
vc at @sparkcapital past: head of product at @openai; co-founder/ceo of an AI startup that was acquired by Airbnb
Joined December 2006
- Tweets 330
- Following 266
- Followers 14,132
- Likes 5,043
30 Photos and videos

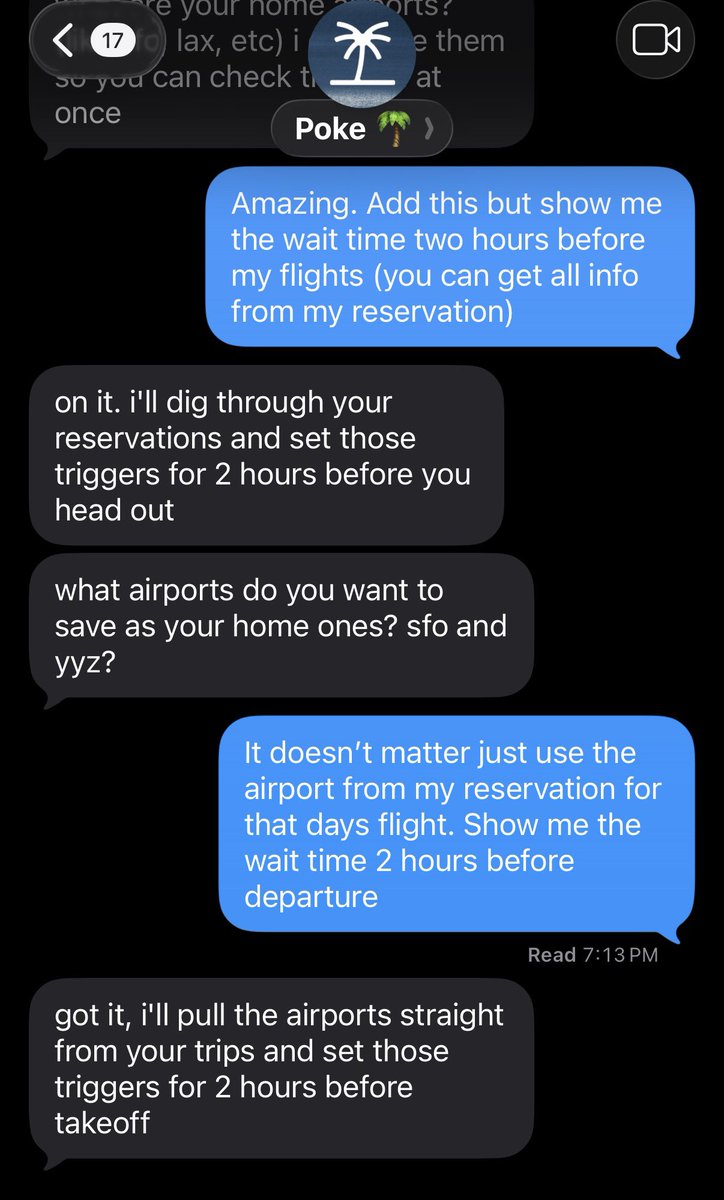










Generalist CEO @peteflorence says robotics models are in a transition period similar to the step change between GPT-2 and GPT-3.
They're "starting to cross over into levels of performance where these things are commercially viable for a number of different applications."
"We think this is a crossover point where we have a general model starting to be able to hit levels of reliability, speed, and improvisational intelligence where we can start to get these things out there."
"Very much like — you take a GPT-2-level model, you scale it to a GPT-3-level model, and certain types of commercial applications start to become viable."
3
18
68
21,575
fraser retweeted

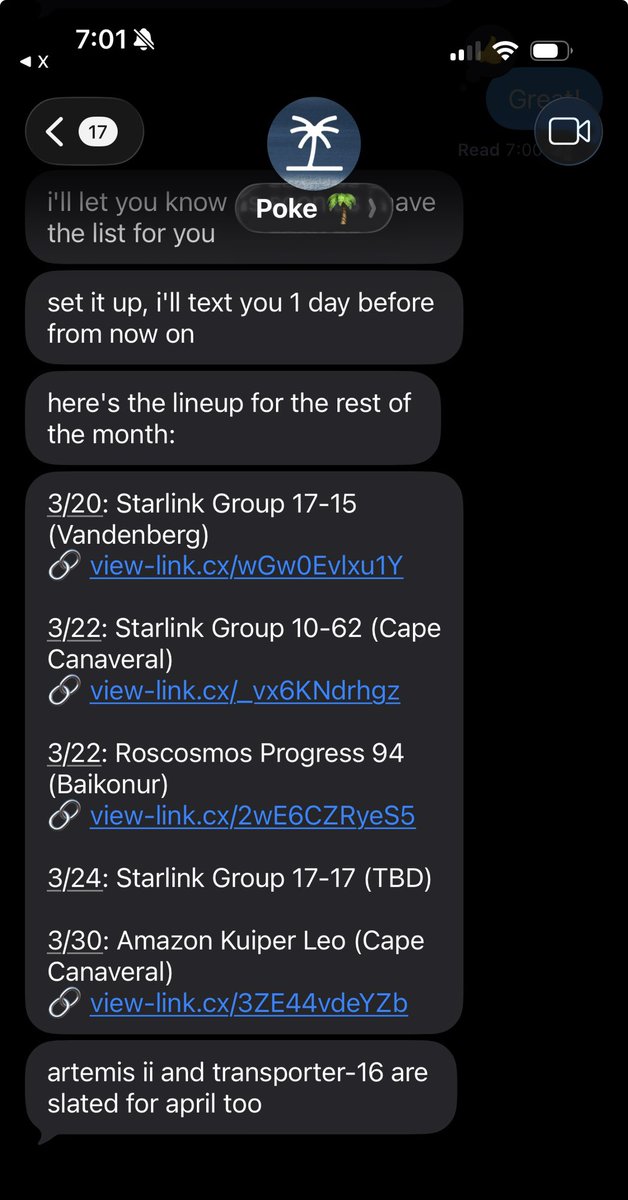
Jun 8
Claim your Poke handle today! 💌
poke.com/claim
- Receive emails rerouted into your Gmail inbox today
- We're gradually rolling out email sending
- There's more to come later this month (samyok.poke.com) 👀
Jun 4

Say hi to the new Poke! 🌴
Now officially approved by Apple to text on Apple Messages.
As the first and only AI agent. Chat now: Poke.com
176
37
733
639,330
fraser retweeted

Jun 6
more love, care, and intentionality has been poured into the smallest minutiae of Poke than is present in any other consumer AI product that exists.
it is a testament to the passion of the @interaction team, and to the triumph of beauty in technology
Jun 4
Say hi to the new Poke! 🌴
Now officially approved by Apple to text on Apple Messages.
As the first and only AI agent. Chat now: Poke.com
6
6
78
9,079
fraser retweeted
Jun 4
Say hi to the new Poke! 🌴
Now officially approved by Apple to text on Apple Messages.
As the first and only AI agent. Chat now: Poke.com
435
248
5,463
4,893,609

As @marvinvonhagen says, Poke is inevitable
Jun 4
Say hi to the new Poke! 🌴
Now officially approved by Apple to text on Apple Messages.
As the first and only AI agent. Chat now: Poke.com
4
1
9
2,313
These models, they just want to learn
Jun 4

We've raised $400M in new funding. This capital goes toward one mission: building general intelligence for the physical world and making it useful to everyone.
1
11
915
fraser retweeted

May 28
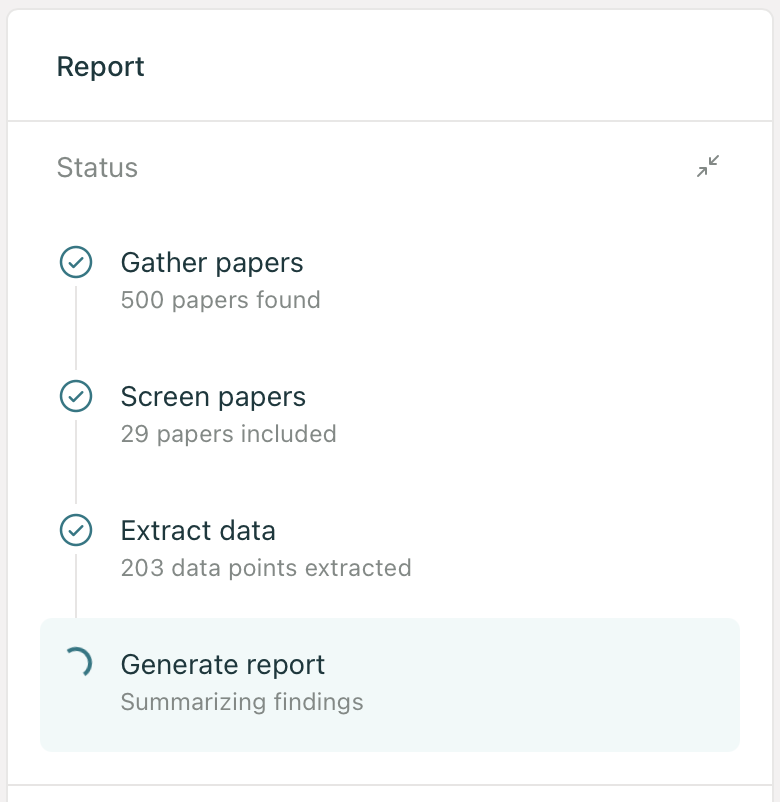
Elicit now has an MCP server. Use it inside Claude, ChatGPT, Copilot, Gemini, and any MCP-compatible tool.
Agents hallucinate when they don't have access to the right evidence. With Elicit's MCP, they search 138M papers and cite instead of guess.
Ask your agent to run a full Elicit research report from inside your existing workflow. It searches, screens, extracts, and produces a shareable report you can build on.
Your agents are only as useful as the evidence they can access. Now they can access Elicit.
Install directly in ChatGPT or ask your agent to read the setup instructions at elicit.com/api
1
7
22
1,659

Most VCs wouldn’t touch Anthropic in 2023.
Yasmin Razavi did.
The Spark Capital partner led a $450M round when Anthropic had no public product, no revenue and a massive capital need. Now the AI giant’s rise has landed her on the Forbes Midas List for the first time. forbes.com/sites/iainmartin/… (Photo: Guerin Blask For Forbes) #ForbesMidas

53
100
889
356,108
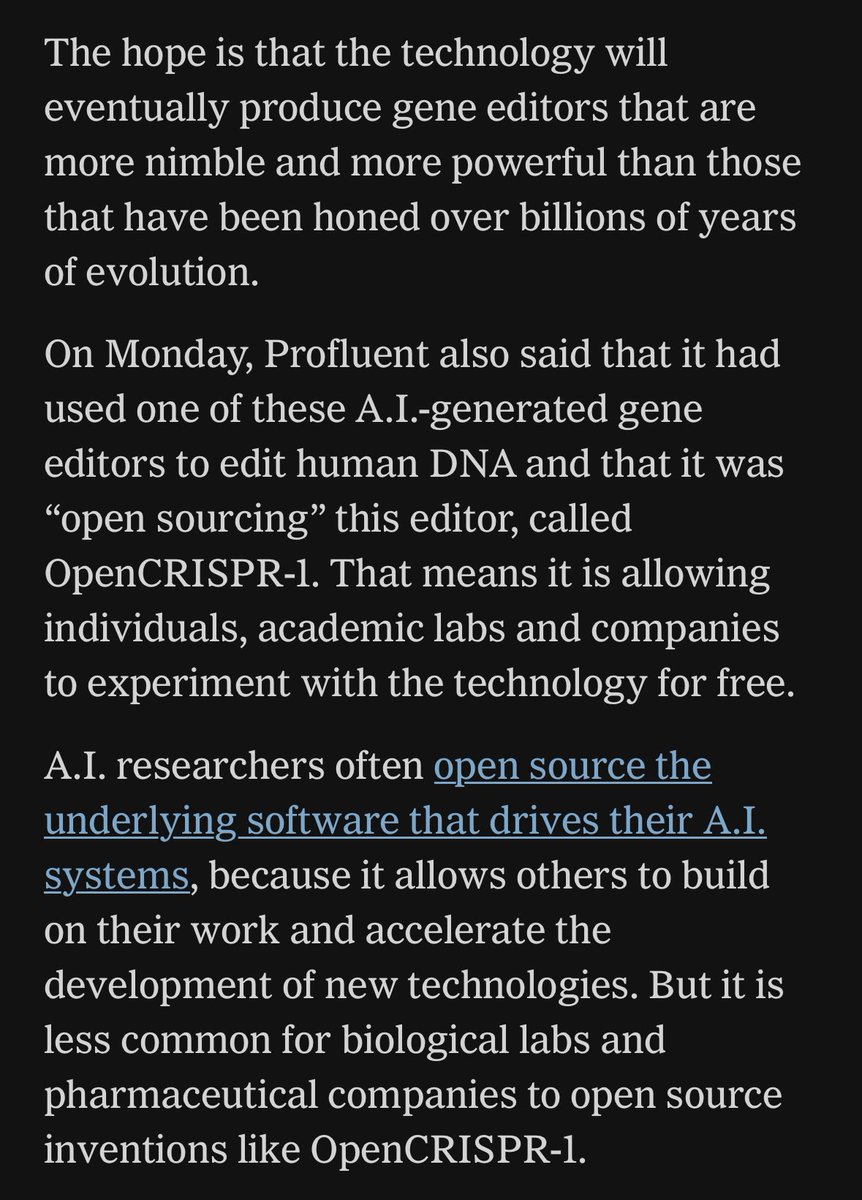
Most AI-in-pharma stories are about going faster. Profluent and Lilly's partnership is a scientific moonshot -- using AI to design large-scale DNA editors for genetic diseases where one-mutation fixes don't work, reaching patients conventional approaches can't
Apr 28

AI has two modes in drug discovery. Accelerate: moving faster through the existing playbook. Unlock: opening frontiers that weren't possible before.
Excited to announce Profluent is partnering with Eli Lilly, the global pharma powerhouse, to unlock breakthrough medicines for patients.
It's a big deal beyond the numbers ($2.25B royalties): we’ll get to use our frontier AI models and foundational datasets to design proteins focused on large gene insertion, a therapeutic moonshot.
Proteins govern almost everything in biology. We've built a generalizable AI platform to design all proteins. Onward!
1
8
1,368
fraser retweeted

Apr 10
5
10
59
16,363
There's enough evidence now that it's all going to work just like LLMs.
"Will it work?" is the wrong question. "How fast?" and "How to do it faster?" become the questions.

Scale is all you need (again). Generalist has pretrained a robotics foundation model from scratch, scaled it up, and it's all working as you'd expect if you truly believe in the scaling hypothesis
The scaling laws they showed previously continue to hold. New capabilities emerge at scale. Some capabilities cross a threshold and are now commercially deployable
generalistai.com/blog/apr-02…
2
18
6,884
Scale is all you need (again). Generalist has pretrained a robotics foundation model from scratch, scaled it up, and it's all working as you'd expect if you truly believe in the scaling hypothesis
The scaling laws they showed previously continue to hold. New capabilities emerge at scale. Some capabilities cross a threshold and are now commercially deployable
generalistai.com/blog/apr-02…
2
4
36
10,615
fraser retweeted

Mar 31
Recent Hallway Chat with @Fraser and I, we chatted about our favorite recent feature from @conductor_build
Instead of submitting a comment you can submit a prompt. And what that implies about the future of software.
Full episode below.
2
3
17
7,112
I’m a daily user of Poke. This type of product — a helpful personal assistant, universally available via messaging — will be one of the most important products of this era.
Text is the universal interface. It’s intuitive, without a learning curve. And while a button can only do what a button says, a text box can do anything the user can articulate. There’s a reason why over the history of the consumer internet only two UI paradigms have reached a billion-user scale: the media feed and the chat interface
Poke.com - now available for everyone
Mar 19
Starting today, personal superintelligence is just one tap away.
No download, no signup.
Text Poke for free now:
Poke.com 🌴
—
0:00 – What's Poke?
0:50 – Introducing Poke Recipes
1:25 – Create a Recipe in 10 seconds
1:43 – Earn on Poke
2:44 – Build with npx poke
12:58 – Recap
13:36 – Parisian Love
6
3
34
7,016
fraser retweeted
Mar 4
The Elicit API is now available in preview for Pro and Teams users. You can search 138M papers and generate Research Reports from your code, scripts, or AI tools.
Get your API key at elicit.com/settings and check out docs.elicit.com

4
7
38
8,348
Little nudges, adjustments, and taps... human intuition that helps us get things done when working with our hands.
@GeneralistAI is showing emergent behavior where the model starts to react, correct, and recover in real-time. Weirdly human to see.

1
1
6
1,450
fraser retweeted
Jan 29
Congrats to Q.ai on the acquisition by Apple, the second largest in their history.
In 2022, Aviad cold emailed out of the blue. He barely even told me what he was up to. But from the very first call it was obvious I had met a force of nature, and a kindred spirit.
These folks have really made magic, oh how I wish this wasn't in stealth so you all could see. But with Aviad & team inside of Apple, the magic is sure to hit us all soon enough.
@sparkcapital are so happy to have had the chance to partner with them. Congrats to the Q team!
reuters.com/business/apple-a…

29
24
478
60,856
fraser retweeted

16 Dec 2025
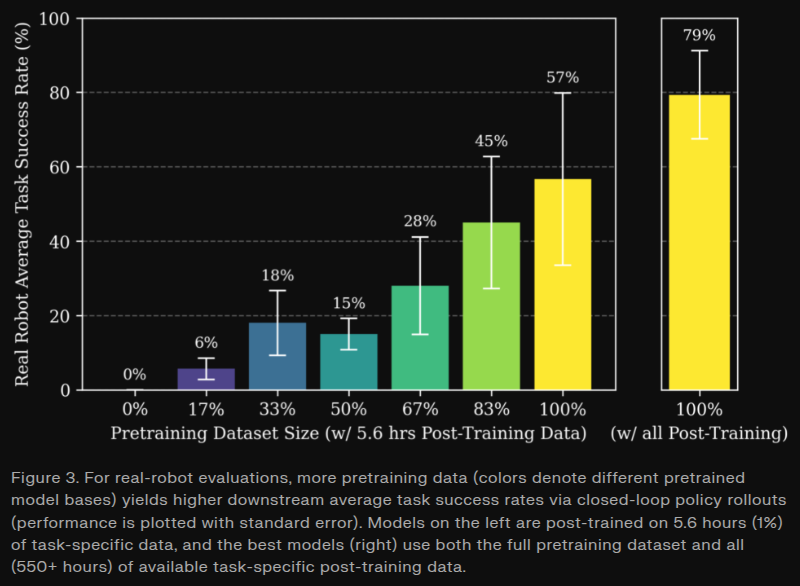
More pretraining improves GEN-0 real-robot performance (via blind A/B evals with closed-loop rollouts).
Improvements are significant in the low-data regime, but the best models thrive with both pretraining and ample post-training.
See blog addendum: generalistai.com/blog/nov-04…
5
27
187
81,221

opus 4.5 for scientific research & automated literature reviews!
26 Nov 2025

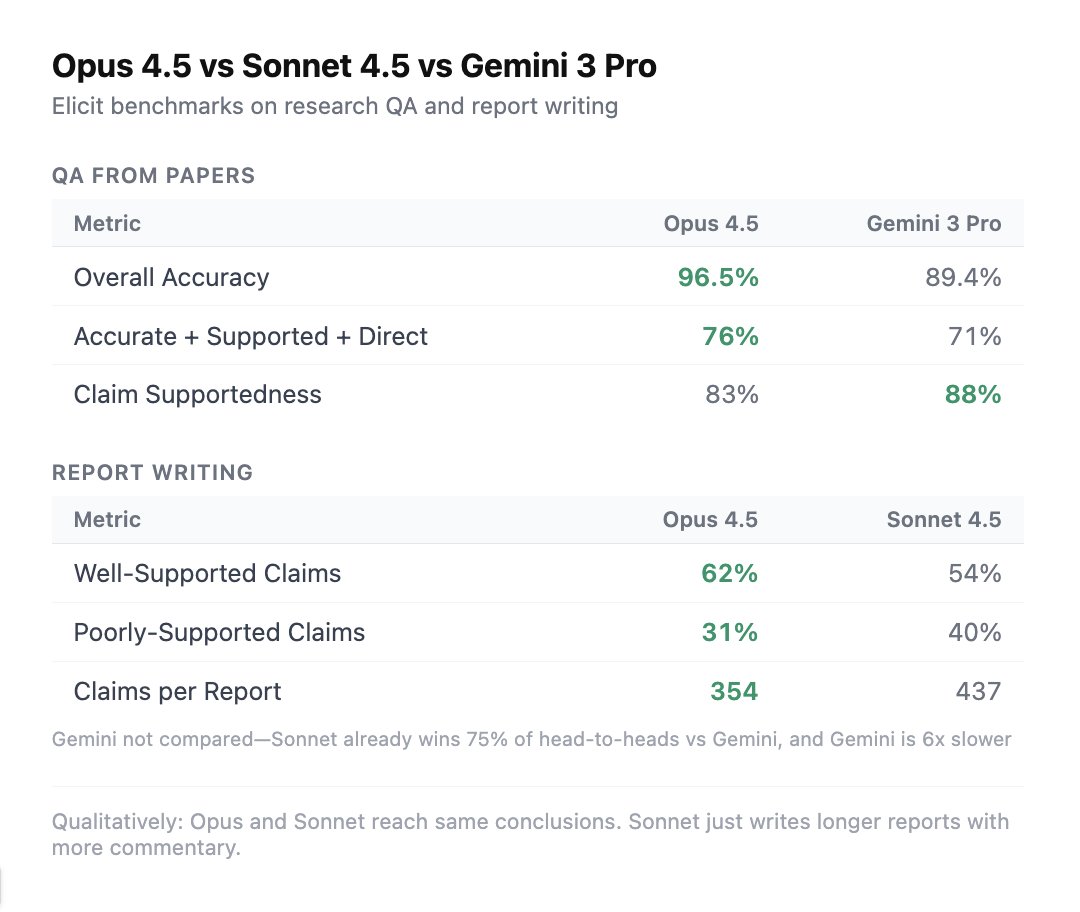
We benchmarked Opus 4.5, Sonnet 4.5, and Gemini 3 Pro on research tasks at Elicit - extracting answers from papers and writing systematic review reports. Results were pretty clear:
*QA from papers:* Opus 4.5 dominates. 96.5% accuracy vs Gemini's 89.4%. Opus is also best on our combined "accurate supported direct" metric (76% vs 71%). Gemini is slightly better on claim supportedness
*Report writing:* Opus 4.5 produces significantly better-supported reports than Sonnet 4.5, the previous best model for this task:
- 62% of claims well-supported vs Sonnet's 54%
- 31% poorly-supported vs Sonnet's 40%
Opus is less verbose and writes ~20% fewer claims per report. We didn't bother comparing to Gemini since Sonnet 4.5 already wins 75% of head-to-head comparisons vs Gemini, and Gemini is 6x slower than Sonnet
Qualitatively, in a manual screen of 5 reports, @PradyuPrasad found that Opus and Sonnet reach the same conclusions with no dramatic differences in output. Sonnet just writes much longer reports with more extensive commentary by default
Opus still has stability issues at scale - we hit a bunch of 529 errors during testing. But once reliability improves, Opus 4.5 looks like the new default for accuracy-critical research workflows
1
27
2,981