
A Sr director of AI research at NVIDIA and a CS Prof. at Bar-Ilan U. I study learning for reasoning and perception.
Joined July 2018
- Tweets 185
- Following 395
- Followers 999
- Likes 270
6 Photos and videos


Gal Chechik retweeted

Jun 9
🎉 Happy to share our latest work: Bootstrap Your Generator: Unpaired Visual Editing with Flow Matching (accepted to #ICML2026)!
TL;DR: We train image and video editing models without any paired data.
No ground-truth edit data, no external reward models.
6
14
36
4,682

Feb 6
Thank you for explaining our work so wonderfully well!

I felt like Indiana Jones unearthing a hidden treasure with this. 🤠 NVIDIA's new AI tech deletes the un-deletable - shadows on grass and more. All this in real time! Full video: youtu.be/RaNay3x0Fmk

3
421
Gal Chechik retweeted

3 Dec 2025
It's amazing to see how far ProtoMotions has come since it's first release. If you are looking for a feature-rich and scalable framework that can train controllers on massive datasets, then checkout ProtoMotions!
3 Dec 2025

At @nvidia, we built ProtoMotions to help us, and researchers world-wide, innovate quickly without compromising on applicability.
We're proud to announce ProtoMotions3 -- our biggest release yet!
🧵👇
2
10
88
8,798
Gal Chechik retweeted

3 Dec 2025
At @nvidia, we built ProtoMotions to help us, and researchers world-wide, innovate quickly without compromising on applicability.
We're proud to announce ProtoMotions3 -- our biggest release yet!
🧵👇
8
53
267
52,694

🎉 I am excited to present our new paper!
Our paper improves personalization of text-to-image models, by adding one special cleaning step on top of existing personalized models.
With just a single gradient update (~4 seconds on an NVIDIA H100 GPU) and a single image of the target concept, our method improves both text alignment and image alignment. For example, it improves LoRA by ( 7% / 14%). This is achieved by adding new loss terms and taking into account the prompt and seed.
This work was done together with @dvir_samuel and @GalChechik.
🌐 Paper page: per-query-visual-concept-lea…
📄 arXiv paper: arxiv.org/abs/2508.09045
More details in the comments below.

4
10
17
1,008
Gal Chechik retweeted

24 Aug 2025
What if video editing took seconds instead of hours? OmnimatteZero – by @dvir_samuel Prof. @GalChechik from @Bar_ilan, HUJI & OriginAI – Removes dynamic objects with their shadows and reflections, separates layers, and reinserts them in real time.
👉 arxiv.org/abs/2503.18033

3
6
386
25 Mar 2025
How do generative models represent the notion of "an object"?
In early 20th century, Gestalt psychologist studied this question for human perception.
This paper now looks into related mechanisms in text-to-video models.
25 Mar 2025

🚀 Excited to share OmnimatteZero: Training-Free Real-Time Omnimatte with Video Diffusion Models!
📄 Paper: arxiv.org/abs/2503.18033
🌐 Project: dvirsamuel.github.io/omnimat…
🧵👇
1
13
1,069
24 Mar 2025
Personalizing image generation from a single image is still very hard. Check out this paper
24 Mar 2025

🚀Introducing SISO – a plug-and-play approach for image personalization using just one image!

1
22
1,691
Gal Chechik retweeted

5 Mar 2025
This morning, I had the pleasure of attending #EMTech Europe 2025 in Athens, an international conference on emerging technologies.
Sr. Director of @NVIDIA, Israeli @GalChechik , gave a fascinating talk on the future of #AI, moderated by @yanpal7 of @kathimerini_gr , highlighting its transformative impact across industries in our lives. Innovation which is defining our future.

1
5
19
742
3 Mar 2025
Teach your text-to-image model to count
3 Mar 2025

🎉 I'm happy to share that our paper, Make It Count, has been accepted to #CVPR2025!
A huge thanks to my amazing collaborators - @YoadTewel, @SegevHilit , @hirscheran, @RoyiRassin, and @GalChechik!
🔗 Paper page: make-it-count-paper.github.i…
Excited to share our key findings!
7
721
Gal Chechik retweeted

3 Mar 2025
🎉 I'm happy to share that our paper, Make It Count, has been accepted to #CVPR2025!
A huge thanks to my amazing collaborators - @YoadTewel, @SegevHilit , @hirscheran, @RoyiRassin, and @GalChechik!
🔗 Paper page: make-it-count-paper.github.i…
Excited to share our key findings!
2
18
56
8,863
8 Jan 2025
It's always a bit stressful: Testing a pre-trained model on new datasets, with a different population and setup. Gluformer predictions were beyond what we hoped for!
8 Jan 2025

We have a new and revised GluFormer manuscript! We expanded our analyses considerably: now showing that our AI model for CGM can identify individuals at higher risk of declining glycemic control before it happens, and can predict long-term diabetes & cardiovascular mortality.

3
16
1,325
Gal Chechik retweeted

8 Jan 2025
We have a new and revised GluFormer manuscript! We expanded our analyses considerably: now showing that our AI model for CGM can identify individuals at higher risk of declining glycemic control before it happens, and can predict long-term diabetes & cardiovascular mortality.
1
13
36
7,665
Gal Chechik retweeted
4 Nov 2024
🚀 Excited to release the code and demo for ConsiStory, our #SIGGRAPH2024 paper!
No fine-tuning needed — just fast, subject-consistent image generation!
Check it out here 👇
Code: github.com/NVlabs/consistory
Demo: build.nvidia.com/nvidia/cons…

Nvidia presents ConsiStory
Training-Free Consistent Text-to-Image Generation
paper page: huggingface.co/papers/2402.0…
enable Stable Diffusion XL (SDXL) to generate consistent subjects across a series of images, without additional training.
1
33
137
22,569
Gal Chechik retweeted
20 Oct 2024
MaskedMimic pre-trained model public release 🧑🎄
github.com/NVlabs/ProtoMotio…
Some info in the thread on how to play with the model
1/
22 Sep 2024
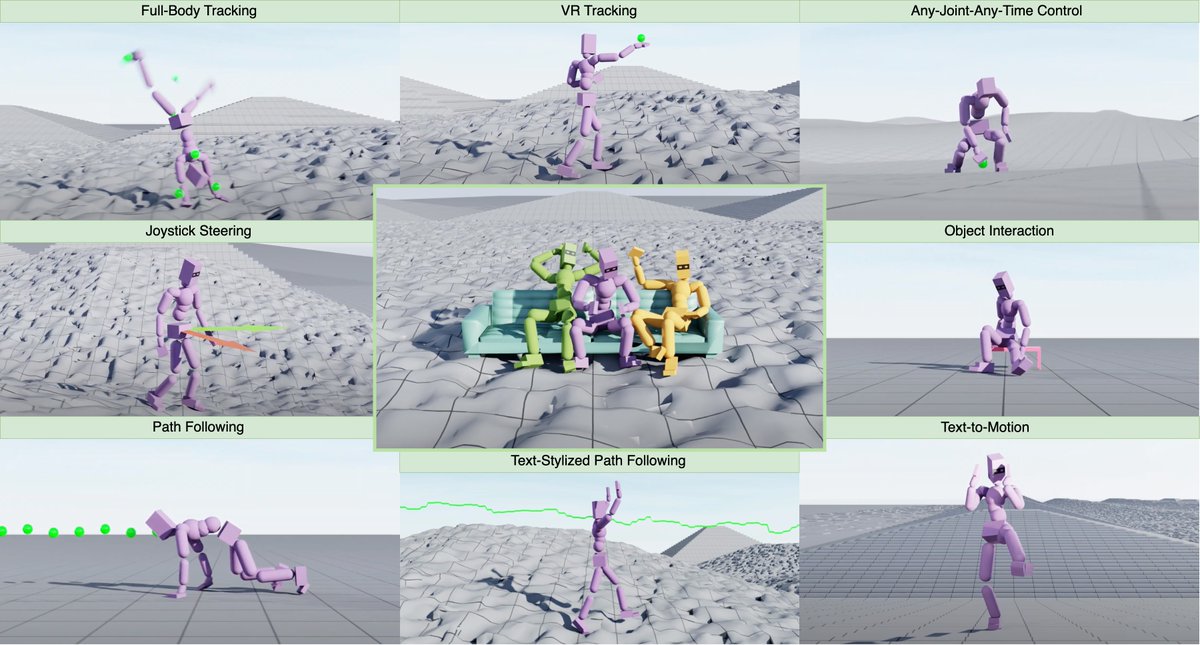
Excited to share our latest work! 🤩
Masked Mimic 🥷: Unified Physics-Based Character Control Through Masked Motion Inpainting
Project page: research.nvidia.com/labs/par…
with: Yunrong (Kelly) Guo, @ofirnabati, @GalChechik and @xbpeng4.
@SIGGRAPHAsia (ACM TOG).
1/ Read along! 😃
4
23
161
20,058
3 Oct 2024
Interesting #ECCV2024 keynote on distribution shift. @sanmikoyejo discussed interpolation and extrapolation.
There is a 3rd case: Composition. Interpolate for each component but extrapolate the combination.
Can we do better with composition than worst-case extrapolation?
1
10
742

TL;DR - we improve text-to-image output quality by tuning an LLM to predict ComfyUI workflows tailored to each generation prompt
Project page: comfygen-paper.github.io/
Paper: arxiv.org/abs/2410.01731
[1\4]


13
74
393
41,676
At inference, just give the LLM a new prompt a high score, and predict a prompt-specific flow.
For more info, please read our paper or come find us at @eccvconf
Work done with my amazing collaborators @adihaviv @yuvalalaluf, Amit Bermano,
@DanielCohenOr1 and @GalChechik
[4/4]

2
10
1,263
Gal Chechik retweeted

1 Oct 2024
Thrilled to share that our paper, "Where's Waldo: Diffusion Features for Personalized Segmentation and Retrieval" has been accepted to NeurIPS 2024! 🎉
Paper: arxiv.org/abs/2405.18025
Project Page: dvirsamuel.github.io/pdm.git…
#NeurIPS2024
@GalChechik @RamiBenAri1 @MatanLvy

2
16
30
1,204
22 Sep 2024
Animators of human motion want to control some aspect of the movement, and not bother with others.
MaskedMimic does exactly that using physics-based models. Check out the code and video
22 Sep 2024
Excited to share our latest work! 🤩
Masked Mimic 🥷: Unified Physics-Based Character Control Through Masked Motion Inpainting
Project page: research.nvidia.com/labs/par…
with: Yunrong (Kelly) Guo, @ofirnabati, @GalChechik and @xbpeng4.
@SIGGRAPHAsia (ACM TOG).
1/ Read along! 😃
1
7
579