
QR at Citadel Securities. Ex Google AI resident.
Joined October 2015
- Tweets 84
- Following 232
- Followers 401
- Likes 130
5 Photos and videos




Pinned Tweet

6 Oct 2020
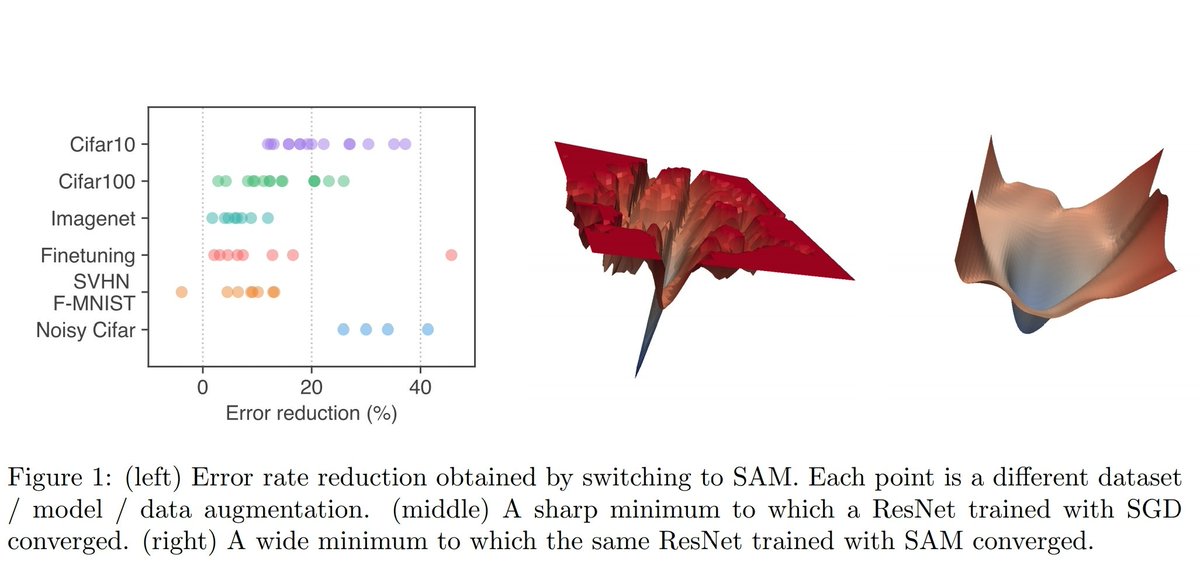
Introducing SAM: An easy-to-use algorithm derived by connecting PAC Bayesian bounds and geometry of the loss landscape. Achieves SOTA on benchmark image tasks (0.3% error on CIFAR10, 3.9% on CIFAR100) and drastically improves label noise robustness.
arxiv.org/abs/2010.01412
6
38
150
Pierre Foret retweeted

15 Jun 2022
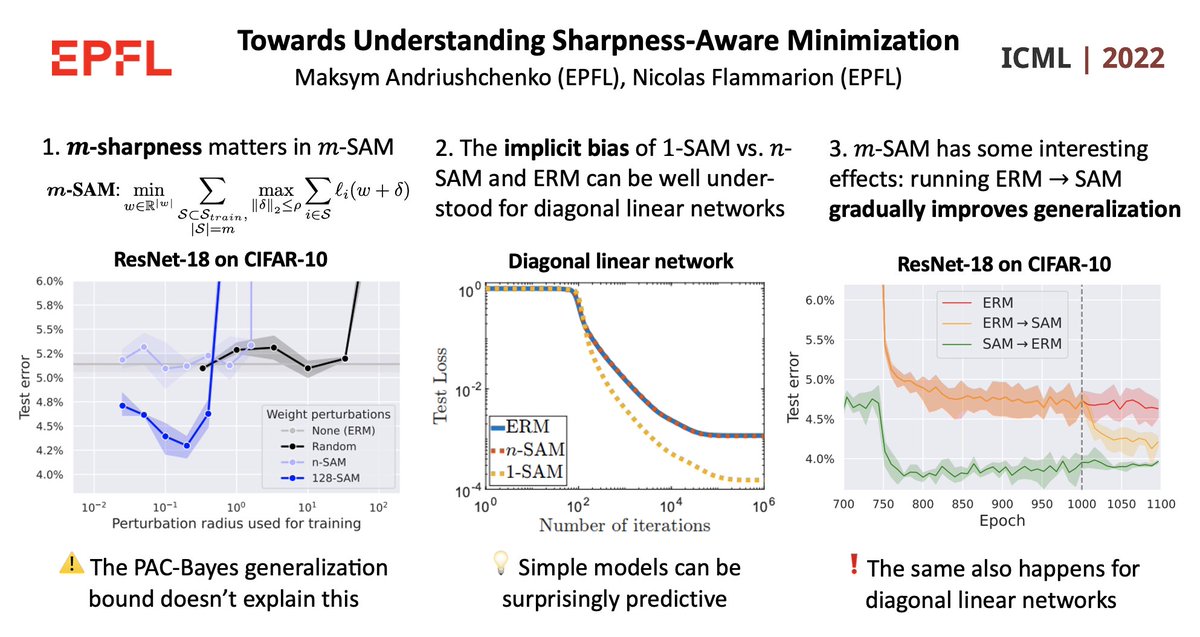
Excited to share our #ICML2022 paper "Towards Understanding Sharpness-Aware Minimization"!
Why does m-sharpness matter in m-SAM? Can we explain the benefits of m-SAM on simple models? Which other interesting properties does m-SAM show?
Paper: arxiv.org/abs/2206.06232
🧵1/n
4
31
195

Excited to host @TheGradient to talk about the current state of Sharpness-Aware Minimization (SAM) and future directions next Friday 25th Feb 5pm (GMT time) Zoom details: ucl-ellis.github.io/dm_csml_…
7
21
Pierre Foret retweeted

29 Jan 2022
Are you a strong PhD student interested in doing cutting edge research at @GoogleAI? I have an opening for student researcher position to explore open problems and extensions of Sharpness-Aware Minimization (SAM) w/ @bneyshabur. Please refer to tinyurl.com/4nfarsvt.

4
22
117
Pierre Foret retweeted

19 Oct 2021
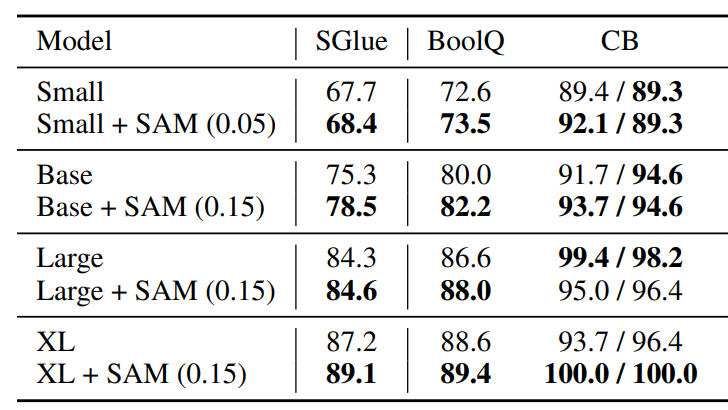
Sharpness-Aware Minimization Improves Language Model Generalization
SAM substantially improves performance on SuperGLUE, GLUE, Web Questions, Natural Questions, Trivia QA, and TyDiQA by encourageing convergence to flatter minima w/ minimal overhead.
arxiv.org/abs/2110.08529
1
16
88

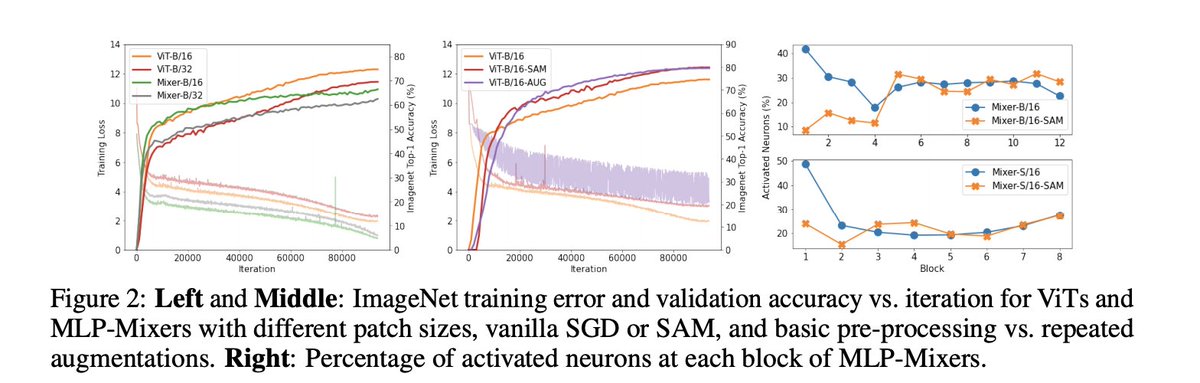
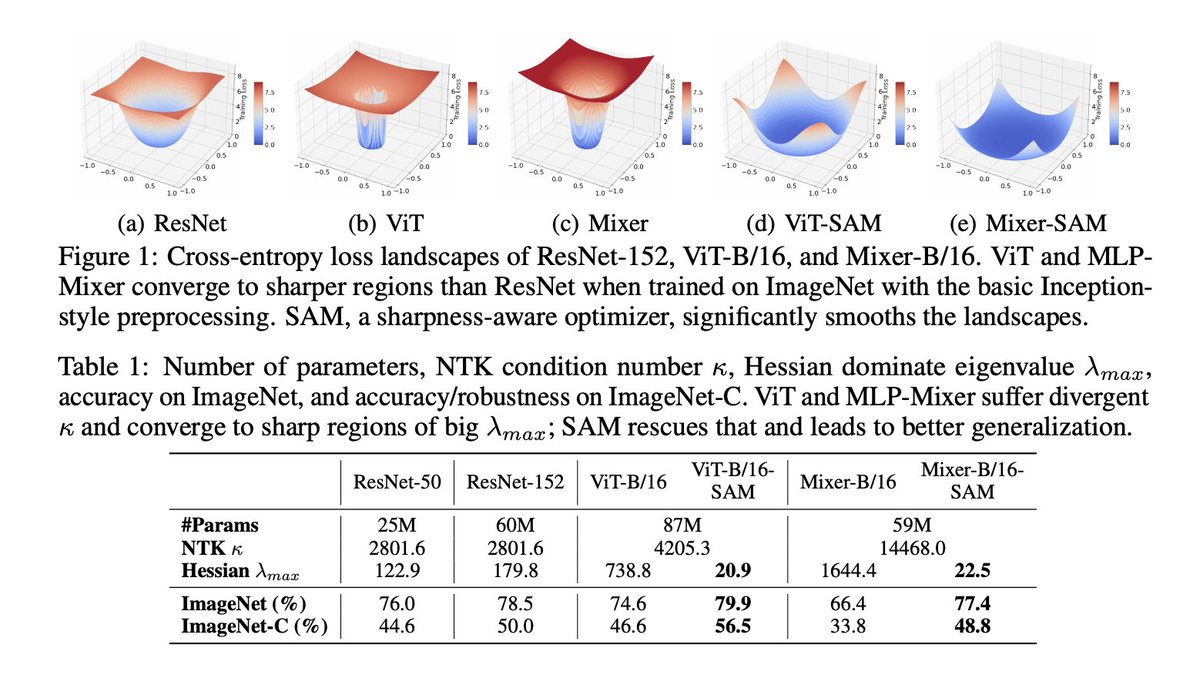
When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations
pdf: arxiv.org/pdf/2106.01548.pdf
abs: arxiv.org/abs/2106.01548
5.3% and 11.0% top-1 accuracy on ImageNet for ViT-B/16 and MixerB/16, with the simple Inception-style preprocessing
7
124
472
Pierre Foret retweeted

4 Jun 2021
Interesting empirical study of the geometry of the loss landscape of Vision Transformers and MLP-Mixers and study of the critical impact of Sharpness Aware Minimization (SAM) for those architectures.

When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations
pdf: arxiv.org/pdf/2106.01548.pdf
abs: arxiv.org/abs/2106.01548
5.3% and 11.0% top-1 accuracy on ImageNet for ViT-B/16 and MixerB/16, with the simple Inception-style preprocessing
6
27
Pierre Foret retweeted
28 May 2021
Excited to see Sharpness-Aware Minimization (SAM optimizer) we have proposed recently (w/ @Foret_p @bneyshabur and Kleiner) is becoming a persistent component in recent state-of-the-art records 😇
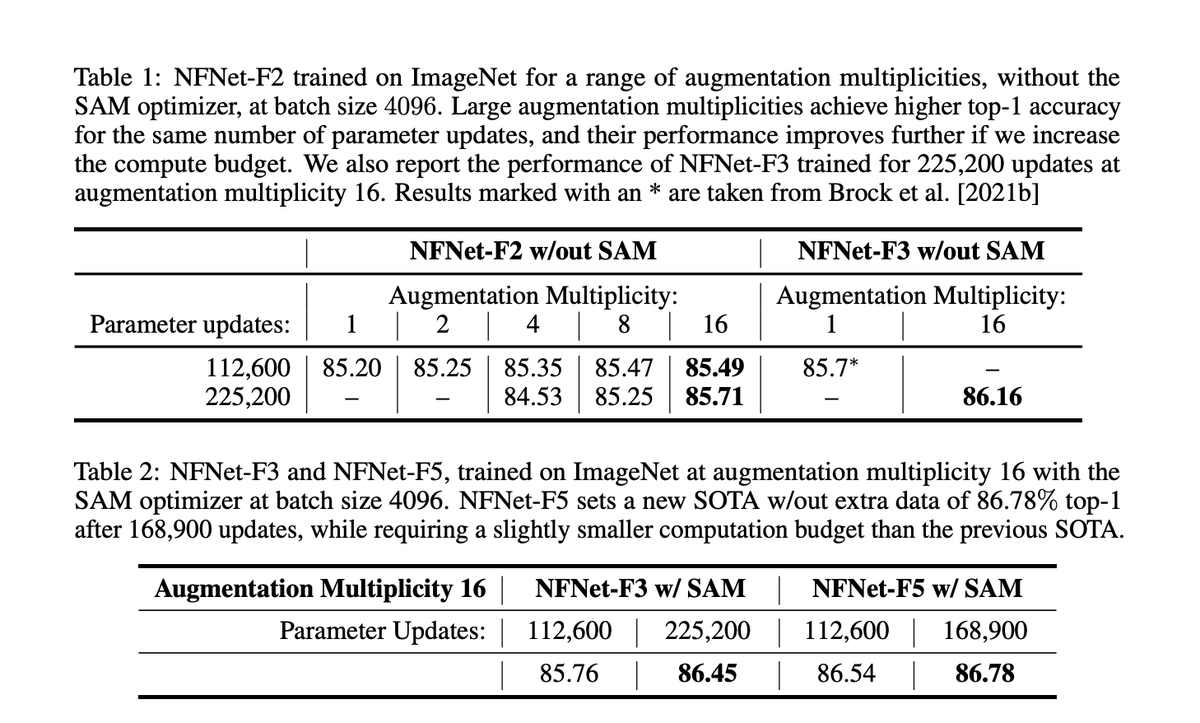
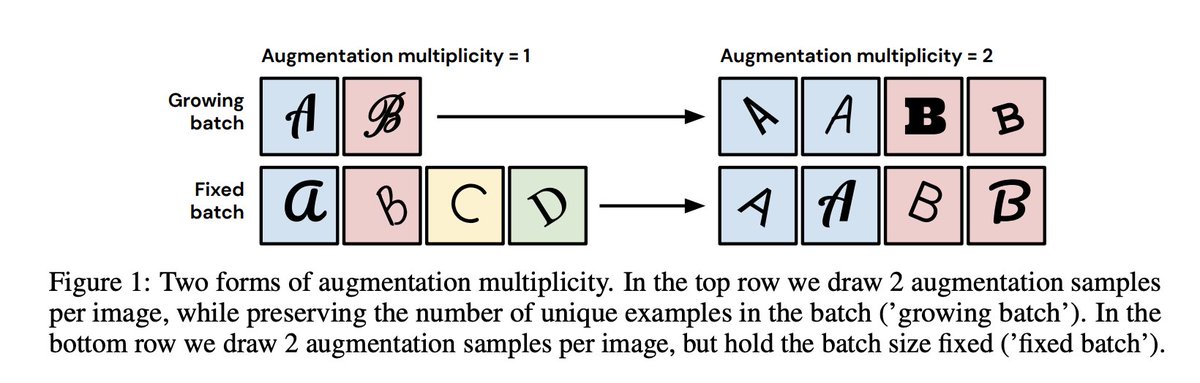
Drawing Multiple Augmentation Samples Per Image
During Training Efficiently Decreases Test Error
pdf: arxiv.org/pdf/2105.13343.pdf
abs: arxiv.org/abs/2105.13343
ImageNet SOTA of 86.8% top-1 accuracy after just 34 epochs of training with an NFNet-F5 using the SAM optimizer
7
39
Pierre Foret retweeted

30 Apr 2021
Sharpness-Aware Minimization for Efficiently Improving Generalization (Spotlight at #ICLR2021 )
with @Foret_p, Ariel Kleiber and @TheGradient
Paper: openreview.net/forum?id=6Tm1…
Code: github.com/google-research/s…
Video and Poster: iclr.cc/virtual/2021/poster/…
3/7

2
4
19
Pierre Foret retweeted

18 Mar 2021
We don’t need to worry about #Overfitting anymore? Sharpness-Aware Minimization, seeks parameters that lie in neighborhoods having uniformly low loss; results in a min-max optimization formulation with efficient gradient descent #MachineLearning buff.ly/38VJTOf

14
21
Pierre Foret retweeted

17 Feb 2021
Pretrained NFNet model weights (F0-F5, F6 SAM) are now available at dpmd.ai/nfnets, along with a demo Colab! All models are pretrained on ImageNet.
12 Feb 2021

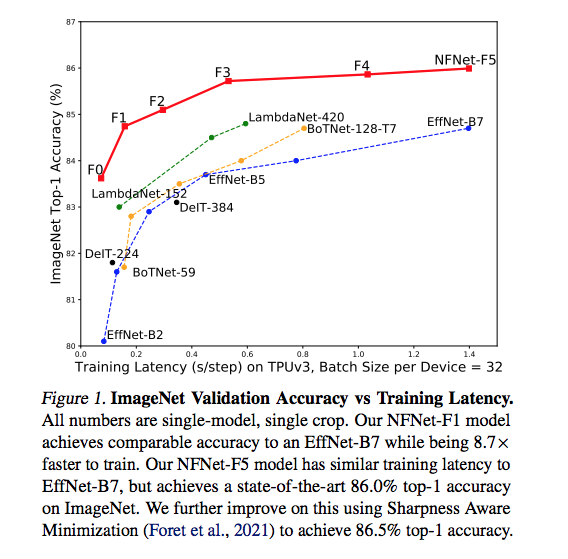
Our most recent work on training Normalizer-Free nets!
We focus on developing performant architectures which train fast, and show that a simple technique (Adaptive Grad Clipping, or AGC) allows us to train with large batches and heavy augmentations and reach state-of-the-art.
3
33
150
High-Performance Large-Scale Image Recognition Without Normalization
pdf: arxiv.org/pdf/2102.06171.pdf
abs: arxiv.org/abs/2102.06171
github: github.com/deepmind/deepmind…
1
64
240
Pierre Foret retweeted
12 Feb 2021
Also nice to see that NFNets can also benefit from Sharpness Aware Minimization by @Foret_p et a.:
arxiv.org/abs/2010.01412
1
1
6
12 Jan 2021
🎉 Happy to announce that we will do a spotlight presentation of our work at @iclr_conf. See you there to discuss sharpness and generalization!
6 Oct 2020

Introducing SAM: An easy-to-use algorithm derived by connecting PAC Bayesian bounds and geometry of the loss landscape. Achieves SOTA on benchmark image tasks (0.3% error on CIFAR10, 3.9% on CIFAR100) and drastically improves label noise robustness.
arxiv.org/abs/2010.01412
2
30
Pierre Foret retweeted

Happy new year everyone 🥳! We have the perfect gift to kick off your research in 2021. All data used for the competition are now open-sourced. In addition, the write-ups and talks of the participating teams are also available. You can find them at: sites.google.com/view/pgdl20…
1
8
19
Pierre Foret retweeted
This is happening right now!

We will also have a longer event where all participants will present their solutions and participate in a roundtable discussion. This event happens at 2:00 pm EST and will be streamed at: youtu.be/30cF3PhTq-I. We hope to see you there!
1
5
Pierre Foret retweeted
It’s the last day of NeurIPS 👀 The winners of PGDL will be presenting their solutions at the Saturday NeurIPS competition tracks at 12:00 EST (neurips.cc/virtual/2020/publ…). Come to find out what 🔥 generalization measures 🔥 they discovered!
1
4
9
11 Dec 2020
🥳 It is now super easy to fine-tune EfficientNet in FLAX! We open sourced a FLAX version of all officials EfficientNet checkpoints as a by product of our last paper: github.com/google-research/s…
7
65
Pierre Foret retweeted
7 Dec 2020
🔥New state-of-the-art performance on ImageNet recorded by our "Sharpness-Award Minimization" work; a very simple yet effective optimization method. Paper arxiv.org/abs/2010.01412 Performance paperswithcode.com/sota/imag…. w/ @Foret_p @bneyshabur and Ariel Kleiner.
7 Dec 2020
Fine-tuning the EfficientNet l2-475 from the noisy student paper with SAM increases the imagenet accuracy from 88.2% to 88.6%, giving a new state or the art!
With Ariel Kleiner, @TheGradient, and @bneyshabur
paperswithcode.com/sota/imag…
1
9
70
7 Dec 2020
Fine-tuning the EfficientNet l2-475 from the noisy student paper with SAM increases the imagenet accuracy from 88.2% to 88.6%, giving a new state or the art!
With Ariel Kleiner, @TheGradient, and @bneyshabur
paperswithcode.com/sota/imag…
8
45