
Joined October 2016
- Tweets 10
- Following 51
- Followers 17
- Likes 64
Photos and videos
Anton Baumann retweeted

Jun 4
On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
Jun 4

Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
21
127
1,303
138,260
Anton Baumann retweeted

May 27
We have been exploring new algorithmic frontiers and are excited to share our contributions to Self Distillation Policy Optimization (SDPO) for agentic continual learning, check out our blog post here:
trajectory.ai/field-notes/sc…
3
6
71
38,737
Anton Baumann retweeted
May 18
Been working on text feedback / OPSD in Composer. Really interesting space, and much more to be explored.

May 18

We improved Composer by scaling training, generating more complex RL environments, and introducing new learning methods.
For example, we use text feedback during RL to learn faster by assigning credit in rollouts spanning hundreds of thousands of tokens.
11
28
277
39,874
Anton Baumann retweeted

May 18
Self-distillation for long-horizon training at scale!
May 18
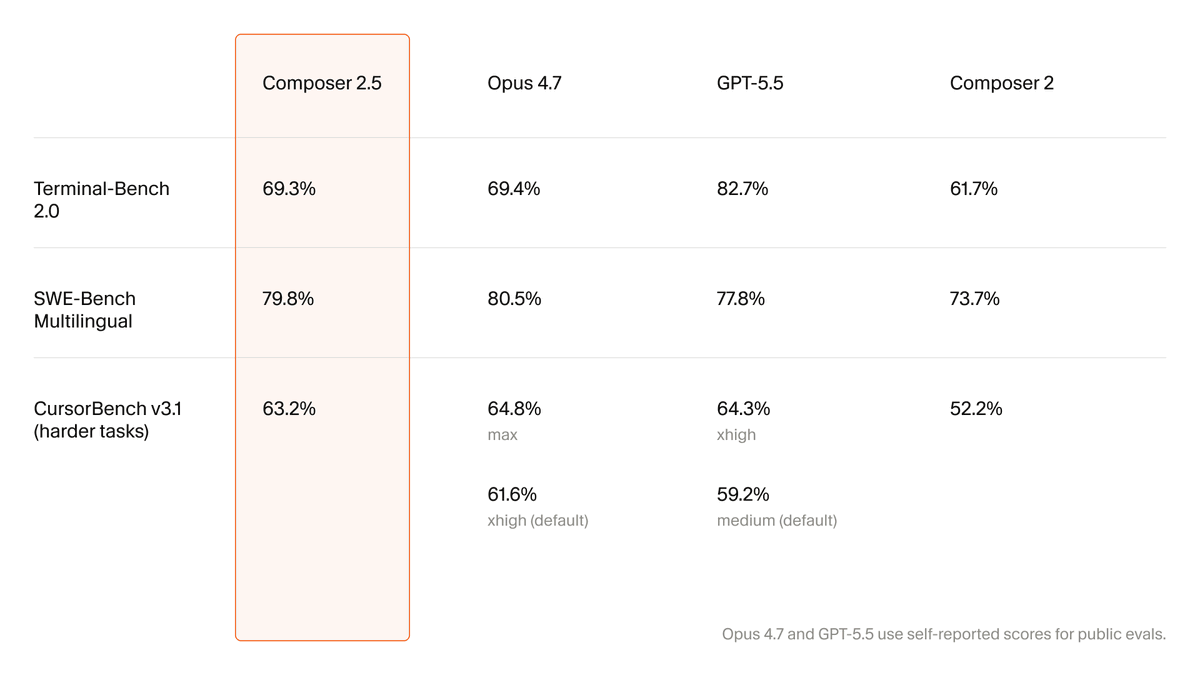
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
1
5
67
4,846
Anton Baumann retweeted
Apr 26
Today and tomorrow we’ll be presenting self-distillation with orals at ICLR in Rio 🇧🇷
1. “Self-Distillation enables Continual Learning” at lifelong agents workshop (Sun 11:30am)
2. “Reinforcement Learning via Self-Distillation” at scaling post-training workshop (Mon 2:40pm)
3. “Test-Time Self-Distillation” at test-time updates workshop (Mon 4:15pm)

10
48
431
101,921
Anton Baumann retweeted
Feb 15
Just came across this great discussion of self-distillation on @latentspacepod! Really good run down by Ted Kyi and we’re every bit excited about what’s next as he is!
m.youtube.com/watch?v=CrJp0s…
4
21
3,123
Anton Baumann retweeted

3/
Post-hoc Probabilistic Vision-Language Models
@_antonbaumann, @ruili_pml, Marcus Klasson, Santeri Mentu, @ShyamgopalKart1, @zeynepakata, @arnosolin, Martin Trapp
[Paper]: arxiv.org/pdf/2412.06014
[Project]: aaltoml.github.io/BayesVLM/
[Code]: github.com/AaltoML/BayesVLM
1
1
1
166
Anton Baumann retweeted
Jan 29
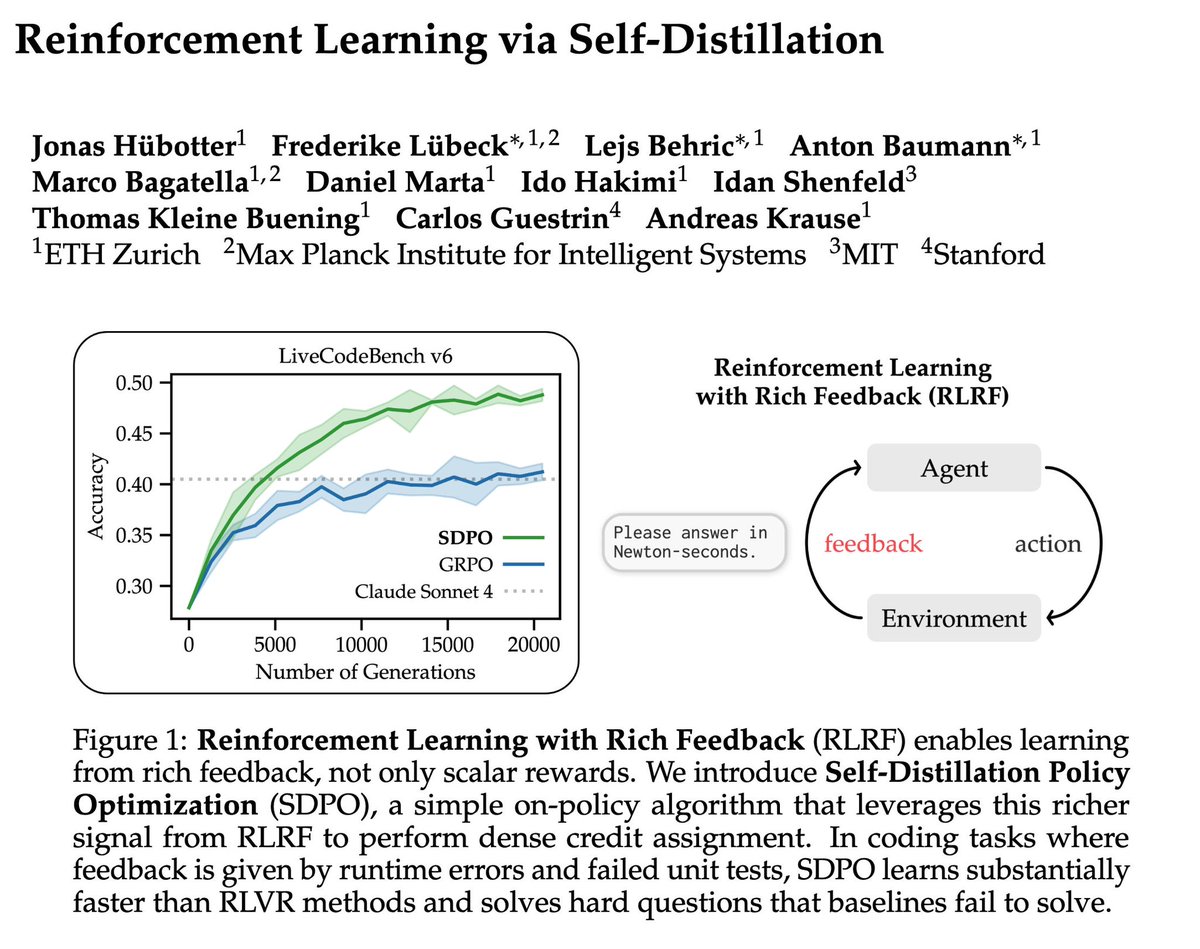
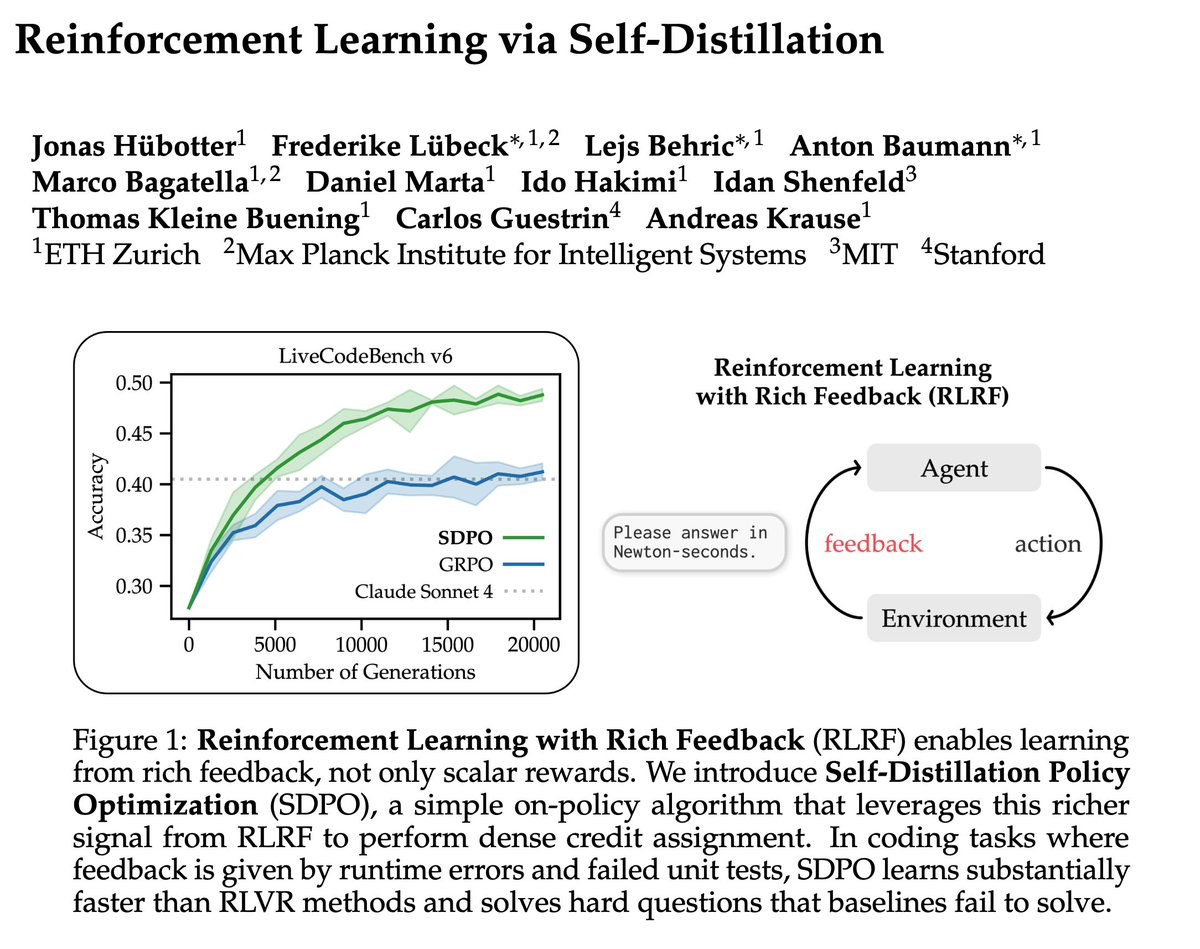
Training LLMs with verifiable rewards uses 1bit signal per generated response. This hides why the model failed.
Today, we introduce a simple algorithm that enables the model to learn from any rich feedback!
And then turns it into dense supervision.
(1/n)
22
139
1,116
211,165