
A long-horizon reinforcement learning company.
Joined May 2024
- Tweets 77
- Following 0
- Followers 5,206
- Likes 225
37 Photos and videos







Pinned Tweet

May 26
🎡📜 We are recruiting for our London chapter.
The next era of reinforcement learning is going to be unlike the last, and requires new algorithms, environments and everything inbetween.
🏛️ Shape the next civilisation with us. Link below 👇
1
5
25
12,506
May 26
🎡📜 We are recruiting for our London chapter.
The next era of reinforcement learning is going to be unlike the last, and requires new algorithms, environments and everything inbetween.
🏛️ Shape the next civilisation with us. Link below 👇
1
5
25
12,506
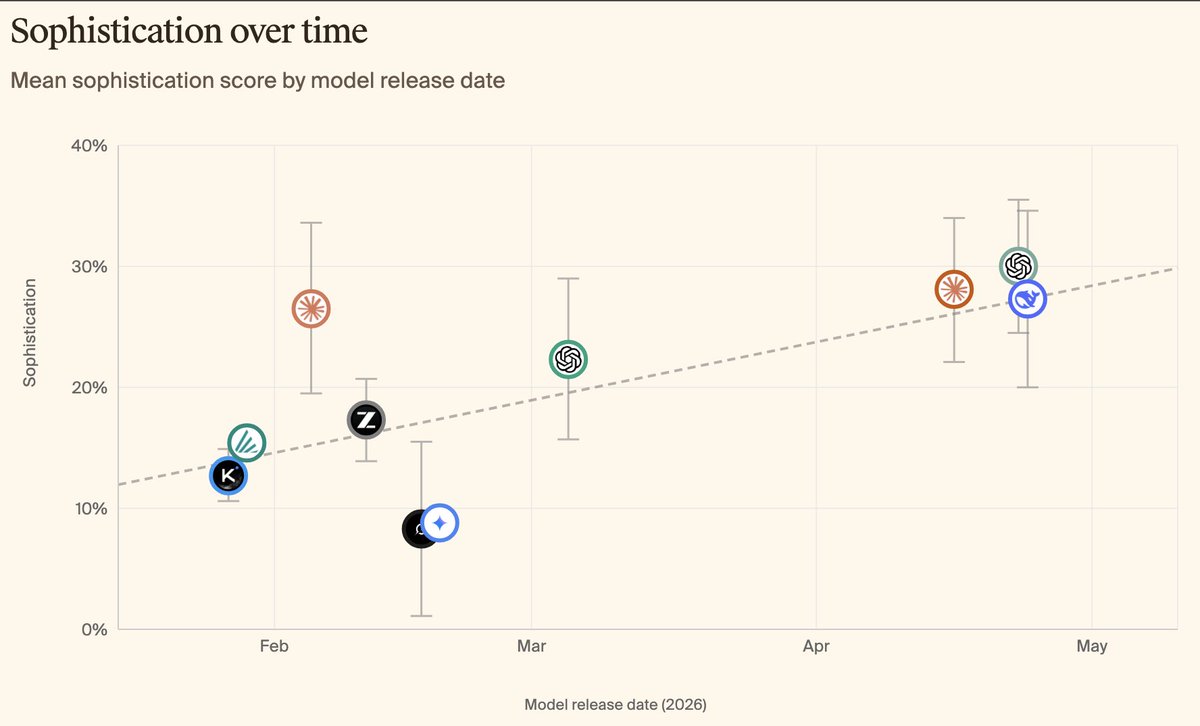
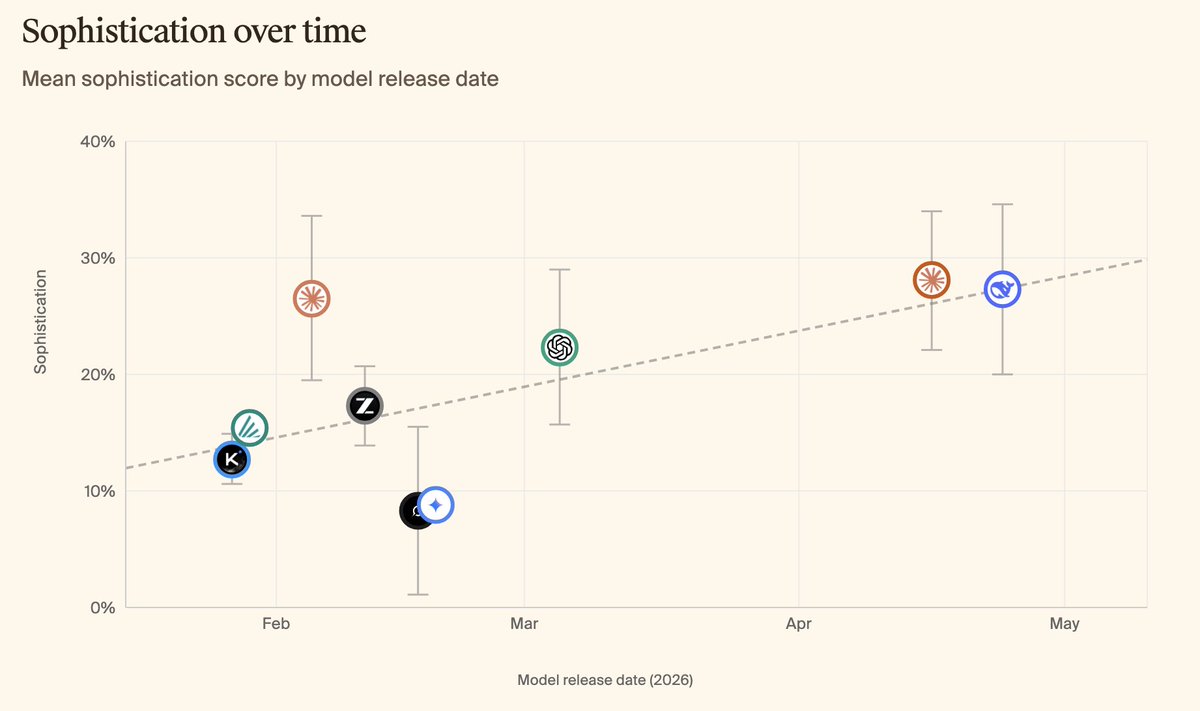
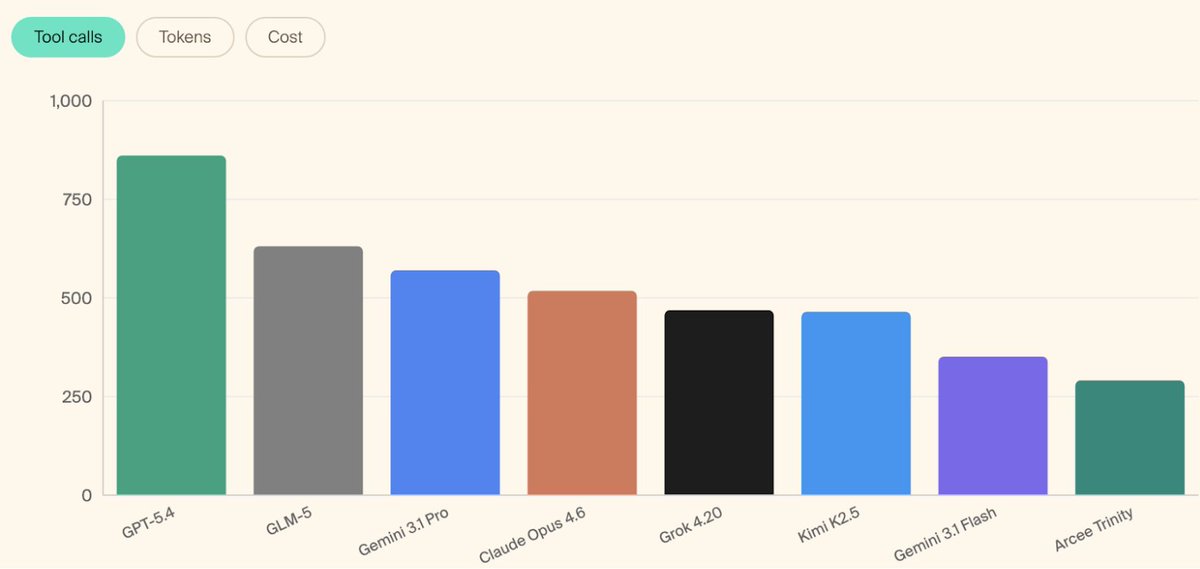
New models on KellyBench, the benchmark for long-horizon sequential decision making.
🎆 Claude Opus 4.7 - new state-of-the-art, with the highest strategy sophistication recorded on the benchmark (28.5%). But still loses -3.7% on average over five seeds.
🐋 DeepSeek V4 Pro - shows strong feature development capabilities, but scores poorly on overfitting rubrics which harms it in deployment (-47%).
Link and more graphs below.
2
6
93
11,288
We’re also thankful that KellyBench was featured on the front page of the FT last month!
(The British AI neuron has a superposition with football…)

1
4
816
We've updated the leaderboard with GPT-5.5 results:
gr.inc/releases/introducing-…
TLDR: 30% strategy sophistication (new SoTA), much more efficient than GPT-5.4, but still in the red and systematically underperforming human approaches.
1
433
🌍 Last month we hosted the Complex Worlds Hackathon in London.
Participants built an impressive range of environments, spanning synthetic game pipelines, arable farm management, dynamic vehicle routing, hospital triage, robotics, cybersecurity, and more.
Congrats to our winners, Julie Huang and Khalid A!
3
3
27
5,551
Thanks to @ibragim_bad, Jeff Smith and Giovanni R for judging. Thanks to event partners @join_ef @airstreet.
You can view the environments contributed at the event below:
openreward.ai/environments
1
460
Apr 22
🎉 We're now supporting the Agent Data Protocol as a default agentic trajectory format.
Any trajectories you log to @OpenReward can be exported in the ADP format.
Thanks to @gneubig @yueqi_song for the collaboration!
11
43
17,512
Apr 21
🎉 Native Harbor support on OpenReward!
🐋 Connect your GitHub repository. We'll build the Docker images for each harbor task and deploy the environment as an API endpoint.
🚂 Train on the deployed tasks with any RL framework.
⚖️ Evaluate on the deployed tasks with any harness.
Drop the anchor here and get started below:
docs.openreward.ai/environme…
1
6
25
4,635
Apr 21
🔥🐴 Firehorse.
Run any model with any harness on any @OpenReward environment.
⚖️ Evaluate the latest models on environment endpoints.
🗂️ Collect agentic data for midtraining and SFT from open models.
🧪 Early experimental library. More support soon.
Link below.
3
7
34
5,030
Apr 17
🌄 Beyond SWE: The Future of Long Horizon Environments
A discussion with our founders about KellyBench, and the need for new environments that require agents to adapt over time and act under uncertainty.
0:00:17 What is KellyBench?
0:02:10 Openendedness, non-stationarity and continual learning
0:03:40 Analytical versus operational capabilities
0:04:13 Why are models bad at KellyBench?
0:05:39 Situational awareness in dynamic environments
0:06:37 Feature stability and real-world non-stationarity
0:07:07 The power of context
0:07:34 "The first principle is that you must not fool yourself"
0:08:20 Machiavelli, fortuna and the ability to adapt to change
0:09:23 How can models improve on evals like KellyBench?
0:10:12 Limitations of KellyBench: data availability and market odds timing
0:11:44 Implications beyond quant finance / sports betting
0:13:26 Civilisations as the ultimate time horizon
0:14:05 Would a mega prompt / better elicitation do much better on the benchmark?
0:14:52 What new types of capability is GR excited about?
0:17:48 Taste and the ability to pursue long-term goals even if they aren't immediately rewarding
0:18:56 Deep learning as an example of a method that took a long time to bear fruit
0:19:25 Optimism about the future of AI
7
77
15,570
Apr 10
🌍🇬🇧 Complex Worlds Hackathon, London
We're hosting an RL environments hackathon in London on the 25th April, partnering with @join_ef and @airstreet
Come join us to build the next generation of RL environments that model complex worlds over long horizons!
luma.com/ykuhqraj
2
13
67
22,268
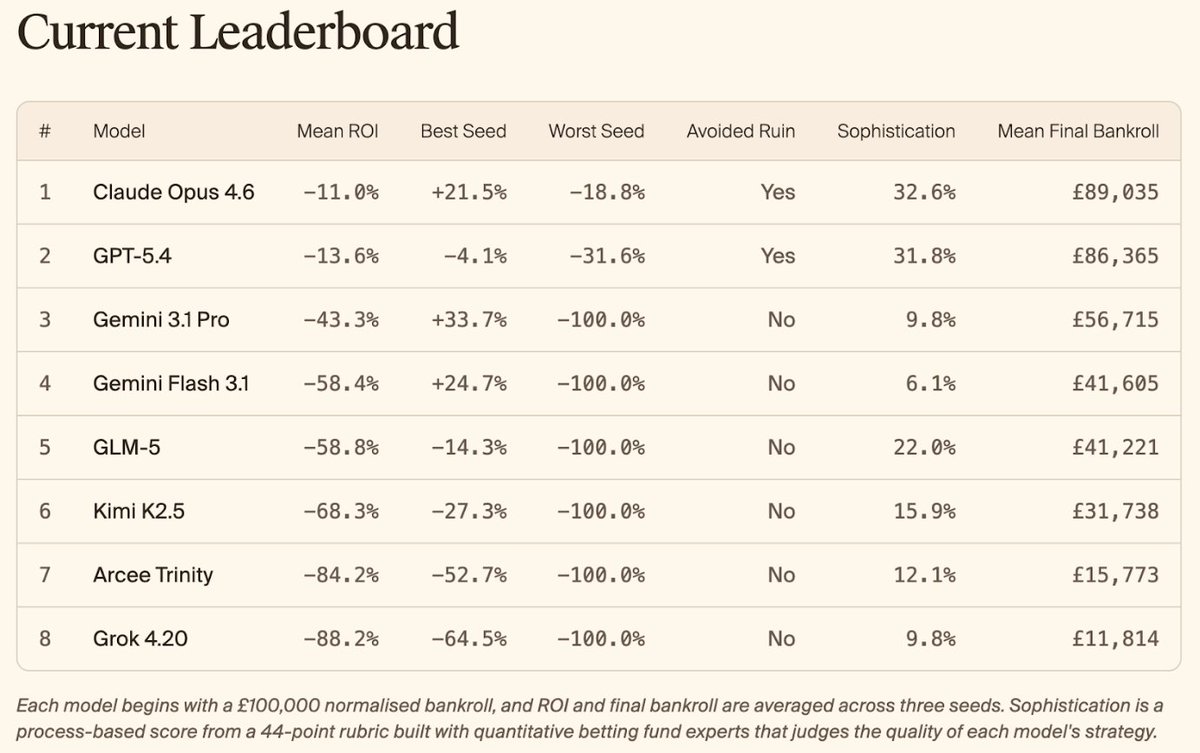
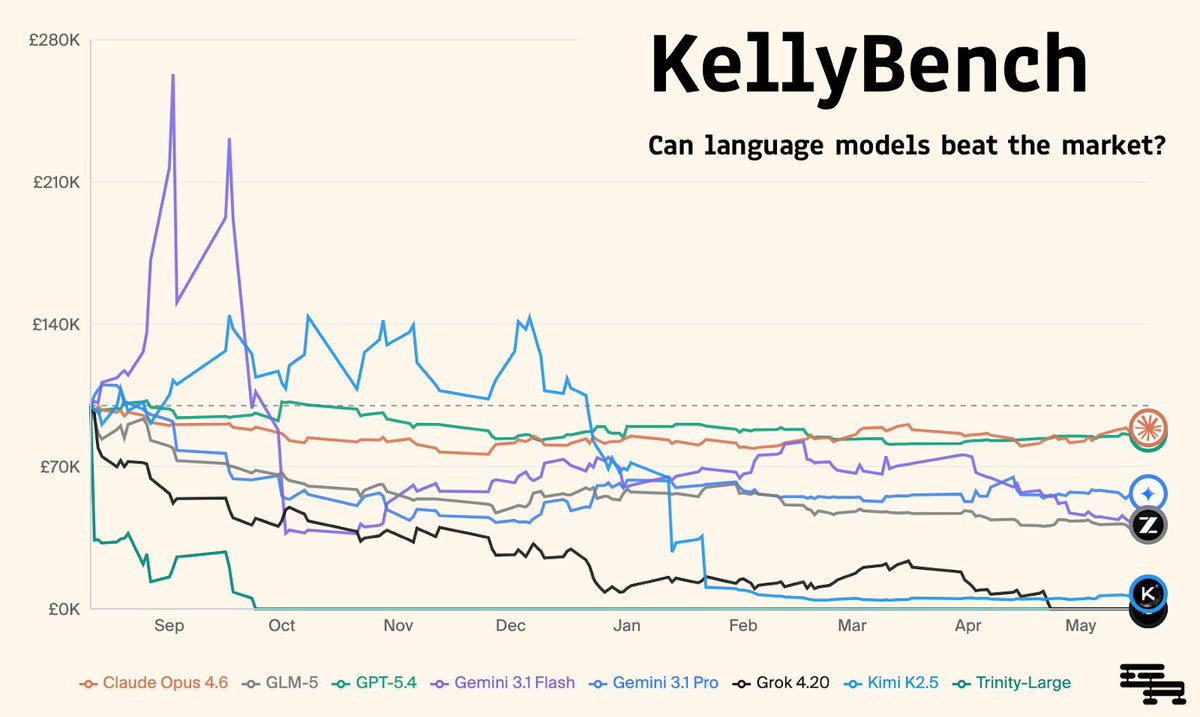
🎲 Introducing KellyBench, a new long-horizon evaluation for frontier models.
KellyBench evaluates models within a year long sports betting market, a challenging and highly non-stationary environment.
Every frontier model we test loses money. They struggle to design ML strategies, manage risk, and adapt as the world changes.
Link and thread below.
25
49
636
158,638
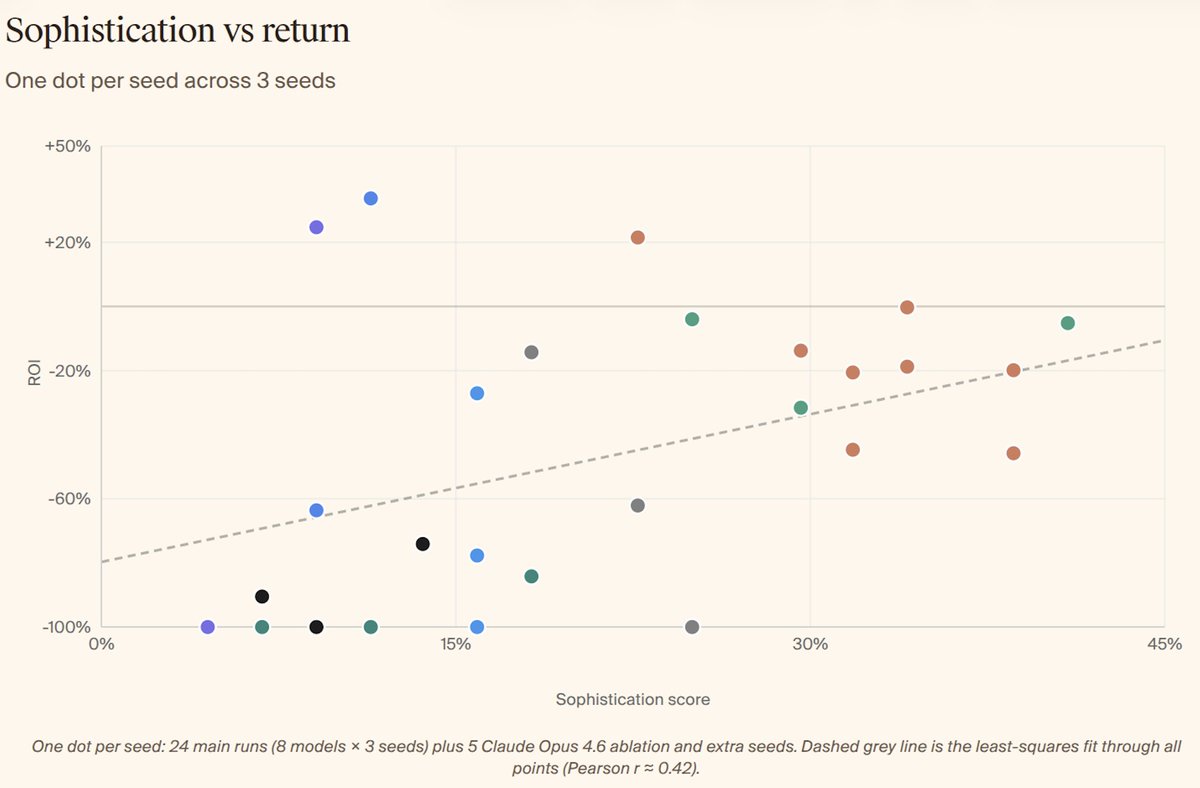
One potential critique of our setup is that betting markets are highly efficient, and models might be doing the best they can with the data they are given.
But we constructed expert rubrics and found models were unsophisticated and heavily underutilising available data. The best performing model Opus 4.6 achieved a sophistication score of only 32.6%.
So even if the market is highly efficient, there is much room for models to improve. In fact we find a positive relationship between sophistication and ROI for the seeds evaluated.
1
19
3,491
What is the implication of our results?
We think better performance is possible on KellyBench with more inference compute. For example evolutionary "autoresearch" approaches to feature development, or multi-agent scaffolds that simulate different roles in a quantitative fund.
But there is a broader point to be made. We believe the field is focusing too much on procedural tasks and not enough on truly long-horizon tasks.
In the real world, agents will need to pursue open-ended goals, act under uncertainty, and adapt their approaches as the world changes. KellyBench is a test for these capabilities, and models struggle to perform effectively.
KellyBench is the first release of our complex worlds research programme. We will have more to share on this direction soon.
Try out KellyBench on OpenReward:
openreward.ai/GeneralReasoni…
2
2
20
2,919