
Postdoctoral Fellow @PrincetonPLI. Ph.D. @mldcmu @cmuneurosci. Prev. @yutori_ai @MSFTResearch.
Joined January 2022
- Tweets 224
- Following 724
- Followers 1,131
- Likes 1,066
41 Photos and videos









Pinned Tweet
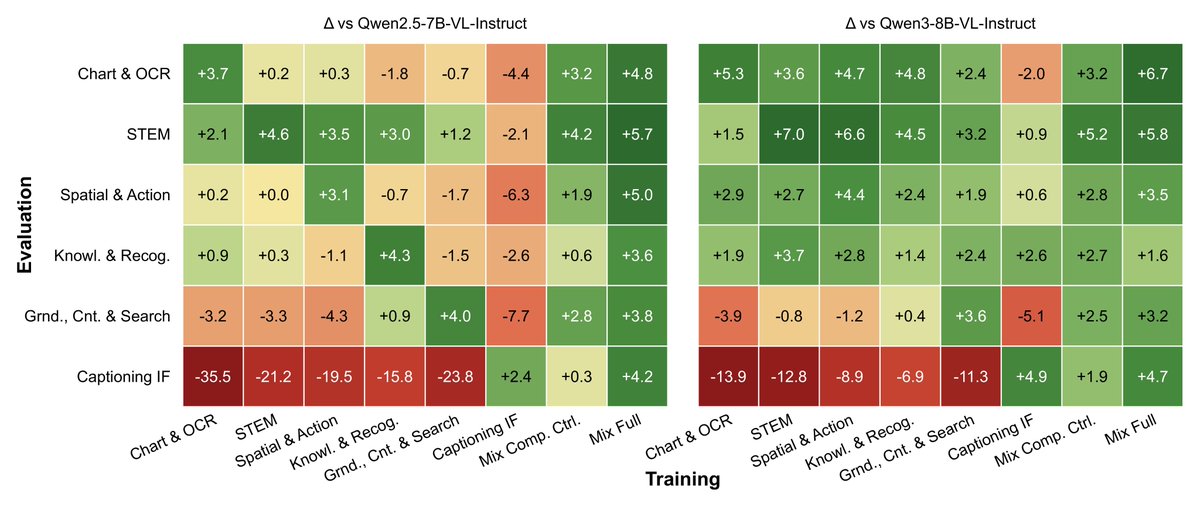
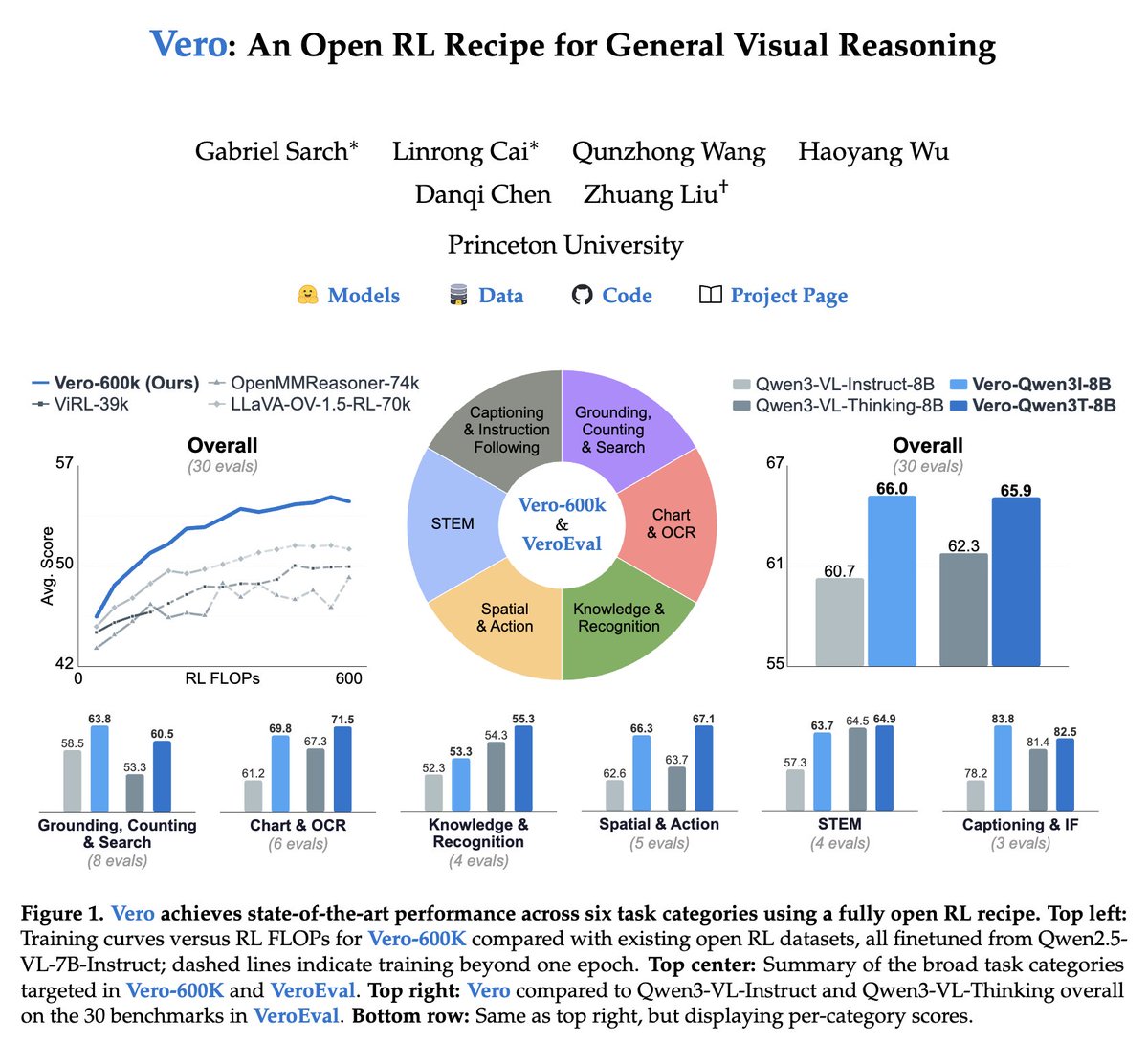
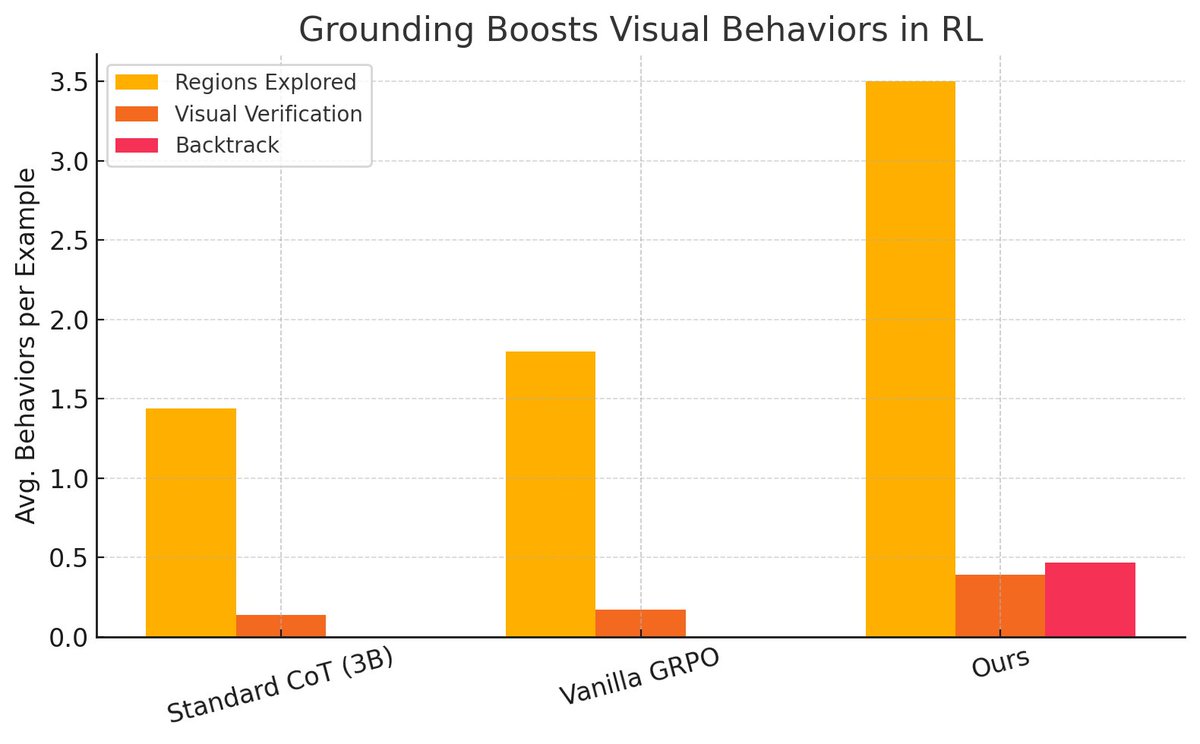
Introducing Vero, the strongest fully open RL recipe for training next-generation visual reasoners.
From charts to spatial to open-ended tasks, Vero sets a new bar.
• sota 8B VLM across 30 benchmarks
• 4.4 avg over four base models (30 evals)
• beats prior RL datasets
🧵👇
3
59
297
62,697
It’s clear VLMs still struggle across diverse visual inputs. Introducing WorldBench, our new VLM benchmark with visually diverse, realistic, and challenging VQA questions! All questions are annotated *by hand* and checked meticulously for quality. Try it out for yourself!

Today’s vision benchmarks suggest VLMs are nearing saturation, but real-world visual understanding is far from solved.
Introducing WorldBench: 2,000 hand-written, human-verified VQA questions focused on visual diversity and designed to be challenging for frontier models. Gemini-3.1-Pro leads with just 64.0% accuracy. (1/10)

1
12
1,135
Great to see this level of transparency from an industry lab. Detailed recipes and reporting like this are a real asset to the research community and the public!

MAI-Thinking-1 is out!
Excited to share what we are building and how climbing from scratch (no distillation) actually works: simple recipes, rigorous science, self-distillation, patience, and great infra.
Check out our tech report has the full story of our RL climbs.
microsoft.ai/wp-content/uplo…

16
1,067
I’ll be at CVPR June 3-6 and excited to talk with folks!
We’ll be presenting Vero at June 3 workshops (vero-reasoning.github.io):
- DataMFM Oral 2:40pm, Room 111
- MMFM Poster, 3pm, 3A
- ViScale Poster, 5pm, 506
And be sure to come by the CogVL Workshop cogvl.github.io!
11
840
Gabriel Sarch retweeted

CogVL Workshop at #CVPR2026 is less than a week away!
We have an exciting lineup of keynote speakers across Vision, NLP and Cog Sci, and orals/posters on reasoning methods for VLM models.
🕐 June 3, 1 PM
📍 Rooms 610/612
🔗 Schedule: cogvl.github.io

1
3
4
933

May 20
Happy to be recognized as an outstanding reviewer at CVPR!

We are grateful to all of the 17,491 reviewers who helped make #CVPR2026 possible. We are especially pleased to recognize the following Outstanding Reviewers, whose high-quality reviews (as judged by their Area Chairs) placed them among the top 5% of reviewers.



11
835
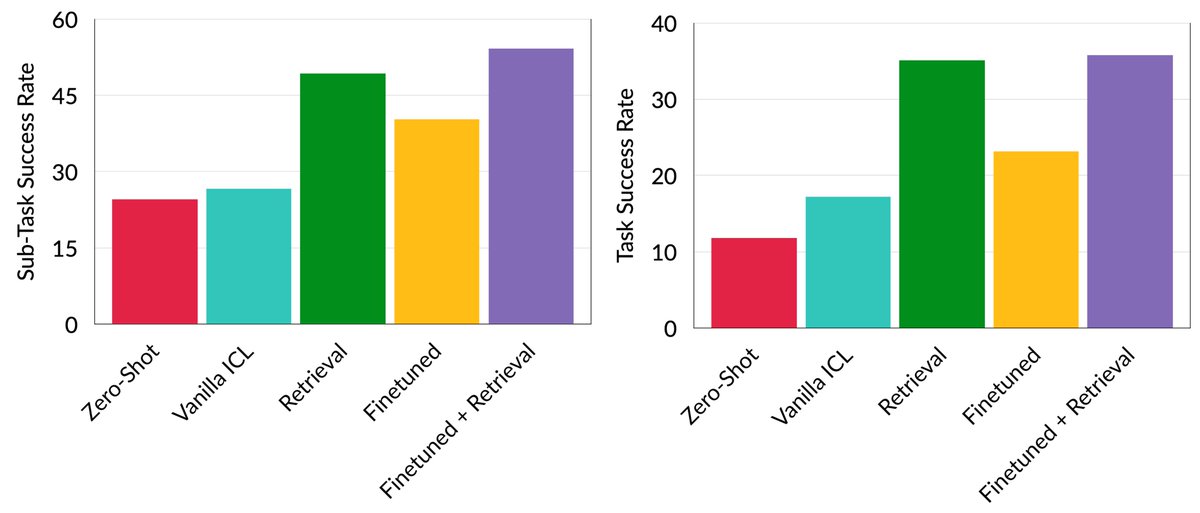
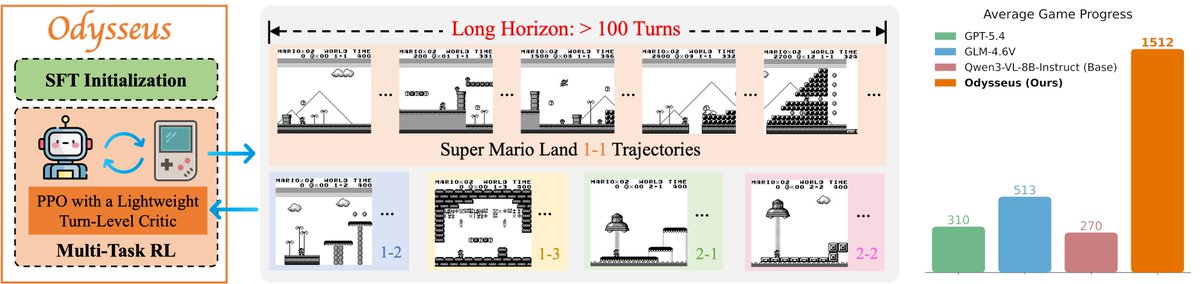
Really excited about this new work scaling VLMs to 100 turns for playing Mario! Games are a great testbed for long-horizon agentic tasks, and this setting makes it clear the default short-horizon tricks for VLM training often fall short. Check out the thread and paper!

🔥 Excited to share our new paper:
🚀 Odysseus: Scaling VLMs to 100 Turn Decision-Making in Games via Reinforcement Learning
🎮 We study how to make RL stable and effective for training VLM agents in long-horizon, visually grounded environments — using the video game Super Mario Land as a testbed.
📜 Paper: arxiv.org/abs/2605.00347
🔗 Project page (w/ video demos): odysseus-project.github.io/
2
12
1,949
Gabriel Sarch retweeted

Apr 29
AI agents can work pretty well on the web now for short tasks. I wanted to know: could they go longer, on harder tasks?
Can an agent plan 2 weddings in different cities and a honeymoon within the same month, or find the most suitable culinary arts school across the US for my post PhD plans?
We are releasing Odysseys: a benchmark of 200 long-horizon web agent tasks evaluated on the live internet. All our tasks are inspired from real human data and many take hours to complete.
The best frontier model we tested (Claude Opus 4.6) reaches only 44.5% perfect-task success, leaving substantial room for improvement.
I donated a couple of my own automation wishes to this benchmark. My favorite contribution was to “Rank the top 10 ACL Meniscus surgeons in the area” - as this took me a decent amount of time to do myself when I got my own knee fixed. GPT 5.5 was able to do this for me with 4 dollars and 30 minutes!
2
12
33
17,790
Gabriel Sarch retweeted

Apr 17
Hi all. I just put up my course materials for my Multimodal LLM Agents course at @UUtah online so it can be used by the broader community. I really tried to tie together LLMs with RL and CV to give students the full picture of how MLLMs can be incorporated into embodied agents.
1
6
23
2,006
Gabriel Sarch retweeted

Apr 14
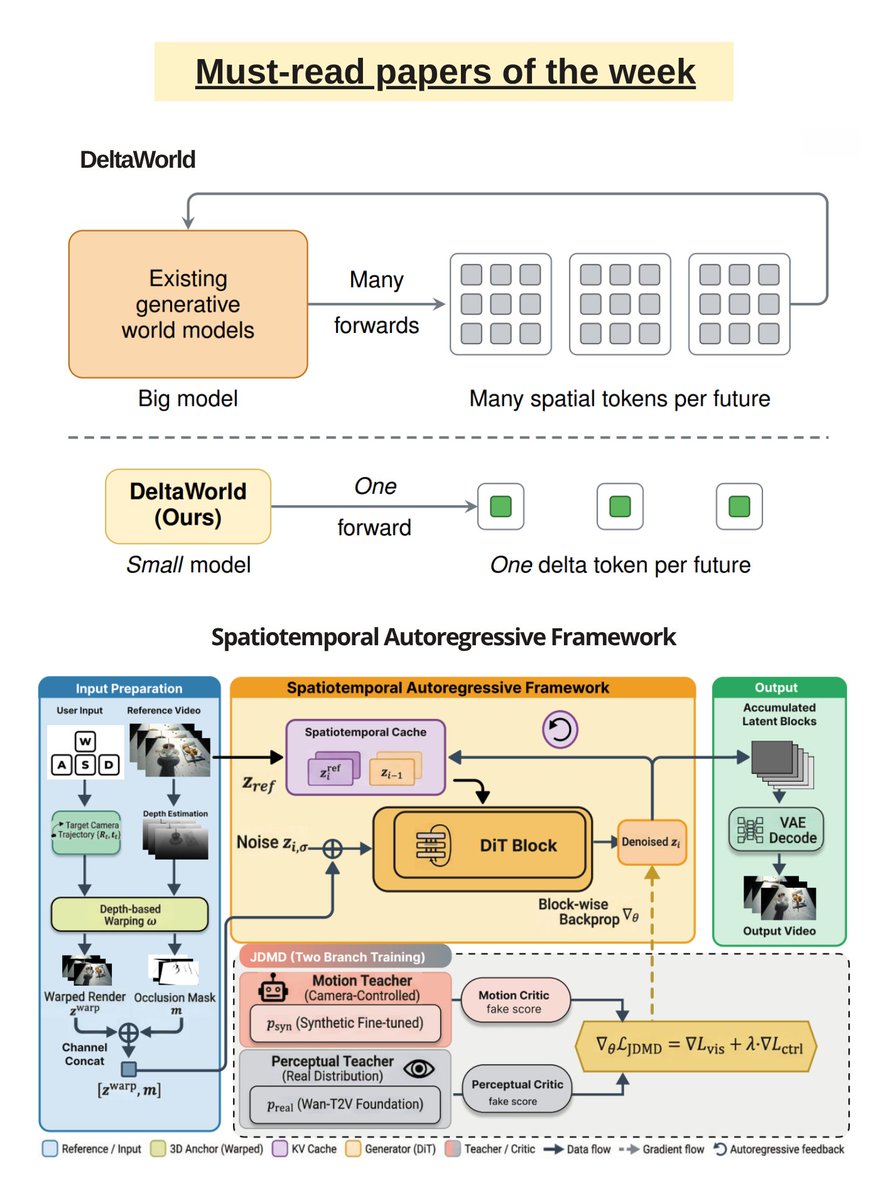
Must-read research of the week
▪️ Neural Computers
▪️ The Illusion of Stochasticity in LLMs
▪️ Learning is Forgetting: LLM Training as Lossy Compression
▪️ A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens
▪️ INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
▪️ Vero: An Open RL Recipe for General Visual Reasoning
▪️ RAGEN-2: Reasoning Collapse in Agentic RL
▪️ TriAttention: Efficient Long Reasoning with Trigonometric KV Compression
▪️ In-Place Test-Time Training
▪️ Fast Spatial Memory with Elastic Test-Time Training
▪️ Gym-Anything: Turn any Software into an Agent Environment
▪️ SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
▪️ PaperOrchestra: A Multi-Agent Framework for Automated AI Research Paper Writing
Find all the links and other important AI news of the week here: turingpost.com/p/fod148
6
78
317
18,155
Gabriel Sarch retweeted

aimodels.fyi/papers/arxiv/ve…
> be me
> open source researcher
> everyone making amazing vision AI but won't share how
> "just trust me bro it works"
> decide to build our own and document everything
> call it Vero
> actually works
> tfw transparency wins
> recipe.pdf
1
1
107
Gabriel Sarch retweeted

Apr 7
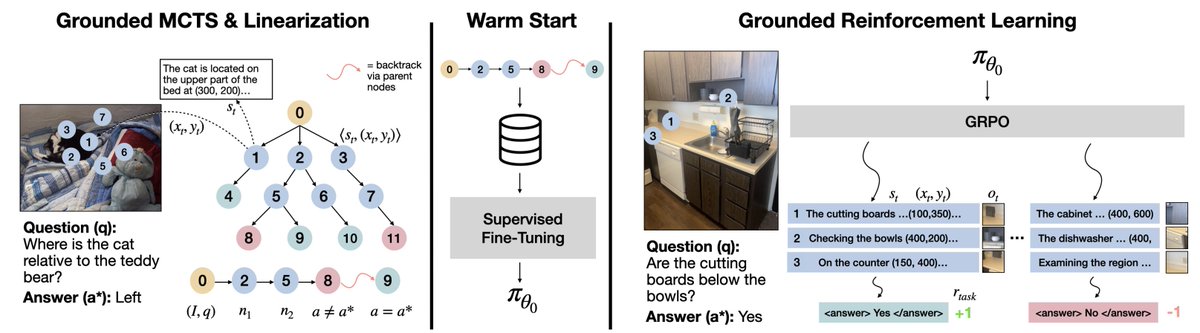
My biggest takeaway from this project: even in an academic setting, with the right people and dedication, we can catch up with part of what top industry teams have achieved. Vero's final training run only takes 8 GPUs.
Vero only addresses the RL reasoning stage, but it proves that a lot is still very much possible in academia!

Introducing Vero, the strongest fully open RL recipe for training next-generation visual reasoners.
From charts to spatial to open-ended tasks, Vero sets a new bar.
• sota 8B VLM across 30 benchmarks
• 4.4 avg over four base models (30 evals)
• beats prior RL datasets
🧵👇
5
22
185
22,509
Gabriel Sarch retweeted
Apr 7
Today we release Vero for visual reasoning.
Open data, open training code, and open weights!
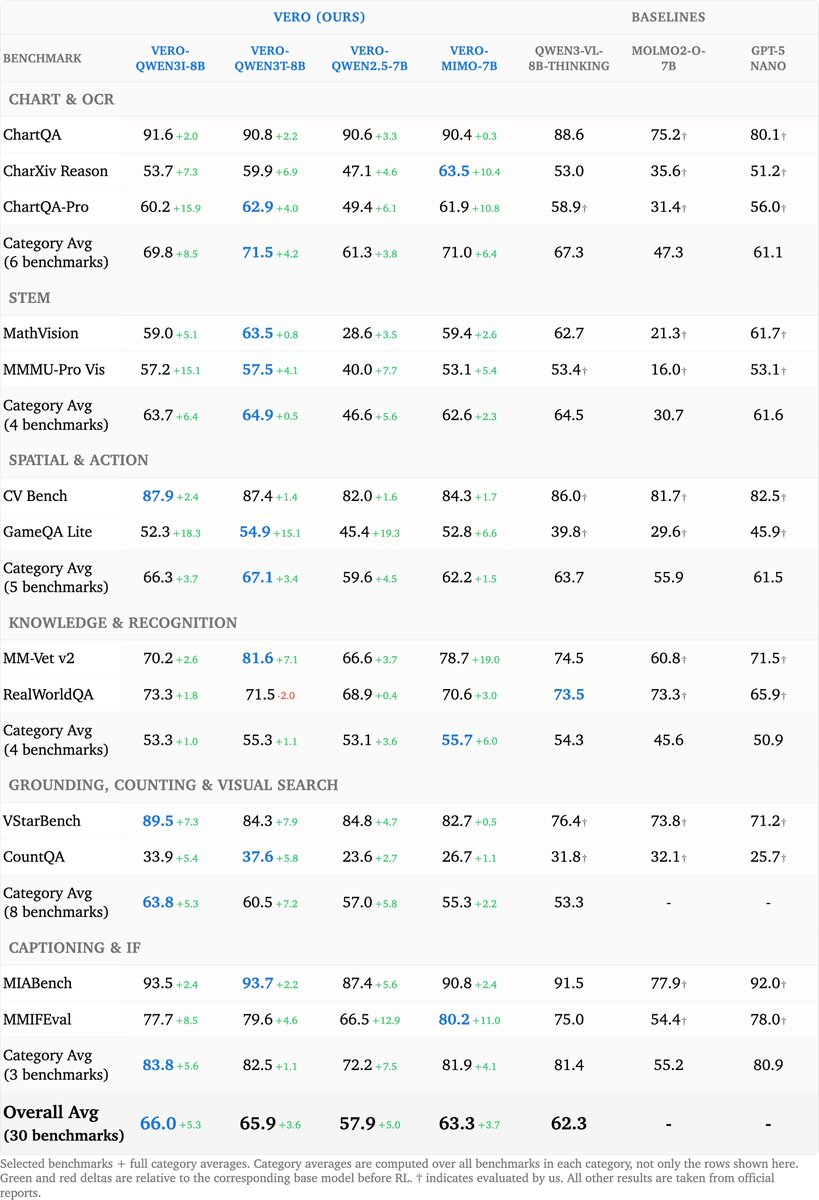
Vero is the strongest open-weight 8B VLM on average across 30 benchmarks.
Vero reasons broadly across six diverse visual domains, from charts and science to spatial understanding and open-ended tasks.
Introducing Vero, the strongest fully open RL recipe for training next-generation visual reasoners.
From charts to spatial to open-ended tasks, Vero sets a new bar.
• sota 8B VLM across 30 benchmarks
• 4.4 avg over four base models (30 evals)
• beats prior RL datasets
🧵👇
2
24
113
17,513
Introducing Vero, the strongest fully open RL recipe for training next-generation visual reasoners.
From charts to spatial to open-ended tasks, Vero sets a new bar.
• sota 8B VLM across 30 benchmarks
• 4.4 avg over four base models (30 evals)
• beats prior RL datasets
🧵👇
3
59
297
62,697
Vero wouldn’t be possible without the team: co-lead @CaiLinrong, @HaoyangWuX, @qunzhongwang, and PIs @liuzhuang1234 and @danqi_chen.
Everything is public to support further research on broadly-capable VLMs and multi-task visual RL!
1
4
1,140
Paper: arxiv.org/abs/2604.04917
Project page (w/ demos): vero-reasoning.github.io
Code: github.com/zlab-princeton/ve…
Data: huggingface.co/datasets/zlab…
Models: huggingface.co/collections/z…
10
1,065