
language models, mts @MicrosoftAI, ex co-lead of Olmo @allen_ai, @uwcse, he/him, kylelo.bsky.social🧋
- Tweets 935
- Following 1,484
- Followers 4,663
- Likes 3,129









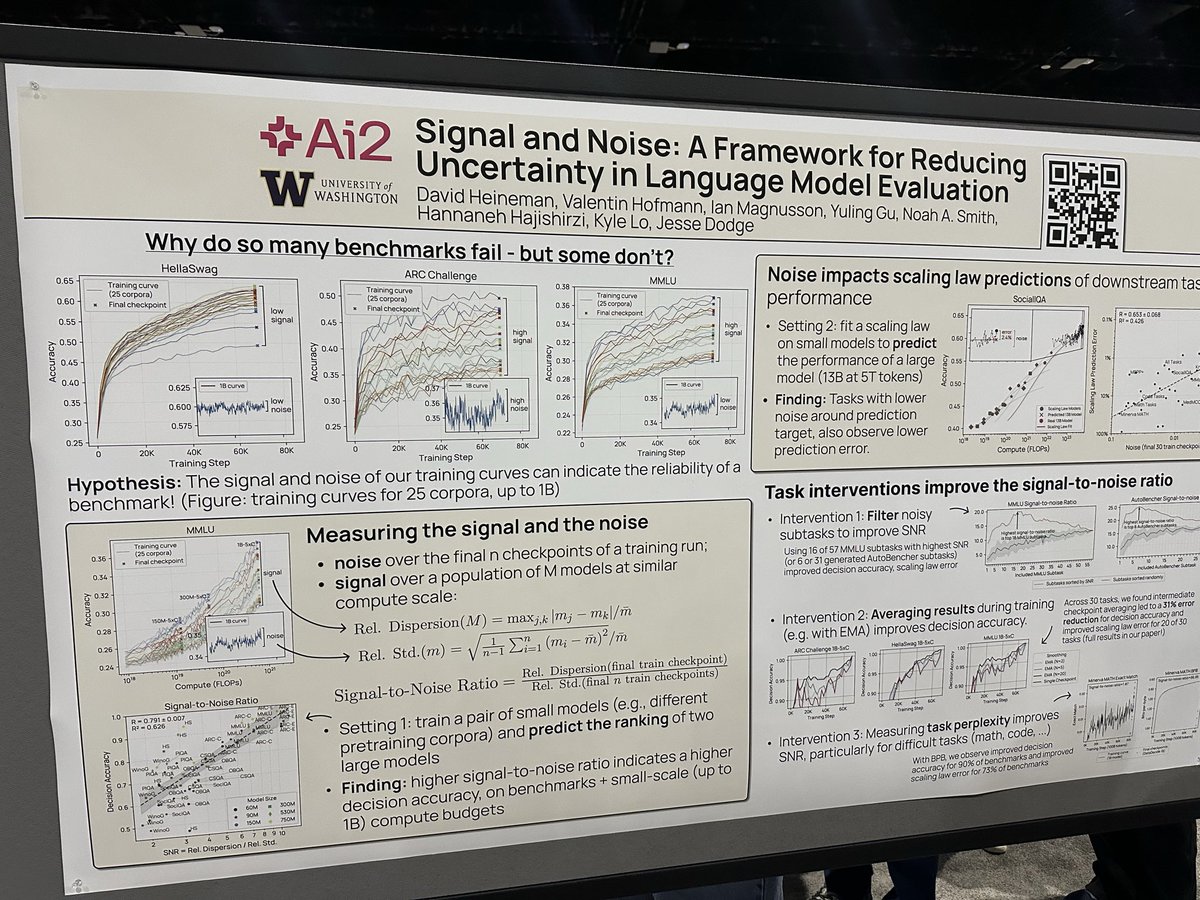





















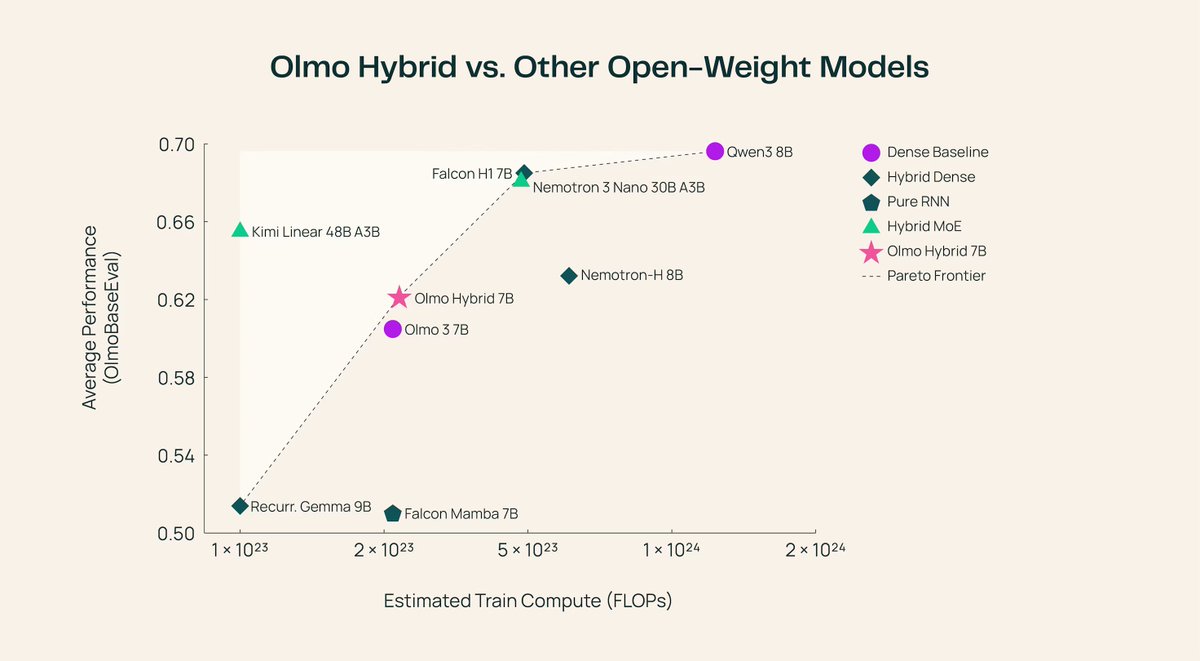

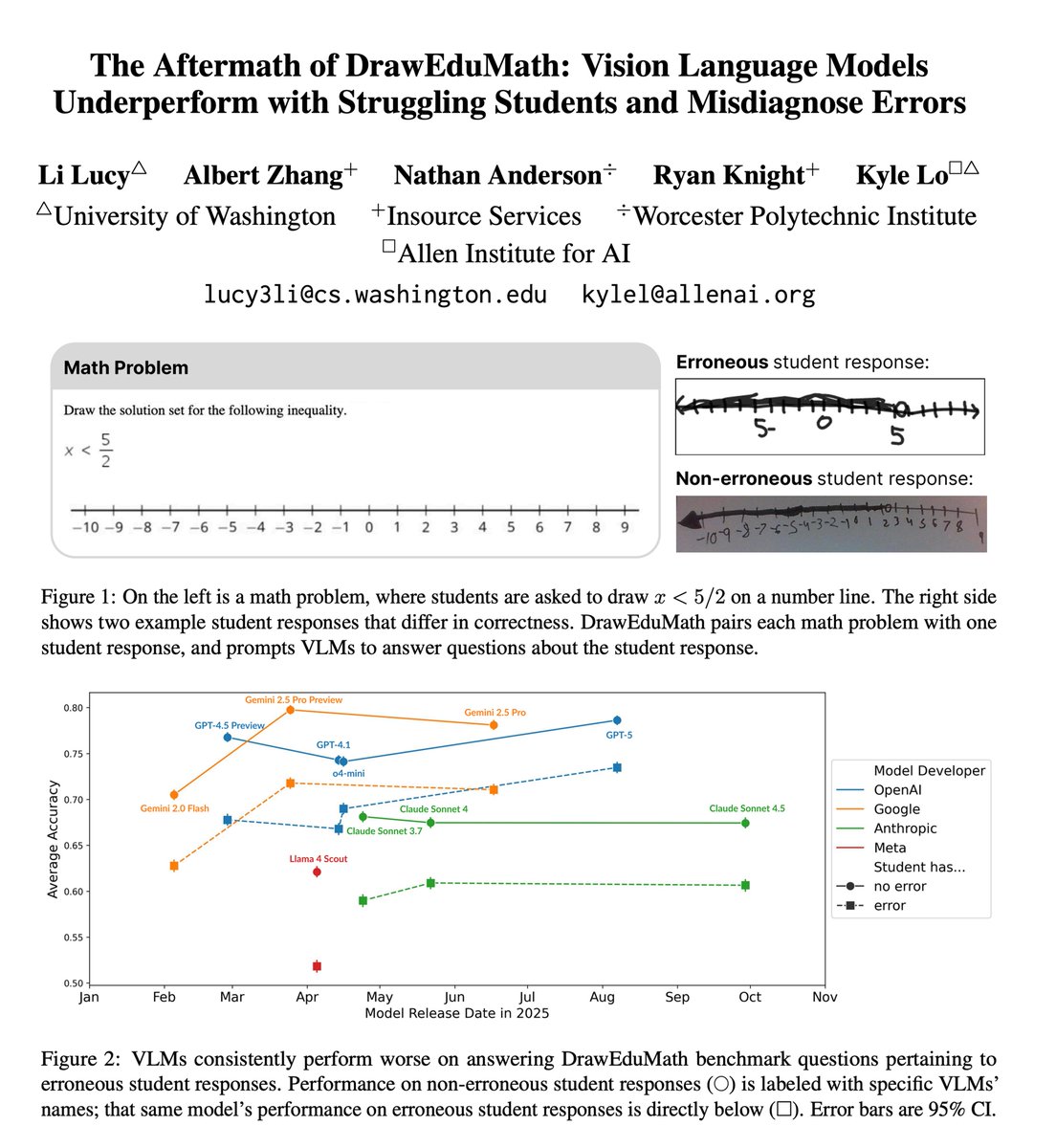
ALT Title, author list, and two figures from the paper. Title: The Aftermath of DrawEduMath: Vision Language Models Underperform with Struggling Students and Misdiagnose Errors Authors: Li Lucy, Albert Zhang, Nathan Anderson, Ryan Knight, Kyle Lo Figure 1: On the left is a math problem, where students are asked to draw x < 5/2 on a number line. The right side shows two example student responses that differ in correctness. DrawEduMath pairs each math problem with one student response, and prompts VLMs to answer questions about the student response. Figure 2: VLMs consistently perform worse on answering DrawEduMath benchmark questions pertaining to erroneous student responses. Performance on non-erroneous student responses is labeled with specific VLMs’ names; that same model’s performance on erroneous student responses is directly below.
