
Institute for Explainable Machine Learning @HelmholtzMunich and Interpretable and Reliable Machine Learning group @TU_Muenchen
Joined August 2021
- Tweets 311
- Following 100
- Followers 3,082
- Likes 187
110 Photos and videos






Explainable Machine Learning retweeted

May 27
A medical LLM can give the right answer for the wrong reasons.
Delighted our work is now published in Nature Communications Medicine — evaluating 8 LLMs on 1,269 unstructured seizure descriptions, with a practical guideline to use AI in clinical setup 🧵
doi.org/10.1038/s43856-026-0…
1
3
5
299

Happy to share that we have 3 papers accepted (one oral) at #CVPR2026, see you in Denver! Please see the thread for details👇
1
1
14
783
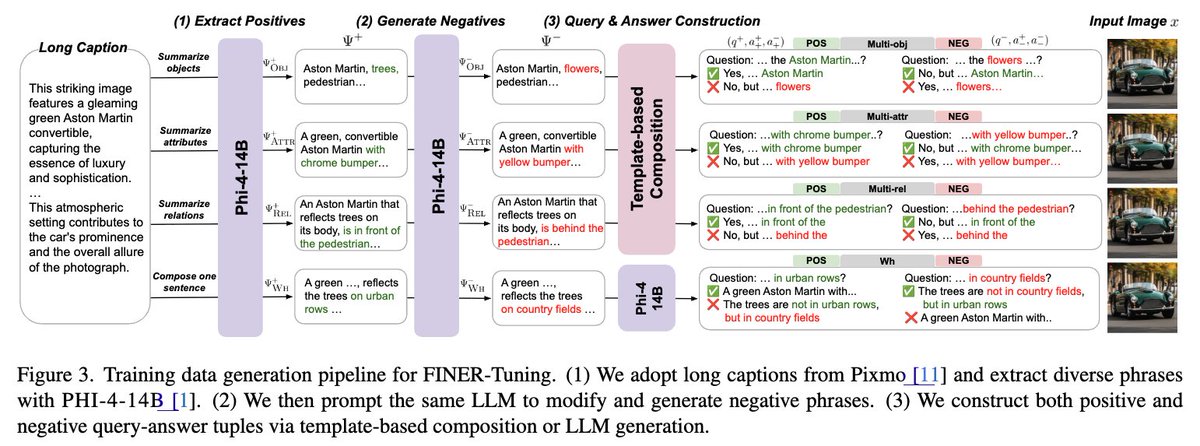
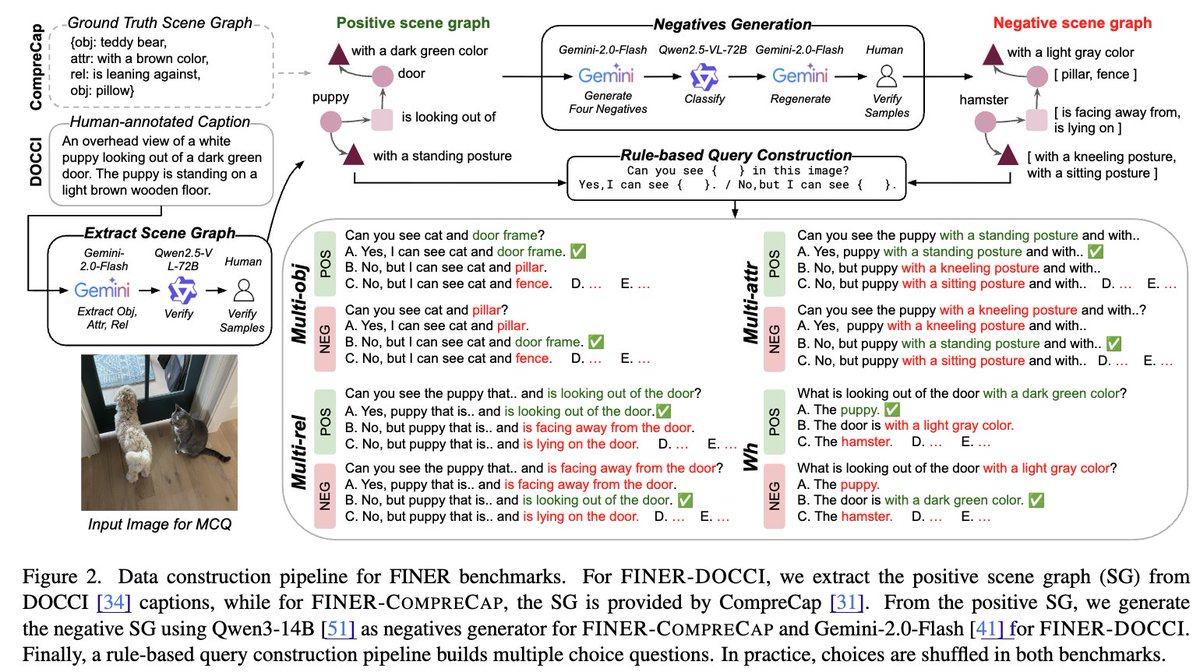
We also introduce FINER-Tuning: generate fine-grained positive/negative phrases from dense captions, turn them into accept/reject QA pairs, and train MLLMs with DPO so they learn to spot subtle mismatches instead of hallucinating.
1
125
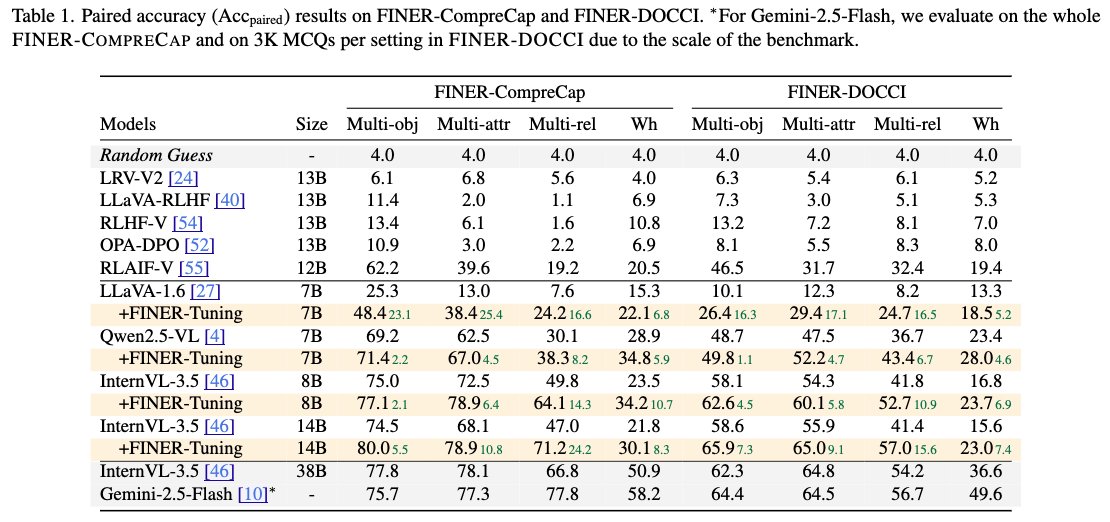
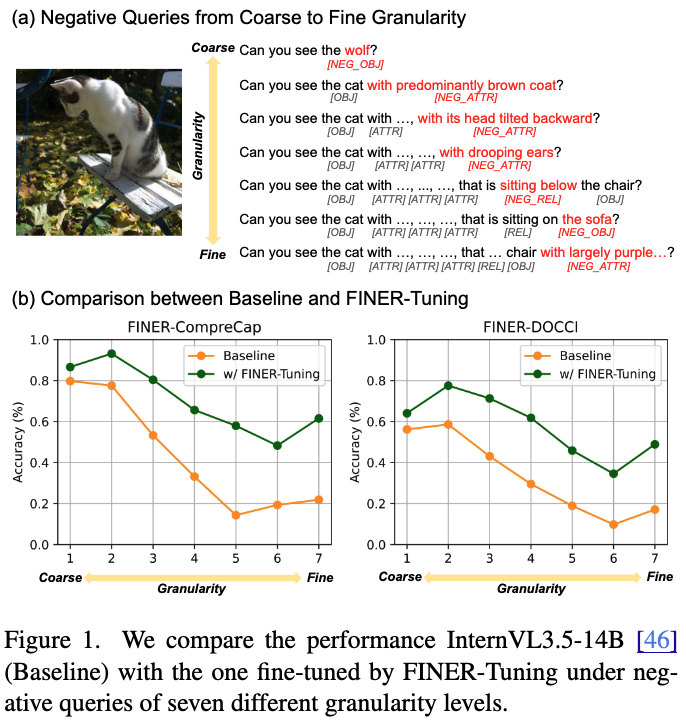
Results: FINER-Tuning improves performance on our FINER benchmarks, transfers to other hallucination benchmarks, and even boosts general MLLM ability. On InternVL3.5-14B, we get up to 24.2% on FINER without hurting overall capability.
109
Excited to share that our paper “Diamond Maps: Efficient Reward Alignment via Stochastic Flow Maps” won the Best Paper Award at the #ICLR2026 ReALM-GEN Workshop 🎉✨
Check out the paper & code 👇
📕 arxiv.org/abs/2602.05993
💻 github.com/PeterHolderrieth/…
1
4
25
2,030
Explainable Machine Learning retweeted

Apr 22
Accurate reward guidance in diffusion models has been a long-standing challenge.
We propose Diamond Maps 💎, through stochastic flow maps we make reward guidance both accurate and scalable.
5
22
165
8,123
Our EML members are heading for Rio🇧🇷 for #ICLR2026! 🌴We’re excited to share our latest research — three poster presentations. Check out the thread below and come say hi to our authors
1
4
22
1,115
2/
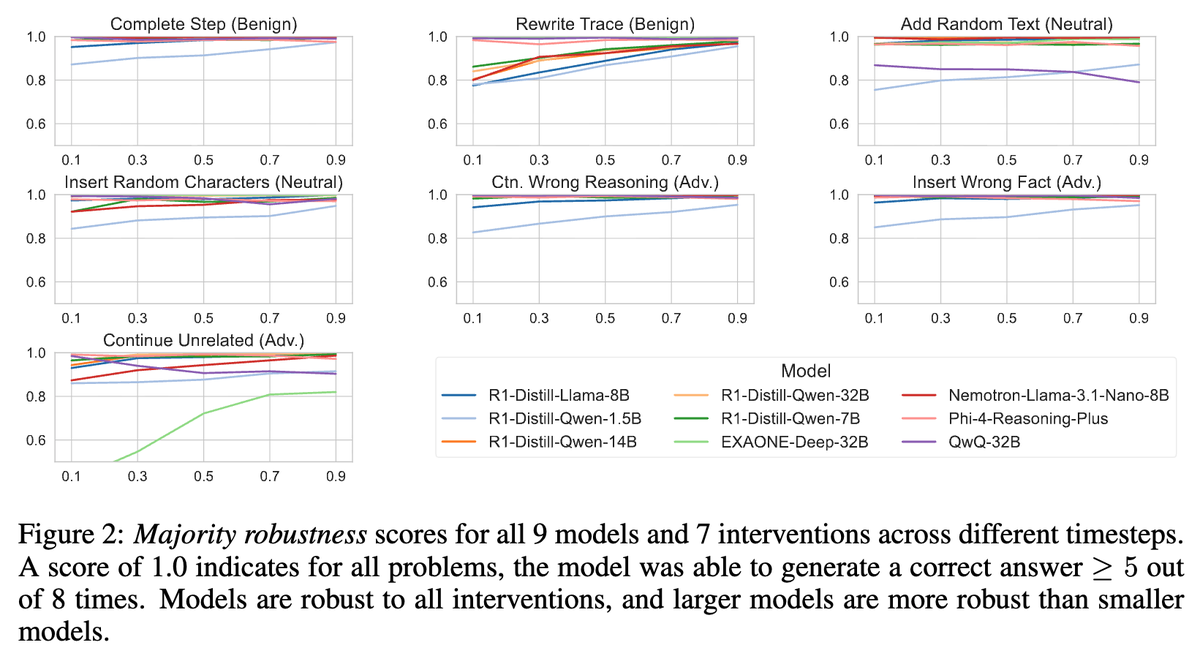
Are Reasoning LLMS Robust to Interventions on Their Chain-of-thought?
@avrecum, Leander Girrbach, @zeynepakata
[Paper]: arxiv.org/pdf/2602.07470
🕑 Fri, Apr 24, 2026 • 6:30 AM – 9:00 AM PDT
🚩Pavilion 3 P3-#918
1
1
1
182
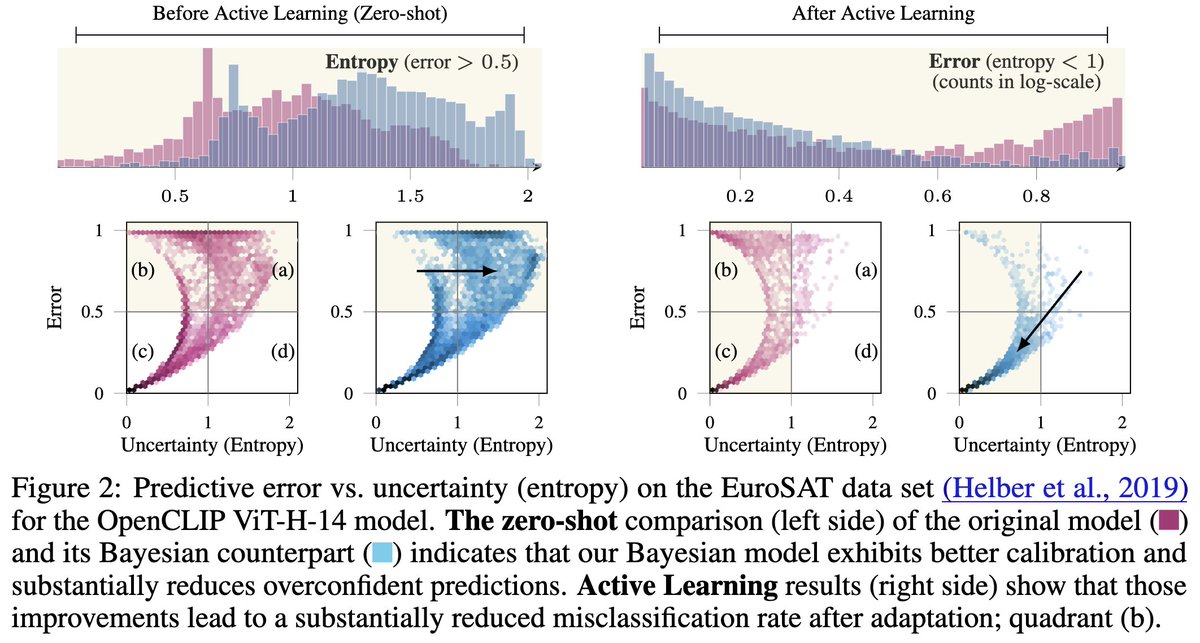
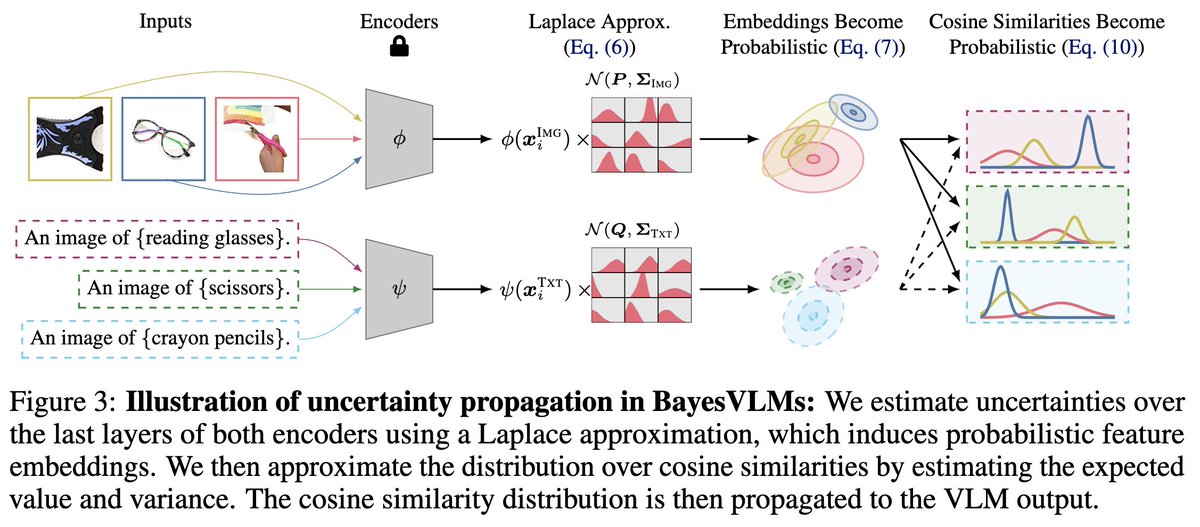
3/ Post-hoc Probabilistic Vision-Language Models
@_antonbaumann, @ruili_pml, Marcus Klasson, Santeri Mentu, @ShyamgopalKart1, @zeynepakata, @arnosolin
, Martin Trapp
[Paper]: arxiv.org/pdf/2412.06014
🕑 Fri, Apr 24, 2026 • 6:30 AM – 9:00 AM PDT
🚩 Pavilion 3 P3-#313
2
2
344