
Joined November 2016
- Tweets 1,907
- Following 1,188
- Followers 3,159
- Likes 825
435 Photos and videos













Pinned Tweet

Jun 10
Boris Cherny(Claude Code 的创始人兼负责人) @bcherny 和 Cat Wu(Claude Code 产品负责人) 复盘 Claude Code 第一年:
一年前通用版上线,第一个 demo 发到 Slack 只换来两个 emoji;现在每天有几千个自主 agent 在跑。
这一年最反直觉的转变,是 Boris 已经不直接跟 agent 说话了。
「我跟一个 loop 说话,或者跟一个 routine 说话,由它来给 Claude 发提示词,这真的很疯狂。」
他把 18 个月概括成两次平台级跃迁:第一次,人从写源代码挪到跟 agent 对话;第二次正在发生,人从跟 agent 对话再挪到跟一个 loop 对话,由它去驱动 Claude。
loop 能干到什么程度?Cat Wu 留下的一个边界 bug,当晚被「另一个 Claude」先修好了——一位同事的 routine 专盯 5 小时没人回应的 bug 报告,自动提修复、容易验证的直接合并。Boris 说 routine 现在接管了全部代码审查:
· 帮你盯着每一个 PR
· 手动修 CI、手动 rebase 这些,他已经很久没做了
放手让 agent 自己跑,不会更危险吗?Boris 的判断正相反。
他的原话:
「其实你根本不想读大多数这些请求,把它路由给另一个模型去做安全检查,效果好太多了。」
理由是人性:当 99% 的权限提示都无害,人读着读着眼睛就发直了,真正危险那条反而被漏掉。推给用户前,团队拿数千条执行轨迹训练分类器,再让红队对代码库做提示注入攻击,每一次成功的攻击都变成一个 eval。
那怎么让一个 agent 能无人值守一直跑?Boris 的第一原则是不纠正单次输出:
「每次 Claude 犯了错,我不会告诉 Claude 下次要怎么做不同。」
而是把解法写进 CLAUDE.md 或做成一个 skill,把同类错误从此关掉。至于上下文,他给的是一条时间线——Sonnet 3.5 要做提示词工程,Opus 4 要做上下文工程,现在的模型两者都不要:
「给它最精简的系统提示词,最少的工具,然后让模型自己搞清楚。」
被问到下一步,Boris 没有预测形态,只说 agent 会跑得更久、更自主,同时并行的数量从一个跳到几千,而协调它们的界面会和现在完全不同——「再过一年,会是一套全新的东西,如果还是这些东西,那反而令人意外」。
完整双语转录 章节摘要 字幕:
lattifai.com/zh/podcasts/Cla…
43
25
126
42,626
19h
A 家 平均年纪要超 35 了,国内说平均年纪 25
Jun 11

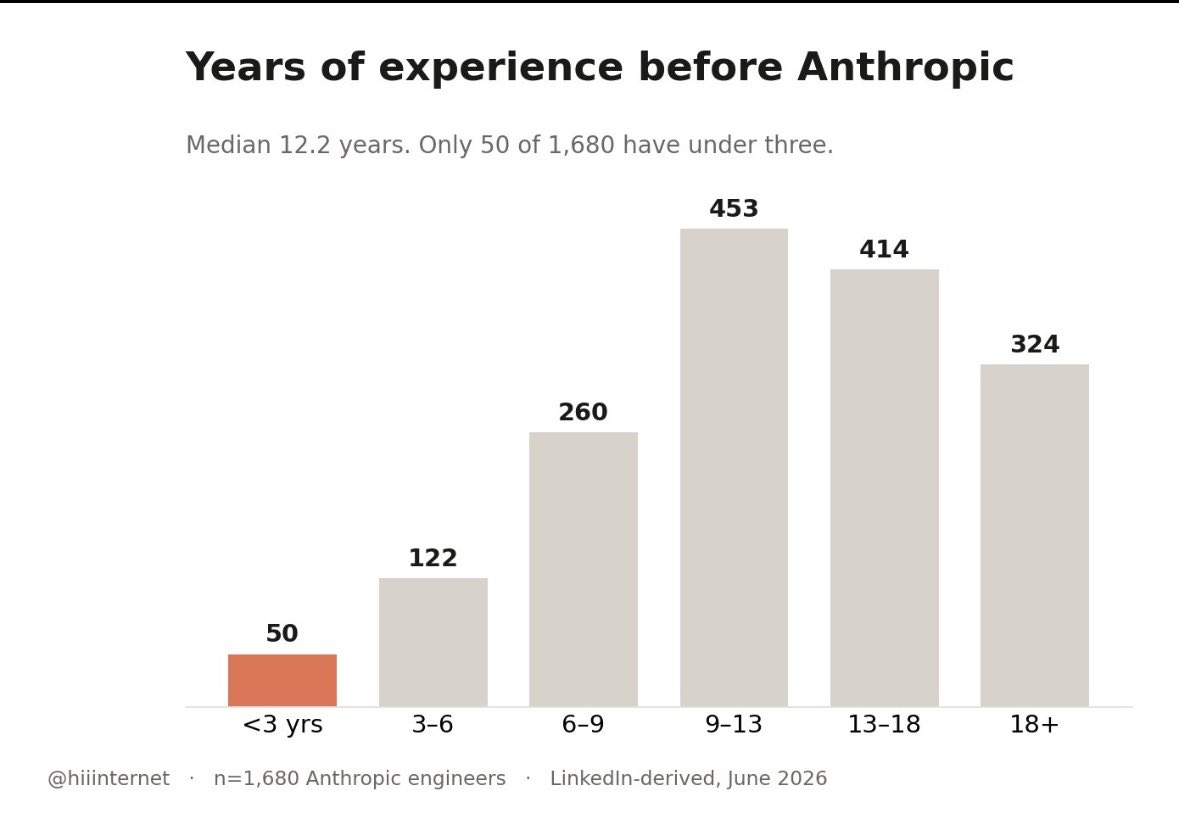
Anthropic almost AVOIDS hiring juniors unless they have a PhD. and only ~13% of their employees have PhD, most have years of careers behind them.
1
432
19h
Zyphra 放出 ZONOS2:开源实时 TTS,原生 44.1kHz 输出,主打高保真声音克隆,Apache 2.0 直接商用。
训练数据从上一代的 20 万小时干到 600 万 小时,30 倍。
33 种语言分三档,档位基本对应训练语料的多少、效果也更好:第一档中/英/日料最足最稳,第二档 10 种(韩/法/西/德/俄/意/葡/越/荷/希伯来),剩下 20 种打底。
MoE 架构,本地能跑(推理服务基于 Mini-SGLang),也有托管版,云端跑在 AMD 上。
模型 🤗 huggingface.co/Zyphra/ZONOS2
代码 github.com/Zyphra/ZONOS2

Today we're releasing ZONOS2, our next-generation real-time TTS model with high-fidelity voice cloning.
ZONOS2 is the most expressive open-source TTS model, released under Apache 2.0 and available on Zyphra Cloud on @AMD. 🧵
3
50
7,686
Jun 13
艹
“美国政府援引国家安全权限,发布了一项出口管制指令,暂停任何外国国民(无论在美国境内还是境外)对 Fable 5 和 Mythos 5 的所有访问权限,包括 Anthropic 的外国国民员工。”
从昨晚一直强迫退回 Opus(是 Anthropic 分类器误判) 到早上刚开始 agent teams 开始干活就报错;
重置额度来给安慰了


Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
506
Jun 13
“因此,为了确保合规,我们必须立即停止所有客户对《神鬼寓言5》和《神话5》的访问。”
整个模型下线 不能使用了
anthropic.com/news/fable-myt…
1
2
130

Jun 11
创始人兼 CEO Ahmad Awais(27 年编程、300 开源项目) 在 Latent Space 的访谈:
他的核心论断:开源模型在编程上「不行」,多半不是模型菜,是接它的框架(harness)菜。框架修对了,便宜的 DeepSeek V4 Pro 就能反超昂贵的 Opus 4.7。
CommandCode 是个 AI 编程命令行工具,和 Claude Code、Cursor 同类,但它的目标「让便宜的开源模型也能干活」上:靠一层拦截并修复模型工具调用的中间件。
那开源模型到底差在哪?他发现一个叫「工具混淆」的失败模式——模型发出格式错误的工具调用,你按程序员本能把严格的 Zod 校验报错回传给它,它居然不改。
他的原话:
「在 10 亿 token 里,它平均会重复同样的错误 56 次。」
那怎么解决?他不把报错丢回去,而是确定性地修好、执行、再附一条自然语言修复提示。
· 他的类比是「把它想象成教人开车」:先帮你扳回方向盘,再讲哪儿错了
· 效果是「当你把结果和修复提示一起发回去,第三次工具调用就修正了」
· 这套修复逻辑是一点点滚大的:起步只有 3200 行代码,一个模型一个模型地补(Kimi、MiniMax 等),如今攒到约 16000 种不同的修复变体,覆盖数千亿 token
那为什么 Twitter 上有人说 DeepSeek 神、有人说垃圾?因为很多人直接把 Claude Code 换个 endpoint 当开源模型的 harness,而 Claude Code 把每会话 50 多次工具调用失败折叠进了 Ctrl-O,你根本看不见,只觉得「DeepSeek 怎么这么慢啊」。两派口碑,几乎完美对应有没有修复逻辑。
为了公开证明这是框架问题不是能力问题,他们上了个每月 1 美元、放出 6 亿 token DeepSeek Pro 额度的 Go 计划。Ahmad 甚至认为这股势头传导到了 DeepSeek 自己降价。
同一套「先验证再修复」还被搬到了设计上:那种所有 LLM 都爱用的靛蓝紫渐变是可预测的「设计垃圾」,24 份参考文档 10 种设计臭味 7 种模式,他说「可以修复 90% 的设计垃圾,这不是能力差距」,而是 harness 和用户真实需求之间的「契约差距」。
最后他给了个判断:价值正在从「模型本身多强」移到「谁能把框架的契约补得更准」——用顶配模型沉淀一份偏好上下文,再让便宜模型照着持续干。CommandCode 打算把整套开源,让你能接任何本地模型。
原 @MrAhmadAwais 帖 x.com/MrAhmadAwais/status/20…
完整双语转录 章节摘要 字幕:
lattifai.com/zh/podcasts/Lat…
May 3

how did we make deepseek outperform opus 4.7?
i've been thinking about why "open model bad at tool calling" is almost always a harness problem, not a model problem.
context: spent the two days looking at billions of tokens in @CommandCodeAI (tb open source ai cli) using deepseek. I ended up writing a tool-input repair layer. the trigger was watching deepseek-flash fail on the simplest /review run, every shellCommand and readFile call bouncing back with a raw zod issues blob, the model unable to recover because the error wasn't in a form it could read. by the end deepseek v4 pro was beating opus 4.7 6/10 times on our internal evals.
a few things i learned that feel general:
1/ the failure modes aren't random they're a small finite compositional set.
across deepseek-flash, deepseek v4 pro, glm, qwen, the same four mistakes repeat almost exactly:
- sending `null` for an optional field instead of omitting it
- emitting `["a","b"]` as a json *string* instead of an actual array
- wrapping a single arg in `{}` where the schema expected an array (an "empty placeholder")
- passing a bare string where an array was expected (`"foo"` instead of `["foo"]`)
four repairs, ~30-100 lines each, ordered carefully (json-array-parse must run before bare-string-wrap or `'["a","b"]'` becomes `['["a","b"]']`). that is the whole catalogue. when i hear "this open source model can't do tool calls" i now assume one of those four, and so far that's been right ~90% of the time.
2/ the funniest failure mode is also the most revealing.
deepseek-flash, when asked to edit or write a file, sometimes emits the path as a *markdown auto-link*:
filePath: "/Users/x/proj/[notes.md](http://notes. md)"
our writeFile tool obediently trued creating files literally named `[notes.md](http://notes .md)` until we caught it. this is not a hallucination. it's the post-training chat distribution leaking through the tool boundary the model has been rewarded for auto-linking in conversational output, and is applying that prior in a context where it makes no sense. the fix is two regex lines that unwrap only the degenerate case where link text equals url-without-protocol real markdown like `[click](https://x .com)` passes through untouched.
this is also conditioning of their own tools during RL which were different from all other tools we write and ofc can't predict.
"tool confusion" is a more useful frame than "capability gap." the model knows how to format a path. it just hasn't been told clearly enough that this path is going to fopen, not into a chat bubble. so we encode that hint at the schema level `pathString()` instead of `z.string()` and the leak is plugged for every path field at once.
3/ the design choice that mattered was inverting preprocess-then-validate to validate-then-repair.
my first attempt was the obvious one: a preprocessing pass that normalized inputs (strip nulls, parse stringified arrays, etc.) before zod ever saw them. it broke immediately, writeFile content that *happened* to be json-shaped got rewritten before it hit disk. silent corruption, easy to miss in a smoke test.
then i made it less greedy
- parse the input as-is. if it succeeds, ship it. valid inputs are never touched.
- on failure, walk the validator's own issue list. for each issue path, try the four repairs in order until one applies.
- parse again. on success, log `tool_input_repaired:${toolName}`. on failure, log `tool_input_invalid:${toolName}` and return a model-readable retry message.
the structural insight here is: when you preprocess, you encode a prior about what's broken. when you let the validator complain first, the schema is the prior, and you only spend repair budget at the exact paths the schema actually disagreed at. the validator is doing the work of localizing the bug for you. it's the same shape as cheap-then-careful everywhere else try the fast path, fall back on evidence.
(this also gives you per-tool telemetry for free. you can watch repair rates per (model, tool) and notice when a model regresses on a specific contract before users do.)
4/ shape invariants and relational invariants need different fixes.
the four repairs above all handle shape problems wrong type, missing key, wrong container. but read_file had a *relational* invariant: "if you provide offset, you must also provide limit, and vice versa." deepseek kept calling `readFile({ absolutePath, limit: 30 })` and getting an `ERROR:` back. you can't fix this with input repair, because each field is independently valid the bug is in the relationship between them.
so i taught the function the model's intent instead. `limit` alone → `offset = 0`. `offset` alone → `limit = 2000` (matches common read tool ops default). then surfaced the decision back to the model in the result:
"Note: limit was not provided; defaulted to 2000 lines. To read more or fewer lines, retry with both offset and limit."
no `Error:` prefix, so the tui doesn't paint it red. the model sees what we picked and can self-correct on the next turn if our guess was wrong. transparency over silent magic wins big.
repair where you can. extend semantics where you can't. surface the choice either way.
zoom out:
a lot of what looks like model capability is actually contract design. a strict schema is a choice with a cost it filters out noise, but it also filters out recoverable noise from any model that hasn't memorized the exact json contract you happened to pick. the largest commercial models eat that cost invisibly and are linient on tool calling because they've seen enough of every contract during pretraining; open models pay it loudly and get dismissed for it.
the harness is where you mediate between distributions. four small repairs (i'm sure more to follow as we have three more merging today), two regex lines for auto-links, one relational default, one prefix change. the model didn't change. the contract got more forgiving in exactly the places it needed to be.
deepseek v4 pro now beats opus 4.7 6/10 times on our internal evals.
imo "skill issue" applies to the harness more often than the model.
3
1
33
8,828
Feiteng retweeted

Jun 11
再次强烈推荐「Agentic Engineering Patterns」
作者 @simonw 2026 年 2 月起撰写,每周约新增 1–2 章,目前仍在演进。文字由他本人撰写,示例与代码借助 LLM 辅助。
在线阅读:
simonwillison.net/guides/age…
核心目标:如何用好 Claude Code、Codex 这类能写代码、也能执行代码的 coding agent,拿到可靠、可维护的结果。
# 核心概念:Agentic Engineering ≠ Vibe Coding
Vibe Coding vs Agentic Engineering
· 定义来源:Karpathy 提出 vs Willison 提出的专业实践
· 适用人群:常与非程序员原型相关 vs 专业工程师放大既有能力
· 代码质量:未审查、原型级 vs 审查、测试、可上线
· 人的角色:几乎不参与代码理解 vs 定义问题、验证结果、持续改进 harness
Agent 的定义: 在循环中调用工具以达成目标。Coding agent 的关键差异是能执行代码——没有执行能力,LLM 输出价值有限;有了执行,agent 才能迭代到"确实能跑"的软件。
人的工作并未消失,而是上移:
· 决定写什么代码(问题空间有数十种解法与权衡)
· 提供工具与足够细的规格
· 验证结果是否稳健可信
· 把经验写回指令与 harness(LLM 本身不会从错误中学习,但系统可以)
# 全书最重要的一个判断
写代码变便宜了,写好代码并没有。
过去几十年,工程习惯都建立在"代码昂贵"之上:
· 宏观: 大量设计、估算、排期,功能必须数倍覆盖开发成本
· 微观: 是否重构、写测试、补文档、做 debug UI——每个决定都受时间约束
Agent 把这个约束打碎。一个人还能并行跑多个 agent,同时实现、重构、测试、写文档。
但"好代码"仍有明确标准:
· 能跑、且被证明能跑
· 解决对的问题
· 处理错误路径,不只 happy path
· 简洁、可维护
· 有测试与合适文档
· 设计留出演进空间(YAGNI 与可扩展性的平衡)
· 满足安全、可观测性等 non-functional 要求
新习惯: 当直觉说"不值得做"时,不妨开个异步 agent 试一下——最坏情况是浪费几分钟 token;很多过去"不划算"的改进,现在值得做。
# 五大原则层(Principles)
1. 定义边界
Agentic Engineering 是专业工程师用 coding agent(能写能跑)放大能力;不等于 vibe coding(不审代码的原型玩法)。人的核心工作:定目标、给工具、验结果、把经验写回 harness。
2. 接受新约束
写代码几乎免费,写好代码仍然贵。旧习惯(过度规划、跳过测试/文档/重构)要推翻;直觉说「不值得做」时,不妨开个异步 agent 试一下。
3. 囤积可复用解法
积累带可运行证明的代码片段(仓库、笔记、小工具)。最强用法:把两个已验证例子拼进 prompt,让 agent 组合出新方案;每个技巧人类只需解决一次。
4. 质量应上升,而非下降
技术债、命名混乱、大文件拆分等「简单但耗时」的清理,交给后台 agent 做,成本已低到可零容忍 code smell;用原型并行验证技术选型;任务结束做回顾,把有效做法写进指令(复合工程)。
5. 严守反模式
绝不提交自己没审过的 PR。合格标准:确信能跑、体量小、有上下文、描述自己读过、附测试证据。否则只是把活甩给 reviewer。
# 实操层:与 Agent 更好的协作
1. 先懂机制,再谈用法
Agent = LLM 系统提示 工具循环。你不必背实现细节,但要清楚:
· 对话越长越贵;agent 会尽量利用 token 缓存
· 模型无状态,每次重放上下文
· 能执行代码才是 coding agent 与普通 LLM 的分水岭
· Reasoning/Thinking 对调试复杂问题尤其有用
2. Git:大胆用,不必背
把 Git 当 agent 的「时间机器」和「安全网」:
· 新会话恢复上下文:Review changes made today
· 救场:Sort out this git mess for me
· 找丢了的代码:Find and recover my code that does ...
· 定位回归:Use git bisect to find when this bug was introduced
· 修 commit / 抽库留历史:Undo last commit / 从新 repo 复制模块并保留 commit 历史
3. Subagent:省上下文,不是炫技
上下文有限,大任务要「分身」:
· Explore:进陌生 repo 先摸清结构,汇总给主 agent
· 并行:多文件独立改动可同时跑,可用更便宜模型
· 专家(审查 / 跑测 / 调试):隐藏冗长输出,只回报结果
原则: 为省 token 而拆,不为拆而拆;主 agent 够用就别过度分工。
4. 测试:三层防线
① TDD:先写测 → 确认失败 → 实现至通过
② 建立测试意识:新会话先跑全套测试
③ 手动验:python -c / curl / Playwright 真浏览器
④ 留证:Showboat 记录命令与真实输出,防编造
5. 理解代码:还认知债
Agent 产出若成黑盒,会积累 认知债(类似技术债,拖慢后续决策):
· Linear walkthrough:线性导读,用 grep/cat 引用代码,禁止手抄
· Interactive explanation:在导读基础上做可暂停、可调速的动画演示
适用: 陌生代码、自己忘了细节的代码、vibe code 出来却没看过的代码。

Jun 10

I've been writing a whole guide! simonwillison.net/guides/age…
5
96
324
31,226
Jun 11
两个月前让 Claude Code 优化 MLX 的模型计算速度,给了它 方向(优化 channel sequence 数据排列 它自己头脑风暴)和让它写好精度对比测试,之后十几分钟后,就做完了加速两倍
coding agent 做速度优化很容易定义“验证” 所以不容易跑飞
Jun 11

十年啊,兄弟们!十年间,我不知道花了多少时间调教语法解析和渲染的性能。Fable花了10分钟把综合性能提升了 7 ~ 17 倍!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!

2
1,906

Feiteng retweeted

Jun 11
👋 你好!我是 MakerJackie,喜欢探索世界/旅行/开源,用 AI 开发一些有趣的小产品。人生苦短,做热爱的事情顺带赚点钱。
现在是一名独立开发者/OPC/数字游民,同时也是周周黑客松社区的发起人,做过几年的AI语音算法工程师,96年,中山大学计算机
我的博客和作品集:makerjackie.com
我的 AI 产品创作教程:01mvp.com
自媒体全网同名: MakerJackie

1
1
3
393
Jun 11
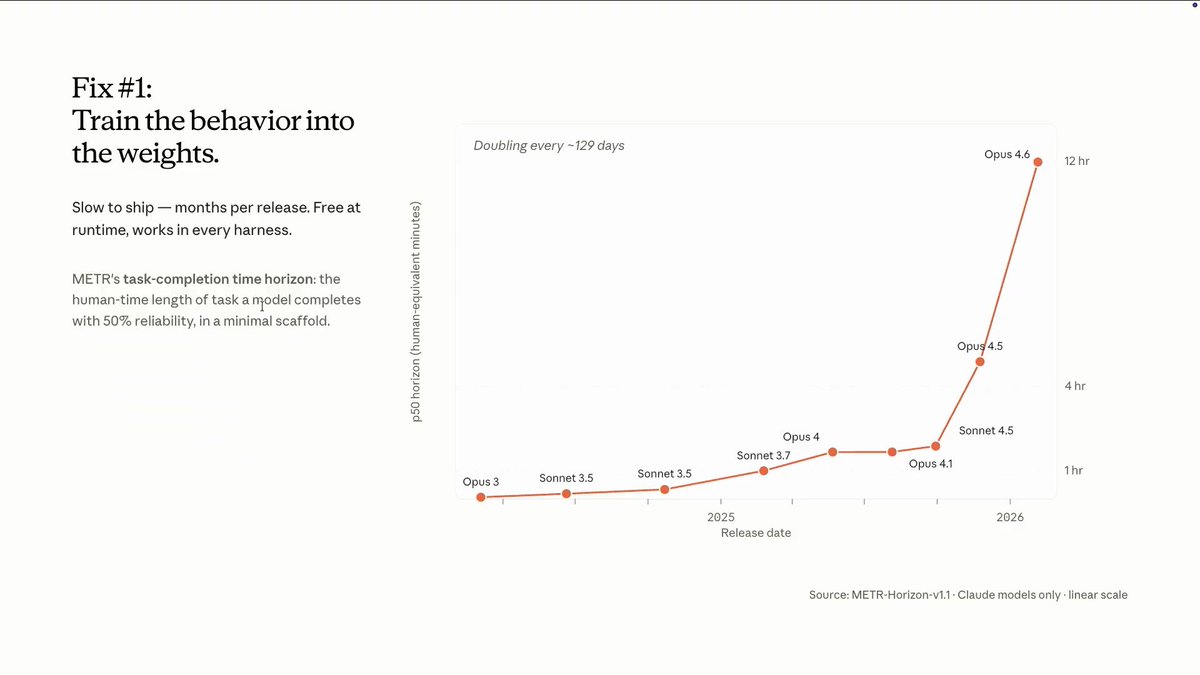
通过不断的把 harness 行为训练进模型权重来提交模型自身的 harness 能力
@AnthropicAI 一年内模型自主运行时长从 Sonnet3.7 1小时提高到 Opus 4.6 12 小时

1
1
489
Feiteng retweeted

Jun 10
Moshi is great but sometimes not fully exploiting its full-duplex abilities. @atsumoto_ohashi applied carefully crafted RL rewards on Moshi's output given some real inputs to improve interactivity on all axis. Works great on Moshi and the derived PersonaPlex by @nvidia.
Jun 10

New paper: Multi-Faceted Interactivity Alignment in Full-Duplex Speech Models
We use RL to post-train speech models (Moshi and PersonaPlex) to talk more like a human: to know when to respond, when to wait, and when to nod along with “yeah”s and “okay”s when listening.
7
30
2,711
Jun 10
就算是真的,CEO这种格局以后不知道会出多少幺蛾子


1
633
Feiteng retweeted

LLM can Read Spectrogram: Encoder-free Speech-Language Modeling
Ruchao Fan, Yiming Wang, Yuxuan Hu, Bo Ren, Yufei Xia, Xiaofei Wang, Yao Qian, Jinyu Li
arxiv.org/abs/2606.10231 [𝚎𝚎𝚜𝚜.𝙰𝚂 𝚌𝚜.𝚂𝙳]
3
18
1,007