
Developer-friendly, open source AI-Native Multimodal Lakehouse github.com/lancedb/lancedb
Joined April 2023
- Tweets 1,027
- Following 64
- Followers 4,351
- Likes 507
308 Photos and videos











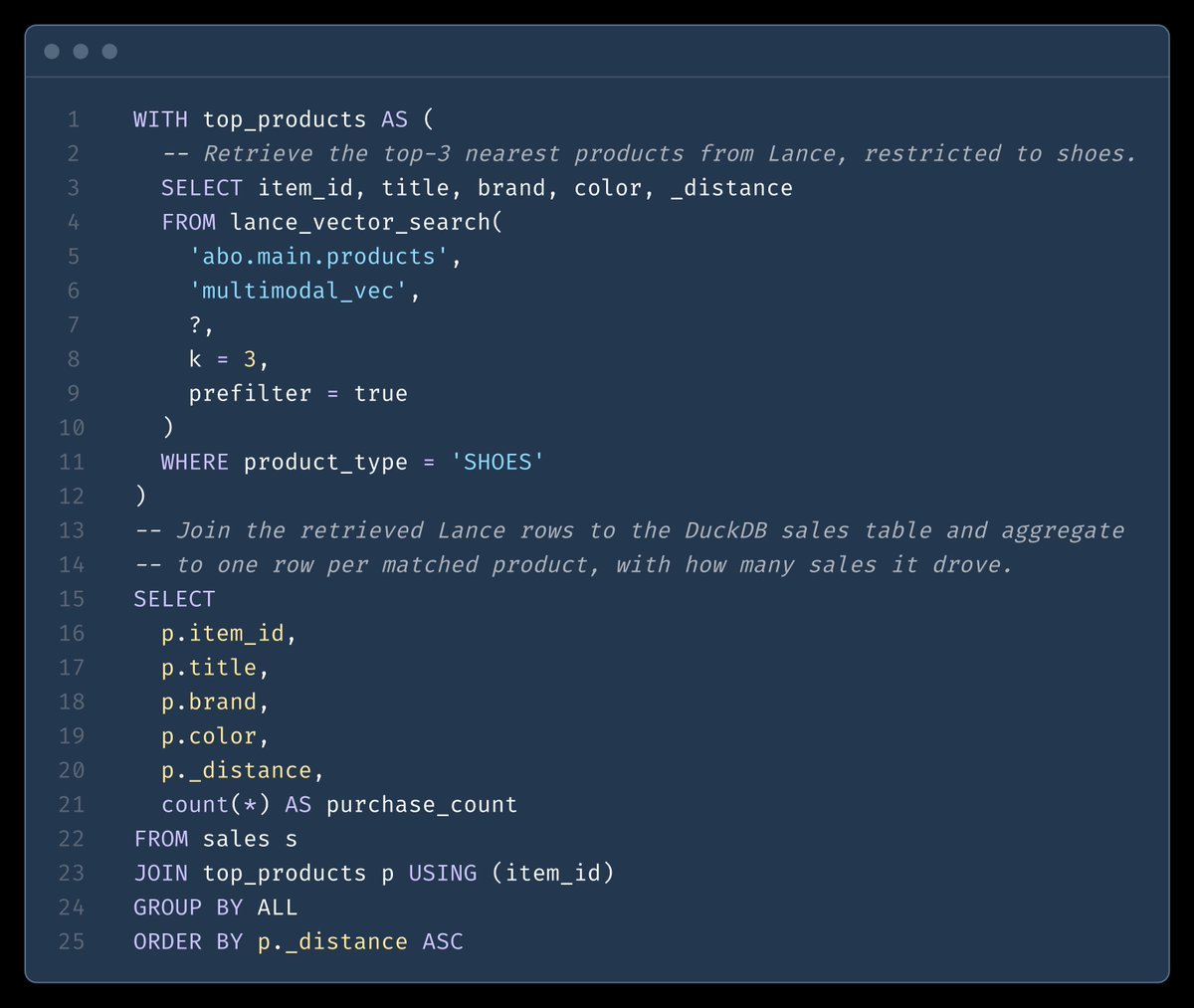





Most feature engineering pipelines rewrite the full table for every new column.
In Lance, adding a column writes only the new data. Blobs, embeddings, indexes untouched. Every write is a versioned commit.
That's data evolution.
🔗 lancedb.com/blog/scalable-fe…
3
16
753
2/ 𝗠𝗮𝗻𝗮𝗴𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 𝗮𝘁 𝗘𝘅𝗮𝗯𝘆𝘁𝗲 𝗦𝗰𝗮𝗹𝗲 𝗳𝗼𝗿 𝗔𝗜 𝗠𝗼𝗱𝗲𝗹 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴
The full exploration-to-GPU-loading path: why single-purpose tools force teams to copy data across systems for each workflow step, and how LanceDB collapses that into one table.
🔗 databricks.com/dataaisummit/…
1
2
416
3/ 𝗙𝗿𝗼𝗺 𝗦𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝘁𝗼 𝗦𝗲𝗮𝗿𝗰𝗵: 𝗛𝗼𝘄 𝗘𝘅𝗮 𝗨𝘀𝗲𝘀 𝗟𝗮𝗻𝗰𝗲 𝗮𝗻𝗱 𝗔𝗽𝗮𝗰𝗵𝗲 𝗦𝗽𝗮𝗿𝗸 𝗳𝗼𝗿 𝗛𝗶𝗴𝗵-𝗧𝗵𝗿𝗼𝘂𝗴𝗵𝗽𝘂𝘁 𝗔𝗜 𝗪𝗼𝗿𝗸𝗹𝗼𝗮𝗱𝘀
Joint session with @ExaAILabs where we walk through Exa's Spark Structured Streaming pipeline, ~10K rows/second into Lance, and how the same tables power their vector search.
🔗 databricks.com/dataaisummit/…
3
370
Prashanth Rao @tech_optimist and Sarwar Bhuiyan are running a workshop at TMLS on June 19.
𝗘𝗻𝗵𝗮𝗻𝗰𝗶𝗻𝗴 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 𝘄𝗶𝘁𝗵 𝗟𝗮𝗻𝗰𝗲 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗠𝘂𝗹𝘁𝗶𝗺𝗼𝗱𝗮𝗹 𝗟𝗮𝗸𝗲𝗵𝗼𝘂𝘀𝗲
They're covering Lance's architecture and what makes it suited for ML workloads (fast random access, native blob storage, built-in versioning), live PyTorch and Hugging Face integration examples, a 3D world-model dataset case study, and I/O benchmarks during data loading.
If you're managing multimodal training data at scale and your storage, search, and training layers are still three separate systems, this one's for you.
1
1
4
926
Conference Agenda 🔗 torontomachinelearning.com/a…
3
326

5/ Events:
Check out our 2 sessions at Data AI Summit by @databricks — June 15–18, San Francisco
- Managing Data at Exabyte Scale for AI Model Training
- From Streaming to Search: How Exa Uses Lance and Apache Spark for high-throughput AI Workloads

1
276
6/ More in May newsletter: lancedb.com/blog/newsletter-…
233
2/ The loader is URI-agnostic: local, s3://, gs://, hf://buckets/... all use identical code. @huggingface Buckets is first-class — Lance's fragment design and Buckets' chunk storage share deduplication primitives, so you get it for free.
1
3
6
2,114
3/ Train LeWorldModel with stable-worldmodel: lancedb.com/blog/stable-worl…
Thanks to @lucasmaes_, @quentinlldc, and @lhoestq for collaborating on this blog post!
4
366
Lei Xu is speaking at #SnowflakeSummit this Thursday alongside Vishwa Lakkundi (Sr. Manager, Snowflake) for 𝗔𝗽𝗮𝗰𝗵𝗲 𝗣𝗼𝗹𝗮𝗿𝗶𝘀 𝗶𝗻 𝗣𝗿𝗮𝗰𝘁𝗶𝗰𝗲: 𝗢𝗽𝗲𝗻 𝗖𝗮𝘁𝗮𝗹𝗼𝗴𝘀, 𝗢𝗽𝗲𝗻 𝗙𝗼𝗿𝗺𝗮𝘁𝘀, 𝗢𝗽𝗲𝗻 𝗖𝗼𝗺𝗺𝘂𝗻𝗶𝘁𝘆.
The session covers where the open catalog layer is heading. Lance is one of the formats Polaris now supports alongside Delta and Iceberg. The direction is one catalog spec that works across every engine and every format, multimodal included.
If you're at @Snowflake Summit and building on Lance or thinking about how your catalog layer handles multimodal data as the format mix expands beyond Iceberg, this is the session.
1
1
8
914
Cosmos 3 by @nvidia released today — a frontier omnimodal world model for Physical AI.
For the data infrastructure behind it, they built on Lance.
SILA, NVIDIA's internal curation platform, processes tens of billions of multimodal training candidates as a single Lance dataset. Curation signals, embeddings, and vector indexes all in one table. No separate vector DB.
One table from raw data to training-ready.
2
5
20
3,427
Full infrastructure section in @nvidia's Cosmos 3 technical report: research.nvidia.com/labs/cos…
1
333
2/ On LAION-1M, queried directly from the Hugging Face Hub:
→ 1.16M rows to 604K in a single SQL predicate chain
→ pHash catches ~25% near-duplicate clusters; CLIP-feature NN matching catches the rest
→ 95/5 stratified split, identical mean similarity (0.3318) across train and test
1
3
434
3/ Every write versions automatically. Tag the baseline, tighten the threshold, both versions stay on disk. Open v1 and you get exactly the 604K rows the original run trained on. Full code: lancedb.com/blog/reproducibl…
2
253