
EVAL SYS is a continuously evolving, open-source community! We are on a mission to track and advance model agentic capabilities.
Joined August 2025
- Tweets 24
- Following 6
- Followers 242
- Likes 64
9 Photos and videos





Pinned Tweet

Jun 12
MCPMark Verified is live ✅
Independently benchmarked, reproducible MCP agent performance.
And the first Verified result is in 🎉
Congrats @Kimi_Moonshot
K2.7-Code — Ranked #2 at 81.1%
8.3pts over K2.6 · Ahead of Claude Opus 4.8 max
Open-source code models are closing in 💪
Jun 12

🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced!
🔷 Improved coding & agent performance over K2.6: 21.8% on Kimi Code Bench v2, 11.0% on Program Bench, and 31.5% on MLS Bench Lite.
🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6.
🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates.
⚡️ 6x High-Speed Mode coming soon!
🔌 Available today via Kimi API and Kimi Code.
🔗 Kimi Code: kimi.com/code
🔗 API: platform.moonshot.ai


2
1
7
6,797
8 Dec 2025
MCPMark Leaderboard Update 🚀
🌟 DeepSeek-V3.2-thinking jumps to the #1 spot among open-source models — and we’re honored to see MCPMark cited in the @deepseek_ai technical report.
⚡️ Gemini 3 Pro High @GoogleDeepMind now leads with the highest pass@1 and pass@4 success rates.
This update brings two newly released models onto the leaderboard: Gemini 3 and DeepSeek V3-2.

2
8
12
1,542
8 Dec 2025
💻 Code & Community: github.com/eval-sys/mcpmark
🌐 Website: mcpmark.ai
📄 Paper: arxiv.org/pdf/2509.24002
2
165
8 Dec 2025
Huge thanks to @m4rkmc for the contributions to the community 🙌
– Added the Gemini 3 model name
– Upgraded to LiteLLM 1.80 (with support for passing thought signatures)
– Implemented forwarding of thought_signatures, which this model specifically requires
8 Dec 2025

MCPMark Leaderboard Update 🚀
🌟 DeepSeek-V3.2-thinking jumps to the #1 spot among open-source models — and we’re honored to see MCPMark cited in the @deepseek_ai technical report.
⚡️ Gemini 3 Pro High @GoogleDeepMind now leads with the highest pass@1 and pass@4 success rates.
This update brings two newly released models onto the leaderboard: Gemini 3 and DeepSeek V3-2.
1
1
3
445
1 Oct 2025
Proud to share our first research paper!
MCPMark stress-tested Model with MCP servers with 127 CRUD tasks × 5 MCPs × 30 models.
Key findings:
🔸 GPT-5 leads at 52.56% pass@1
🔸 Claude-sonnet-4.5 reaches 32.1%
🔸 The 30% barrier shows MCP workflows remain challenging even for top models
Open research: paper, code, trajectory explorer leaderboard expanding to agent submissions soon.
Excited for what the community builds next! 🚀
1 Oct 2025

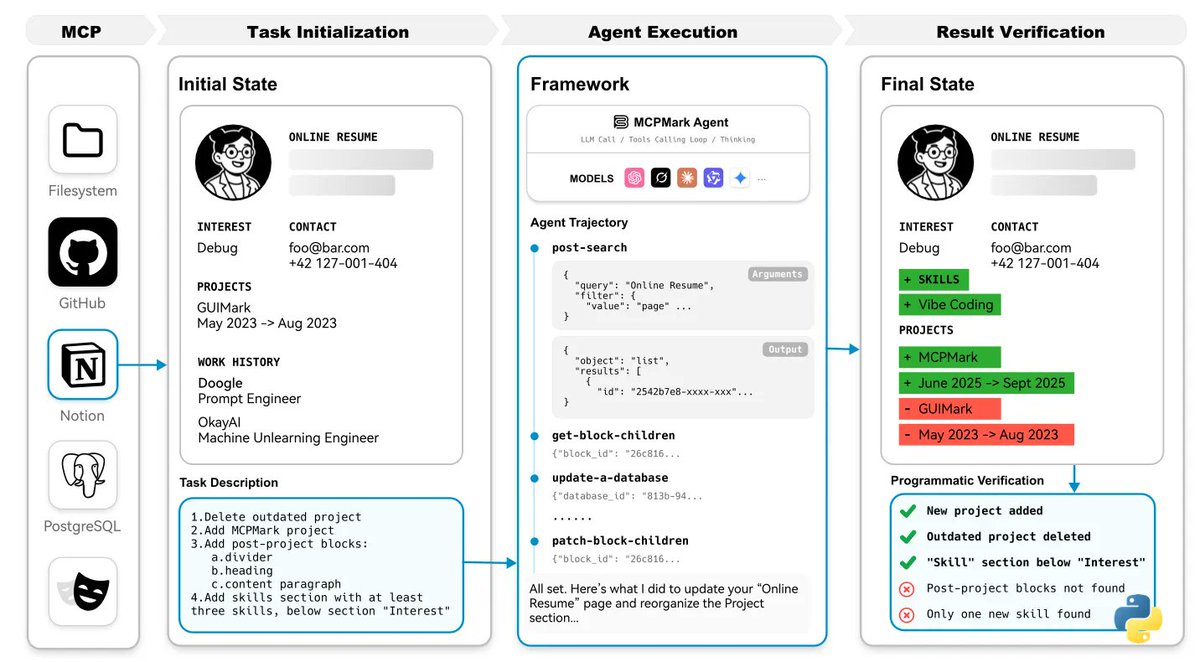
Your agent can call tools; can it close the loop ?
We stress-tested MCP with 127 CRUD-heavy tasks across 5 MCPs and >30 models, using a minimal but general MCPMark-Agent for fair comparison.
📄 Paper: arxiv.org/pdf/2509.24002
🌐 Website: mcpmark.ai/
💻 Code: github.com/eval-sys/mcpmark
🤗 Daily Papers: huggingface.co/papers/2509.2…
GPT-5 reaches 52.56% pass@1 and 33.86% pass^4, yet widely regarded strong models such as claude-sonnet-4 and o3 remain below 30% pass@1 and 15% pass^4. The newest Claude-sonnet-4.5 improves to 32.1% pass@1 and 16.5% pass^4 — just crossing the 30% line.
The full report dives into data distributions, failure modes, and case studies (PASS vs FAIL). Plus trajectory explorer to debug agents yourself.
👉 Our leaderboard already tracks by models and MCP servers, and will soon support agent submissions — we welcome the community to submit results!
Key insights in thread ⬇️
1
2
5
663
22 Sep 2025
Congrats on the launch of Strata! Thrilled that @Klavis_AI chose MCPMark. 🚀
MCPMark now benchmarks not only model agentic performance, but also MCP Services and frameworks. Can’t wait to see what the community builds next — and always open to partnership!
22 Sep 2025

AI agents fail when given too many tools - a lesson from our work on tool use at Google Gemini.
So we're launching Strata: one MCP server for AI agents to handle thousands of tools progressively.
The Result? A 13% success rate boost on benchmarks & 83% accuracy on human eval.
klavis.ai
2
6
861
9 Sep 2025
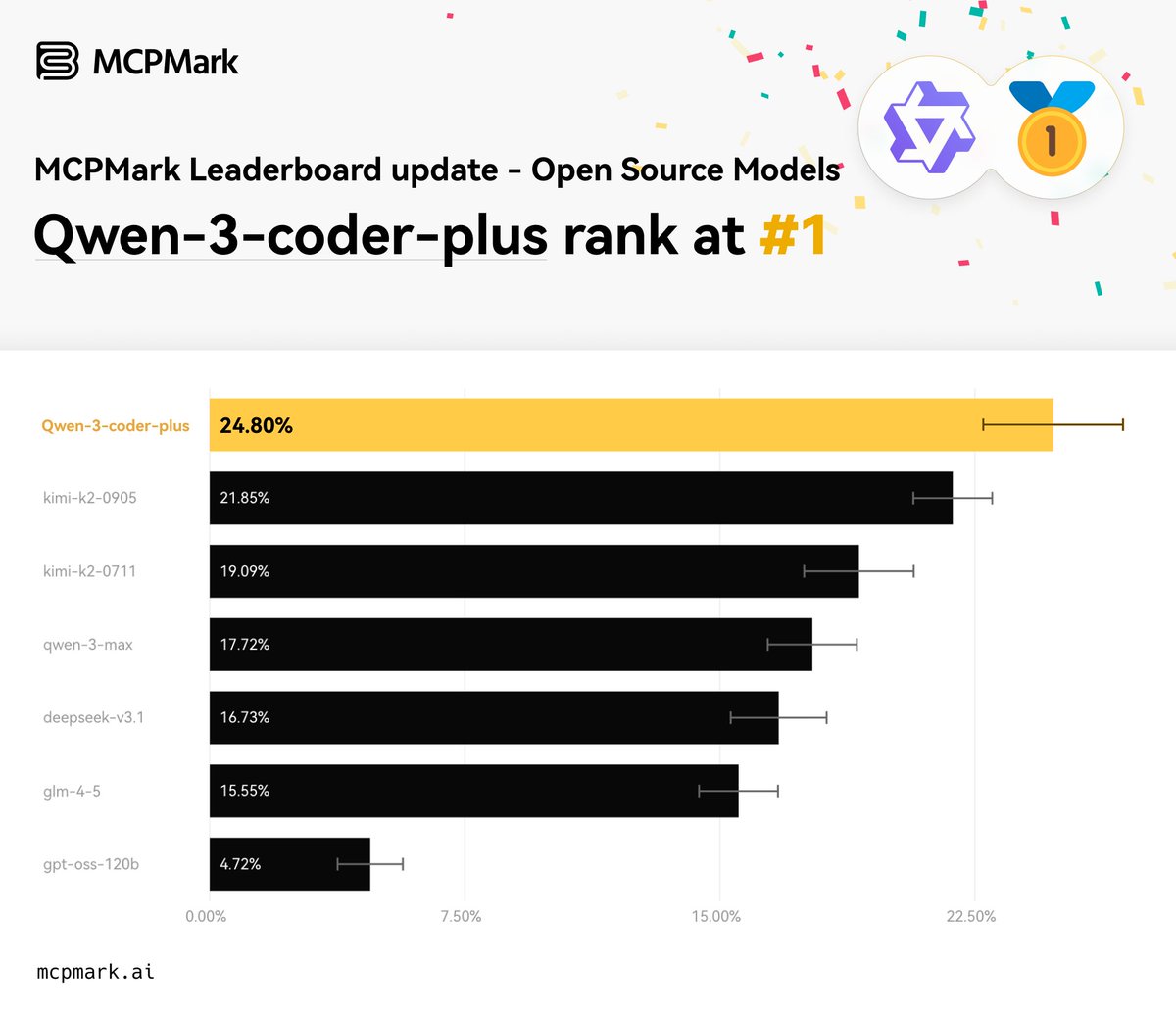
MCPMark Leaderboard Update 🚀
🌟 Qwen-3-Coder takes the #1 spot among open-source models, with an impressive per-run cost of just $36.46.
⚡️ Grok-Code-Fast-1 delivers the lowest per-run cost ($16.08) and the fastest average agent time (156.63s) across the top 10 models.
Kimi-K2-0905 outperforms Kimi2 in success rate, though at nearly double the per-run cost and average agent time.
Notably, Qwen-3-Coder achieves a success rate close to O3, but at roughly one-third the per-run cost — offering the community a highly cost-effective option for MCP tool-use applications.
This update introduces three newly released models to the leaderboard: Qwen-3-Max, Grok-Code-Fast-1, and Kimi-K2-0905.

5
21
133
94,735
9 Sep 2025
We're always looking for contributors in community! Check out more detail here:
Github:github.com/eval-sys/mcpmark
Website:mcpmark.ai
4
2,126
28 Aug 2025
🚀 MCPMark website updated! → mcpmark.ai/
On MCPMark, you can now dive into each task’s description, verification, and model performance. We’ve also added model trajectories to each task leaderboard, so you can clearly see how models execute step by step.
Many users found this super helpful for understanding models better—some even spent the whole afternoon exploring it.
💡 Feedback is always welcome—stay tuned for more updates!
👍 Big thanks to @arvinxu95 for the brilliant UX design and feature delivery!
4
1,587
Eval Sys retweeted

26 Aug 2025
We believe MCP servers are shaping the future of software. That’s why we built MCP Mark: a live benchmark for model mastery in real-world MCP use.
Amazing experience collaborating with great friends & building community—EvalSys will keep driving meaningful work for the community!
25 Aug 2025
The first EvalSys initiative, in amazing collaboration with NUS TRAIL @michaelqshieh and @lobehub !
• 127 challenging real-world tasks, 2-3 expert hours each, pass@1 <30% (except GPT-5)
• Solid engineering effort on environment isolation and state tracking
More insights soon—stay tuned!
3
6
1,118
Eval Sys retweeted

26 Aug 2025
Excellent eval, and open weight models holding ground 🙌
25 Aug 2025
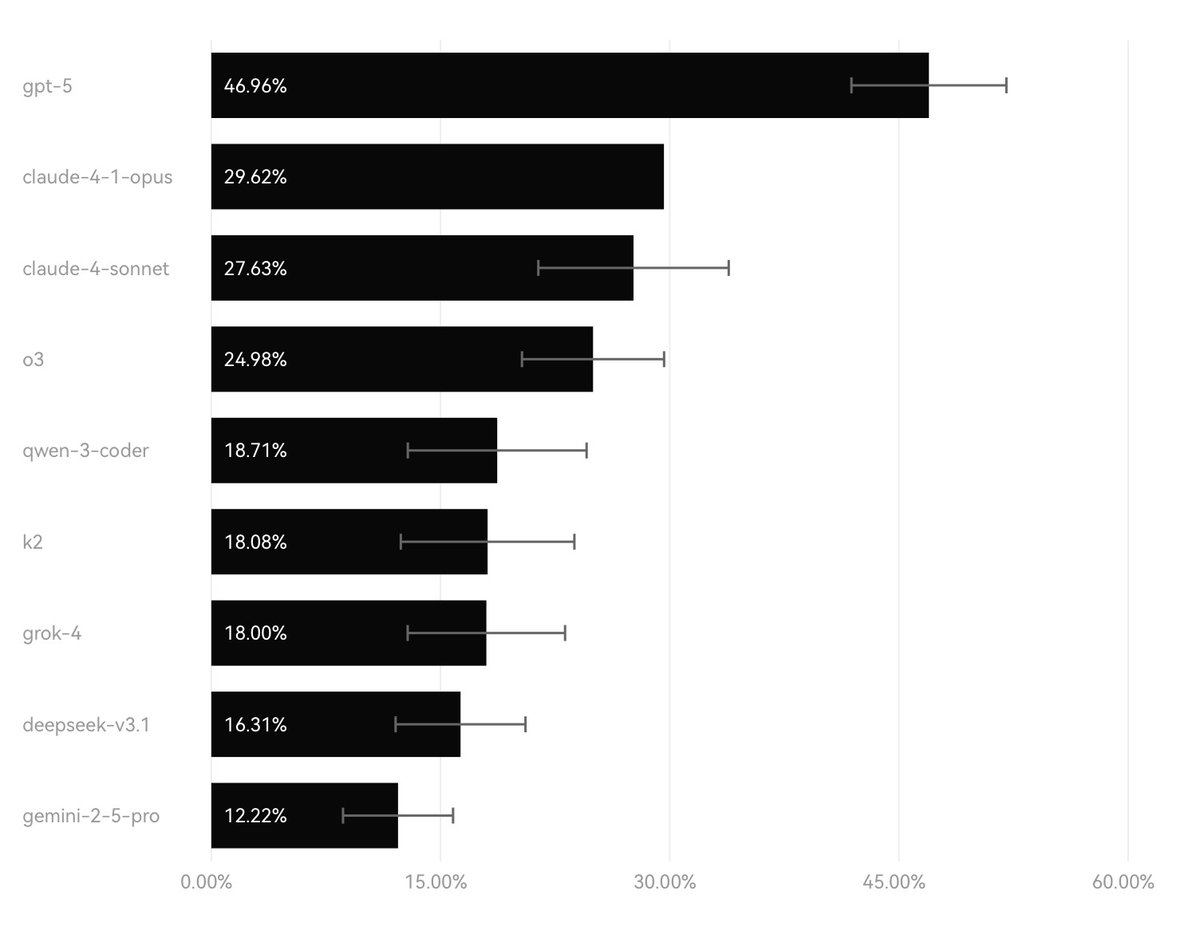
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
2
3
1,183

1/8) Excited to launch MCPMark (mcpmark.ai) today with NUS TRAIL and @EvalSysOrg! 🥳
It’s a high‑quality, program‑verifiable benchmark for MCP (Model Context Protocol) — designed to measure model's agentic capability & stability in MCP Use.
Not another “lab” benchmark — this one reflects the messy reality of production.
#MCP #LLM #Benchmark
25 Aug 2025
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
1
7
12
2,498
Eval Sys retweeted

26 Aug 2025
🚀 🚀Just launched MCPMark, a challenging MCP benchmark I participated in. Its filesystem section include ops on files, structure exploration, reasoning, and multi-skill tasks. Most models show clear room for improvement, while GPT series excel in precise text manipulation
25 Aug 2025
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
2
7
822
Eval Sys retweeted

26 Aug 2025
Excited to be part of @EvalSysOrg and contribute to our debut milestone, MCPMark! Follow us for updates, and come join the team—we’re just getting started!
Github:
github.com/eval-sys/mcpmark
Website:
mcpmark.ai/
Huggingface trajectory log:
huggingface.co/datasets/Jaku…
25 Aug 2025
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
4
15
1,465
Eval Sys retweeted

26 Aug 2025
Sharing some of my thoughts when developing, hope they can help 👇
1/ Choosing the initial state defines task diversity, difficulty, and usefulness.
2/ State tracking and management is the trickiest stage. Each MCP needs its own isolation strategy. Worth it though: sandboxing lets agents CRUD freely instead of being stuck read-only.
3/ In many MCP use cases, top agents (esp. Claude Code) outperform humans. That's why we design human-agent workflows to co-create tasks🤓.
4/ GUI may feel more human-friendly, but MCP seems like the closest path to AGI right now.
25 Aug 2025
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
5
11
1,496
Eval Sys retweeted

25 Aug 2025
Thrilled to see MCPMark officially live! 🚀
@AnthropicAI's vision for MCP — a universal, open standard for AI integrations — is summed up perfectly by the “USB‑C port for AI” analogy: a single, reliable connector that lets LLMs access tools and data seamlessly. 
With MCPMark, we turned that vision into a concrete benchmark, stress‑testing models across diverse MCP workflows — including filesystem, GitHub, Notion, Playwright, and Postgres. We absolutely went all in; it was an intense journey, and I’m immensely proud of what our team has built.
Here’s to pushing LLMs ever closer to becoming tool‑aware, context‑rich AI systems! ✨
25 Aug 2025
Introducing MCPMark, a collaboration with @EvalSysOrg and @lobehub!
We created a challenging benchmark to stress-test MCP use in comprehensive contexts.
- 127 high-quality data samples created by experts.
- GPT-5 takes the current lead and achieves a Pass@1 of 46.96% while the other models fall in the range of 10-30%.
- Diverse test cases on Notion, Github, Filesystem, Playwright (browser), and Postgres.
9🧵s ahead
3
18
1,439