
Joined October 2020
- Tweets 3,813
- Following 2,758
- Followers 9,116
- Likes 46,307
138 Photos and videos












Grad retweeted

Jun 5
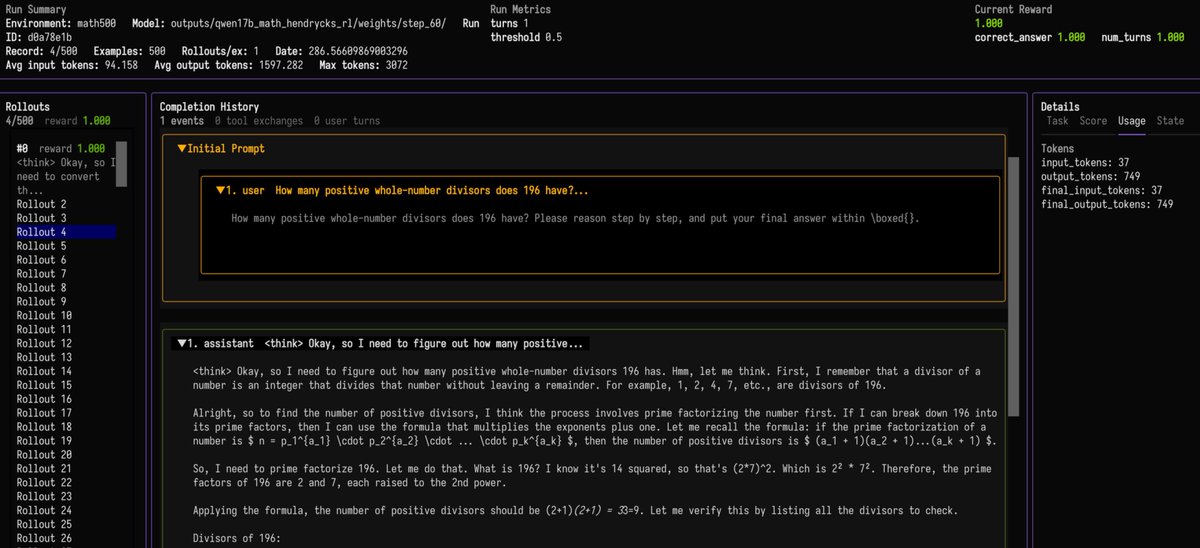
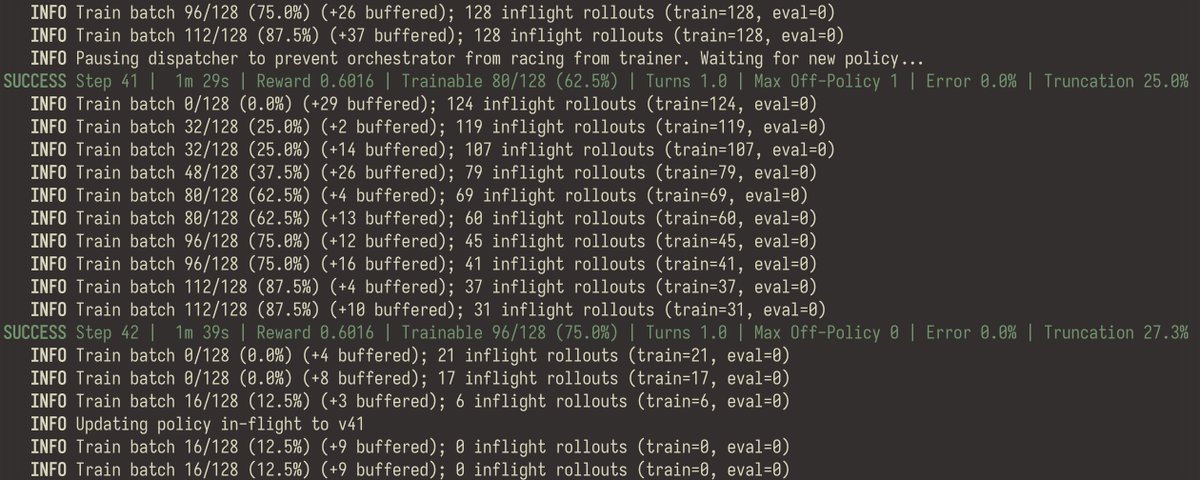
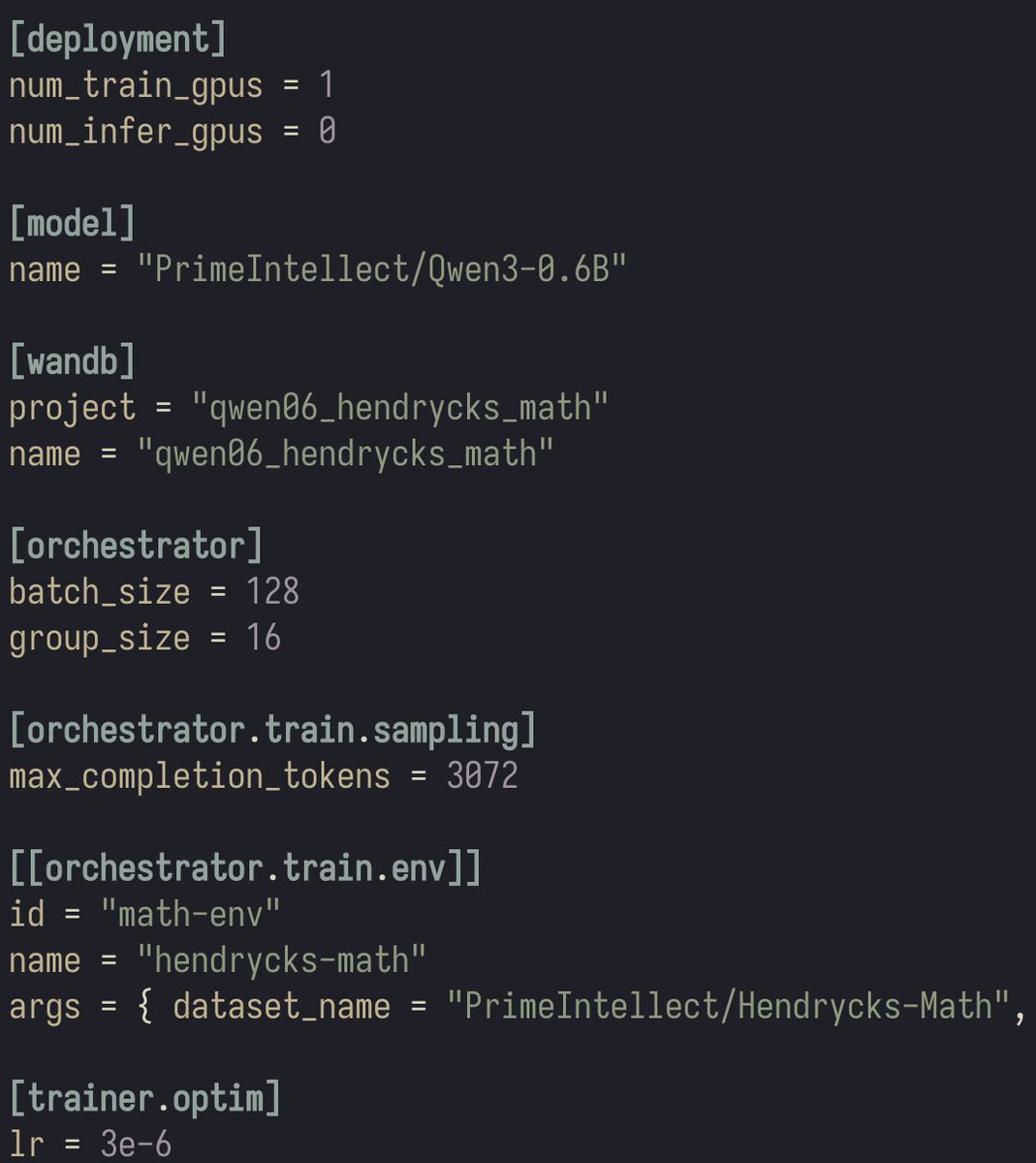
finally had the chance to give prime-rl a try...
It is very, very nice! Super easy to get experiments running, well-balanced logs that keep you up-to-date but don't drown you in warnings, amazing eval visualisation, efficient training...
Did not try the hosted training, just local single-gpu experiments.
I tried a couple of frameworks in the last couple of months, somehow this hits the sweet spot of easy configurability, and necessary level of detail to "be in control" (and not discover some unintuitive defaults after some weeks)
Great work @PrimeIntellect
5
11
54
8,571

Jun 4
Interestingly didn’t see anyone talking abt this but MAI used a batch size of almost 1B tokens during their final RL stage
13
6
193
14,358
Jun 4
In general RL seems to have a very different batch size scaling than pretraining
Also even in their previous shorter context stages, the batch sizes were always bigger or equal to the pretraining batch size
1
3
43
3,540
Grad retweeted

Jun 2
KV Cache re-use is the most important thing for agentic rollouts. We've integrated Mooncake Store into prime-rl with vLLM, you can now use it as a drop-in replacement for native CPU/Disk offloading, giving you cross-node prefix cache reuse to make your agents go brrr🚀
May 6

🚀 New on the @vllm_project blog: Serving Agentic Workloads at Scale with vLLM x Mooncake.
Agentic traces grow to 80K tokens with 94% reusable prefixes, but local KV caches evict them and cross-instance routing misses them.
By integrating Mooncake Store as a distributed KV cache pool, vLLM gets:
🚀 3.8x higher throughput
⚡ 46x lower P50 TTFT
⏱️ 8.6x lower E2E latency
📈 Cache hit rate 1.7% -> 92.2%
🌐 Scales near-linearly to 60 GB200 GPUs at >95% hit rate
🔥 Powered by a deep collaboration between @Inferact and @KT_Project_AI
📖 Read more: vllm.ai/blog/mooncake-store
🧵👇
14
25
337
31,084
Grad retweeted

Jun 1
ptc is the way
Jun 1

Introducing Search as Code, our new search architecture for AI agents.
It writes Python that calls our search stack directly, instead of looping through function calls one at a time.
Available in the Perplexity Agent API, and now default in Computer.
research.perplexity.ai/artic…

5
9
168
23,716
Grad retweeted

May 28
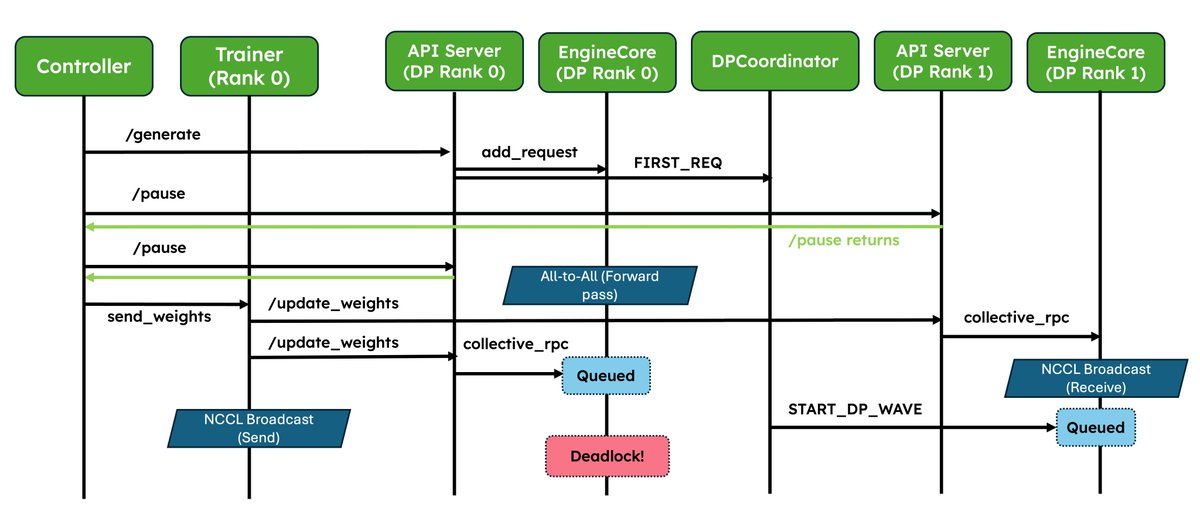
Excited to share some of our work on improving vLLM for RL!
A number of RL frameworks, including SkyRL, use vLLM for inference, and we’ve noticed some common problems:
1. Weight syncing between training and inference is implemented in an ad-hoc fashion and duplicated across frameworks.
2. Asynchronous RL is prone to break at scale, especially in P/D and DPEP deployments.
We’ve been working on improving both!
8
41
184
28,897
Grad retweeted

May 28
what is suggested here is what we initially implemented ~december and have since found to be a nightmare to deal with and ultimately led to renderers. a bit from our diaries and why we think "just tokenize a tool bridge delta" is not a good solution

multi-turn RL and the "tito" problem keeps coming up. we've been working on it for a while, and the takeaway is that it's much easier than people are making it.
it takes 1 implementation rule, and 1 chat-template property that all models already comply with.
**that's all you need to do it right**
qgallouedec-tito.hf.space
2
7
58
8,443
Grad retweeted

May 19
The next step toward automating AI is automating RL environments
Introducing General-Agent: A fully synthetic environment whose task corpus self-evolves and grows harder over time
4,504 tool-use tasks · 1,040 domains · 8,159 unique tools
47
125
1,307
289,718
May 19
Always painful to see wasted data in the form of evals that no one uses
Open source community should every couple of months take all evals that no one uses and allow it to be trained on without being shamed
2
2
32
2,043
May 18
Cool to see work on this although I think many misunderstood the main work here
Making credit assignment work is mainly held back by the fact that in the objective to solve a task, it’s rare to have intermediate parts of a rollout that are verifiable directly
There is no correct intermediate tool call to make for example
Now something like model communication and code style it’s different
Like if we want no failed tool calls (more code style then something to solve the task) then this is a verifiable intermediate task
Same with model communication, like if we want the model to communicate its progress over time outside thinking
Main question is if u can use credit assignment to actually improve the performance of the model on solving tasks correctly
We’re currently quite bullish on some directions here that are elegant and general and hopefully can push some stuff out on this soon
May 18

We improved Composer by scaling training, generating more complex RL environments, and introducing new learning methods.
For example, we use text feedback during RL to learn faster by assigning credit in rollouts spanning hundreds of thousands of tokens.
1
4
99
9,886
Grad retweeted
May 14
Automating AI research is the next major step in AI
We let Claude Code (Opus 4.7) and Codex (GPT 5.5) run autonomously on the nanoGPT speedrun optimizer track using our idle compute. ~10k runs, ~14k H200 hours
Opus now holds the record at 2930 steps vs the 2990 human baseline

57
155
1,735
626,802
Grad retweeted
May 12
Introducing Renderers
RL trainers work in tokens. Environments work in messages. Going back and forth corrupts sampled tokens, wasting compute on every agentic turn.
With Renderers, we fix this mismatch. This unlocks >3x throughput on popular open models.

16
80
853
285,303
Grad retweeted
The next wave of AI will not be won by better prompts. It will be won by systems that learn from experience.
Today, Prime Intellect Lab is out of beta, open for you to start training your own models.
The era of self-improving agents is here.
83
200
1,986
1,320,206
Apr 29
I think this also then makes the battle against archs back on
Mimo using a 1:7 (or 1:6 can’t remember) ratio with SWA is iiuc a similar kv cache saving to DeepSeek v4 (not considering the attn hparams), and assuming DSA on the full layers works well
Also with KDA, could u push even higher ratios (although tbh idk how prefix caching works with KDA but guessing it works well)?
Question I guess is if ur getting better or worse model performance compared to the DeepSeek hybrid arch
Apr 28
As an update and convos with many others it did seem like the kv cache reduction is mainly to help hit rates with prefix caching, and for P/D kv transfer overhead
The improvements here are mainly for deployment and not for RL efficiency
Tbh I just didn’t know the prefix caching and hierarchical kv cache offloading was that much of a bottleneck but does seem quite important here tbf (so helps with being able to store more on layers higher up and evict less)
Also for prefill/training I kinda assumed DSA didn’t help much as the sparsity is dynamic but I’m pretty sure I’m wrong here (tbf never seen DSA training or prefill speed comparisons but haven’t looked much)
So the decisions do make sense for these reasons, although I still think the fact that kv cache size is now a bottleneck for prefix caching and P/D transfer compared to for decoding as before is an interesting change so might be more potential to do stuff here
3
41
4,210
Apr 28
As an update and convos with many others it did seem like the kv cache reduction is mainly to help hit rates with prefix caching, and for P/D kv transfer overhead
The improvements here are mainly for deployment and not for RL efficiency
Tbh I just didn’t know the prefix caching and hierarchical kv cache offloading was that much of a bottleneck but does seem quite important here tbf (so helps with being able to store more on layers higher up and evict less)
Also for prefill/training I kinda assumed DSA didn’t help much as the sparsity is dynamic but I’m pretty sure I’m wrong here (tbf never seen DSA training or prefill speed comparisons but haven’t looked much)
So the decisions do make sense for these reasons, although I still think the fact that kv cache size is now a bottleneck for prefix caching and P/D transfer compared to for decoding as before is an interesting change so might be more potential to do stuff here
Apr 27
I'm still confused by some of the decisions done in deepseek v4
Main confusion is why the huge focus on reducing KV cache size when with something like HiSparse u can offload most of ur kv cache (making ur decode compute bound)
This also is compensated with a huge 128 heads and 512 head dim for MQA (making training and prefill more expensive)
Using GQA with a bigger kv cache but reduce head dim to have cheaper attn just seems like a much better tradeoff (and making the compression quite confusing)
Compression mainly would help with making the indexer much cheaper but theres other ways too to do this like indexCache (actually even better for this as u can overlap the overhead of loading kv cache from CPU as u share indices over multiple layers)
I might be missing something here tho but just seems like deepseek didnt consider something like HiSparse for decode?
4
3
66
10,353
Apr 28
Also I still do think there’s an argument in general on if targeting this while sacrificing performance really is the way
Like the fact that u move into more ugly arch stuff like token compression is typically a sign that u might be moving too far in that direction
Although I guess it plays to their approach, guessing other players here are taking it in another direction but will see I guess
11
926
Apr 27
I'm still confused by some of the decisions done in deepseek v4
Main confusion is why the huge focus on reducing KV cache size when with something like HiSparse u can offload most of ur kv cache (making ur decode compute bound)
This also is compensated with a huge 128 heads and 512 head dim for MQA (making training and prefill more expensive)
Using GQA with a bigger kv cache but reduce head dim to have cheaper attn just seems like a much better tradeoff (and making the compression quite confusing)
Compression mainly would help with making the indexer much cheaper but theres other ways too to do this like indexCache (actually even better for this as u can overlap the overhead of loading kv cache from CPU as u share indices over multiple layers)
I might be missing something here tho but just seems like deepseek didnt consider something like HiSparse for decode?
32
8
253
37,189
Apr 27
I guess where it would appear is latency of moving the kv cache from prefill to decode workers but would need to look more at that
7
16
3,262
Apr 27
Hisparse: lmsys.org/blog/2026-04-10-sg…
indexCache: x.com/realYushiBai/status/20…
Mar 13

🧵 1/4
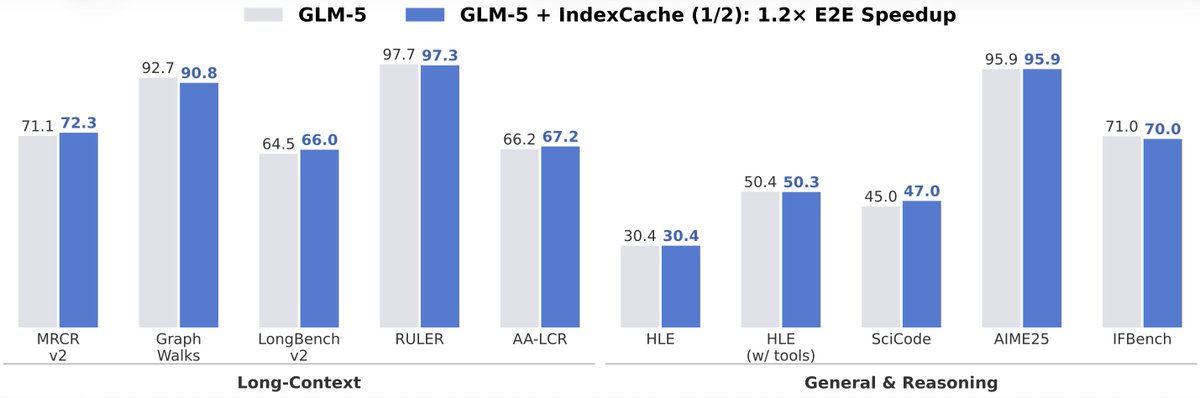
Still waiting for DeepSeek-V4? We (@Zai_org) made DSA 1.8× faster with minimal code change — and it's ready to deliver real inference gains on GLM-5.
IndexCache removes 50% of indexer computations in DeepSeek Sparse Attention with virtually zero quality loss. On GLM-5 (744B), we get ~1.2× E2E speedup while matching the original across both long-context and reasoning tasks.
On our experimental-sized 30B model, removing 75% of indexers gives 1.82× prefill and 1.48× decode speedup at 200K context. How? 🧵👇
#DeepSeek #GLM5 #Deepseekv4 #LLM #Inference #Efficiency #LongContext #MLSys #SparseAttention
1
22
4,754
Grad retweeted

Apr 5
update: joining @PrimeIntellect 🦋
i'm super excited to join the team. i really admire what they've been building and i love the mission of pushing the frontier in the open
i'll be working on pre/mid training, there's so much left to figure out and i truly believe a small group with the right people, resources and focus can do sooo much 🚀

ALT lfggggg
171
45
1,199
103,752