
Joined February 2020
- Tweets 2,257
- Following 211
- Followers 2,530
- Likes 1,207
541 Photos and videos


Pinned Tweet

9 Dec 2024
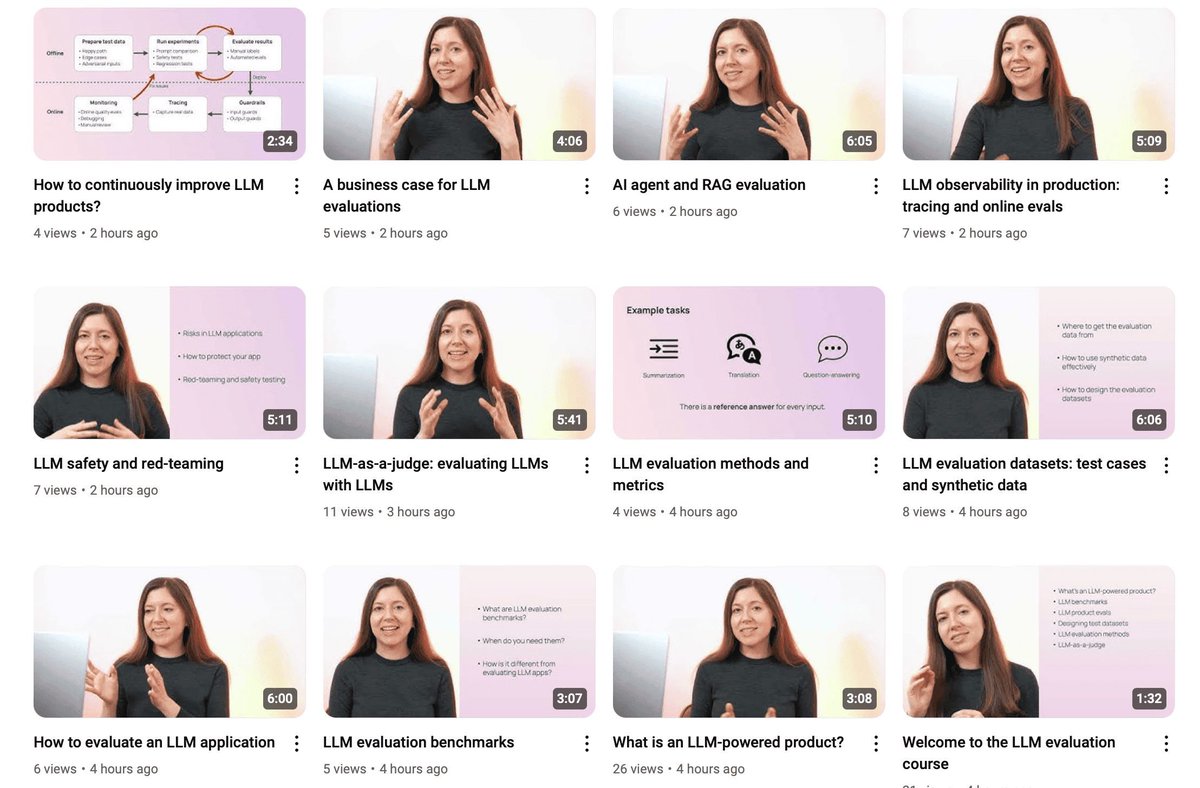
3️⃣ 2️⃣ 1️⃣ Our free course on LLM evaluations for AI product teams starts today!
🎥 7 days of byte-sized videos into your inbox
⭐️ Certificate upon completion
👩💻 No coding skills required
👩🎓500 students have signed up
You can still join the course👇
evidentlyai.com/llm-evaluati…
3
1
7
1,813
Apr 24
How Zalando builds a search quality assurance framework with LLM-as-a-judge:
engineering.zalando.com/post…
96
Apr 4
📌 In case you missed it
How to evaluate an AI agent?
Follow the tutorial as we:
1️⃣ Build an AI agent,
2️⃣ Create a test dataset,
3️⃣ Assess responses and tool choice,
4️⃣ Track the agent’s behaviour.
Follow the tutorial from our LLM evals course: youtube.com/watch?v=9KMmadw7…
1
176
Apr 3
A Friday ML use case 📕
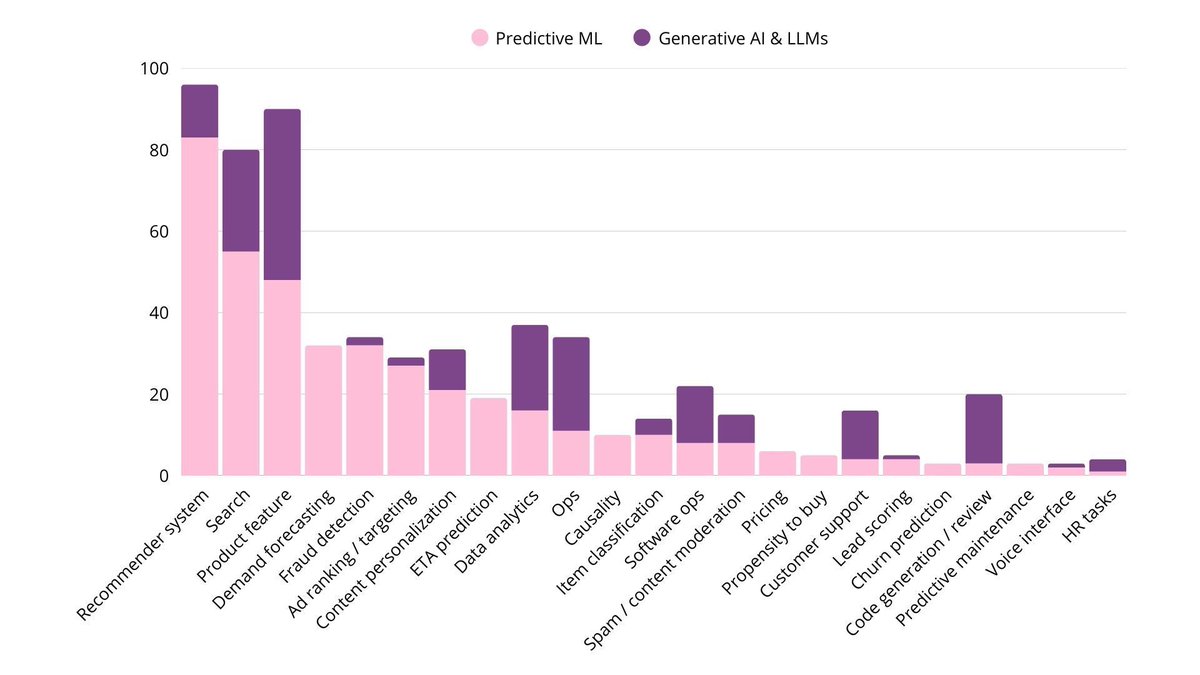
📚 From the database of 800 ML & LLM systems: cutt.ly/SwrZWL0g
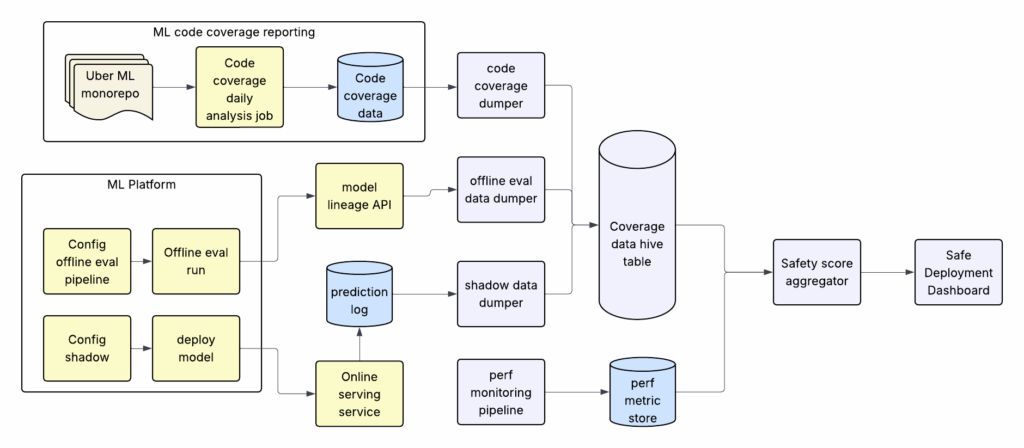
How Uber improves driver availability at airports: Estimated time-to-request model, Earnings-per-hour prediction, and Driver-deficit forecasting.
uber.com/en-GB/blog/forecast…
131
Apr 1
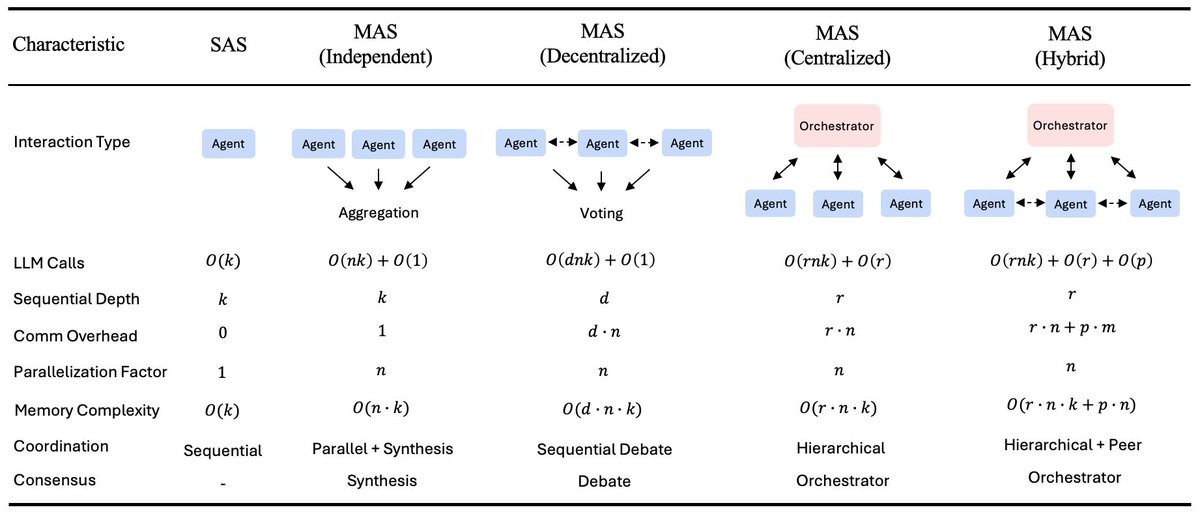
🦾 More AI agents aren’t always better.
Google evaluated 180 agent setups and found multi-agent systems help with parallel tasks but can hurt sequential ones.
The work also proposes a model to predict optimal agentic designs.
research.google/blog/towards…
1
94
Mar 28
📌 In case you missed it
Let’s test your RAG system!
Follow the tutorial as we:
1️⃣ Build a RAG system,
2️⃣ Generate test data,
3️⃣ Evaluate answers for correctness and faithfulness.
Watch the tutorial from our LLM evals course: youtube.com/watch?v=jckp5R09…
123
Mar 27
A Friday ML use case 📕
📚 From the database of 800 ML & LLM systems: cutt.ly/SwrZWL0g
How GoDaddy built Lighthouse, an internal AI analytics platform: prompt engineering framework, model orchestration, solution architecture, and use cases.
godaddy.com/resources/news/h…
74
Evidently AI retweeted

Mar 24
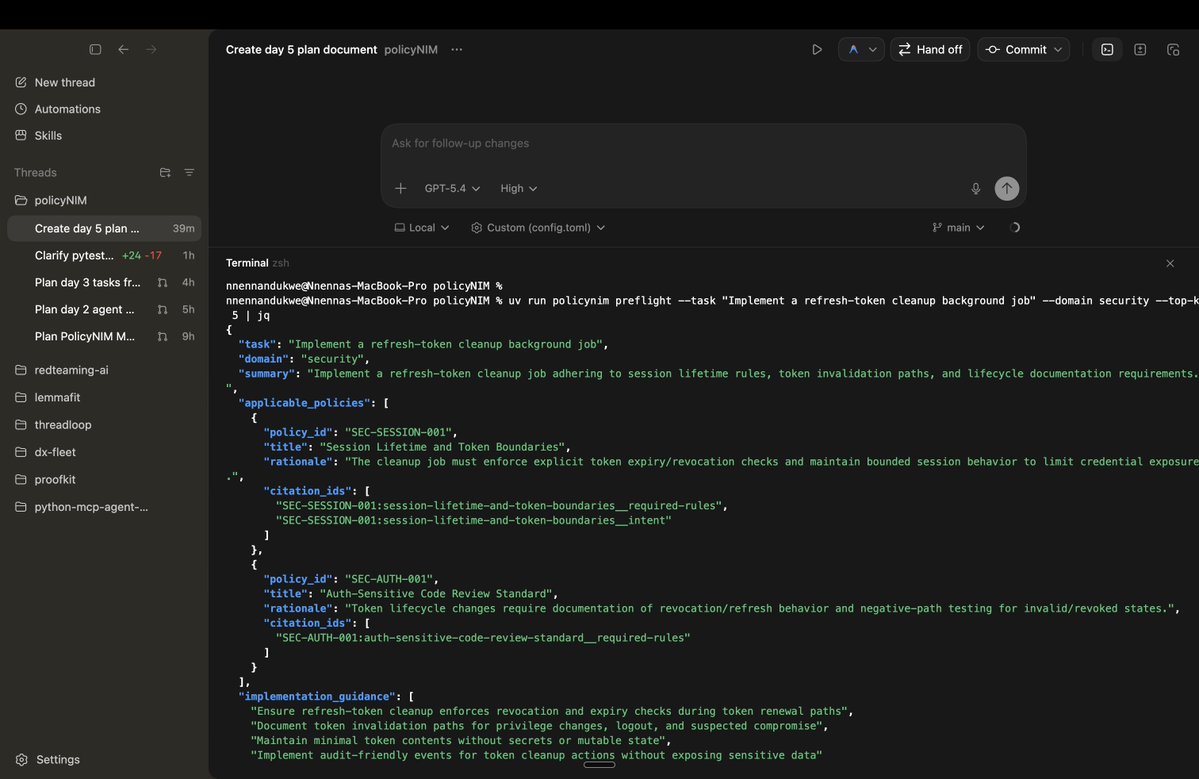
(policyNIM oss tool)
preflight command is working. when I provide a coding task, it kicks off a search through indexed policies to determine which rules are relevant for implementation.
@nvidia for embedding w/ @OpenAI @lancedb for vector storage.
eval command is also working. using @EvidentlyAI for running eval suite.

1
2
4
429
Mar 24
🚦 Meta’s “Agents Rule of Two”
According to Meta, AI agents should satisfy at most two of these conditions per session to reduce prompt-injection risk:
- Handle untrusted inputs
- Access sensitive data
- Change state / act externally
ai.meta.com/blog/practical-a…
50
Mar 21
📌 In case you missed it
How do you know if your RAG works?
You need to check:
✅ Can it find the right information?
✅ Is the final answer complete, relevant, and free of hallucinations?
Watch the intro to RAG evaluation from our LLM evals course: youtube.com/watch?v=qI2qQfOG…
1
166
Mar 20
A Friday ML use case 📕
📚 From the database of 800 ML & LLM systems: cutt.ly/SwrZWL0g
How DoorDash improves its RecSys using LLMs to bridge behavioral silos in multi-vertical recommendations.
careersatdoordash.com/blog/d…
61
Mar 18
💭 Can AI systems introspect?
Anthropic’s new research suggests Claude models can sometimes identify and describe their own internal states.
It’s still unreliable, but marks a step toward more transparent AI reasoning.
anthropic.com/research/intro…
48
Mar 14
📌 In case you missed it
Can LLMs write engaging tech tweets?
Follow the tutorial as we:
1️⃣ Build a tweet generator,
2️⃣ Score its outputs with custom LLM judges,
3️⃣ Improve the results with prompt iteration.
Watch the tutorial from our LLM evals course: youtube.com/watch?v=KhkiM9C0…
1
2
176
Mar 13
A Friday ML use case 📕
📚 From the database of 800 ML & LLM systems: cutt.ly/SwrZWL0g
How Shopify transformed its product classification system from basic categorization to an AI-driven framework using Vision Language Models.
shopify.engineering/evolutio…
1
2
71
Mar 10
📚 Context is everything.
OpenAI shares how it built an in-house data agent that answers complex questions in minutes.
It uses 6 layers of context:
- Table metadata
- Human annotations
- Codex enrichment
- Company knowledge
- Memory
- Runtime context
openai.com/index/inside-our-…
1
113
Mar 7
📌 In case you missed it
Are LLMs good for classification tasks?
We built an LLM-based classifier for a travel support chatbot and compared its performance to a classic ML model.
Watch the tutorial from our LLM evals course: youtube.com/watch?v=Gl2X_o99…
1
2
156
Mar 6
A Friday ML use case 📕
📚 From the database of 800 ML & LLM systems: cutt.ly/SwrZWL0g
How Wayfair built Wilma, a customer service agent copilot: workflow, prompt templates, and the copilot’s evolution.
aboutwayfair.com/careers/tec…
83
Mar 4
🤖 How to develop and deploy chatbots at scale?
DoorDash shares how they created a simulation platform and evaluation flywheel, allowing them to test chatbots with fast feedback loops and without production risk.
careersatdoordash.com/blog/d…
1
1
60
Feb 28
📌 In case you missed it
How to create an LLM judge that aligns with human labels:
- Define criteria
- Create test dataset
- Run evaluation prompt to see if the judge aligns with your labels
- Evaluate the judge
Watch the video from our LLM evals course: youtube.com/watch?v=kP_aaFnX…
1
1
169
Feb 27
A Friday ML use case 📕
📚 From the database of 800 ML & LLM systems: cutt.ly/SwrZWL0g
How Wayfair uses AI agents to automatically triage support tickets: agents vs. workflows and a hybrid approach.
aboutwayfair.com/careers/tec…
81
Feb 24
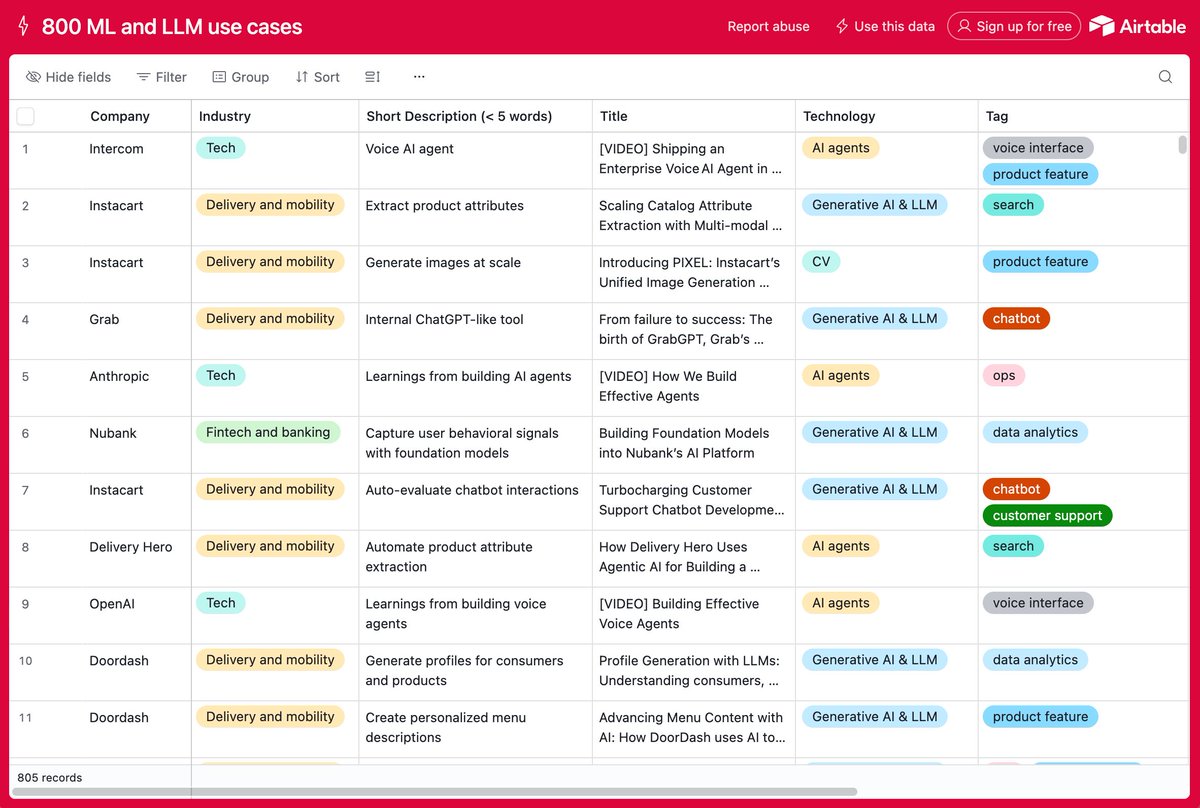
🔎 Scaling catalog attribute extraction with multi-modal LLMs
Instacart shares how it built PARSE, a self-serve multi-modal LLM platform for structured product attribute extraction from text and images at scale 👇
tech.instacart.com/multi-mod…
1
2
122