
Online marketing, SEO, digital assets, crypto, music. Glass is half full!
Joined March 2008
- Tweets 323
- Following 203
- Followers 1,030
- Likes 697
16 Photos and videos
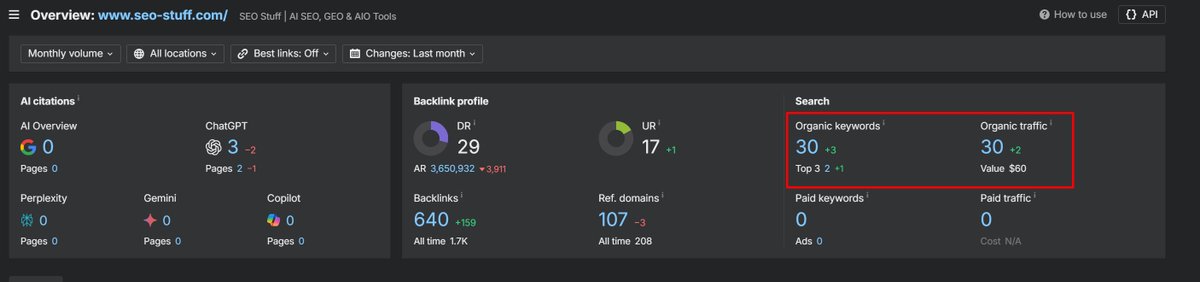
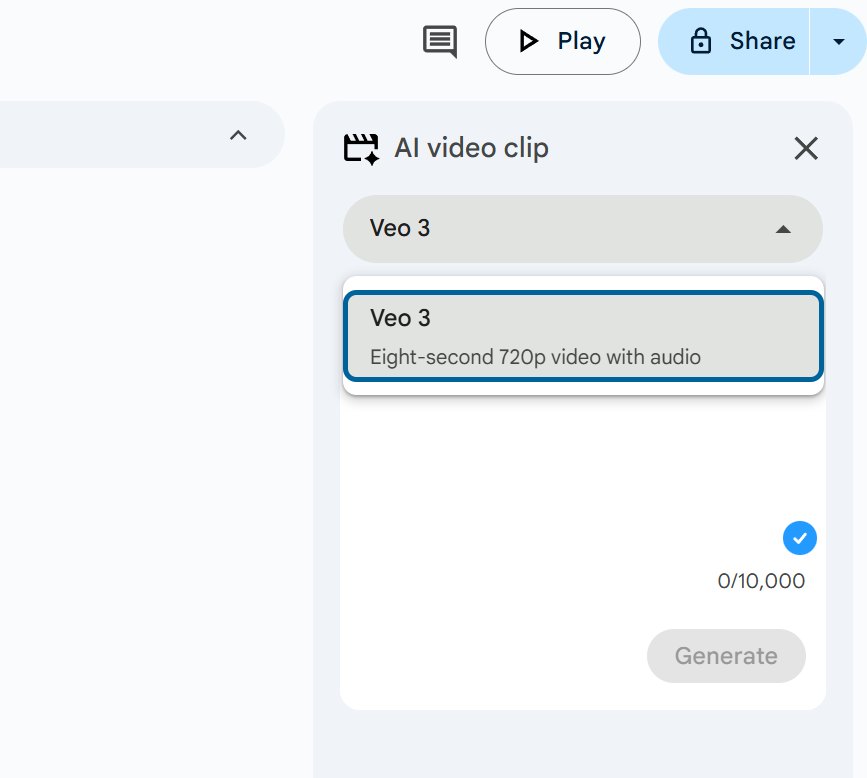









Apr 23
Has GPT Pro 5.4 (5.5) been nerfed again? For me, it’s noticeably slower and the output quality seems back to the old pre-spud version.
1
207
Guillaume vd Laar retweeted

Apr 16
This is the benchmark to watch today after the launch of Claude Opus 4.7.
BridgeBench Reasoning.
Claude Opus 4.6 sits at #4.
Behind Grok 4.20 Reasoning, GPT 5.4, and Grok 4.20 Non-Reasoning.
If Claude Opus 4.7 doesn't leapfrog all three, Anthropic has a problem.
Results coming the moment the model drops.

14
4
68
9,986
Guillaume vd Laar retweeted

15 Sep 2025
ik neem aan dat Bruls nu aangiftes gaat verzamelen tegen Bob Vylan?? Het #CDA is toch voor fatsoen moet je doen? Toch? 🤡🤡🤡telegraaf.nl/binnenland/cent…
5
32
104
1,681
26 Mar 2025
Binnenkort te koop? #Mand, #MandjeVanTichelaar, #OmroepMaxim, #MaximHartman, #BenStrik, #Meme, #DutchMeme, #Viral, #korter, #nogkorter, #bobblehead
101
12 Sep 2024
Heyyyy, @OpenAI's new o1-preview model got the marble/microwave question correct. It also got the strawberry question right. On to some more testing....
2
101
Guillaume vd Laar retweeted

18 Apr 2022
Partnering with @MechGameNft for a HUGE giveaway!
11 Whitelists 1 Genesis NFT for 12 lucky winners!
-P2E Transferable 3D NFTs
-Native token staking
-Amazing storyline with WEBGL
-Rock star team
To enter:
Follow, RT, Like, and join the Discord
Discord: discord.com/invite/5XVMrQume…

47
92
111
20 Feb 2021
Wat er in 2 weken kan veranderen... 33 graden! 😎🍹☀️
#someren #somerennatuurlijk #somerencentrum #gemeentesomeren #zon #lente #summervibes instagram.com/p/CLg8BfmJt2h/…
1
18 Jun 2020
1
1
20 Jul 2016
Gezocht: Jong talent op internetgebied
Ben jij heel goed met het internet, ben je communicatief vaardig en ben je geïnteresseerd in online…
13 Dec 2014
12 Apr 2013
Ready for some serious racing tomorrow @ Spring event Weeze! instagram.com/p/YAvQjHk5TF/
2
9 Nov 2012
Does anyone have Kate Upton's number for me again? I lost all my numbers!
1