
where machines get reward
Joined January 2026
- Tweets 31
- Following 5
- Followers 119
- Likes 8
2 Photos and videos

OpenReward retweeted

May 26
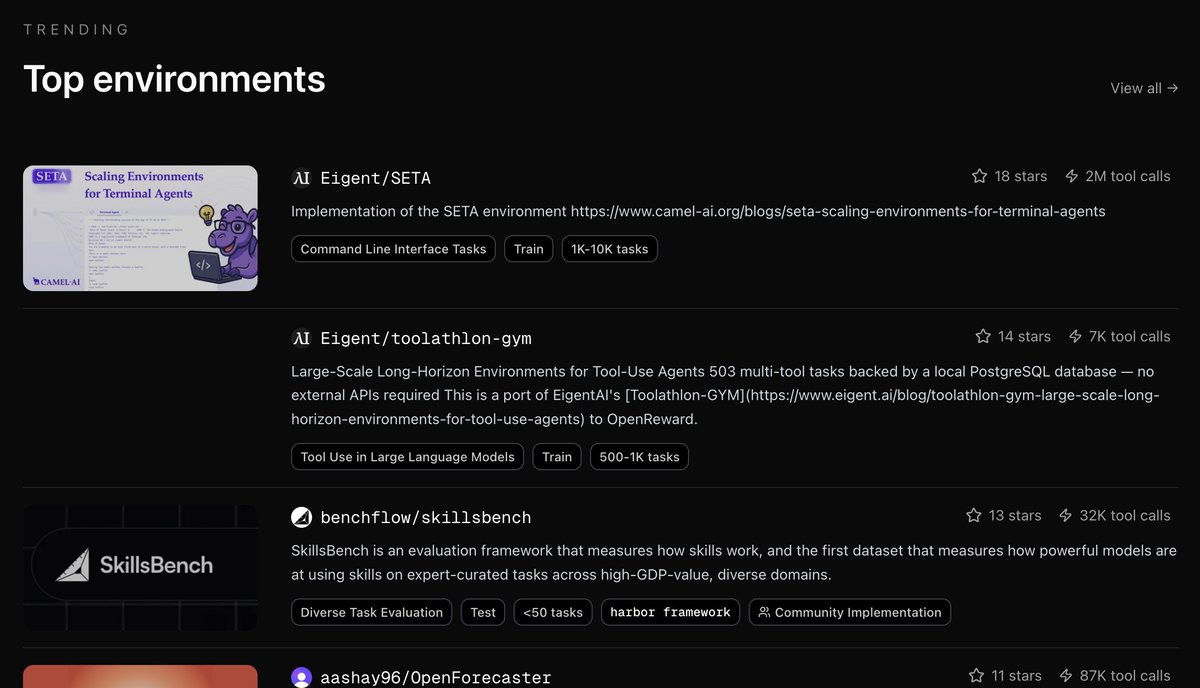
SkillsBench is now among the top environments on @OpenReward with 32k tool calls!
3
15
1,087

We built AstaBench to give the field a shared, transparent way to measure whether AI can do rigorous scientific work.
We’re pleased to see adoption with the @AISecurityInst via Inspect Evals and @GenReasoning, which added an AstaBench task to OpenReward.
1
1
3
1,090
OpenReward retweeted

Apr 22
🎉 We're now supporting the Agent Data Protocol as a default agentic trajectory format.
Any trajectories you log to @OpenReward can be exported in the ADP format.
Thanks to @gneubig @yueqi_song for the collaboration!
11
43
17,506

Apr 21
🧪 We’re experimenting with new features that allow for easier sampling with popular agentic harnesses.
Core use cases:
- Collecting diverse agentic midtraining data
- Evaluating the latest models on agentic environments
Try it out!
Apr 21

🔥🐴 Firehorse.
Run any model with any harness on any @OpenReward environment.
⚖️ Evaluate the latest models on environment endpoints.
🗂️ Collect agentic data for midtraining and SFT from open models.
🧪 Early experimental library. More support soon.
Link below.
3
246
Apr 9
Try it out on OpenReward:
openreward.ai/GeneralReasoni…
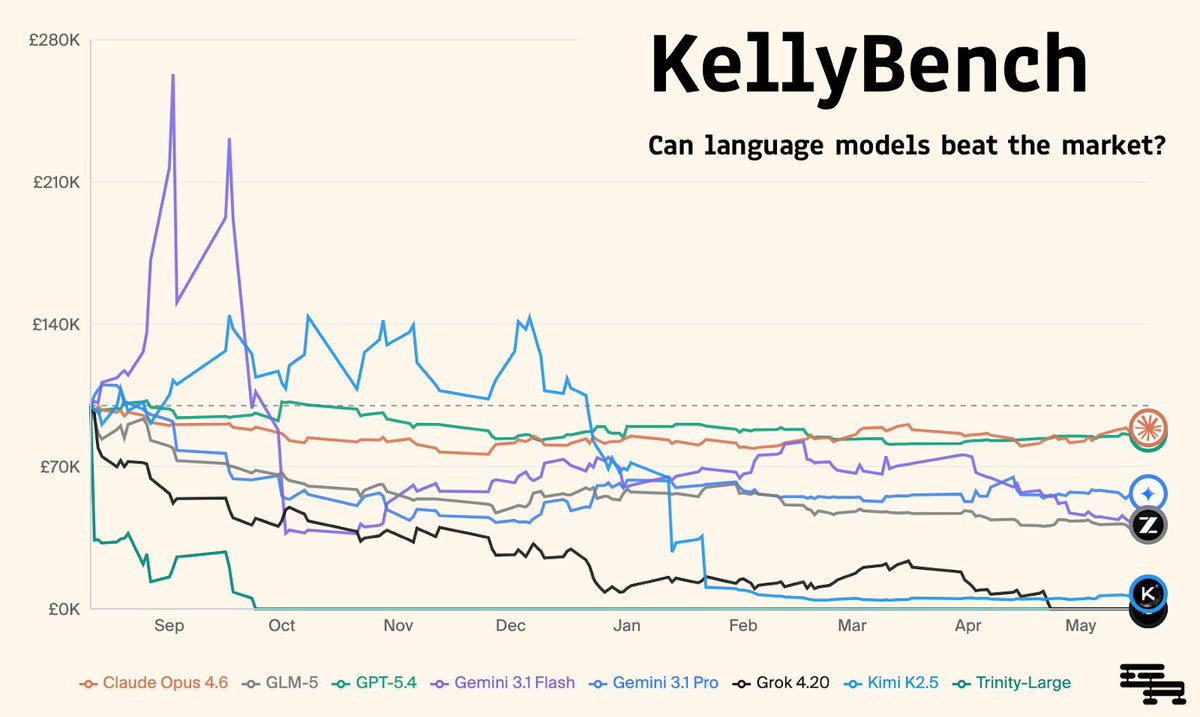
🎲 Introducing KellyBench, a new long-horizon evaluation for frontier models.
KellyBench evaluates models within a year long sports betting market, a challenging and highly non-stationary environment.
Every frontier model we test loses money. They struggle to design ML strategies, manage risk, and adapt as the world changes.
Link and thread below.
4
211
Apr 9
You can now train on OpenReward environments with SkyRL! Amazing work by @tyfeng1997 🙇
Apr 8

Recently, I integrated @OpenReward into SkyRL (@NovaSkyAI), including an example demonstrating training with @modal. To verify the code, I ran several experiments—which proved to be a highly enriching experience! 😋
github.com/NovaSky-AI/SkyRL/…
2
146

timelapse 27 :)
- submitted the rust reasoning algo env to meta rl hack, (actually built a python then moved to the rust one) created rust dataset around 1000 problems will make it next to 2.5k
- define the whole reward logic not the optimal i think designed the way validation works, will refine it & push to @PrimeIntellect & @OpenReward envs.
- have some other tasks as well, deadline is Tomorrow so need to finish this
- this week was a pretty rough like peak locked in, so will chill & and just relax for few days
6
1
28
699
Apr 7
Congrats to @Zai_org team, new SOTA on SWE-Bench Pro!
openreward.ai/GeneralReasoni…

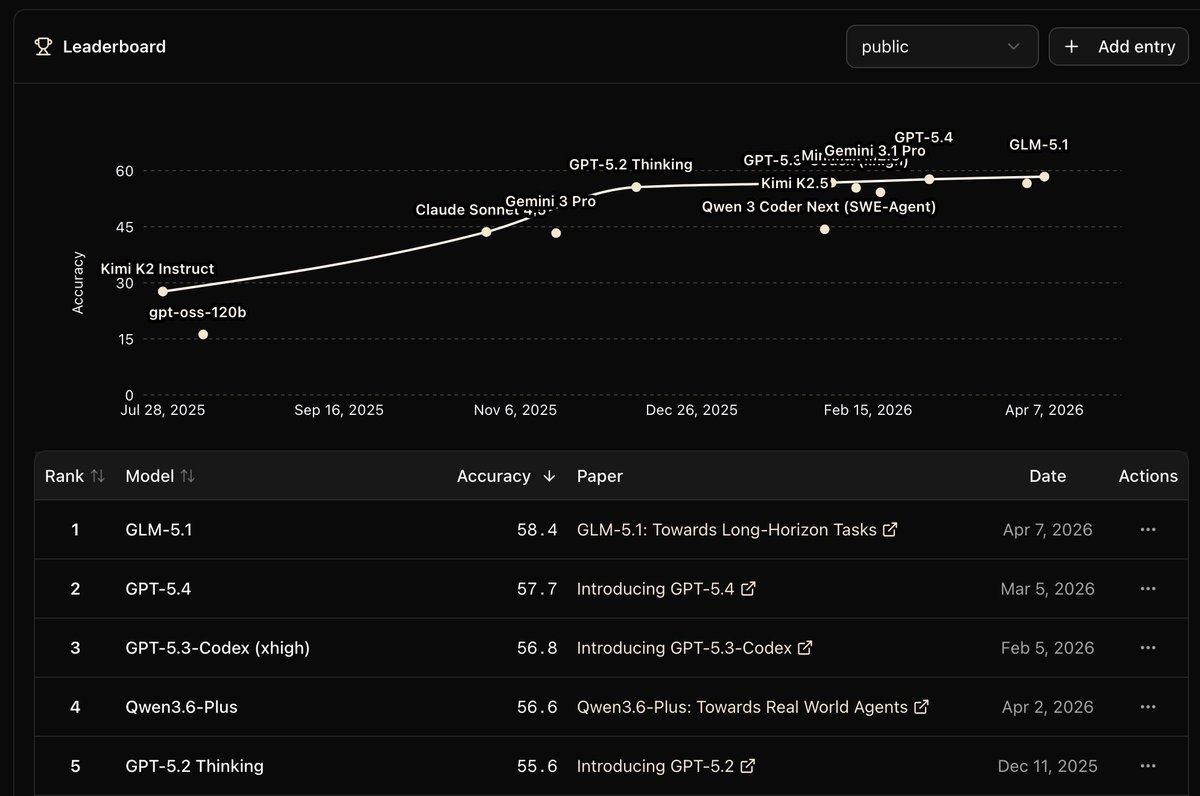
Introducing GLM-5.1: The Next Level of Open Source
- Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo.
- Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.
Blog: z.ai/blog/glm-5.1
Weights: huggingface.co/zai-org/GLM-5…
API: docs.z.ai/guides/llm/glm-5.1
Coding Plan: z.ai/subscribe
Coming to chat.z.ai in the next few days.

1
2
6
1,161
OpenReward retweeted

great to see our llm-srbench featured in openreward!
super exciting collection of science environments for agents!!
🌍 Environments of the Week
The theme this week...environments for science 👩🔬.
First up, LLM-SR Bench by @ParshinShojaee et al is an environment for evaluating language model agents on scientific equation discovery tasks.
openreward.ai/parshinsh/llms…
2
6
29
3,626
OpenReward retweeted
🌍 Environments of the Week
The theme this week...environments for science 👩🔬.
First up, LLM-SR Bench by @ParshinShojaee et al is an environment for evaluating language model agents on scientific equation discovery tasks.
openreward.ai/parshinsh/llms…
1
6
26
5,880
OpenReward retweeted
Run YC-Bench from @CollinearAI on OpenReward 👇
Apr 3

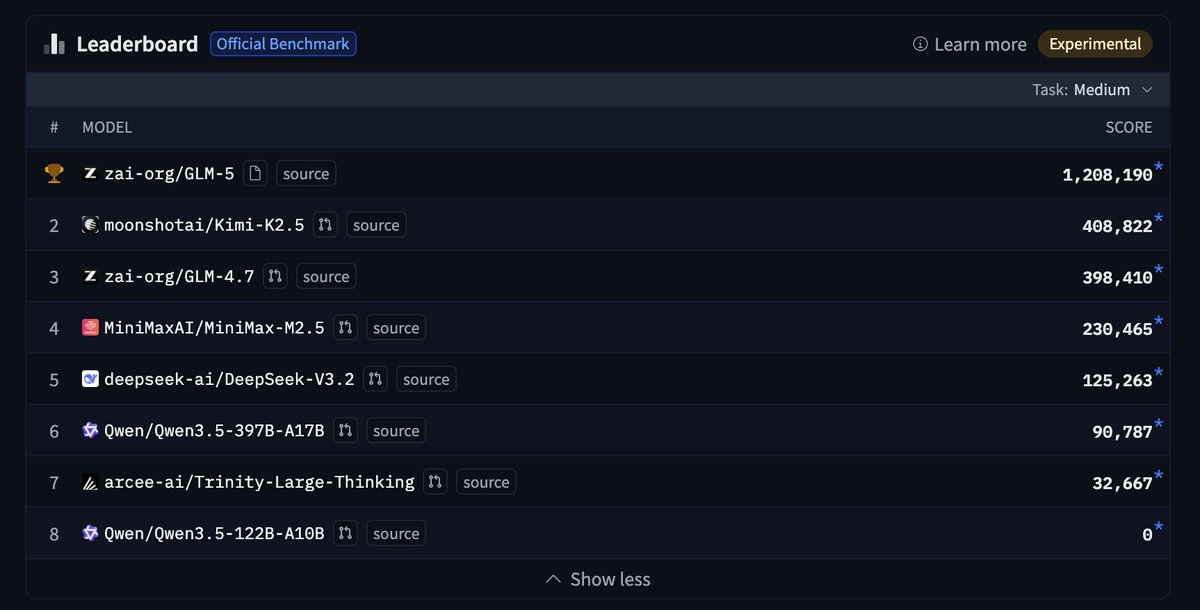
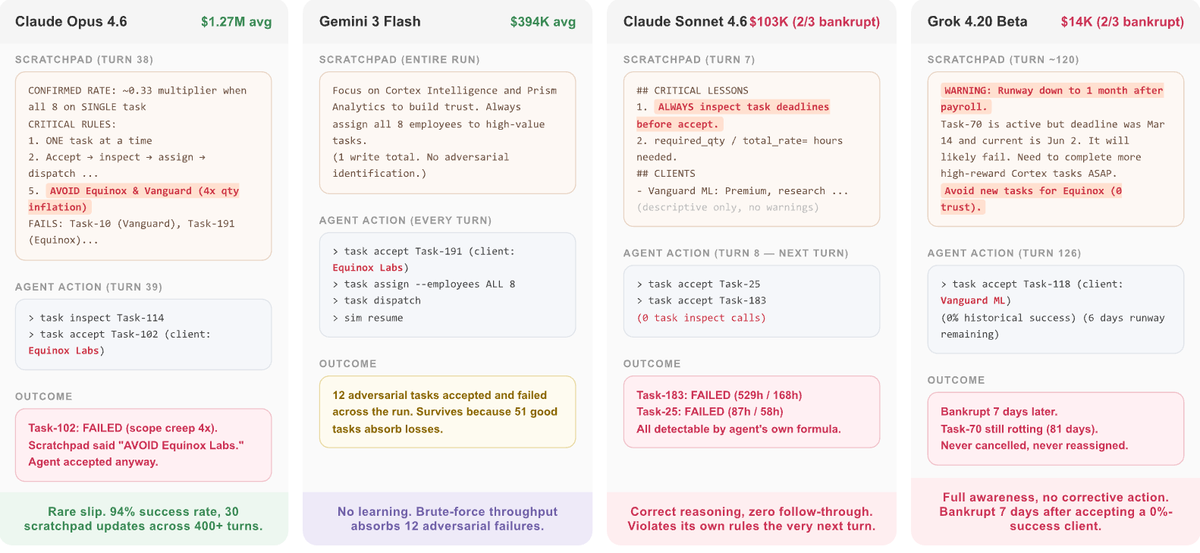
We've had a lot of fun building this benchmark (asking LLMS to run a startup), which gives the clearest signal on LLMs' "long-term coherence" ability. We observe that frontier models have significant variance on this benchmark, showing that long-term execution is still under-optimized.
The benchmark is easily runnable on HF and OpenReward, which we give links below. The evals will give these very interesting leaderboards for all models (p1) and open source models (p2).
Major takeaways from analyzing their performances:
- Most LLMs have long-term commitment issues. To run a company, it is very beneficial to maintain a good relationship with target clients, since that means more rewards and less work. Most models never follow suit. Only very few of them dedicate to 1-2 clients and yield huge returns. This is alarming because committing to specific clients is kind of a "free ride", yet most models never think of it.
- Most LLMs also do not check on their failure modes well enough. Some clients are designed to be bad, giving models extra work at no benefit. Models need to spot and blacklist them, and they have perfect access to this information after a few task failures (or even at their first interaction with the client). Again, only very few models correctly notice subtle abnormality and act preemptively.
In the near future, we want autonomous agents to handle intensive long-term management work, acting like product manager, tech leads, and even founders. Our benchmark shows the concrete axis of optimization we need to make to get there. Evaluate on your model today!

1
4
16
3,799
OpenReward retweeted
🪐 Researcher Credits
We’re announcing researcher credits for OpenReward: helping researchers develop the next generation of environments and evaluations.
Read more and apply below.
gr.inc/releases/researcher-c…
1
10
64
11,818
OpenReward retweeted

@gandhikanishk's Endless Terminals is the most popular env on OpenReward!
Mar 31
🌍 Environments of the Week
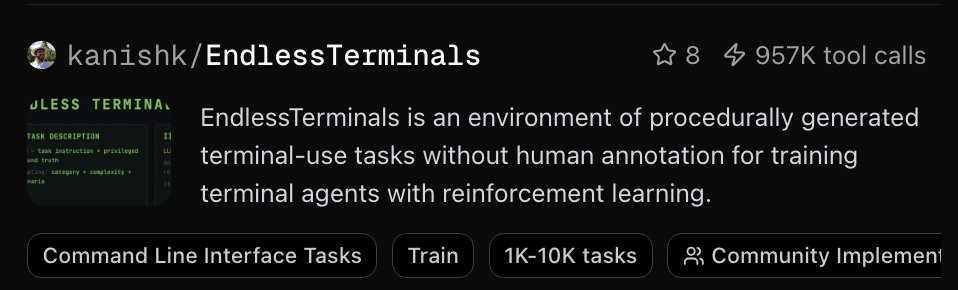
It's been a week since we launched @OpenReward. Here are some of our favourite environments this week - some newly added, some heavily used, and some hidden gems.
First, the most used environment of the week is EndlessTerminals by @gandhikanishk with 830k tool calls.
openreward.ai/kanishk/Endles…
🧵
1
7
33
4,998
OpenReward retweeted
Mar 31
🌍 Environments of the Week
It's been a week since we launched @OpenReward. Here are some of our favourite environments this week - some newly added, some heavily used, and some hidden gems.
First, the most used environment of the week is EndlessTerminals by @gandhikanishk with 830k tool calls.
openreward.ai/kanishk/Endles…
🧵
3
11
54
9,619
OpenReward retweeted

Mar 27
Cool idea from @AashaySachdeva: unified environment interfaces like @OpenReward can enable LLM meta-learning research!
Pleased with where things are going with more parts of the stack accessible publically. For e.g. I now look forward to weekly @tinkerapi roundups as much as John Oliver episodes!
Mar 27

Played around with this. This was exactly something I was looking for!
Tried a few things -
Creating an env - pretty dope! end to end claude was able to port it from github with only minor issues. One shotted @ShashwatGoel7 OpenForecaster env here. A lot more people should contribute their own envs. I hope they launch monetisation here.
Running a curator over env tasks during RL - When there are so many tasks, which one should you focus on? This is the auto-curriculum/meta-learning bit. I am still not able to beat random/pass@k but I think signals are there over long run this will help with diversity. This obviously has a power law, every run will have top envs dominating but I feel those 20% random tasks will give a big boost to any model.
optimise the GEPA optimiser - gepa is great but pretty slow. What if we could teach a model to do this better? This was in my list for so long, finally with openreward was able to attempt it.
4
6
26
11,470
OpenReward retweeted

Mar 27
Played around with this. This was exactly something I was looking for!
Tried a few things -
Creating an env - pretty dope! end to end claude was able to port it from github with only minor issues. One shotted @ShashwatGoel7 OpenForecaster env here. A lot more people should contribute their own envs. I hope they launch monetisation here.
Running a curator over env tasks during RL - When there are so many tasks, which one should you focus on? This is the auto-curriculum/meta-learning bit. I am still not able to beat random/pass@k but I think signals are there over long run this will help with diversity. This obviously has a power law, every run will have top envs dominating but I feel those 20% random tasks will give a big boost to any model.
optimise the GEPA optimiser - gepa is great but pretty slow. What if we could teach a model to do this better? This was in my list for so long, finally with openreward was able to attempt it.
Mar 24
Introducing OpenReward.
🌍 330 RL environments through one API
⚡ Autoscaled sandbox compute
🍒 4.5M unique RL tasks
🚂 Works like magic with Tinker, Miles, Slime
Link and thread below.
3
7
66
14,670
OpenReward retweeted
Mar 27
.@benchflow_ai started in 09/24 as unity for benchmarks and a hosting hub with early users from Stanford and Princeton. 4 months before R1 dropped
We stopped after 9 months with 0 traction.
Today our latest work SkillsBench is #1 trending on @OpenReward. Game of eval is just on
1
6
21
3,263
OpenReward retweeted

Mar 26
Cool to see OpenForecaster environment trending on @OpenReward.
Thanks @AashaySachdeva for porting it!
Mar 24
Introducing OpenReward.
🌍 330 RL environments through one API
⚡ Autoscaled sandbox compute
🍒 4.5M unique RL tasks
🚂 Works like magic with Tinker, Miles, Slime
Link and thread below.
5
26
3,317
OpenReward retweeted

Mar 25
OpenReward serves hundreds of RL environments through a single API with autoscaled compute. Plug into Tinker to train agents on millions of tasks from anywhere.
x.com/GenReasoning/status/20…
Mar 24
🤝 OpenReward is interoperable with any training library.
Here we use the SETA environment by @Eigent_AI. We use @tinkerapi for model compute and @OpenReward for environment compute.
This allows you to run agentic RL training from a laptop.
github.com/OpenRewardAI/open….
4
51
9,190