
State-of-the-art generalisation testing in NLP. Tag us for a RT of your NLP generalisation paper tweet!
Joined April 2022
- Tweets 193
- Following 15
- Followers 432
- Likes 104
72 Photos and videos















The GenBench workshop is back! Do you work on generalisation (benchmarking) in #NLProc? Submit to the 2nd edition (genbench.org/workshop/) co-located with #EMNLP2024. We have a regular track and a ✨collaborative benchmarking task (CBT)✨ that's fully LLM-focused this year (1/6)
1
11
22
12,569
That's a wrap! We (@glnmario, @christos_c, @_dieuwke_, @vernadankers, @khuyagbaatar_b, @a_kazemnejad & @ryandcotterell) thank all presenters, authors, reviewers and attendees!! The keynotes, the cats 😻, the posters, the talks and the lively panel: it was fantastic👏 🔥
6
46
2,876
GenBench retweeted

16 Nov 2024
so proud of @HayleyRossLing for getting a best paper award at @GenBench this year!! 🎉🪅🎉 I'm sure @TeaAnd_OrCoffee would be too :) check out our paper and share if you think homemade cats are cats!

24 Oct 2024

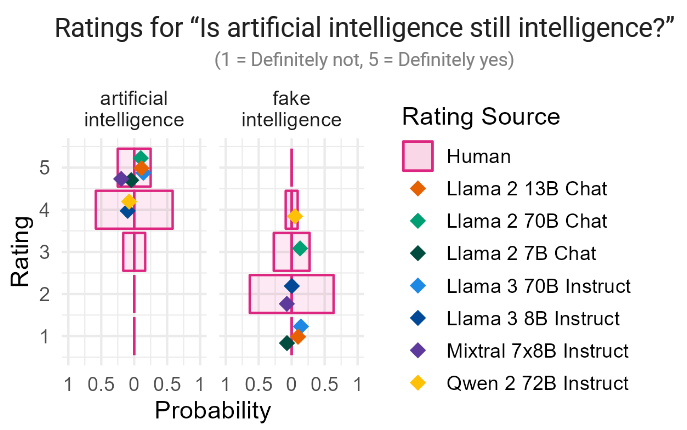
New paper with @najoungkim and @TeaAnd_OrCoffee testing if LLMs can draw adjective-noun inferences like humans! Turns out they often can, and even generalize to unseen combinations. But they're more optimistic about "artificial intelligence" than humans.
arxiv.org/abs/2410.17482
1
5
60
3,473
GenBench retweeted

16 Nov 2024


1
16
1,271
Congratulations!
16 Nov 2024

so proud of @HayleyRossLing for getting a best paper award at @GenBench this year!! 🎉🪅🎉 I'm sure @TeaAnd_OrCoffee would be too :) check out our paper and share if you think homemade cats are cats!
3
237

Come listen to the hot takes of our panelist in the Brickell room! Do we still need generalisation evaluation? 🧐 #GenBench2024 #EMNLP2024
3
15
1,491
Did you miss the GenBench poster session? Don't worry we've got you, here are (nearly all) posters! 😉 #GenBench2024 #EMNLP2024 Next up: keynote by Sameer Singh at 3!
1
13
830
Spotlight time! Mirella Bueno on
MLissard: Multilingual Long and Simple Sequential Reasoning Benchmarks
aclanthology.org/2024.genben…
1
1
3
535
Continuing with Bastian Bunzeck, presenting
The SlayQA benchmark of social reasoning: testing gender-inclusive generalization with neopronouns
aclanthology.org/2024.genben…
1
3
86
Last spotlight presentation:
MMLU-SR: A Benchmark for Stress-Testing Reasoning Capability of Large Language Models
aclanthology.org/2024.genben…
Unfortunately the authors couldn't make it, the work is kindly presented by their colleague Hengyi Wang 🙏
1
71
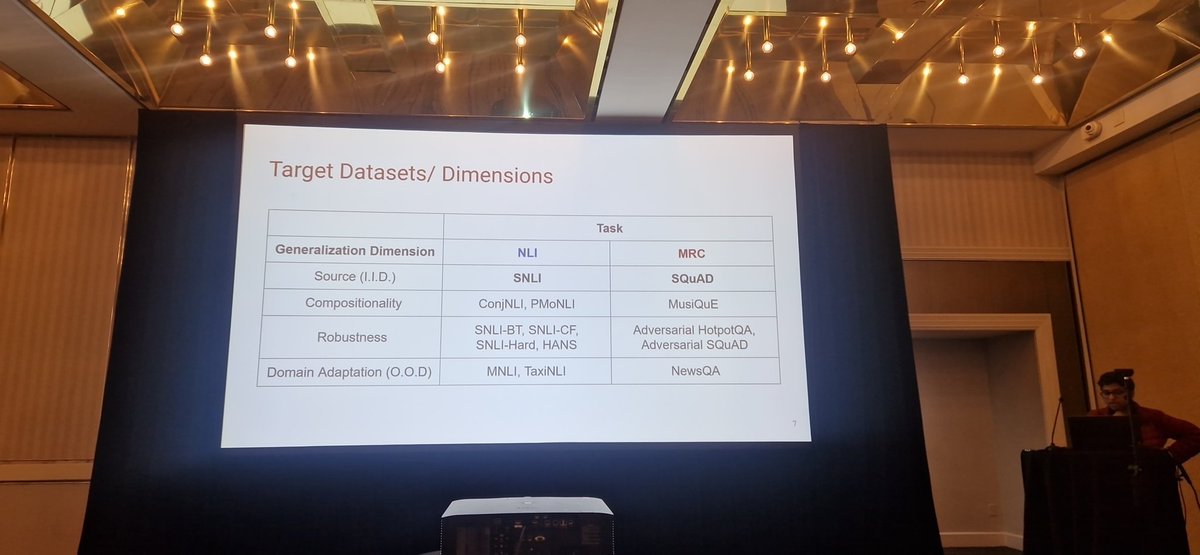
Oral presentation two with @sagnikrayc
Investigating the Generalizability of Pretrained Language Models across Multiple Dimensions: A Case Study of NLI and MRC
aclanthology.org/2024.genben…

1
2
7
916