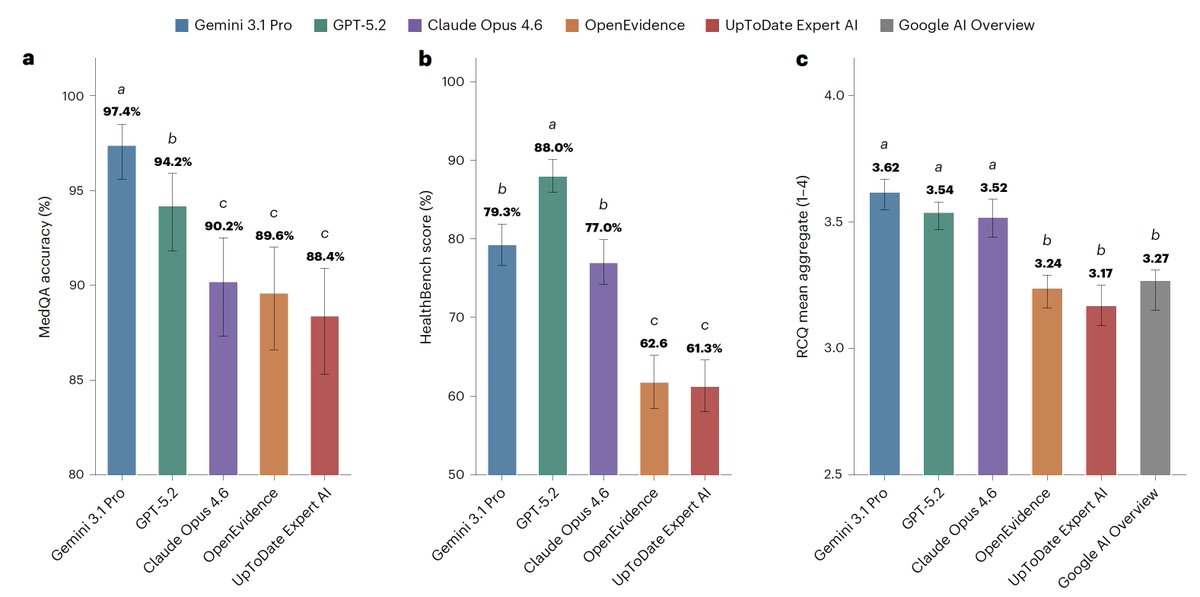
For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
113
490
1,805
664,231
Jun 12
Here is the performance breakdown for each model's blinded assessment for 4 major tasks: (1) clinical correctness, (2) completeness, (3) safety, and (4) clarity.
2
6
55
16,695
15h
The overall ranking.
Congratulations to @ekoermann @krithikvish and their team @nyulangone for getting this done. We need more of these rigorous assessments.
3
2
17
6,459
15h
A life-threatening inherited disease, hereditary angioedema, with striking benefit from one-shot CRISPR genome editing.
Phase 3 randomized, double-blind trial results @NEJM today
nejm.org/doi/full/10.1056/NE…
2
42
158
31,090
Jun 12
Getting to the root of age-related diseases. By studying a rare accelerated aging genetic disorder, gain-of-function mutations of DNMT3A were found to be causal.
DNA hyper-methylation was then linked to stem cells dysfunction and multiple age-related diseases (blood, bone, metabolic). Work in mice and humans. @NatureGenet
nature.com/articles/s41588-0…
7
32
182
20,065
Jun 12
Interleukin-17 (IL-17 and its receptor, IL7R) is emerging as a key mediator in many immune-related diseases. Today @SciImmunology a superb review
science.org/doi/10.1126/scii…
4
95
343
24,289
Eric Topol retweeted

Jun 12
There has been a push to use OpenEvidence AI for doctors. But this paper suggests general models are much better: “Frontier LLMs outperformed clinical AI tools in all three evaluations. Clinical AI tools performed comparably to auto-enabled Google Search AI Overview on the RCQ.”
Jun 12

For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
41
44
422
68,463
Eric Topol retweeted

Jun 12
Medicine discovers the bitter lesson: frontier LLMs (here GPT 5.2, Opus 4.6, Gemini 3.1) outperform specialized "clinical AI" (e.g. OpenEvidence) in a blind test.
Even funnier that hospital IT are more likely to approve the *specialized* versions despite them being worse.

Jun 12
For medical information, general AI frontier models (Google, OpenAI, Anthropic) outperformed specialized @EvidenceOpen and @UpToDate as assessed by 12 US clinicians, randomized and blinded to which model and extensive testing/benchmarks. This was not anticipated. @NatureMedicine
nature.com/articles/s41591-0…
30
166
1,147
180,054
Jun 11
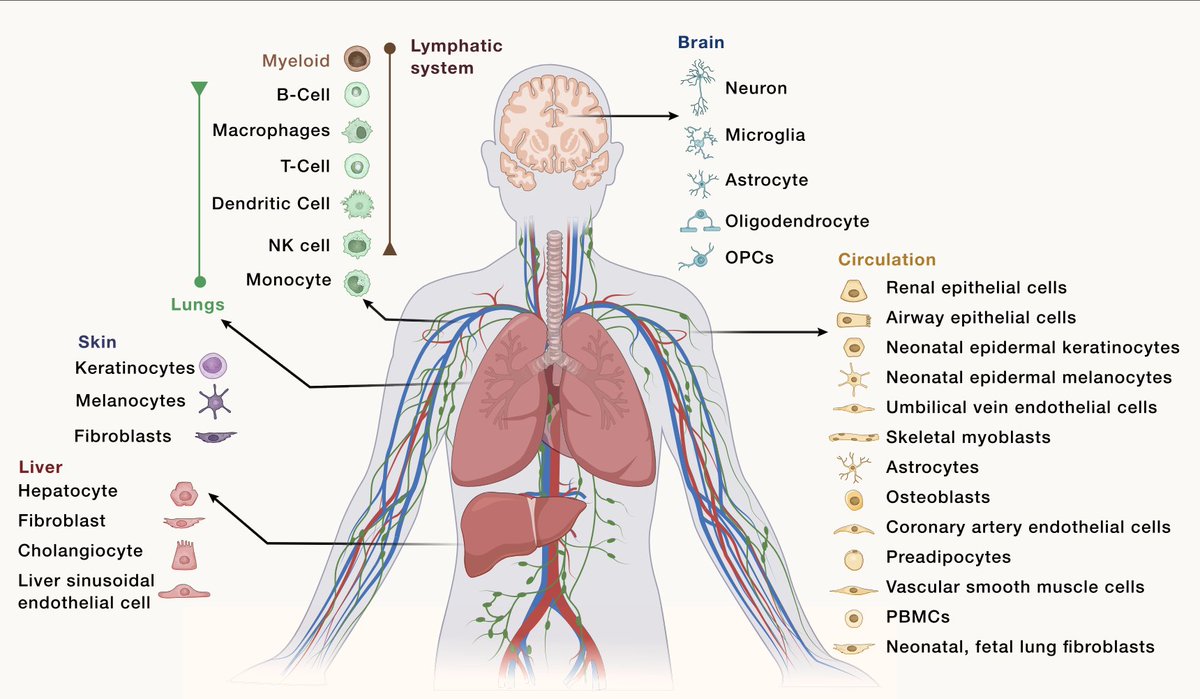
We're learning a lot about cellular senescence, how to track it, and its role in aging and disease. Cover and commentary @CellCellPress
cell.com/cell/fulltext/S0092…
9
69
274
24,631
Jun 11
Circulating senescent proteins and their prognostic value and an atlas of these cells
sciencedirect.com/science/ar…
linkinghub.elsevier.com/retr…

5
13
54
11,380
Jun 11
Workforce survival in healthcare
"The coming decade demands that we stop asking whether AI can replace clinicians and start asking how it can help us keep them."
thelancet.com/journals/lance…
12
52
168
16,349
Jun 10
Not every day you see an odds ratio of 50 (for interleukin-10 autoantibodies and a common HLA allele).
~80% of patients with inflammatory bowel disease (IBD) have this HLA allele
These individuals (~3.5% of IBD) may benefit from B cell depletion (such as achieved via CAR T).
nejm.org/doi/full/10.1056/NE…
nejm.org/doi/full/10.1056/NE…
9
98
432
39,477
Jun 10
The cerebellum has long been considered spared from being tied to cognitive resilience and Alzheimer's disease. That turned out to be wrong @NatureNeuro
nature.com/articles/s41593-0…
6
50
206
21,754